تشخیص چهره (Face Detection) یا همان پیدا کردن چهره در تصویر تکنولوژی در کامپیوتر است که در بسیاری از برنامه هایی که با (Computer Visual) سر و کار دارند استفاده می شود. تشخیص چهره همچنین به فرایند روان شناختی ای که توسط آن انسان ها چهره ها را تشخیص می دهند و به آن در یک صحنه ی بصری می پردازند.

۱. مقدمه
تشخیص چهره حالتی خاص از مساله ی بزرگ تر خود یعنی تشخیص اشیا موجود در تصاویر است. در تشخیص اشیا مربوط به یک کلاس، مساله پیدا کردن مکان و اندازه ی همه ی اشیا مربوط به کلاس داده شده است. به عنوان مثال: پیدا کردن علایم و تابلو های راهنمایی و رانندگی، ماشین ها و پلاک هایشان و ... .
که چهره، کلاسی خاص از اشیا است.
الگوریتم های تشخیص چهره بر روی تشخیص چهره ی انسان از رو به رو تمرکز می کند. طریقه ی کار کرد آن بر اساس تطبیق دادن عکس داده شده با عکس های ذخیره شده در پایگاه داده (Database) است. هر گونه تغییر در ویژگی ها و شاخصه های تشخیص چهره که در Database ذخیره شده، فرایند تشخیص چهره را نا معتبر می کند.
حل کردن مساله ی Face Detection کاربرد ها ی متعدد و مهمی در زمینه ی Computer Visual دارد که در موارد زیر به آن ها اشاره خواهیم کرد:
`
عکاسی (Photography):
تکنولوژی تشخیص چهره در دوربین های عکاسی به عنوان راهکاری برای Auto Focus روی چهره ی افراد بسیار رایج است. حتی در جدید ترین تلفون همراه Apple که با نام iPhone X به بازار تلفون های همراه عرضه شد از فناوری Face Detection برای حالت Portrait Mode خود به بهترین شکل استفاده
می کند به گونه ای که چهره ی انسان را تشخیص داده و Background را Blur یا تار می کند تا صورت انسان برجسته تر به نظر بیاید.
کاربرد دیگر آن استفاده از تشخیص لبخند (Smile Recognition) است که افراد به کمک آن در بهترین زمان ممکن که لبخند فرد مقابل در بهترین حالت خود است از او عکس بگیرند.

باز شناسی چهره (Face Recognition):
تشخیص چهره پایه و اساس مساله ی Face Recognition است که خود مساله ای حایز اهمیت در زمینه ی امنیت است. برای شناسایی چهره ابتدا باید چهره را پیدا کرد سپس چهره ی پیدا شده را با چهره های موجود در Database تطبیق داد. Face Recognition برای افزایش امنیت در app ها و گوشی ها هست که به عنوان مثال Apple به تازگی از Face Recognition با نام Face ID در جدید ترین گوشی همراه خود یعنی iPhone X استفاده کرده، Samsung و بقیه شرکت ها نیز به تازگی از این فناوری در تلفون های همراه خود استفاده کرده اند. Face Recognition در فرودگاه ها و سایر مکان های مهم کاربرد دارد تا بتوان مجرمان را شناسایی و بازداشت کرد.

شمارش افراد و بازاریابی(Marketing):
فناوری Face Detection به تازگی نظر بازاریاب ها را به خود جلب کرده به گونه ای که می توان دوربینی در تلویزیون به کار برد تا چهره ی هر انسانی که از کنار آن عبور می کند را تشخیص دهد و سن، جنسیت و نژاد او را محاسبه کند و نمایشگر تبلیغات متناسب با ویژگی های تشخیص داده شده را برای فرد در حال عبور به نمایش بگذارد.
Usage of Face Detection in Marketing
ضبط حرکت صورت(Facial Motion Capture):
روندی است که در آن حرکت چهره ی افراد را به صورت الکترونیکی با استفاده از اسکنر های لیزری یا دوربین به یک Database تبدیل می کند که از Database ایجاد شده برای درست کردن Computer Graphics یا همان CG برای انیمیشن بازی ها و فیلم های کامپیوتری به کار می رود. حرکت شخصیت های CG بر اساس حرکت انسان های واقعی نشات گرفته که منجر به واقعی تر و منحصر به فرد شدن شخصیت ها نسبت به زمانی که انیمیشن ها دستی ساخته شوند می شود.
۲. کارهای مرتبط
برای حل کردن مساله ی پیدا کردن چهره در تصویر الگوریتم های زیادی وجود دارند که در این بخش به رایج ترین و معروف ترین آن ها اشاره خواهد شد:
۲.۱. پیدا کردن تصاویر در پس زمینه ی کنترل شده:
این روش، روشی آسان و نه چندان قوی است که در آن از تصاویر با پس زمینه ی تک رنگ ساده یا پس زمینه ی ایستای از قبل تعریف شده استفاده می شود. از بین بردن پس زمینه همیشه مرزهای چهره یا صورت را به ما می دهد، که باقی آن ساده است:
پیدا کردن چهره با رنگ:
اگر تصویر داده شده رنگی باشد، می توان از رنگ پوست معمولی برای پیدا کردن بخش های صورت استفاده کرد.
اشکال عمده ی این الگوریتم: با تمام رنگ های پوست کار نمی کند و در شرایط نور دهی متنوع خیلی قوی نیست.
در این روش به مقاله ی از Jay P. Kapur اشاره می کنیم که در آن حل این مساله از دو فرایند تشکیل شده که ابتدا نواحی ای را که احتمالا حاوی پوست انسان در تصاویر رنگی هستند، شناسایی می کند و سپس اطلاعاتی از این مناطق را که ممکن است محل چهره در تصویر را نشان دهد، استخراج می کند. تشخیص پوست انسان با استفاده از یک فیلتر پوست که بر اطلاعات رنگ و بافت تکیه دارد انجام می شود. تشخیص چهره نیز بر روی یک تصویر سیاه و سفید که تنها حاوی مناطقی است که در آن پوست انسان شناسایی شده انجام می شود.
`پیدا کردن چهره با حرکت:
اگر قادر باشیم از ویدیو بی درنگ استفاده کنیم، می توانیم از این حقیقت که چهره انسان دائما در واقعیت در حال حرکت است استفاده کنیم. فقط کافی است مکان های در حال حرکت را محاسبه کنیم تا چهره را تشخیص دهیم.
اشکال: اگر اشیا دیگری در پس زمینه در حال حرکت باشند چه می شود؟
یکی از روش های ارئه شده پیرامون این موضوع استفاده از سیستم تشخیص پلک زدن (Blink Detection) است. همان طور که می دانید چشمان انسان ها دائما در حال حرکت هستند پس از آن می توان برای تشخیص صورت استفاده کرد. در این روش چندین عکس پشت سر هم گرفته می شود و هر عکس دریافت شده از عکس قبلی کم میشود (یعنی تفاوت ها را مشخص می کند که این تفاوت مرزی کوچک در اطراف سر است) اگر در یکی از این تصاویر چشم ها بسته باشند مرزی دور چشم ایجاد می شود که نشان دهنده ی پلک زدن است.[1]
روش های ترکیبی نیز از دو الگوریتم های بالا ارائه داده شده که هم رنگ صورت را در نظر می گیرند هم حرکت چهره را که در
مقاله ی T. Darrell, G. Gordon, M. Harville and J. Woodfill به آن اشاره شده.[2]
۲.۲. پیدا کردن چهره در تصاویر بدون محدودیت:
این روش راهکار اصلی و همچنین پیچیده ترین روش در کل مساله ی تشخیص اشیا است. به عنوان مثال اگر تصویر ورودی یک تصویر سیاه و سفید باشد
(بدون هیچ رنگ پوست و حرکتی) حال چگونه می توان چهره ها را تشخیص داد؟ انسان ها قادر هستند این کار را به آسانی انجام دهند پس یک الگوریتم قوی باید برای آن درست شود که در ادامه به کارهایی که پیرامون این مساله انجام شده اشاره خواهد شد .
۲.۲.۱. ردیابی چهره مبتنی بر مدل:
به نظر می رسد که روش های مبتنی بر لبه با استفاده از مدل های هندسی احیا شده اند. دو روش برتر از لحاظ عملکرد که در اویل دهه ی ۲۰۰۰ ارائه شدند:
تشخیص چهره بی درنگ با استفاده از تطبیق لبه:
در این روش که در عکس های سیاه و سفید استفاده می شود لبه های عکس را پیدا کرده و از آن برای پیدا کردن چهره در تصویر استفاده می کنند.[3]
تشخیص چهره با استفاده از فاصله Hausdorff:
این روش نیز مبتنی بر لبه است و روی عکس های سیاه و سفید کار می کند. (Hausdorff Distance (HD یک متریک بین دو مجموعه نقطه است و چون قرار است برای پیدا کردن اشیا در تصاویر دیجیتال استفاده شود، HD به دو بعد محدود می شود. در این روش از HD برای پیدا کردن چهره یا کلا اشیا در تصویر به کار می رود. به عنوان مثال فرض کنید دو مجموعه نقطه ی A و B نمایانگر تصویر و شئ باشند بنابراین هر دو نقطه از این دو مجموعه یک Edge Point را تشکیل می دهد که به کمک این Edge Point ها می توان اشیا را در تصویر پیدا کرد. [4]
۲.۲.۲. ردیابی چهره بر اساس طبقه بندی آبشاری:
پیشرفت در پیدا کردن و شناسایی چهره با Viola & Jones رخ داد. این الگوریتم ارائه داده شده می تواند تعلیم داده شود که انواع اشیا را در تصویر پیدا کند اما اولین بار برای حل مساله ی تشخیص چهره ارائه شد.
ویژگی هایی که باعث شدند الگوریتم Viola-Jones یک الگوریتم تشخیص دهنده ی خوب شود:
قدرتمند بودن در تشخیص: نرخ تشخیص بالا و اشتباه خیلی کم.
بی درنگ بودن: برای کاربردهای عملی باید حداقل دو فریم (Frame) بر ثانیه پردازش شود.
فقط تشخیص چهره (نه بازشناسی چهره): هدف متمایز کردن چهره از غیر چهره در تصاویر است (همان طور که در مقدمه اشاره شد تشخیص چهره پایه و اساس Face Recognition است)
این الگوریتم چهار مرحله دارد:
انتخاب ویژگی Haar
ایجاد یک تصویر یکپارچه
آموزش و تعلیم (AdaBoost(Adaptive Boosting
طبقه بندی های آبشاری
ویژگی های Haar:
چهره ی تمام انسان ها دارای خواص مشابهی هستند که با Haar Features هماهنگ می شوند:
ناحیه چشم تیره تر از گونه های فوقانی است (شکل ۱)

شکل ۱ قسمت برآمدگی بینی از رنگ چشم ها روشن تر است (شکل ۲)

شکل ۲
ترکیب خواصی که ویژگی های همپوشانی صورت را تشکیل می دهند:
موقعیت و اندازه: چشم ها، بر آمدگی بینی و دهان
ارزش: شیب متمایل شدت پیکسل ها
سپس به دنبال این چهار ویژگی ذکر شده در بالا که توسط این الگوریتم تطبیق داده شده اند در یک تصویر چهره می گردیم. [5]
۲.۲.۳. یاد گیری عمیق و HOGs:
یاد گیری عمیق (با استفاده از شبکه های عصبی چند لایه)، مخصوصا بیشتر برای Face Recognition به کار می رود تا برای Face Detection،
و (HOG (Histogram of Oriented Gradients روش های کنونی (2017) برای حل مساله ی Face Recognition و Face Detection هستند.
۳. آزمایش ها:
۳.۱. طبقه بندی HAAR:
در این قسمت الگوریتم Viola & Jones که مبتنی بر ویژگی های Haar است پیاده سازی و آزمایش می شود. برای این کار از کتابخانه ی openCV که برای بینایی کامپیوتر است استفاده می شود.
۳.۱.۱. توضیحات:
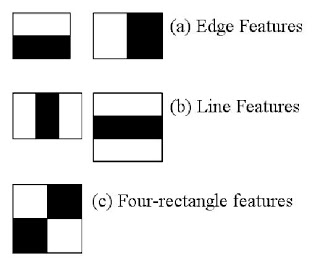
این رویکرد که مبتنی بر یادگیری ماشین است ، تابع آبشاری آن (Cascade Function) باید تحت یک سری تصاویر مثبت (Positive Images یا تصاویری که در آن چهره ی فرد وجود دارد ) و تصاویر منفی (Negative Images یا تصاویری که در آن چهره ی فرد وجود ندارد ) تعلیم داده شود سپس باید ویژگی های چهره از آن استخراج شود. برای این کار از ویژگی های Haar که در شکل ۳ نشان داده شده اند استفاده می شود.
هر ویژگی یک تک مقداری است که با تفریق کردن مجموع پیکسل های درون مستطیل سفید از مجموع پیکسل های درون مستطیل سیاه به دست می آید.
از بین تمامی ویژگی های به دست آمده بسیاری از آن ها نامرتبط هستند. به عنوان مثال در شکل ۴ ردیف بالا دو ویژگی خوب و مفید را نشان می دهد که اولی به نظر می رسد بر روی ناحیه ای از چهره متمرکز است که در آن معمولا چشم ها تاریک تر از گونه و بینی هستند و دومی بر روی ناحیه ای متمرکز است که پل بینی (همان وسط بینی) از چشم ها روشن تر هستند. برخی از ویژگی های به دست آمده مفید نیستند مثلا اگر همین ناحیه ی ذکر شده روی گونه ها بود فایده ی چندانی نداشت و چون تعداد ویژگی های به دست آمده بسیار زیاد است (در یک چهارچوب ۲۴*۲۴، ۱۶۰۰۰۰ ویژگی وجود دارد) بهتر است بهترین آن ها را انتخاب و استفاده کرد. فرایند انتخاب کردن با کمک Adaboost ممکن می شود (تعداد ویژگی ها را از ۱۶۰۰۰۰ به ۶۰۰۰ ویژگی مفید کاهش می دهد).

در این الگوریتم از طبقه بندی آبشاری (Cascade Classifiers) استفاده می شود چون چک کردن ۶۰۰۰ ویژگی برای این که مشخص شود چهره است یا
خیر زمان زیادی می برد. طریقه ی کارکرد Cascade Classifiers به این گونه است که تعدادی از ویژگی ها را در مراحل متفاوتی از طبقه بندی ها دسته بندی می شود به این معنا که اگر قسمتی از تصویر از یک مرحله رد شد دیگر سایر ویژگی ها روی آن چک نمی شوند و سراغ قسمت دیگری از عکس رفته. قسمتی از عکس که از تمام مراحل عبور کند چهره ی انسان است.
۳.۱.۲. پیاده سازی و آزمایش:
توضیحات کد:
برای پیاده سازی از طبقه بندی Face Cascade برای تشخیص چهره ها که قبلا تعلیم داده شده در OpenCV استفاده می کنیم . از زبان Python 2.7 برای پیاده سازی استفاده می کنیم، چالش اصلی پیاده سازی نصب OpenCV بود که وقت گیر و همراه با تعدادی error بود.
ابتدا عکس گرفته شده از کاربر را سیاه و سفید می کند ( در کد زیر مشاهده شود )، همان طور که در قسمت توضیحات بیان شد عکس باید سیاه و سفید باشد تا ناحیه های روشن تر و تاریک تر مشخص شوند که بتوان ویژگی های Haar را روی آن اجرا کرد.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
سپس با استفاده از تابع detectMultiScale چهره ها را پیدا می کند و در یک لیستی از لیست ها که در هر کدام از آن ها (x, y, w, h) وجود دارند که x عرض چپ ترین و بالاترین نقطه ی چهره ی یافت شده است y نیز طول همان نقطه است و h, w نیز ابعاد صورت یافت شده اند. (مبدا مختصات بالا ترین و چپ ترین نقطه ی عکس می باشد )
نمونه ای از صورت های یافت شده که به صورت لیست هستند:
[[243 20 60 60]
[376 41 52 52]
[467 76 57 57]
[114 58 59 59]]
کد زیر مربوط به پیدا کردن چهره ها می باشد:
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30)
)
حال که مختصات چهره ها به دست آمد می توانیم کادری اطراف چهره های به دست آمده بکشیم:
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 1)
کد کامل و عکس های آزمایشی در github قرار دارند.
داده های مورد استفاده برای آزمایش:
برای آزمایش چند عکس مختلف که با دوربین های متفاوت از افراد در فاصله های مختلف عکس گرفتند، استفاده می کنیم تا کد را در شرایط متفاوت آزمایش کنیم و کارایی آن را بسنجیم. بیش از ۱۰ عکس برای آزمایش به کار برده شده ( نمونه هایی از مورد های تست شده در github وجود دارد ) که در زیر نمونه هایی از عکس های مورد آزمایش آورده شده:

نمونه ی دوم چالش بیشتری برای کد ایجاد می کند چون چند چهره در پیش زمینه قرار دارند و تار هستند.
برای آزمایش سعی می کنیم انواع عکس ها را امتحان کنیم تا مشخص شود الگوریتم در شرایط گوناگون چگونه عمل می کند.
نتایج آزمایش:
داده های داده شده را آزمایش می کنیم، برای اجرا شدن برنامه باید آن را در Terminal یا Command Prompt اجرا کرد و عکس مورد نظر را به عنوان آ رگومان به برنامه پاس می دهیم. نتیجه ی نمونه ی اول که در بخش بالا توضیح داده شد به صورت زیر می باشد:

همان طور که مشاهده می شود همه ی چهره ها به خوبی تشخیص داده شد و دقت ۱۰۰٪ داشت. تشخیص دادن چهره های موجود در عکس هایی همچون نمونه ی اول بسیار ساده هستند چون از فاصله مناسب گرفته شده، چهره ها از هم فاصله خوبی دارند و چهره ای که در پیش زمینه و تار باشد وجود ندارد همچنین تمامی چهره ها به یک فاصله از دوربین هستند.
حال نمونه ی دوم را که چالش بیشتری دارد اجرا میکنیم تا عملکرد الگوریتم مشخص شود:

این بار در ۱۱ چهره ی موجود در عکس ۶ چهره را به درستی تشخیص داد و یک جا را اشتباهی به عنوان چهره در نظر گرفت یکی از دلایل این اشتباه فاصله زیاد چهره ها از دوربین است که اگر مقیاس (Scale Factor) آن را تغییر دهیم این اشتباه درست می شود. دلیل تشخیص ندادن برخی چهره ها هم به دلیل بیش از حد تار بودن و زاویه ی بد صورت است به گونه ای که Haar classifier نمی تواند ویژگی های Haar را روی آن اجرا کند.
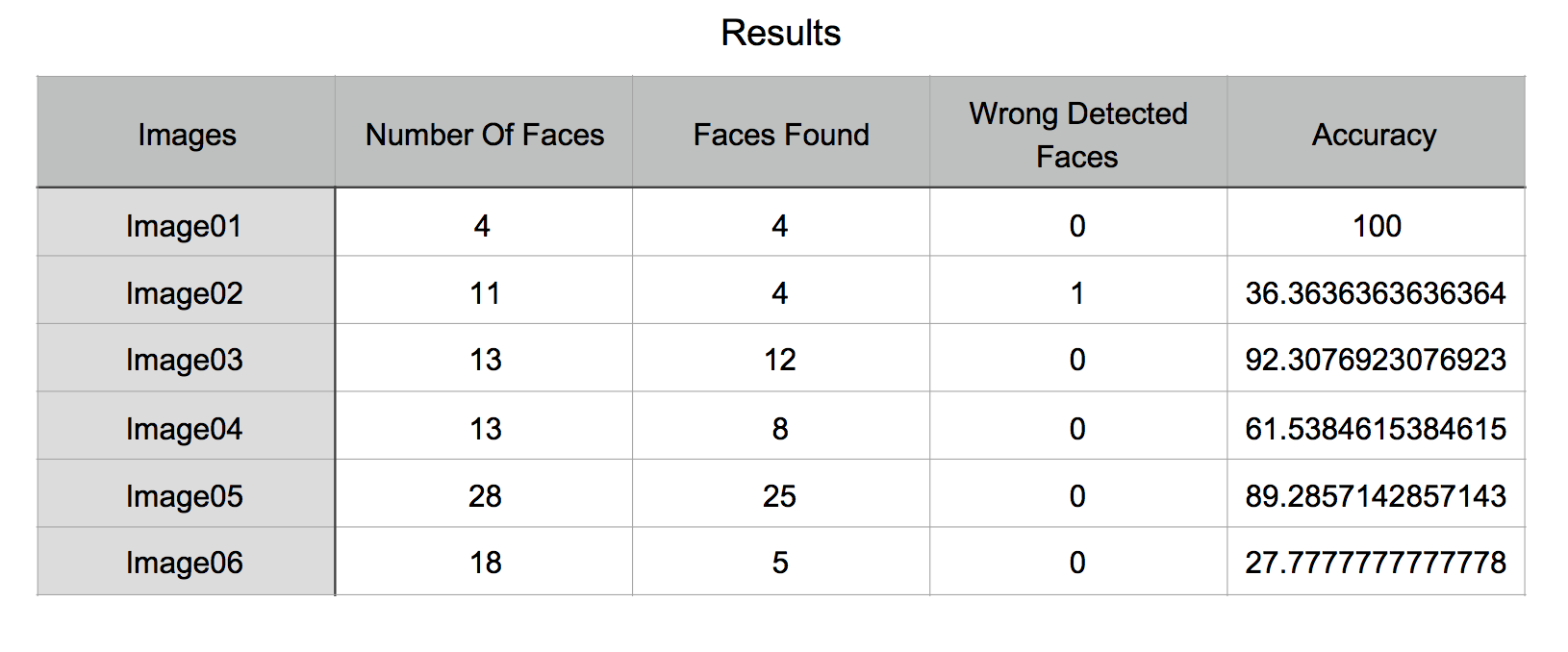
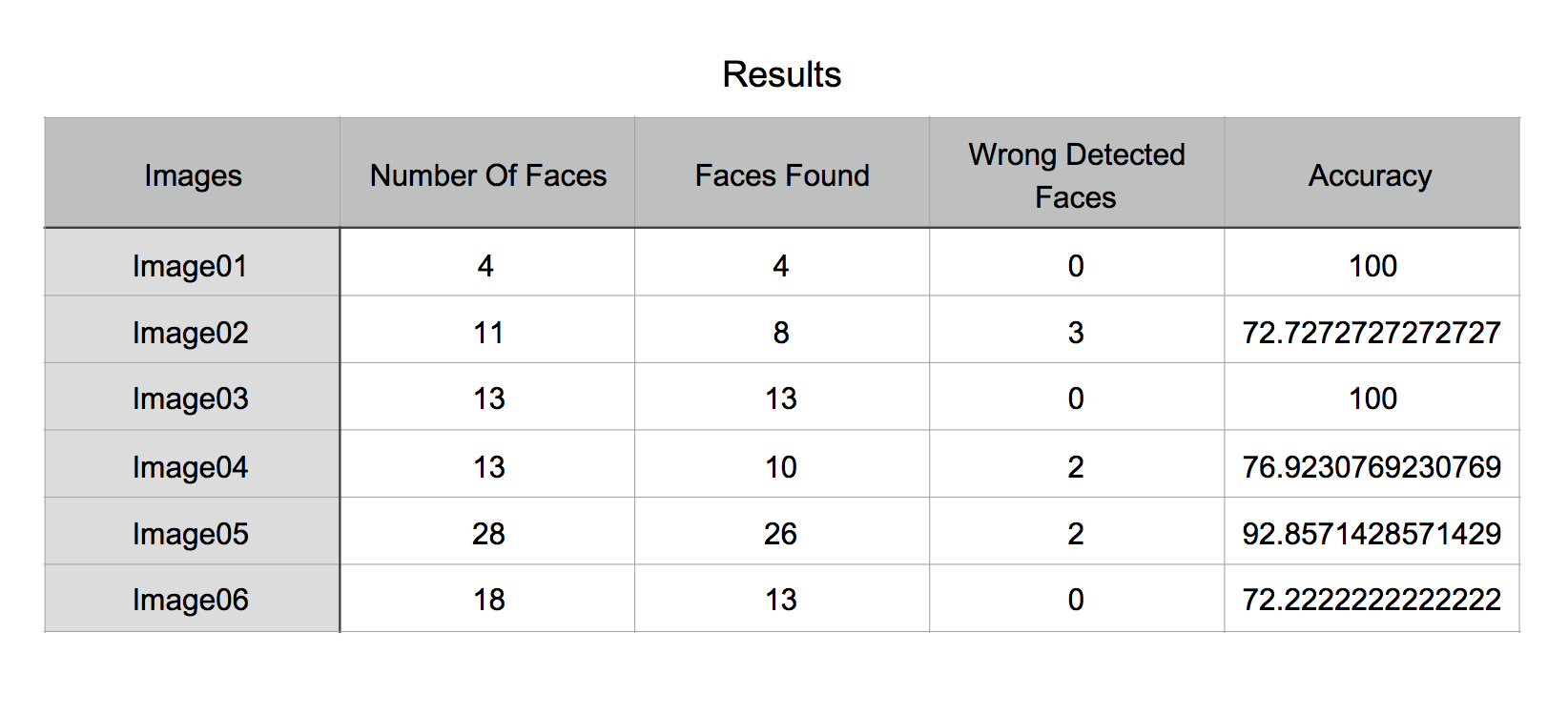
نتایج در جدول زیر آمده ( عکس های ۳ تا ۶ در github وجود دارند):

همان طور که مشاهده می شود دقت همه ی عکس ها از ۵۰ بیشتر است و عکسی که دارای چهره های تار در پیش زمینه بود بیشترین چالش را برای الگوریتم ایجاد کرد و الگوریتم کمترین دقت را داشت، عکس ها و نتایج آن ها که در جدول بالا ذکر شده به طور کامل در github وجود دارد. در این میان یک سری چهره اشتباهی تشخیص داده شده اند که همان طور که قبلا گفته شد به خاطر فاصله ی مختلف چهره ها از دوربین است. اگر چهره ها به صورت نیمه در تصویر وجود داشته باشند نمی توان ویژگی های Haar را روی آن ها پیاده کرد بنابراین به عنوان چهره تشخیص داده نمی شوند. (دقت الگوریتم درصد چهره های یافت شده به کل چهره های موجود تعریف شده)
۳.۲. طبقه بندی LBP:
۳.۲.۱. توضیحات:
مانند Haar Classifier، طبقه بندی LBP یا همان Local Binary Patterns نیز روی ۱۰۰ ها تصویر آموزش ببیند. LBP یک توصیفگر بافت است و چهره ها نیز از الگو های میکرو بصری تشکیل شده اند. بنابراین ویژگی های LBP برای شکل دهی بردار ویژگی که یک چهره را از غیر چهره جدا می کند استخراج می شوند.

همان طور که در شکل بالا دیده می شود LBP به پیکسل مرکزی هر بلوک ( یک پنجره ی 33) نگاه می کند سپس پیکسل مرکزی را با پیکسل های همسایه در همان پنجره ی ۳۳ مقایسه می کند. برای پیکسل های همسایه ای که مقدارشان بزرگتر مساوی پیکسل مرکزی است مقدارش را برابر یک قرار می دهد و مقدار بقیه را صفر.
در ادامه مقدار های تعیین شده را در جهت عقربه های ساعت می خواند و یک عدد دو دویی تشکیل می دهد و سپس عدد دو دویی را به عددی ده دهی تبدیل میکند و این عدد ده دهی به دست آمده مقدار جدیدی برای مرکز بلوک است. این روند برای تمامی بلوک ها تکرار می شود.

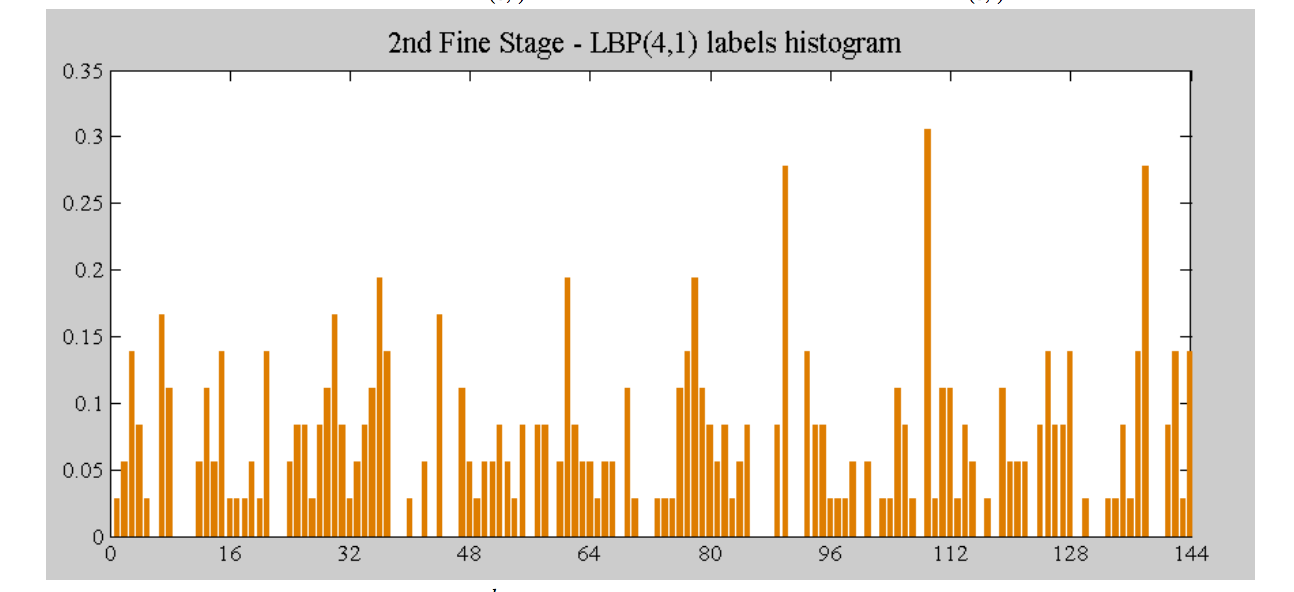
سپس مقدار هر بلوک را به یک هیستوگرام تبدیل می کند پس یک هیستوگرام برای هر بلوک داریم، مانند شکل زیر:
و در آخر این هیستوگرام ها را به هم پیوند می زند و یک بردار ویژگی برای آن تصویر درست می کند که شامل تمام ویژگی های مورد نیاز است.
۳.۲.۲. توضیحات کد:
همانند Haar Cascade از OpenCV و python 2.7 استفاده می کنیم، و تنها تفاوت آن با Haar این است که به جای Haar Classifier باید از LBP Classifier استفاده کنیم و سایر کد و توضیحات آن مانند یک دیگر هستند.
۳.۲.۳. داده های مورد استفاده:
برای بهتر فهمیدن تفاوت دو الگوریتم از یک سری داده استفاده می کنیم تا بتوانیم عملکرد هر دو الگوریتم را در شرایط یکسان بسنجیم.
۳.۲.۴. نتایج آزمایش:
در عکس اول هر دو الگوریتم کامل و دقیق بودند اما در عکس دوم الگوریتم LBP دقت Haar را نداشت اما سرعتش در پیدا کردن چهره بسیار بیشتر بود و دلیل آن هم این است که LBP فقط با int کار می کند در حالی که Haar با float کار می کند که سرعت آن را به شدت پایین می آورد.
آزمایش نمونه دوم:

همان طور که مشاهده می شود LBP از دقت کمتری برخوردار بود.
برای سنجیدن عملکرد الگوریتم از همان داده های Haar استفاده می کنیم که نتایج آن در عکس زیر قابل مشاهده است:
همان طور که مشاهده می شود LBP از دقت خیلی کمی برخوردار بود اما کمتر از Haar چهره های اشتباه پیدا کرد.
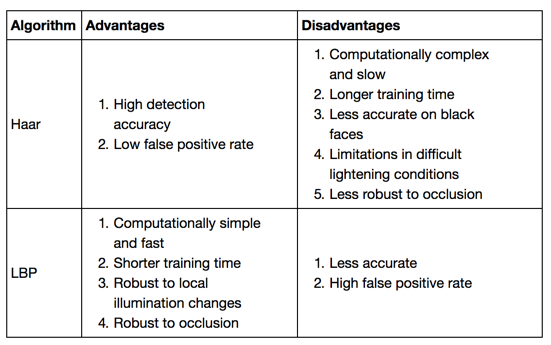
۳.۳. مقایسه ی Haar و LBP:
در مواقعی که دقت بالا نیاز باشد بهتر است از Haar Classifier استفاده کنیم. برای سیستم های امنیتی بسیار مفید است اما اگر سرعت مهم باشد باید از LBP استفاده کنیم مثلا در mobile applications یا embedded systems.
از time می توان برای مقایسه ی سرعت دو الگوریتم استفاده کرد مثلا در image02 الگوریتم Haar در 0.251 ثانیه چهره ها را پیدا کرد اما LBP در 0.128 ثانیه تقریبا نصف زمان Haar.
`پس به طور خلاصه می توان مزیت و معایب آن ها را به صورت زیر بیان کرد:
مزایای Haar:
دقت در تشخیص بالا
معایب Haar:
از لحاظ محاسباتی کند
زمان آموزش طولانی
در شرایط نوردهی سخت محدود
ضغیف در تشخیص چهره های جفت شده
مزایای LBP:
از لحاظ محاسباتی ساده و سریع
زمان آموزش کوتاه تر
قوی در تشخیص چهره های جفت شده
معایب LBP:
دقت کم
۴. بهبود نتایج:
در هر دو الگوریتم Haar و LBP دو عامل در در پیدا کردن چهره مؤثرند:
minNeighbours
scaleFactor
با تغییر مقدار این دو عامل می توان نتایج بهتر و دقیق تری داشت. scaleFactor برای مشخص کردن مقیاس عکس به کار می رود یعنی نشان می دهد که در چه مقیاسی باید چهره ها را تشخیص دهد. در آزمایش های قبلی scaleFactor ثابت و برابر 1.2 بود. حال اگر در الگوریتم Haar، مقدار scaleFactor و minNeighbour را کمی تغییر دهیم نتایج به طور چشم گیری بهبود میابند مثلا در image02 اگر minNeighbour را برابر ۳ و scaleFactor را برابر ۱.۱ قرار دهیم از ۱۱ چهره ی موجود ۱۱ چهره را به درستی تشخیص داد و سه جا را اشتباهی به عنوان چهره تشخیص داد.

نکته: در عکس فوق faces found چهره هایی هستند که به درستی تشخیص داده شده اند.
گویا بهترین نتیجه برای Haar زمانی بود که minNeighbour برابر ۳ و scaleFactor برابر ۱.۱ قرار داده شده بود.
همان طور که مشاهده می شود Haar از دقت بسیار بالا تری نسبت به LBP برخوردار است.
برای دسترسی به github اینجا را کلیک کنید.
۵. کارهای آینده:
در آینده برای کامل تر شدن فرایند تشخیص چهره و کاربردی تر شدن آن، تشخیص لبخند و چشم هم اضافه خواهد شد که حتی با استفاده از آن در فیلم ها یا عکس های پشت سر هم بتوان تعداد پلک زدن انسان را در مدت زمان معین بشمارد.
برای اضافه کردن این دو باید classifier آن ها را با هزاران عکس با زمینه ی مثبت و منفی آموزش دهیم تا بتواند چشم و لبخند را در عکس های گرفته شده پیدا کند.
استفاده از یادگیری عمیق(Deep Learning) و HOG برای پیدا کردن چهره که بسیار دقیق تر است.
۶. مراجع:
[1]Tereza Soukupova ́and JanCech. "Real-Time Eye Blink Detection using Facial Landmarks". Czech Technical University in Prague.
[2]T. Darrell, G. Gordon, M. Harville and J. Woodfill. "Integrated person tracking using stereo, color, and pattern detection".
[3]Bernhard Fröba, Christian Külbeck. "Real-Time Face Detection Using Edge-Orientation Matching".
[4]Oliver Jesorsky, Klaus J. Kirchberg, and Robert W. Frischholz. "Robust Face Detection Using the Hausdorff Distance".Third International Conference on Audio- and Video-based Biometric Person Authentication.
[5]Paul Viola and Michael J. Jones. "Robust Real-Time Face Detection".