یکی از پیشنیازهای اصلی برای حل بسیاری از مسائل موجود در حوزه پردازش زبان طبیعی، وجود تحلیل نحوی از جملات زبان است. برای رسیدن به این هدف دو رویکرد متفاوت وجود دارد:
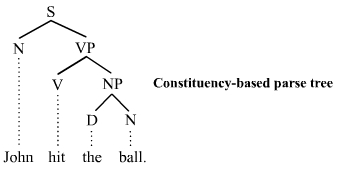
دستور زایشی: ابتدا جمله را به دو بخش نهاد و گزاره تقسیم میشود و در ادامه به صورت بازگشتی کار تقسیم را تا رسیدن به واژههای جمله ادامه میدهد.
دستور وابستگی: وظیفه تجزیه جمله را از فعل اصلی جمله آغاز می کند و در گام اول وابستههای مستقیم فعل و در ادامه به صورت بازگشتی وابستههای سطح بعدی را تا تحلیل کامل جمله ادامه میدهد.
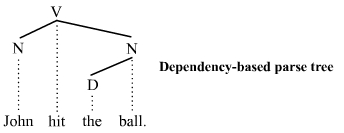
تجزیه وابستگی برای تحلیل زبانهایی مثل فارسی که ترتیب واژگان در آنها ثابت نیستند بهتر است. یکی از الگوریتمهای تجزیه وابستگی که بر روی زبان فارسی دقت بالایی دارد و در عین حال پیادهسازی آن ساده است الگوریتم کاوینگتون است. تلاشهایی برای بهبود این الگوریتم نیز صورت گرفته است مثل + و +.
در این پژوهش از شما خواسته شده است که الگوریتم کاوینگتون را پیادهسازی کرده و تلاش کنید دقت آن را بر روی زبان فارسی بهبود بخشید.
مقدمه
کارهای مرتبط
آزمایشها
کارهای آینده
مراجع
[1] م. خلاش، "بررسی روشهای تجزیه در دستور وابستگی"، سمینار کارشناسی ارشد ، دانشگاه علم و صعت ایران، 1390. لینک
[2] م. خلاش، "ساز و کاری برای کشف تأثیر ویژگیهای مختلف ساختواژی و صرفی بر روی تجزیة وابستگی زبان فارسی"، پایاننامه کارشناسی اشد، دانشکده مهندسی کامپیوتر، دانشگاه علم و صنعت، 1391. لینک
[3] Kubler, S., McDonald, R., & Nivre, J. "Dependency parsing", Synthesis Lectures on Human Language Technologies, Vol. 1, pp. 1–127, 2009.
[4] Khallash, M., Hadian, A., & Minaei-Bidgoli, B. "An Empirical Study on the Effect of Morphological and Lexical Features in Persian Dependency Parsing". In Proceedings of the Fourth Workshop on Statistical Parsing of Morphologically Rich Languages, pp. 97–107, 2013.