در ردهبندی متون هدف این است که سندهایی را که در اختیار داریم بتوانیم برچسبگذاری موضوعی کنیم. در واقع این موضوع صرفا یک مسئله با ناظر است، یعنی مجموعهای از اسناد متنی که گروهبندی موضوعی شدهاند به عنوان دادهی آموزشی در اختیار سامانه قرار میگیرد تا بتواند با یادگیری از این مجموعه، اسناد جدید ورودی را به یکی از این گروههای موضوعی ملحق نماید.
در این پژوهش روشهای مختلف ردهبندی اسناد متنی مورد بررسی قرار گرفته و برای زبان فارسی پیادهسازی میشوند.
۱. مقدمه
امروزه باتوجه به گسترش روزافزون استفاده از سیستم های رایانه ای بخصوص پس از ظهور تلفن های همراه، با شبکه عظیمی از انتقال داده ها و اطلاعات مواجه هستیم. در دوران کنونی تولید محتوا به سرحد اشباع خود رسیده و موضوع مورد اهمیت در عصر حاضر تحلیل این داده ها در کسری از ثانیه و به اصطلاح تحلیل آنی داده هاست[RealTimeAnalysis] و درقدم بعد استفاده از این تحلیل ها در ارائه راهکار برای بهبود کارایی سرویس ها است، از آنجا که مطالعه تک به تک این داده ها باتوجه به کثرت داده ها کاری غیرمنطقی است روش نتیجه بخش استفاده از روش های خودکار برای انجام تحلیل روی مجموعه ای از داده هاست.
سیستم های مختلفی برای تحلیل داده ها وجود دارند که باتوجه به نوع داده ها می توان از آن ها به تناسب استفاده کرد، یکی از انواع تحلیل ها درمورد دسته بندی متون و اسناد می باشد که باتوجه به کثرت اسناد و متون، می تواند کمک حال بسیاری از موتور های جستجو برای یافتن متنی خاص باشد. برای دسته بندی متون ابتدا باید کلمات کلیدی هر سند استخراج شده و باتوجه به الگوریتم های موجود به هرکلمه وزنی متناسب با ارزش کلمه موردنظر داده شده و با نمونه های آزمایشی مقایسه شده و در انتها نتیجه منعکس شود. در تمامی مراحل یاد شده از روش های متن کاوی برای تحلیل روی داده ها استفاده می شود.
متنکاوی، به دادهکاویای که بر روی متن انجام شود اشاره دارد. همچنین به عنوان آنالیز متن نیز شناخته میشود که منظور از آن فرایند استخراج اطلاعات با کیفیت از متن است. اطلاعات پر کیفیت، بطور معمول از فهم الگوها و گرایشها از طریق معانی و بوسیله یادگیری الگوهای آماری حاصل میشود. متن کاوی معمولاً درگیر در فرایند ساختاردهی به ورودیهای متنی (معمولاً تجزیه، همراه با افزودن برخی ویژگیها تفاسیر زبانی و حذف موارد اضافی و درج موارد بعدی در پایگاه داده انجام میگیرد)، استخراج الگوهای درون دادههای ساختار یافته، و در نهایت ارزیابی و تفسیر خروجیها است. «پر کیفیت» در متن کاوی معمولاً به ترکیبی از مرتبط بودن، نو ظهور بودن و جالب بودن اشاره دارد. وظایف متن کاوی معمول شامل دستهبندی متون، خوشه بندی متون، استخراج معنی و مفهوم، تولید ردهبندی دانهای، تجزیه و تحلیل احساسات، خلاصه کردن اسناد و مدلسازی ارتباط موجودیتها است.[1]
به طور کلی هدف یک دسته بند متون، دسته بندی اسناد در قالب تعداد معینی از دسته های از پیش تعیین شده میباشد. هر سند میتواند در یک، چند و یا هیچ دسته ای قرار بگیرد. در مورد هر سند به این سوال پاسخ داده خواهد شد که این سند در کدام یک از دستهها قرار میگیرد. این موضوع میتواند در قالب یک یادگیری خودکار قرار گیرد تا با استفاده از آن بتوان هر سند را به طور خودکار به دسته ای نسبت داد. در این تحقیق، از روش دسته بندی بر مبنای قواعد انجمنی که از روی فرایند کاوش الگوهای مکرر مجموعه داده های آموزشی تولید شدهاند، برای دسته بندی متون فارسی استفاده میشود. این فرآیند با فرآیندی که در داده کاوی داده های بزرگ پایگاه دادهها استفاده میشود یکسان میباشد.[2]
هنگام بررسی طبقه بندی متون، اشاره به انواع طبقه بندی های موجود لازم است. در کل طبقه بندی به دو دسته انحصاری و غیر انحصاری تقسیم می شود. در طبقه بندی انحصاری، هر شیء دقیقاً به یک دسته وابسته میشود. در حالیکـه در طبقـه بنـدی غیر انحصاری میتواند به چند دسته اختصاص یابد و اصطلاحاً در این مـورد گفتـه میشود که همپوشانی دارد. برای مثال، دسته بندی گروهی از افراد بـا وزن یـا قـد یکسـان، از نـوع انحصـاری اسـت و دسـته بنـدی گروهـی از افـراد دارای بیمـاری، غیرانحصاری میباشد. زیرا یک شخص میتواند بطور همزمان به چند بیماری دچار شود.
طبقه بندی انحصاری میتواند به دو زیر شاخه تقسیم شود:
1- ذاتی: intrinsic یا Unsupervised
2- خارجی: extrinsic یا Supervised
تفاوت میان این دو دسته در این است که در دسـته دوم، دسـته هـای از قبـل مشخص شده را برای طبقـه بنـدی اشـیاء مـورد اسـتفاده قـرار میدهد. در حالیکه اولین گروه، یک راه پیش بینی شده را برای طبقه بندی مشخص میکند. زیرشاخه ذاتی خود به دو زیـر شـاخه سلسـله مراتبـی و partitional تقسـیم مـیشـود. سلسـله مراتبـی را "nested sequence of partitions" مـینامنـد، در حالیکه partitional یک single partition است. لازم به ذکر است که اصطلاحات خوشـه بنـدی و خوشـه بنـدی سلسـله مراتبـی بـه ترتیـب بـرای Unsupervised partitional و طبقه بندی سلسله مراتبی به کـار رفتـه اسـت.[3]
دسته بندی متون در بسیاری از زمینه ها از جمله فیلترکردن متون مخصوصا در نامه های الکترونیکی، طبقه بندی اسناد، ابهام زدایی از کلمات، سیستمهای خودکار پاسخ به سوالات و یا حتی نمره دهی به مقالات در سیستمهای آموزشی و به طور کلی در هر کاربردی که سازماندهی مستندات و یا توزیع انتخابی و تطبیقی خاصی ازمستندات مد نظر باشد، کاربرد دارد. همچنین برچسب زنی موضوعی متون با مسائلی چون استخراج اطلاعات و دانش از متون و داده کاوی متون دارای ویژگیهای فنی مشترک میباشد.
همانگونه که در بالا به برخی از کاربرد های حل این مسئله بیان شد اما یکی از بزرگترین قسمت هایی که می تواند در دنیای وب نمود پیدا کند سیستم های توصیه گر می باشند که به کمک حل این مسئله می توانند، موضوعات مورد نیاز کاربر را به وی نمایش دهند، که این کار در زمینه بازاریابی کمک حال بسیاری از سیستم های بزرگ مانند گوگل ادورزد می باشد.
روش های متنوعی برای دسته بندی موضوعی متون استفاده شده اند. یکی از این روش ها استفاده از قواعد دسته بندی یا کلاسه بندی (Classification) برای ساختن مدلی از داده ها استفاده می شود و باتوجه به شباهت ها و تفاوت های هر متن، در دسته خاص مربوط به خود قرار میگیرند.[4]
همچنین روشی دیگر استفاده از الگوریتم های یادگیری ماشین (MachineLearning) و پردازش زبان های طبیعی (NLP) می باشد که البته تمامی این روش ها نیاز به یک سری داده های اموزشی دارند تا این الگوریتم ها به کمک آن داده های از پیش تعریف شده بتوانند داده های جدید را از طریق یادگیری دسته بندی کنند.[5]
همچنین از جمله مشکلات و چالش های جدی در این الگوریتم ها می توان به اطمینان بخش بودن نتیجه دسته بندی های حاصل از این الگوریتم ها و به اصطلاح درستی این الگوریتم ها اشاره کرد.
باتوجه به کثرت تعداد متون، استفاده از داده های اموزشی زیاد برای بهبود درستی این الگوریتم ها بسیار کارا می باشد کما اینکه افزایش داده های اموزشی منجر به زمان بر شدن این الگوریتم ها می شوند که یک راه حل این مشکل استفاده از تقریب برای اجرای این الگوریتم ها می باشد. اما این راه حل ممکن است درنتیجه نهایی تاثیر گذار واقع شود و سبب به دست دادن نتایج پرت (Outlier) و اشتباه شود، درنتیجه چالش دیگر، در تحقیق انتخاب تقریب درست، به منظور ایجاد یک تعادل بین درستی الگوریتم و سرعت اجرای آن است.
۲. کارهای مرتبط
دسته بندی متون با روشهای مختلف برای زبان انگلیسـی صـورت گرفته است. Yang و Liu در سال 1999 دسته بندی متـون را بـا اسـتفاده از بردارهـای فراوانـی ریشـه کلمـات انجـام دادنـد.[6] Joachims در سـال 1998 دسـته بنـدی متـون را بـا اسـتفاده از ماشین بردار پشتیبان انجام داد.[7] Bellegarda در سال 2000 روش آنالیز معنایی پنهان (LSA) را برای دسته بندی به کار بـرد.[8] Wood و Gedeon در ســال 2001 از شــبکه هــای عصــبی هیبرید به منظور دسته بندی متون استفاده کردند.[9] در همین سال Torkolla آنالیز تمـایزی خطـی را در دسـته بنـدی بـه کـار گرفـت.[10] Blei و همکـاران در سـال 2003 روش «تخصـیص دیریکلۀ پنهان» (LDA) را برای مدلسازی متون پیشنهاد دادنـد و از آن در دسته بندی متـون نیـز اسـتفاده کردنـد.[11] در سـال 2005 نیز Guandong و همکـاران روش تحلیـل معنـایی پنهـان احتمالاتی (PLSA) را بـرای دسـته بنـدی صـفحات وب بـه کـار گرفتند.[12]
تحقیقات انجام شده در زمینه دسته بندی متون برای زبان فارسی تا کنون بسیار اندک بوده است. عرب سرخی و فیلی یک روش دسته بندی با استفاده از بردارهای فراوانی ریشۀ کلمات و الگوریتم بیزین ساده پیشنهاد داده اند. سپس آنها با ترکیب روش بیزین با ایده نگهداری کلمات همنشین، روش خود را بهبود بخشیدند.[13] حاجی حسینی و الماس گنج نیز یک روش بانظارت برای دسته بندی متون فارسی با استفاده از تحلیل معنایی پنهان (LSA) پیشنهاد دادند. روش LSA بردارهایی را در یک فضای برداری کاهش بُعد یافته برای هر متن در اختیار قرار میدهد. با استفاده از این بردارها آنها از روش شبکۀ عصبی برای آموزش دسته بندی و تعیین دستۀ مربوط به متون جدید استفاده کردند.[14] پیله ور و همکاران، با استفاده از یادگیری چندی سازی برداری دسته بندی مستندات متنی فارسی را از روی پیکره همشهری انجام دادند.[15]
در مقاله ای دیگر فرهودی و یاری، با استفاده از روش بهره جویی از گنج واژه و انتخاب ویژگی دو مرحله ای به دسته بندی متون فارسی پرداخته اند. [16]
در مقاله ای دیگر از بردار بسامد وزن دار کلمات کلیدی در متون آموزشی هر کلاس به عنوان مدلی برای طبقه بندی استفاده شده است و برچسب زنی متون جدید با استفاده از تعیین میزان شباهت یا فاصلۀ بین بردار متن جدید با بردار هر کلاس صورت میگیرد. عمده ایده بکار رفته در تهیۀ بردار کلاس ها، بررسی دیدگاه های زبان شناختی اعم از صرف و معنی شناسی در استخراج کلمات مهم یا کلیدی و مخصوصا هرس کلمات زاید به صورت دستی می باشد.[3]
الگوریتم پیشنهادی برای برچسب زنی موضوعی بدین صورت عمل میکند که ابتدا تعدادی کلمه از بین کلمات دادگان آموزشی به عنوان کلمۀ کلیدی انتخاب میشود. در مرحلۀ بعد بسامد وزندار کلمات کلیدی در متون آموزشی مربوط به هر موضوع استخراج میشود. به ازای هر موضوع، بردار بسامد وزندار کلمات کلیدی به عنوان بردار نماینده آن کلاس در نظر گرفته میشود. در مرحلۀ آزمون، برای برچسب زنی موضوعی به یک متن جدید، ابتدا بردار بسامد وزندار کلمات کلیدی متن جدید استخراج گشته و سپس فاصلۀ این بردار با تک تک بردارهای مربوط به کلاس ها سنجیده میشود. کلاس یا موضوعی که بردار مربوط به آن کمترین فاصله را از بردار ورودی داشته باشد، به عنوان محتمل ترین موضوع برای متن جدید در نظر گرفته میشود. در این مقاله از معیار کسینوسی به عنوان :معیار فاصلۀ بین بردارها استفاده شده است.
اولین مرحله در استخراج کلمات کلیدی آماده سازی متون می باشد داده های ورودی به برنامه طبقه بندی متون، عموماً متونی هستند که از سایت های
خبری فارسی جمعآوری شدهاند. بررسی کلی روی هفت طبقه زیر میباشد:
1- اجتمـاعی 2- اقتصـادی 3- پزشـکی 4- سیاسـی 5- فرهنگـی 6- مـذهبی7- ورزشی
برای هر یک از این طبقه ها ۱۰۰ متن در نظر گرفته شده است. از هر کـدام از این ۱۰۰ متن، ۸۰ متن برای فاز یادگیری و ۲۰ متن دیگر برای فاز تست اسـتفاده خواهد شد. با توجه به اینکه این متون در ویرایشگرهای فارسی متفاوتی تایپ شده است و نیز در هنگام بارگذاری روی اینترنت ممکن است دچار تغییراتی شده باشد،
لازم است در ابتدا بازبینی کلی روی متون انجام شود. قسمتی از ایـن بـازبینی بـه شیوه دستی انجام شده است که اهم آنها عبارتند از:
دسته بندی متون در گروه های مربوطه و تعیین اسم متون بر مبنای "شماره حرف اختصاری نمایانگر آن گروه".
برطرف نمودن غلط های املایی تا حد امکان.
چک کردن رعایت فاصله صحیح بین کلمات.
یکسان نویسی حروف و علائم ریاضی.
معرفی افعال،پیشوندها، پسوندها، حروف ربط، اضافه و نشانه، افعـال ربطـی، علائم نقطه گذاری و ضمایر به صورت فایل های جداگانه به عنـوان ورودی سیسـتم.[17]
سپس به مرحله استخراج کلمات کلیدی می رسیم.
در حل مسائل مربوط به رده بندی موضوعی متن مهم ترین بخش استخراج کلمات کلیدی مفید می باشد زیرا بسیاری از کلمات قیدی و کمکی بار معنایی زیادی برای تفهیم یک موضوع به فرد ندارند. ثابت شده است فقط ۳۳ درصد از کلمات یک متن مفید هستند و از آن ها برای فهم متن می توان استفاده نمود.[18] پس از حذف کلمات غیر مفید و بدون بار معنایی به مرحله ریشه یابی کلمات می رسیم باتوجه به اینکه بسیاری از کلمات دارای مفهومی یکسان می باشند، برای مثال کلمات رفتم و رفتی هردو مفهوم رفتن را به شنونده القا می کنند. البته این ساده ترین نوع از مفاهیم یکسان به شمار می رود، در بسیاری از موارد ما ابتدا ریشه اصلی کلمه را پیدا کرده و سپس به کمک داده های آموزشی تمامی ریشه های کلماتی را که با ریشه کلمه یافته شده ترادف دارند را با یک وزن خاص درجدولی نگه داری میکنیم، برای مثال دومفهوم بازگشتن و آمدن کلمات مترادفی هستند که باید با یک بار معنایی به آن ها توجه شود. به زبان دیگر شناسایی گروه اسمی و دیگر اصطلاحهایی که به شی ای یکسان ارجاع دارند. در این مرحله چالشی که در مقدمه این مقاله عنوان شد پدید می آید: استفاده از داده های آموزشی بیشتر و دقت بالاتر ولی سرعت انجام پایین یا استفاده از داده های آموزشی کمتر و به تبع آن دقت کمتر در موضوع بندی متن اما سرعت بیشتر در اجرای الگوریتم.
استفاده از ریشه یابی های چند مرحله ای مانند آنچه عنوان شد توان محاسباتی را بصورت نمایی بالا می رود و بشدت بر روی اجرای الگوریتم تاثیرگذار خواهد بود.
در این فاز، به طور کلی عملیات کلی زیر انجام میشود:
الف: تبدیل هریک از متون به برداری از کلمات
ب: پیدا کردن پایان جملات با استفاده از تشخیص افعال و حروف ربط
ج: اطمینان از یکسان بودن کاراکترهای الفبای فارسی (یکسان سازیبرخی از کاراکترها مانند "ی" و "ک" از لحاظ کد اسکی)
د: تفکیک جملات از یکدیگر
ه: از بین بردن کلمات بی فایده (حروف ربط، اضافه، نشانه، علایم نقطه گـذاری، ضمایر، افعال ربطی، شبه جمله ها و ...)
و: انجام عملیات کاهش و ریشه یابی با توجـه بـه دو گـروه کلمـات ، افعـال و اسامی:
بررسی افعال
بررسی پیشوندهای فعل در دو قسمت با تغییر معنی و بـدون تغییـر معنـی.
مثال: فراگرفتن= فرا+گرفتنحذف شناسه افعال و بررسی امکان پذیر بودن کاهش با استفاده از جدول بن و مصدر.
جایگزین نمودن فعل با مصدرش با استفاده از جدول افعال.
مثال: میگفتم← گفتم← گفت← گفتن
بررسی اسامیکاهش علامات جمع (مانند ها، های،...)
حذف ضمایر متصل
حذف پیشوند
حذف پسوندهای اسم
مشتق
مرکب و ساده [3]
همچنین می توان از شناسایی ماهیت و هویت اسم استفاده کرد. این روش از تکنیکهای اماری جهت شناختن نامها استفاده میکند: مردم، سازمانها، نام مکانها، اختصارهای خاص و غیره. ابهام زدایی – با استفاده از راهنماهای متنی –ممکن است نیاز شود برای آنکه تعیین گردد کلمه “Ford” میتواند به یک رئیس جمهور سابق آمریکا، یک کارخانه خودروسازی، یک ستاره سینما، یک رودخانه یا موجودیتی دیگر ارجاع داشته باشد. [1]
۳. پیاده سازی
لینک گیت هاب پروژه: اینجا را کلیک نمایید.
۱.۳: دادگان آموزشی
اولین قدم برای استفاده از الگوریتم های پیشنهادی و آزمایش الگوریتم های موردنظر داشتن بانکی از داده های معتبر می باشند. برای این منظور ما از داده های موجود از مجموعه روزنامه همشهری استفاده میکنیم. این مجموعه حاوی ۳۱۸ هزار سند مربوط به مقاله ها و متون روزنامه همشهری از سال ۱۳۷۵ تا ۱۳۸۶ می باشد که به کمک خزش (Scape) وب سایت همشهری به دست آمده. تمامی این اسناد دارای پرچسب مربوط به دسته بندی خبر موردنظر می باشد که این اطلاعات توسط گروه تحقیقاتی پایگاه داده دانشگاه تهران و با حمایت مرکز تحقیقات مخابرات ایران تهیه شده است. [19]
قالب کلی این متون به صورت فایل XML می باشد که شامل اطلاعاتی از قبیل تاریخ انتشار، عنوان، دسته بندی متن نامبرده و متن مطلب مورد نظر می باشد.
لازم به ذکر است تعدادی از دسته بندی های موضوعی موجود در این مجموعه از داده های آموزشی به فرمت ذیل می باشد:
1. adabh Literature and Art ادب و هنر
2. ejtem Social اجتماعی
3. elmfa Science and Culture علمی فرهنگی
4. eqtes Economy اقتصاد
5. gozar Miscellaneous گوناگون
6. siasi Politics سیاسی
7. varze Sport ورزش
8. trip Tourism گردشگری
9. ...
به علت تعدد موضوعات فرعی تعدادی از دسته های اصلی در اینجا آورده شده اند. برای مشاهده تمامی موضوعات اینجا را کلیک کنید.
همچنین فایلی با عنوان useless.txt آورده شده است، که براساس مشاهدات شخصی این فایل تکمیل گردیده، نمونه هایی از آن ها در پایگاه های داده های آموزشی یافته شد که متاسفانه بدلیل نیاز به نامه معرفی از طرف استاد برای دسترسی به دادگان، امکان استفاده از آنها وجود نداشت.
۲.۳: روش پیاده سازی الگوریتم
۱.۲.۳: مرحله پردازش کلمات کلیدی متن
در این مرحله بعد باید کلمات کلیدی هر متن را استخراج کنیم در اینجا با چالشی جدید مواجه شدیم، به این صورت که در ابتدا ما فرض را بدین گونه گذاشته ایم که تمامی کلمات را استخراج کرده و حروف اضافه و بی معنی را حذف کنیم و با توجه به وزنی که به هرکلمه اختصاص دهیم، درمورد دسته بندی موضوعی متن نتیجه گیری کنیم.
اما سپس به این نتیجه رسیدیم که این روش ممکن است کارا نباشد زیرا این کلمات نیستند که معنی دار هستند بلکه این جملات هستند که معنی دارند و یک مفهوم را میرسانند، درواقع نتیجه گیری براساس تعداد زیادی کلمه صرف ممکن است نتیجه کاملی را به دست ندهد. برای همین منظور ما تصمیم گرفتیم که برای این پروژه هر متن را به جمله های مجزا تقسیم کنیم (که طبیعتا پردازش چند کلمه در یک جمله سریع تر و دقیق تر نیز می باشد) و پس از پردازش به هرکدام از جمله ها چند برچسب را با اولویت اختصاص دهیم، و در مرحله آخر با توجه به وزن کلی جمله ها و مفاهیم مجموعه جمله ها، در مورد موضوع اصلی متن نتیجه گیری کنیم. (در واقع ما از مفاهیم الگوریتم divide and conquer استفاده می کنیم)
با توجه به اینکه در پردازش یک جمله با تعداد کلمات اندکی رو به رو هستیم میتوانیم از الگوریتم های پیچیده تر در زمان کمتر استفاده کنیم تا مفاهیم هر جمله را استخراج کنیم.
حال که روش حل مسئله ما به صورت بالا ارائه گردید مراحل زیر را برای مرحله استخراج کلمات کلیدی خواهیم داشت:
نرمالسازی متن: درصورت وجود غلط املایی یا اشتباه نویسی متون و جمله های آن را اصلاح کنیم.
تقسیم متن به جمله های مجزا: باتوجه به دستور زبان فارسی درمورد ساختار جمله ها، آن ها را پیدا میکنیم.
استخراج کلمات کلیدی هر جمله: این قسمت در بخش کارهای مرتبط و در قسمت استخراج کلمات کلیدی آورده شده است (شامل حذف کلمات بی فایده، بررسی ریشه افعال و اسامی و...)
لازم به ذکر تمامی این مراحل به کمک کتابخانه هضم که یک کتابخانه پردازش زبان فارسی در پایتون می باشد و توسط گروه سبحه توسعه یافته انجام میگیرد. [20]
۲.۲.۳: مرحله پردازش مفاهیم جملات
برای این مرحله ما استفاده از کتابخانه Sklearn را درنظر گرفته بودیم، اما به دلیل بعضی از مشکلات در استفاده از این کتابخانه بر این شدیم تا خود برخی از خصوصیت های کتابخانه مذکور را برای این مرحله پیاده سازی نماییم. و پس از تولید ماتریس های برداری کلمات آن را به راحتی پردازش کرده و همبستگی آن را با متون جدید بررسی کنیم تا بتوانیم درباره موضوع آن متون نتیجه گیری داشته باشیم. [21]
برای این بخش ما یک اسکریپت برای خواندن داده هارا آماده کرده ایم و به کمک کتابخانه هضم آن ها را نرمالسازی کرده و به جمله های مجزا از هم تبدیل میکنیم.
برای مرحله بعد ما یک لیست از کلمات کم کاربرد و بی معنی را آماده کرده ایم تا بتوانیم به کمک آن متون حشو را شناسایی کرده و از متن دور بیاندازیم زیرا در نتیجه گیری نهایی این کلمات حاوی مفاهیم نیستند.
سپس ما یک بردار از تمامی کلمات موجود در هر متن را به صورت زیر ساخته و پس از آن به اندیس گذاری آن می پردازیم، این اندیس گذاری برای استفاده های آتی در ماتریس برداری تعدد کلمات می باشد.
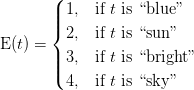
و سپس میزان تکرار کلمات را بررسی می نماییم و سپس به صورت یک ماتریس آن ها را نگه داری میکنیم.
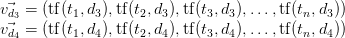


۳.۲.۳: مرحله دسته بندی داده ها
حال به مرحله نهایی این پروژه میرسیم، هدف ما در این مرحله تولید یک ماتریس نرمالسازی شده است که بتوانیم از طریق آن میزان شباهت جملات به یکدیگر را بررسی کنیم.
برای اینکار همانگونه که قبل تر نیز گفته شد، در یک تلاش ناموفق این پروژه را با کتابخانه Sklearn پیاده سازی کردیم که نتایج درمواجهه با کلمات فارسی قابل اتکا نبودند، و با مطالعه ساختار کتابخانه مذکور و الگوریتم های مورد نظر ما برای انجام این کار بخشی از این کتابخانه را پیاده سازی نمودیم.
ما در بخش قبل همانگونه که اشاره شد به تهیه کلمات کلیدی و تولید ماتریسی خاص به نام تعدد اصطلاحات (Term Frequency) پرداختیم، دراینجا ما ماتریس خود را باید نرمالسازی کنیم تا داده های ما قابل اتکا تر باشند، برای درک بهتر این موضوع باید درنظر بگیرید که ما برای اینکه چند داده را بتوانیم با یکدیگر مقایسه کنیم باید تمامی داده ها درشکل معین و خاصی باشند مثلا ممکن است بتوانیم جمله ای با ۲۰ کاراکتر را با جمله ای با ۳ کاراکتر مقایسه کنیم، اما این مقایسه درست نیست زیرا باید چگالی هرکلمه نسبت به کل کلمات به کار رفته در آن جمله سنجیده شود نه صرفا تعداد تکرار ها که میتواند با طولانی شدن یک جمله افزایش یابد، به همین منظور ما هرردیف از ماتریس یاد شده را به بردار های یکه تبدیل میکنیم تا طولانی بودن جمله که طبیعتا باعث زیاد شدن جملات میشود تاثیری در نتایج ما نداشته باشد:
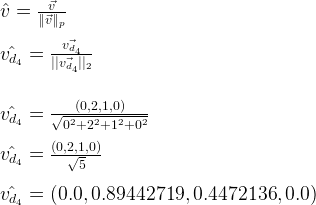
سپس در انی مرحله به یکی از مهم ترین الگویرتم های مورد استفاده در انی پروژه میرسیم: الگوریتم TF-IDF که درواقع دو حرف ابتدایی یعنی TF مخفف همان Term Frequency است که در بالا به استخراج آن پرداختیم، در این مرحله به تولید ماتریس (IDF (Inverse Document Frequency می پردازیم که در ادامه به دلیل استفاده و کاربرد آن در پروژه می پرازیم.
ما می دانیم که هر جمله شامل بسیاری از کلمات است که ممکن است کلماتی مهم بسیار در آن تکرار شوند، اما ممکن است یک کلمه بخصوص بسیار در رده بندی متن کارا باشد و به علت تعدد کلمات دیگر (که آنها نیز مهم هستند) نادیده گرفته شود، در اینجا ما باید به هر کلمه وزنی خاص را اختصاص بدهیم، این کار توسط الگوریتم idf انجام میگیرد:



این الگوریتم و نتیجه tf-idf که حاصل ضرب ماتریسی، ماتریس به دتس آمده از tf و ماتریس به دست آمده از الگوریمت idf می باشد، به شما این امکان را می دهد که یک وزن زیاد از تابع tf-idf خروجی شود، درصورتی که یک کلمه خاص بسیار در آن تکرار شده باشد، و یا اینکه یک کلمه خیلی کم در آن تکرار شده باشد ولی وزن مربوط به idf آن زیاد باشد.
سپس در آخرین مرحله ما باید بار دیگر ماتریس tf-idf را ردیف به ردیف یکه کرده تا داده های ورودی را که می خواهیم با این داده ها مقایسه کنیم و درمورد آن ها نتیجه گیری کنیم، مقایسه عادلانه ای در این مرحله انجام دهیم.
حال ماتریس tf-idf ماتریس نهایی است که برای دادگان آموزشی به دست آورده ایم، حال به ازای هر ورودی باید با محاسبه tf-idf مربوط به آن، میزان شباهت آن به هرکدام از داده های آموزشی که به صورت tf-idf ذخیره شده را پیدا کنیم که با نرم افزار های عادی کلاسه بندی، مانند Clementine، می توانیم این داده ها را به عنوان ورودی به آن ها داده و نتایج را مشاهده کنیم که به کدام یک از ردیف های موجود در ماتریس tf-idf داده های آموزشی بیشتر شباهت دارند. (هر ردیف بیانگر یک مفهوم متنی و سند متنی است.)
۴. کار های آینده
ما در این پروژه سیستم خود برای طبقه بندی موضوعی متن را پیاده سازی کردیم که این الگوریتم براساس استفاده از تحلیل روی جملات بجای تحلیل روی تمام متن کار میکند، این تحلیل یک فرضیه از توسط نویسنده این پروژه بود که شاید این روش کار، کارا تر و سریع تر از تحلیل تمامی متن بصورت یکجا باشد. حال آنکه ما این سیستم را پیاده سازی نمودیم، اما به جد برای مقایسه این دو نوع روش برخورد با طبقه بندی متون، باید روش دیگر یعنی طبقه بندی متن براساس تحلیل تمامی متن نیز در آینده پیاده سازی شود تا با استفاده از نتایج هر دو نوع پیاده سازی بتوانیم به یک نتیجه کلی برای بهینگی الگوریتم ها برسیم. و بفهمیم بهینه تر و دقیق تر است تا ابتدا جمله هارا تحلیل کنیم یا تمام کلمات یک متن را باهم تحلیل و موضوع بندی کنیم.
۵. منابع
Berry, Michael W., ed. Survey of Text Mining I: Clustering, Classification, and Retrieval. Vol. 1. Springer, 2004.
[1]متن کاوی ویکی پدیا (https://fa.wikipedia.org/wiki/متن_کاوی)
[2] دسته بندی موضوعی متون فارسی براساس روش قواعد انجمنی(https://ganj.irandoc.ac.ir/articles/562957)
[3]کاوش متون فارسی بر مبنای روش طبقه بندی، نشریه علمی پژوهشی انجمن کامپیوتر ایران،مجلد ۸، شماره ۱ و ۳ (الف)، ۱۳۸۹
[4]دسته بندی موضوعی متون فارسی بر اساس روش قواعد انجمنی، سید محمد حسین احمدی، پایان نامه ی کارشناسی ارشد ، دی ماه ۹۰)
[5]دستهبندی متون با استفاده از یادگیری ماشین، محسن رحیمی، پروژه هوش مصنوعی، ۹۱
[6] Y. Yang and X. Liu, "A Re-examination of Text Categorization Methods", Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval, pp. 42-49, .1999
[7] T. Joachims, "Text Categorization with Support Vector Machines: Learning with Many Relevant Features in Machine Learning", 10th European Conference on Machine Learning, pp. 137-142, 1998.
[8] J.R. Bellegarda, "Exploiting Latent Semantic Information in Statistical Language Modeling", Proceedings of IEEE, Vol. 88, No. 8, pp. 1279-1296, .2000
[9] S.A. Wood and T.D. Gedeon, "A Hybrid Neural Network for Automated Classification" Proceedings of the 6th Australasian Document Computing Symposium, .2001
[10] K. Torkolla, "Linear Discriminant Analysis in Document Classification", IEEE ICDM workshop on text mining, 2001.
[11] D., Blei, A. Ng, M. Jordan, “Latent Dirichlet Allocation”, Journal of Machine Learning Research, Vol. 3, pp. 993-1022, 2003.
[12] X. Guandong, Y. Zhang, Z. Zhou, "Using Probabilistic L a t e n t S e m a n t i c A n a l ys i s f o r W e b P a g e G r o u p i n g " , Proceedings of Research Issues in Data Engineering: Stream Data Mining and Applications, pp. 29-36, 2005.
[13] محسن عرب سرخی، هشام فیلی، "ارائه یک سیستم دسته بندی موضوعی متون فارسی بر اساس روش های احتمالاتی"، مجموعه مقالات دومین کارگاه پژوهشی زبان فارسی و رایانه، صص ۱۵۱-۱۶۱، ۱۳۸۵.
[14] آزاده حاجی حسینی، فرشاد الماس گنج، "دسته بندی موضوعی متون فارسی بر اساس روش آنالیز معنایی پنهان"، مجموعه مقالات دومین کارگاه پژوهشی زبان فارسی و رایانه، صص ۱۹۰-۲۰۱، ۱۳۸۵.
[15] T. Pilehvar, H. Faili, M. Soltani, Classification of Persian textual documents using Learning Vector Quantization, 4rd IEEE Conference on Knowledge Engineering and Natural Language Processing, NLP-KE, 2009.
[16] 11. M. Farhoodi, A., Yari, M. Mahmoudi., "A Persian Web Page Classifi er Applying a Combination of Content-Based andContext-Based Features", International Journal of Information Studies, Vol. 1, No. 9, 2009.
[17] ح. انوری و ح. احمـدی، دستور زبان فارسی. چـاپ ششـم، چاپخانـه بهـرام، تهران، ۱۳۷۰.
[18] L. Liu, J. Kang, J. Yu, and Z. Wang, "A Comparative Study on Unsupervised Feature Selection Methods for Text Clustering," Proc. of the Conference on Natural Language Processing and Knowledge Engineering, pp. 597- 601, 2005.