یادگیری تقویتی روشی است که در آن عامل با در نظر گرفتن حالت محیط، از بین همه اعمال ممکن یکی را انتخاب می کند و محیط در ازای انجام آن عمل، یک سیگنال عددی به نام پاداش به عامل باز می گرداند.
هدف عامل این است که از طریق سعی و خطا سیاستی را بیابد که با دنبال کردن آن به بیشترین پاداش ممکن برسد.
در این پروژه سعی داریم به یک عامل یاد بدهیم چگونه مواد مورد نیاز برای درست کردن یک کیک را با استفاده از یادگیری تقویتی جمع آوری کند.
محیط به صورت یک ماز است که یک هیولا در آن وجود دارد و در یک سری از خانه ها چاله وجود دارد که مانع عامل ما هستند.
عامل باید سه ماده آرد، شکر و تخم مرغ را در کوتاهترین زمان جمع آوری کند بدون آنکه هیولا او را بگیرد.
مقدمه
در این پروژه محیطی داریم به صورت شطرنجی که عامل با جمع کردن سه ماده آرد، شکر و تخم مرغ و عدم برخورد با غول میتواند کیک مورد علاقه اش را درست کند و بازی را میبرد. در این میان عامل باید سعی کند کمتر به دیوار برخورد کند و یا در چاله بیفتد. عامل ما در هر لحظه در خانه ای به سر میبرد . او میتواند در هر خانه به چهار سمت حرکت کند. در یادگیری تقویتی برای هر حرکت پاداشی در نظر گرفته میشود .
توضیحی بر یادگیری تقویتی : در این موضوع عامل علاوه بر اینکه در هر حالت باید بهترین تصمیم را بگیرد ، باید نسبت به پاداشی که در آینده در حرکتاتی که بعد از حرکت فعلی نسیبش میشود ، حساس باشد . دو معیار اکتشاف و بهره برداری از عواملی هستند که عامل در انتخاب مسیر در هر خانه باید از آن ها کمک بگیرد . اکتشاف یا همان سعی و خطا یعنی امتحان کردن حرکتی جدیدی که در گذشته امتحان نکرده ، به این امید که باعث افزایش پاداش او شود (که همراه با ریسک است) . منظور از بهره برداری نیز این است که عامل متناسب با تجربیات گذشته خویش ، مسیری را انتخاب کند که بیشترین امتیاز را در گذشته به او داده است . هرکدام ازین دو راه اگر به تنهایی مورد توجه عامل قرار گیرند ،باعث شکست خواهد شد . پس برای تعیین خط مشی خود باید هر دو معیار را با نسبت مناسبی مورد توجه قرار دهد.
در پایان عامل باید خط مشیی را پیدا کند که که با استفاده از آن بتواند حالات را به اعمالی نگاشت دهد که بیشترین امتیاز را برای او به ارمغان آورد . یعنی با رجوع با آن در هر موقعیتی که قرار دارد بتواند بهترین عمل را انجام دهد .
کارهای مرتبط
در این پروژه من میخواهم موضوع را با دو الگوریتم Q-learning و sarsa بررسی کرده و میان این دو الگوریتم ، روش بهتر را انتخاب کنم . هر دو روش ذکر شده بر پایه ی یادگیری تقویتی عمل میکنند ، به این صورت که در الگوریتم سارسا ، عامل در مرحله ی یادگیری همراه با یادگیری رویه ی خود را هم بهینه میکند ولی در روش یادگیری Q عامل رویه خود را حین عمل خود تغییر نداده و در پایان خط مشی را به صورت کلی تغییر میدهد .
در فاز سوم روش sarsa را تشریح کرده ، و نتایج آزمایشات را ثبت میگردد .
روش sarsa
روش سارسا یک روش TD(0) online میباشد که همان سیاستی را بهینه میکند که در طول یادگیری از آن استفاده میکند. در عکس زیر الگوریتم آن را مشا هده میکنیم :

ابتدا مقادیر Q را برای همه حالت -عمل ها برابر صفر قرار میدهیم. سپس در هر اپیزود با استفاده از یک سیاست نرم بر پایه Qهای تخمین زده شده تا آن لحظه یک عمل را انتخاب میکنیم و انجام میدهیم. پاداش لحظه ای دریافت میشود و به یک حالت جدید میرویم. در این حالت جدید نیز عمل دلخواه را انتخاب میکنیم و ارزش حالت-عمل اولیه را بر اساس پاداش لحظه ای آن و ارزش حالت-عمل بعدی بروزرسانی میکنیم.
با تکرار مداوم این کار سعی در یافتن ارزشهای بهینه میکنیم. سیاست مورد استفاده برای زمان یادگیری در ابتدا ε-greedy و سپس Boltzman استفاده شدند. سیاست ε-greedy مقدار regret کمتری نسبت به Boltzman دارد ولی Boltzman به مقدار بهتری همگرا میگردد. سیاست ε-greedy به دلیل اینکه Q-based نیست و rank-based است دارای مشکلات و نواقص زیادی است ( مثلا چون همه اعمال غیر بهینه را با احتمالی برابر انتخاب میکند، یک عمل با پاداش بسیار منفی مثل رفتن به خانه غول و یک عمل تقریبا خوب را مثل حرکت به سمت شکر را با احتمالی برابر انتخاب میکند) و این نواقص در Boltzman وجود ندارد ولی با این حال regret در ε-greedy کمتر است. دلیل این امر اولا دشواری مقدار دهی به پارامتر دما در Boltzman است و ثانیا تاثیر نمایی مقدار Q در احتمال انتخابها است. این دو مشکل در ε-greedy وجود ندارد و لذا کمی regret بهتری دارد. هرچند اگر پارامتر دما در Boltzman خیلی خوبی تنظیم شود حتما نتیجه بهتری از ε-greedy خواهد داد.
روش Q-learning
در این روش نیز همانند سارسا ابتدا مقادیر Q را برای همه حالت عملها برابر صفر قرار میدهیم. سپس در هر اپیزود با استفاده از یک سیاست نرم بر پایه Qهای تخمین زده شده تا آن لحظه یک عمل را انتخاب میکنیم و انجام میدهیم. پاداش لحظه ای دریافت میشود و به یک حالت جدید میرویم. باید توجه داشت که Q-Learning یک روش off-policy است یعنی عامل با یک سیاست نرم در محیط در حال زندگی است در حالیکه همزمان یک سیاست حریصانه دیگر را یاد میگیرد و بهینه مکند. در این روش برخلاف سارسا ارزش حالت عمل مشاهده شده را بر اساس ارزش حالت عمل بعدی بروز نمیکنیم بلکه بروزرسانی بر اساس ارزش عملی که در حالت بعد بیشترین ارزش را داراست صورت میگیرد. الگوریتم این روش به طور کامل در شکل زیر آمده است :

آزمایشها
روش sarsa
برای تنظیم پارامتر τ از تابع کاهشی (( ΤAW = 1000 * (1.05 ^ (-ep/60 استفاده شده که در آن ep شمارنده اپیزود است. مدت زمان اجرای روش سارسا با سیاست بولتزمن و تعداد اپیزود 10000 ، برابر 161 ثانیه میباشد.
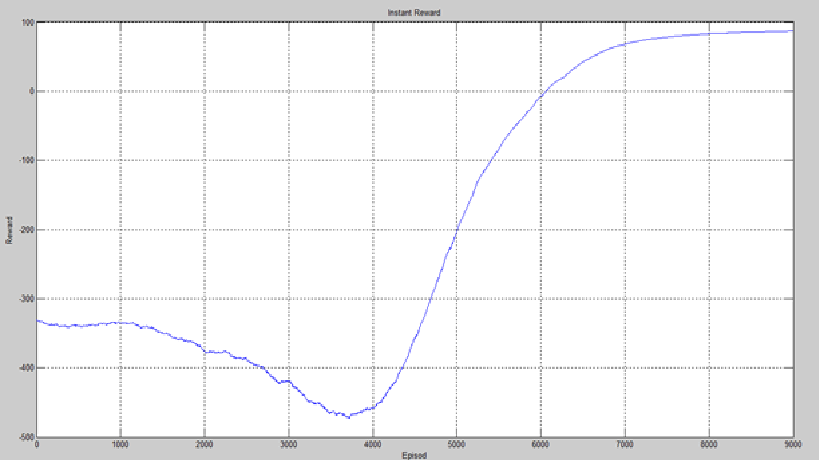
لازم به ذکر است به دلیل اینکه حالت آغازین هر بخش به صورت تصادفی انتخاب می شود و همچنین در انتخاب اعمال نیز عامل شانس دخیل است، بعضی اوقات (به ندرت) این الگوریتمها در مدت زمان زندگی محدود (10000 اپیزود) به جواب مناسبی نمیرسند. نمودارها حاصل اجرای 5 بار یادگیری است که با استفاده از یک پنجره به طول 1000 smooth شده اند.
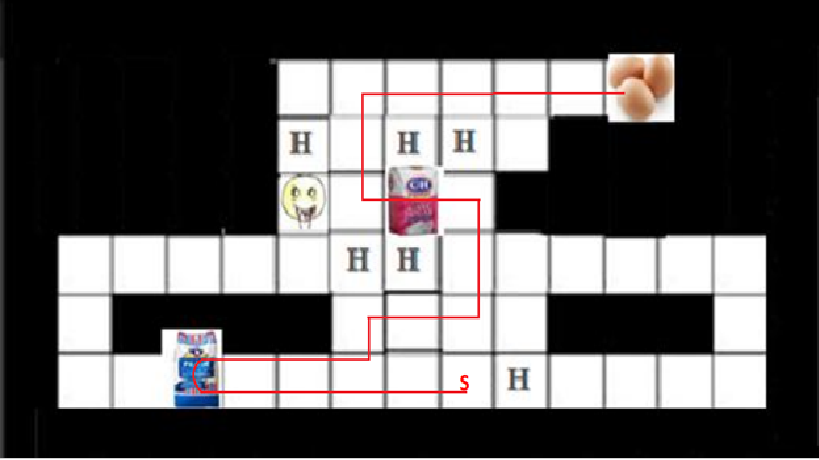
مسیر طی شده عامل از نقطه شروع تا انتهای بخش با استفاده از روش سارسا در شکل زیر آمده است . عامل در خانه ستاره دار یک بار توقف داشته است.
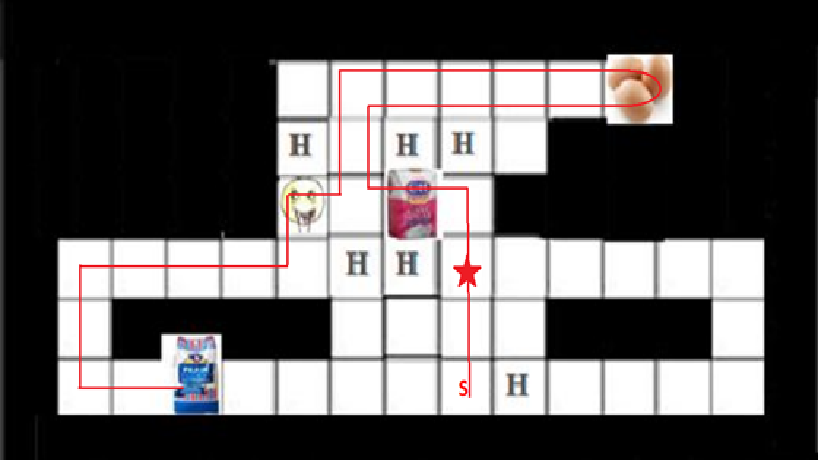
همچنین میانگین پاداش لحظه ای در 5 بار اجرای این روش مطابق نمودار زیر است:
روش Q-learning
تمامی ملاحضات انجام شده برای روش سارسا در اینجا تکرار شده است . زمان اجرای این الگوریتم برابر 115 ثانیه شد که سریعتر از سارسا میباشد. همچنین بهترین مسیر یافت شده در 10000 اپیزود و نمودار پاداش لحظه ای به صورت زیر میباشد:
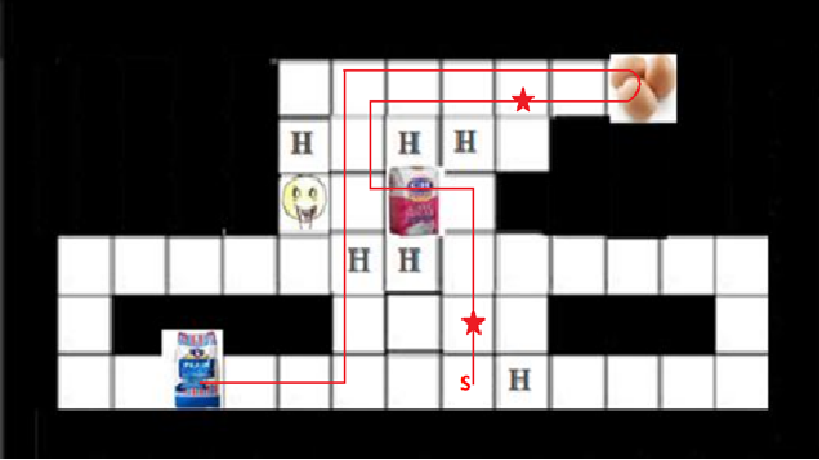
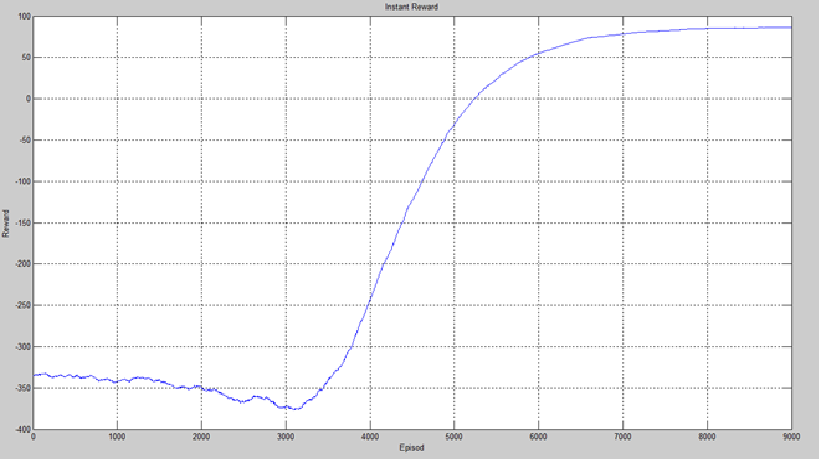
نتیجه گیری
حقیقت امر این است که راه بهینه که در شکل زیر آمده است ، از هیچ کدام از این دو روش پیدا نشده است ، پس باید با مقایسه پارامتر های این دو روش به آن ها امتیاز دهیم :
در تحلیل کلی این دو روش میتوان گفت SARSA مقدار Regret کمتری نسبت به Q-Learning دارد ولی همگرایی آن به میزان قابل توجهی دیرتر از Q-Learning اتفاق می افتد. در این مساله به دلیل اینکه شبیه سازی یک محیط است و در آن ذاتا regret اهمیت فراوانی ندارد، الگوریتم Q-Learning پیشنهاد میگردد.
اختلاف اصلی روش سار سا با روش کیو لرنینگ در سرعت همگرائی و پاسخ آنها می باشد. روش Q-Learning زودتر جواب میدهد ولی regret بیشتری دارد. SARSA مقدار regret مناسبی دارد ولی دیرتر همگرا می گردد. (در حدود اپیزود 8500). در نهایت و جمع بندی کلی بنده برای مسائلی شبیه به این مساله Q-Learning را بیشتر ترجیح میدهم.
میتوانید کد برنامه را از لینک زیر دریافت کنید :

مراجع
محمد غضنفری، "بهبود عملکرد عامل شبیهسازی فوتبال دوبعدی با استفاده از یادگیری تقویتی "، پایاننامه کارشناسی، دانشگاه علم و صنعت ایران، ۱۳۹2. لینک
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. Cambridge, United States of America: MIT Press, 1998.
F. S. Melo and M. I. Ribeiro, "Q-learning with linear function approximation," pp. 602-607, Mar. 2007.
a href = "">Q-learning >>