خوشهبندی به فرآیند تبدیل حجم عظیمی از دادهها به گروههای دادهای مشابه گفته میشود. به همین صورت خوشهبندی متون عبارت است از تبدیل حجم عظیمی از اسناد متنی به گروههایی از متنهای مشابه؛ که به هر کدام از این گروهها یک خوشه گفته میشود. پس مسئله خوشهبندی آیات قرآن را نیز میتوان به صورت گروهبندی آیات قرآن به صورت خودکار در گروه آیههای هممعنی معرفی نمود. برای درک این رابطهی شباهت معنایی بین آیات میتوان از روشهای مختلفی از جمله شباهتیابی بر مبنای واژههای آیه، واژههای ترجمه، تفسیر آیه و ... استفاده نمود.
در این پروژه شما باید آیات قرآن را با استفاده از ظاهر آیات به همراه ترجمه و تفسیر آنها خوشهبندی کنید.
۱. مقدمه
با توجه به گسترش روز افزون داده ها و دشوار شدن پردازش اطلاعات توسط انسان و نیاز به دسترسی سریع به منابع مهم و مورد علاقه به لزوم استفاده از ماشین- ها و وجود روش هایی قوی برای پردازش اطلاعات در این زمینه پی برده شد. در همین راستا ارائه ی ابزارهایی که با بررسی متون بتوانند تحلیلی روی آنها انجام دهند باعث شکل گیری زمینهای جدید در هوش مصنوعی به نام یادگیری متن گردید. این حوزه شامل تمام فعالیت هایی که به نوعی به دنبال کسب دانش از متن هستند ( مثل آنالیز داده های متنی توسط تکنیکهای یادگیری ماشین، بازیابی اطلاعات هوشمند، پردازش زبان طبیعی یا روشهای مرتبط دیگر) می شود. یکی از تکنیکهای یادگیری ماشین در زمینه پردازش متن استخراج الگوهای موجود در بین مجموعه داده های بزرگ است که داده کاوی نام دارد. استفاده از داده کاوی در مورد متن شاخه ای به نام متن کاوی را در علوم هوش مصنوعی بوجود آورد. از جمله فعالیتهای بسیار مهم در این زمینه، خوشه بندی متن میباشد.
خوشه بندی داده ها را به گروه هایی تقسیم می کند که با معنا و کارا هستند. خوشه ها باید به گونه ای باشند که ماهیت داده ها را حفظ کنند و تمام ویژگی های آنها را داشته باشند. هدف این است که داده های داخل خوشه حداکثر شباهت را با هم و حداقل شباهت را با داده های سایر خوشه ها داشته باشند. داده ها را به شکل های متفاوت می توان خوشه بندی کرد و به طور قطع نمی توان گفت که کدام نوع از خوشه بندی بهترین نوع است زیرا تعریف خوشه بندی یک تعریف نادقیق1 است. بهترین خوشه بندی را نتیجه مورد انتظار ما و ماهیت داده ها مشخص می کند[1].
از جمله کاربردهای خوشه بندی می توان به یافتن سند های مشابه، سازماندهی مجموعه های عظیم سند، سیستم پیشنهاد دهنده، تشخیص محتوای تکراری و تقلب و بهینه سازی جست و جو اشاره کرد[2].
قرآن کریم کتاب مرجع بیش از 1.6 میلیارد مسلمان سرتاسر جهان است و استخراج دانش و اطلاعات از آن مختص گروه خاصی از مردم نیست. قرآن طیف گسترده ای از موضوعات و قوانین زندگی را پوشش می دهد اما هر موضوعی توسط مجموعه ای از آیات و سوره های متوالی پوشش نمی یابد و یک سوره (حتی یک آیه) معمولا به موضوعات مختلفی می پردازد، از این رو خوشه بندی آیات قرآن برای دسترسی بهتر به موضوعات مختلف مورد نیاز بشر انجام می شود.
۲. کارهای مرتبط
برای قابل فهم کردن اسناد برای ماشین از مدل های نمایش بردار از قبیل مدل فضای برداری، مدلIDF-TF 2 ، مدل گراف و مدل های احتمالی استفاده می شود[3].
مرحله ی بعد مرحله ی پیش پردازش متن است، در این مرحله روی داده های ورودی عملیاتی (مثل حذف بعضی کلمات و یا تغییر شکل آنها) انجام می شود تا به صورتی درآیند که برای پردازش مناسب تر باشند. از خروجی این مرحله که مجموعه ای از کلمات است در مدل فضای برداری استفاده می شود.

فیلتر کردن:
حذف کلماتی که اطلاعات مفیدی درباره ی متن ندارند. در مورد آیات قرآن این مرحله شامل حذف حرکات از کلمات است. چرا که برای خوشه بندی و مدل سازی کلمه ی «الرَّحمنِ»با کلمه ی «الرحمن» تفاوتی ندارد و حرکات تمایزی بین معنای کلمات ایجاد نمی کنند.نرمال سازی:
یکی از مشکلات زبان عربی که خصوصاً در رسم الخط قرآن بسیار به چشم می خورد شیوه های مختلف نوشتن یک کلمه است. مثلاً نگارش همزه در این زبان چندین شکل مختلف دارد (ئ، أ، ؤ، ء) که در مواقع مختلف و با توجه به حرکتی که روی آن قرار گرفته از یکی از آن ها استفاده می شود در مرحله ی نرمال سازی این گونه موارد به یک شکل تبدیل می شوند.ریشه یابی:
در این مرحله، ریشه ی کلمات استخراج می شوند و برای عملیات خوشه بندی و مدل سازی از ریشه ی کلمه به جای خود کلمه استفاده می شود تا نتایج دقیق تری حاصل شود. برای مثال کلمات «الرحمن»، «الرحیم»، «رحمه»هر سه از ریشه ی «رحم» هستند و باید در یک موضوع قرار گیرند. الگوریتم های ریشه یابی برای زبان های مختلف یکسان نیستند و کاملاً بستگی به زبان دارند. این الگوریتم ها را می توانیم با توجه به نحوه ی عملکرد و میزان دقت آن ها در دسته های جداگانـه طبقه بندی کنیم. این دسته ها را در ادامه بیان می کنیم.
1-3. ریشه یاب جدولی:
ساده ترین روشی که برای ریشه یابی به نظر می رسد، نگهداری ریشه ی هر واژه در یک جدول است. در این روش با جستجوی واژه در این جدول،ریشه ی واژه مشخص می گردد. هر چند از این روش می توان نتـایج خوبی گرفت. اما نگهداری این جدول سربار زیادی برای سیستم دارد و محدود به کلمات از پیش تعیین شده هستیم.
2-3. ریشه یابی بر اساس حالت متناهی:
ریخت شناسی بر اساس مدل حالت متناهی، روش متداولی است. اساس کار آنها بر یک مدل زبان جهانی است. تعریف الگو بر اساس عبارات منظم انجام می شود و پیاده سازی آن بر اساس مدل ماشین حالت متناهی است. در طراحی پردازشگر ریخت شناسی حالت متناهی را می توان به دو بخش مجزا تقسیم کرد.
بخش مربوط به طـرح زبانی و بخش مربوط به طرح رایانه ای. منظور از طرح زبانی، ارائه ی توصیف نظری جامع و کامـل و مانع از ریخت شناسی افعال در زبان فارسی است. ارائه ی توصیف جامع از ریخت شناسی در زبان فارسی به گونه ای که قابل کاربرد در برنامه های رایانه ای باشد، نخستین گام جهـت طراحی برنامـه هـای کـاربردی است. این توصیف می بایست تمام صورت های تصریفی فعل در زبان فارسی را ارائه دهد. بخش دوم طرح رایانه ای است در این بخش نیاز های سخت افزاری و نرم افزاری پردازشگر تعریف می شود.
3-3. ریشه یابی به وسیله ی الگوریتم پورتر
روش پورتر یک روش توانمند و در عین حال یکی از قدیمی ترین روش های ریشه یابی در زبان انگلیسی است. این روش بر پایه ی زبان شناسی و دسته بندی کلمه ها به کمک واج ها و هجاها بنا نهاده شده است. پس از آن وندهای کلمات درون گردایه به طور خودکار برداشته می شوند.
دسته های دیگر از کارها شامل الگوریتم های ریشه یابی هستند که بر اساس قوانین ریخت شناسی زبان مربوطه کار می کنند. در این الگوریتم ها، برنامه از درون ساختاری تصمیم گیرنده مانند یک فلوچارت عبور کرده و با افزودن و کاستن وندها با رعایت قواعد املایی و دستوری، سعی در یافتن ریشه ی کلمات یا به طور خاص، افعال دارد. این کارها عمدتا مشابه الگوریتم پورتر هستند که برای زبان انگلیسی طراحی شده است. مشکل این دسته از الگوریتم ها برای کلمات جدا از هم است. با توجه به اینکه در فارسی مرز دقیق کلمات مشخص نیست برای کلماد چندپاره این روش ها خوب عمل نمی کنند. در یک سیستم ساده ی مبتنی بر قانون برای افعال فارسی ارائه شده است.حذف کلمات توقف:
کلمه ی توقف 3 به کلمه ای گفته می شود که به تنهایی معنای خاصی را نمی رساند و در واقع در مدل فضای برداری اطلاعات مفیدی در اختیار نمی گذارد. معمول ترین روش برای حذف کلمات توقف مقایسه ی مجموعه کلمات متن با مجموعه ی مشخصی از کلمات توقف است. معمولاً لیستی از کلمات توقف برای زبان های مختلف موجود است.

نمونه ای از کلمات توقف در قرآن به همراه مقدار تکرار آنها
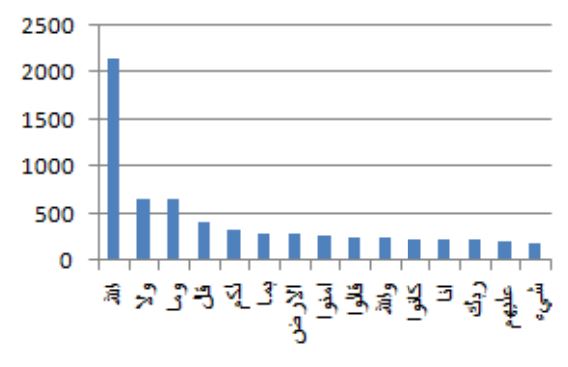
15 کلمه ی بیشتر تکرار شده در قرآن بعد از نرمال کردن و حذف کلمات توقف هرس کردن:
در این مرحله کلماتی که تکرار آن ها در مجموعه ی اسناد بسیار کم است را حذف می کنند. ایده ی این کار آن است که این کلمات حتی اگر برای تمایز خوشه ها قدرت زیادی داشته باشند، تنها به ساخت تعداد کمی از خوشه ها کمک می کنند. در بعضی موارد کلماتی که بسیار تکرار شده باشند را هم حذف می کنند.کاهش ابعاد 4 :
داده های با ابعاد زیاد باعث پیچیدگی محاسبات خواهند شد. در طول خوشه بندی N سند ممکن است M خصوصیت مختلف را در نظر بگیریم درحالی که M>>N؛ اما مسئله اینجاست که ممکن است نیازی به بررسی این تعداد خصوصیت نباشد و در نتیجه ابعاد را کاهش می دهیم. درصورتی که کاهش ابعاد در یک فرایند با ناظر انجام پذیرد، به آن انتخاب خصوصیات می گوییم. در این فرایند، ناظر خصوصیاتی را که معیارهای مشخصی داشته باشد انتخاب می کند. در حالت دیگر استفاده از یک فرایند بدون ناظر است. به این فرایند استخراج خصوصیات گفته می شود. استخراج خصوصیات طی یک تبدیل از فضای M-بعدی به یک فضای K-بعدی صورت می پذیرد که K<M. این تبدیل می تواند هم به صورت خطی و هم به صورت غیرخطی انجام شود. تحلیل اجزای اصلی و تجزیه ی مقادیر منحصر به فرد از جمله روش های کاهش ابعاد هستند[3].
در مرحله ی بعد به خوشه بندی مطالب می رسیم
روشهای خوشهبندی
روشهای خوشهبندی را میتوان از چندین جنبه تقسیمبندی کرد:خوشهبندی انحصاری 5 و خوشهبندی با همپوشی 6 :
در روش خوشهبندی انحصاری پس از خوشهبندی هر داده دقیقأ به یک خوشه تعلق میگیرد (مانند روش خوشهبندی K-Means). ولی در خوشهبندی با همپوشی پس از خوشهبندی به هر داده یک درجه تعلق به ازای هر خوشه نسبت داده میشود. به عبارتی یک داده میتواند با نسبتهای متفاوتی به چندین خوشه تعلق داشته باشد. (نمونهای از آن خوشهبندی فازی است.)خوشهبندی سلسله مراتبی 7 و خوشهبندی مسطح 8 :
در روش خوشه بندی سلسله مراتبی، به خوشههای نهایی بر اساس میزان عمومیت آنها ساختاری سلسله مراتبی نسبت داده میشود. (مانند روش Single Link). ولی در خوشهبندی مسطح تمامی خوشههای نهایی دارای یک میزان عمومیت هستند (مانند K-Means). به ساختار سلسله مراتبی حاصل از روشهای خوشهبندی سلسله مراتبی دندوگرام 9 گفته میشود.
با توجه با اینکه روشهای خوشهبندی سلسله مراتبی اطلاعات بیشتر و دقیقتری تولید میکنند برای تحلیل دادههای با جزئیات پیشنهاد میشوند ولی از طرفی چون پیچیدگی محاسباتی بالایی دارند برای مجموعه دادههای بزرگ روشهای خوشهبندی مسطح پیشنهاد میشوند.
پارامترtf-idf
یکی از پرکاربردترین روابط در حوزه بازیابی اطلاعات، پارامتر tf-idf است، کـه از حاصـل ضـرب فراوانی کلمه در فراوانی معکوس سند به دست می آید. این روش یک روش مبتنی بر چند سند می باشد،که در آن منظور از فراوانی کلمه، فقط تعداد تکرار کلمه در یک سند خاص اسـت. هـمچنـین منظـور از فراوانی معکوس سند، تعداد اسنادی است که این کلمـه خـاص در آن اسـناد ظـاهر شـده اسـت. دلیـل مقبولیت این روش نسبت به سایر روش ها را مـی تـوان بـا توجـه بـه سـهولت در اسـتفاده از ایـن روش،محاسبات کم و نتایج قابل قبول دانست


۳. آزمایشها
برای خوشه بندی آیات قرآن از مدل فضای برداری TF-IDF و الگوریتم K-Means استفاده می کنیم. برای انجام خوشه بندی به صورت همزمان برای آیات و ترجمه ی آن ها نیاز داریم تا ترجمه ی آیات را نیز به داده های آموزشی اضافه کنیم. این عمل را با خواندن ترجمه ی آیات از داخل فایل ترجمه و سپس پیش پردازش و حذف کلمات توقف و ریشه یابی کلمات ترجمه انجام می دهیم. پس از آن ماتریس TF-IDF را این بار برای ترجمه ی آیات محاسبه می کنیم و مقادیر این ماتریس را به صورت ستون های اضافی به ماتریس TF-IDFحاصل از متن عربی آیات اضافه می کنیم در واقع با این عمل به تعداد ویژگی های نمونه های آموزشی اضافه می کنیم. پس از این مرحله الگوریتم خوشه بندی را بر روی ماتریس حاصل اجرا می کنیم.
در ابتدا متن قرآن و ترجمه ی آن کنار هم گذاشته شد

برای شروع آیات قرآن پیش پردازش می شوند و این داده ی پردازش شده به عنوان ویژگی آن آیه در نظر گرفته می شود. داده ها باید در فضای برداری مدل شوند که بهترین فضا، فضای TF-IDF است.بعد سعی می کنیم تا با روش های موجود ابعاد ماتریس TF-IDF را کاهش دهیم و اطلاعات اضافی را پاک کنیم. برای خوشه بندی آیات قرآن بهترین الگوریتم K-Means است.
می توانید کد را در قسمت پیوندها ببینید
۴. کارهای آینده
1- استفاده از تفسیر آیات در کنار متن و ترجمه ی آنها
2- استفاده از ابزاری قوی تر برای پردازش زبان عربی
3- استفاده از تفاسیر و ترجمه های مختلف و مقایسه ی نتایج
4- استفاده از وش جدید وزن دهی ذکر شده در مقاله ی ششم
5- استفاده از روش جدید وزن دهی ذکر شده در مقاله ی هفتم که در آن اثر ترکیب وزن دار خوشه بندی ها و اثر روش های وزن دهی ویژگی ها بررسی شده. در این پایان نامه چـارچوب جدیدی برای بهبـود کارایی خوشه بندی ترکیبی پیشنهاد شده که مبتنی بر استفاده ی وزن دار خوشه های اولیه علاوه بر استفاده از روشی جهت وزن دهی ویژگی ها برای هر خوشه نیز هستند.
6- برچسب گذاری اطلاعات در مرحله ی پیش پردازش به کمک مقاله ی سوم
7- استفاده از خوشه بندی ترکیبی به کمک مقاله ی نهم و دهم
۵. مراجع
[1] م.ایمانی، خوشهبندی متون فارسی، پایاننامه کارشناسی، دانشگاه علم و صنعت ایران، ۱۳۹۱ دریافت
[2]م.رحیمی بافقی، م.پورباقری، خوشهبندی آیات قرآن، پایاننامه کارشناسی، دانشگاه علم و صنعت ایران، ۱۳۹۳
[3]پ.پاسبان، بررسی ارتباط خوشه بندی متون با برچسب های پردازش زبان طبیعی، سمینار کارشناسی ارشد، دانشگاه علم و صنعت ایران،۱۳۸۹
[4]Akour, Mohammed; Alsmadi, Izzat; and Alazzam, Iyad. (2014). "MQVC: Measuring Quranic Verses Similarity and Sura Classification Using N-Gram".WSEAS Transactions on Computers, 13, 485-491.
[5]Muazzam Ahmed Siddiqui,Syed Muhammad Faraz,Sohail Abdul Sattar,Discovering the Thematic Structure of theQuran using Probabilistic Topic Model model,2013
[6]مینا ملکی، احمد عبداالله زاده بارفروش،TFCRF:روش جدید وزن دهی ویژگی مبتنی بر اطلاعات کلاس در حوزه طبقه بندی مستندات، دانشگاه شهید بهشتی،1385
[7]حمید پروین، خوشه بندی ترکیبی با وزن دهی توام خوشه ها و ویژگی ها، رساله دکترا، دانشگاه علم و صنعت ایران، 1392
[8]محسن عمویی، بهینه سازی, خوشه بندی و تشخیص مفهوم جملات و حذف کلمات ناشایست در متون فارسی با استفاده از ابزارهای پردازش زبان طبیعیNLTK و HAZM، پایان نامه کارشناسی، دانشگاه علم و صنعت ایران، 1394
[9]حسین علیزاده، خوشه بندی ترکیبی، سمینار کارشناسی ارشد، دانشگاه علم و صنعت ایران، 1385
[10] حسین علیزاده، خوشه بندی ترکیبی مبتنی بر زیر مجموعه ای از نتایج اولیه، پایان نامه کارشناسی ارشد، دانشگاه علم و صنعت ایران، 1387
[11] Abdul-Baquee M. Sharaf, The Qur'an Annotationfor Text Mining, School of Computing, 2009
[12]Mohammad Alhawarat, Mohamed Hegazi, Anwer Hilal, Processing the Text of the Holy Quran:a Text Mining Study, Salman Bin Abdulaziz University, 2015
[13]Karlheinz Mörth, Claudia Resch, Ulrike Czeitschner, Thierry Declerck, Linguistic and Semantic Annotation inReligious Memento mori Literature, workshop, 2012
پیوندهای مفید
imprecise
Term Frequency-Inverse Document Frequency
Stop Word
Dimension Reduction
Exclusive or Hard Clustering
Overlapping or Soft Clustering
Hierarchical
Flat
Dendogram