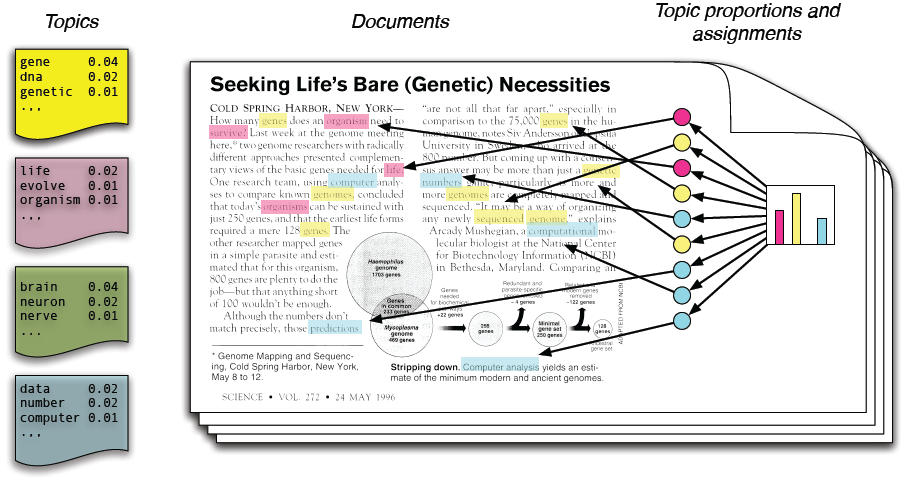
در مدلسازی موضوعی، فرض میکنیم که مجموعه متون ورودی از روی چند موضوع نامعلوم ساخته شدهاند و باید این موضوعات را پیدا کنیم. هر موضوع یک توزیع احتمال نامعلوم روی واژهها است و هر متن توزیع احتمالی روی موضوعها.
* این پروژه توسط یک بنگاه تجاری تعریف شده است.
# ۱. مقدمه
با افزایش حجم اسناد و اطلاعات و از طرفی نمایش آنها به صورت دیجیتال در قالب اخبار، وبلاگها، مقالات علمی، کتابهای الکترونیکی، عکس، صوت و تصویر و شبکههای اجتماعی پیدا کردن مطالبی که به دنبال آن هستیم مشکل میشود. ازاینرو نیاز به ابزار محاسباتی جدیدی برای سازماندهی، جستجو و درک این حجم عظیم اطلاعات هستیم.
تابهحال کار ما روی اسناد آنلاین به دو طریق انجام میگرفت: یکی جستجو و دیگری پیوندها. کلمهی کلیدی را در یک موتور جستجو وارد و مجموعهای از اسناد مرتبط با آن را مشاهده میکردیم. در این اسناد اگر پیوند مفیدی به اسناد دیگر میدیدیم با کلیک روی آن به مجموعه اسناد دیگر دسترسی پیدا میکردیم. این دو روشهای قدرتمندی برای کار کردن با آرشیوهای الکترونیکی بودند اما مشکلاتی نیز وجود داشت.
روش جستجویی که در بالا شرح داده شد مبتنی بر ظاهر یک کلمه بود و هنگام انجام عمل جستجو تمامی اسنادی که حاوی آن کلمهی کلیدی هستند به عنوان نتیجه برگردانده میشوند. این اسناد اگرچه دربردارندهی آن کلمه هستند ولی ممکن است متعلق به موضوعات مختلفی باشند درحالیکه ما احتمالاً فقط به دنبال یک موضوع خاص هستیم. برای اینکه جستجوی دقیقتری داشته باشیم بایستی ابتدا موضوع مورد علاقهی خود را در بین اسناد جستجو کرده و سپس جستجوی خود را محدود به این اسناد جدید کنیم و میتوانیم در این اسناد جدید دوباره موضوع خود را محدودتر کنیم و همینطور پیش برویم تا جایی که به طور دقیق به اسناد مورد نیاز خود دسترسی پیدا کنیم.
به عنوان مثال فرض کنیم میخواهیم در آرشیو یک روزنامه به دنبال یک موضوع باشیم. موضوعات در دستههای سیاسی، اقتصادی، فرهنگی، ورزشی و حوادث قرار دارند. مثلاً میخواهیم در موضوع سیاسی جستجو کنیم. داخل این موضوع زیرموضوعهای سیاست داخلی و خارجی وجود دارد که یکی را انتخاب میکنیم و همینطور پیش میرویم تا دقیقاً به اسناد مورد نیازمان دسترسی پیدا کنیم.
البته اینگونه کار کردن با اسناد بهسادگی امکانپذیر نیست؛ زیرا هر چه حجم اسناد و اطلاعات افزایش مییابد دستهبندی فوق برای انسان کار مشکل و یا غیرممکنی میشود؛ بنابراین نیاز به تکنیکهای یادگیری ماشین داریم تا بتوانیم از طریق کامپیوتر دستهبندی فوق را انجام دهیم. پژوهشگران حوزهی یادگیری ماشین برای این کار مجموعهای از الگوریتمها تحت عنوان مدلسازی موضوعی آماری را توسعه دادهاند.
الگوریتمهای مدلسازی موضوعی روشهای آماری هستند که کلمات داخل یک متن را تحلیل کرده و از این طریق موضوعات داخل متون را استخراج میکنند. همچنین ارتباط این موضوعات با یکدیگر و نیز تغییر آنها در طول زمان را مشخص میکنند. این الگوریتمها نیازی به هیچ فرض اولیهای در مورد موضوعات متون و یا برچسبگذاری متون ندارند. بلکه ورودی آنها متن اصلی است. الگوریتمهای مدلسازی موضوعی به ما این امکان را میدهند تا سازماندهی و خلاصهسازی آرشیوهای الکترونیکیمان را در ابعادی که از عهدهی انسان برنمیآید انجام دهیم.
در مدلسازی موضوعی سه هدف زیر را دنبال میکنیم:
+ پیدا کردن موضوعات نامعلوم که در مجموعه اسناد وجود دارند. (شایع هستند)
+ تفسیر کردن اسناد بر اساس موضوعات آنها.
+ استفاده کردن از این تفاسیر برای سازماندهی کردن، خلاصه کردن و جستجو کردن متنها.
# ۲. کارهای مرتبط
## ۲. ۱. مدلهای موضوعی خطی
گرایش به یادگیری موضوعات از روی مجموعهای از اسناد بهوسیلهٔ ماشین از زمان انتشار مقالهی روش آنالیز معنایی پنهان[^Latent Semantic Analysis] (LSA) آغاز شد.[۱]LSA یک مدل خطی بر پایهٔ تجزیهی ماتریس کلمه-سند X است که $x_{dw}$ نمایشدهندهی تعداد رخداد کلمهی w در سند d است. هدف یافتن تخمین مرتبهی پایین $\tilde {\boldsymbol X}$ از ماتریس X با تجزیهی آن به دو ماتریس است که یکی از آنها اسناد و دیگری موضوعات را نمایش میدهند.
در این مدل اسناد به کیسهای از کلمات[^bag of words] تبدیل میشوند که در آن ترتیب رخداد کلمات در نظر گرفته نمیشود و فقط تعداد کلمات نگهداری میشود.
### ۲. ۱. ۱. تجزیهی مقادیر منحصربهفرد[^Singular Value Decomposition]
یکی از راههای متداول استفاده از تجزیهی مقادیر منحصربهفرد از رابطهی$$\boldsymbol X= \boldsymbol U \boldsymbol \Sigma \boldsymbol V^T$$است که در آن U و V ماتریسهای متعامد نرمال هستند و $\boldsymbol \Sigma$ یک ماتریس قطری است.
با انتخاب فقط k مقدار منحصربهفرد بزرگتر از $\boldsymbol \Sigma $ و بردارهای مربوطه در U و $\boldsymbol V^T $ تعداد k تخمین برتر از X به دست میآید. ردیفهای ماتریس U نشانگر اسناد در یک فضای K-بعدی هستند و ستونهای ماتریس $ \boldsymbol V^T $ نشانگر موضوعات در همان فضای k-بعدی هستند. هر سند میتواند بهصورت یک ترکیب خطی از موضوعات بیان شود.
### ۲. ۱. ۲. تجزیهی ماتریس غیر منفی [^Non-negative Matrix Factorization]
یکی دیگر از رویکردهای متداول استفاده از تجزیهی ماتریس غیر منفی بر روی ماتریس کلمه-سند X است [۳] [۲]در اینجا $\tilde{\boldsymbol X} = \boldsymbol U \boldsymbol V $ است که در آن U نمایشگر موضوعات و V نمایشگر اسناد است و هردوی آنها ماتریسهای غیر منفی هستند.
### ۲. ۱. ۳. مدل LSA
روش آنالیز معنایی پنهان یا LSA از جمله روشهای شناختهشده در کاهش بعد به شمار میرود. ایدهی اصلی پشتوانهی LSA، درست کردن یک ماتریس از وقوع همزمان کلمه/متن و سپس بیان این ماتریس بسیار بزرگ در یک زیرفضای کاهش بعد یافته با استفاده از «تجزیهی مقادیر تکین» یا SVD میباشد. با تصویر کردن کلمات و متون در زیرفضای کاهش بعد یافته، میتوان آنها را به صورت برداری بیان نمود.
این مدل تکنیک دیگری در پردازش زبانهای طبیعی برای بررسی ارتباط بین یک مجموعه از اسناد و لغاتی که در آن اسناد وجود دارند میباشد. این روش مفاهیم پنهان در اسناد را کشف میکند. مطابق این الگوریتم برای هر سند مجموعهای از مفاهیم مرتبط با آن مشخص میشود. الگوریتم LSA فرض میکند کلماتی که معانی نزدیک به هم دارند در یک قطعه از متن قرار میگیرند. این الگوریتم گاهی در بازیابی اطلاعات با نام LSI [^Latent Semantic Indexing] شناخته میشود.
قدم اول در این الگوریتم این است که متن را به صورت یک ماتریس نمایش دهیم. در این ماتریس هر سطر نشاندهندهی یک کلمه و هر ستون نشاندهندهی یک متن میباشد. به هر درایه توسط الگوریتم دیگری یک وزن داده میشود. یک روش وزن دهی tf-idf است. سپس با الگوریتم SVD سعی در کاهش تعداد سطرهای ماتریس میکنیم (کاهش ابعاد). این کار به سه دلیل زیر انجام میگیرد:
+ ماتریس اولیه بسیار بزرگ است.
+ در ماتریس اولیه اصطلاحاً نویز وجود دارد. به عنوان مثال کلماتی که به ندرت مورد استفاده قرار میگیرند باید حذف گردند.
+ ماتریس اولیه یک ماتریس خلوت است؛ بنابراین کلماتی که به هم نزدیک هستند را در یک سطر قرار میدهیم.
کلمات سپس با کسینوس گرفتن از زاویهی بین هر دو بردار که سطرهای ماتریس میباشند با هم مقایسه میشوند. مقادیر نزدیک به یک بیانگر کلماتی هستند که تشابه بیشتری دارند و مقادیر نزدیک به صفر بیانگر کلماتی هستند که تشابه کمتری دارند.
## ۲. ۲. مدلهای موضوعی احتمالی
روش LSA موضوعات را بهصورت نقاطی در فضای اقلیدسی نشان میدهد و اسناد را بهصورت ترکیب خطی از موضوعات بیان میکند. مدلهای موضوعی احتمالی برخلاف LSA، موضوعات را بهصورت توزیعی از کلمات و اسناد را بهصورت توزیعی از موضوعات بیان میکند.
همانطور که گفتیم مجموعهی اسناد ما شامل کلمات قابل مشاهده است و موضوعاتی که به دنبال آن میگردیم ساختارهای پنهان هستند. بهطورکلی مدلهای احتمالی متغیرهای آشکار و متغیرهای پنهان را با هم تلفیق کرده و نتیجه را مشخص میکنند.
بهصورت رسمی با در نظر گرفتن واژگانی از کلمات W، هر موضوع k = 1, ..., K توزیع احتمالی بر روی کلمات است
$$\boldsymbol \phi_k \in \Delta_W$$و هر سند d = 1, ..., D توزیع احتمالی بر روی موضوعات است.
$$\boldsymbol \theta_d \in \Delta_K$$همچنین ماتریس $\boldsymbol \Phi$ با ردیفهای $\boldsymbol \phi_k$ و ماتریس $\boldsymbol \Theta$ با ردیفهای $\boldsymbol \theta_d$ را در نظر بگیرید.
با تخمین پارامترهای مدل ($\boldsymbol \Phi$, $\boldsymbol \Theta$)، دانش جدیدی از مجموعهی اسناد کشف میشوند که در آن موضوعات با توزیع کلمات $\boldsymbol \phi_k$ نمایش داده میشوند و اسناد با موضوعات کشفشده که با $\boldsymbol \theta_d$ نمایش داده میشود برچسب میخورند.
### ۲. ۲. ۱.مدل PLSA[^Probabilistic Latent Semantic Analysis]
هافمن تکنیک آماری جدیدی به نام «آنالیز معنایی پنهان احتمالاتی» یا PLSA را ارائه داد و برای نخستین بار از آن در بازیابی اطلاعات استفاده نمود.[۵] در سالهای اخیر این روش در زمینههایی چون فیلتر کردن اطلاعات، کندوکاو در در وب و طبقهبندی متون به طور موفقی به کار رفته است. در مقایسه با روش استاندارد تحلیل معنایی زبان یعنی LSA که از جبر خطی ریشه میگیرد و منجر به تجزیهی مقادیر تکین از جداول همآیی میشود، این روش بر اساس ترکیب احتمالاتی فاکتورهایی است که از یک مدل کلاس پنهان نشأت میگیرد و باعث ایجاد شیوههای اصولیتر در تحلیل زبان و متون گردیده که دارای زیربنای آماری محکمی میباشد. روش PLSA نه تنها بیان مناسبی از متون در اختیار ما قرار میدهد، بلکه یک روش ردهبندی بدونناظر نیز به شمار میرود. با توجه به تئوری آماری مناسبی که این روش دارد امکان انتخاب و کنترل مدل را فراهم میسازد.
مدل PLSI بهصورت یک فرآیند افزایشی تعریف میشود [5]. روندی که در آن اسناد بهصورت احتمالی بر اساس پارامترهای مدل تولید میشوند. پارامترهای مدل بر اساس روش بیزین آموزش مییابند.
procedure GenerativePLSI(document-tagging theta_d, topics phi_k):
for document d = 1..D:
for position i = 1..N_d in document d:
draw a topic z_di from Discrete(theta_d)
draw a word w_di from Discrete(phi_z_di)
return n_dw = sum_i I(w_di = w)
اگرچه که فرمولهکردن مدل، احتمالی است [۶] تساوی بین دو روش pLSI و NMF را میتوان با نشان دادن اینکه هردوی آنها یک تابع هدف را بهینه میکنند اثبات نمود.
نقطهی شروع مدل PLSA مدل آماری به نام Aspect Model میباشد که متغیرهای کلاس پنهان (غیرقابل مشاهده) $ z \in Z=\{ { z }_{ 1 },{ z }_{ 2 },...,{ z }_{ r }\} $ را با متغیرهای قابلمشاهده که در اینجا متون $ d \in D=\{ { d }_{ 1 },{ d }_{ 2 },...,{ d }_{ n }\} $ و کلمات $ w \in W=\{ { w }_{ 1 },{ w }_{ 2 },...,{ w }_{ m }\} $ هستند، مرتبط میسازد. این مدل یک فرض احتمالاتی شرطی مستقل را معرفی میکند. بدین ترتیب که w و d بهصورت شرطی مستقل از هم میباشند. ازآنجاییکه تعداد متغیرهای پنهان z در مجموعه کلمه/متن کوچکتر از تعداد متون و کلمات است، از z بهعنوان متغیر فرعی در پیشبینی کلمات استفاده میشود. مدل احتمالاتی مشترک روی کلمات و متون با رابطهی احتمالاتی زیر تعریف میشود:
$$P({ w }_{ i },{ d }_{ j })=P({ d }_{ j })\sum _{ { z }_{ k }\in Z }{P({w}_{i}|{z}_{k})P({z}_{k}|{d}_{j})} $$
### ۲. ۲. ۲. مدل LDA[^Latent Dirichlet Allocation]
این روش سادهترین روش است. ابتدا ایدههای اساسی که این روش مبتنی بر آنهاست را توضیح میدهیم. این روش فرض میکند که اسناد موضوعات متعددی را نمایش میدهند؛ یعنی از کلماتی تشکیل شده است که هر یک متعلق به یک موضوع است و نسبت موضوعات داخل یک متن با هم متفاوت است. با توجه به این نسبتها میتوانیم آن متن را در یک موضوع خاص دستهبندی کنیم.[۷]
مجموعهی ثابتی از کلمات را به عنوان واژهنامه در نظر میگیریم. روش LDA فرض میکند که هر موضوع توزیعی روی این مجموعه کلمات است؛ یعنی کلماتی که مربوط به یک موضوع هستند در آن موضوع دارای احتمال بالایی هستند. فرض میکنیم این موضوعات از قبل مشخص هستند. حال برای هر سند از مجموعه اسنادی که در اختیار داریم کلمات را در دو مرحلهی زیر تولید میکنیم:
+ به طور تصادفی توزیع احتمالی را روی موضوعات انتخاب میکنیم.
+ برای هر کلمه از سند:
+ به طور تصادفی موضوعی را با استفاده از توزیع احتمال مرحلهی قبل مشخص میکنیم.
+ به طور تصادفی کلمهای را از واژهنامه با توزیع احتمال مشخصشده انتخاب میکنیم.
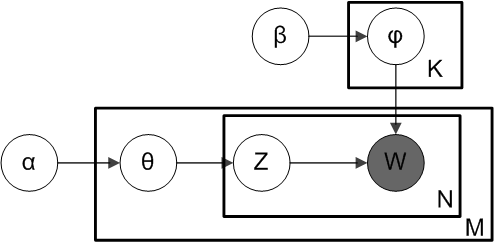
در این مدل احتمالی، اینکه هر سند از چندین موضوع تشکیل شده است را منعکس میکند. مرحلهی اول این قسمت را منعکس میکند که موضوعات مختلف در یک متن با نسبتهای متفاوتی سهیم هستند. قسمت دوم مرحلهی دوم هم بیانگر این است که هر کلمه در هر سند از یکی از موضوعات استخراج شده است و قسمت اول مرحلهی دوم هم بر این نکته تأکید دارد که این موضوع از توزیع احتمال موضوعات روی اسناد انتخاب شده است. ذکر این نکته لازم است که در این روش همهی اسناد مجموعهی یکسانی از موضوعات را در اختیار دارند ولی هر سند این موضوعات را با نسبتهای متفاوتی ارائه میکند.
حال میخواهیم تعریف رسمیتری از LDA ارائه دهیم. موضوعات ما ${β}_{1:k}$ هستند که هر ${β}_{i}$ یک توزیع احتمال روی مجموعهی کلمات است. نسبت موضوعات برای اسناد با پارامتر $θ$ مشخص میشود. بدین معنی که ${θ}_{d,k}$ بیانگر نسبت موضوع k در سند d است. پارامتر z بیانگر تخصیص موضوع است. ${z}_{d,n}$ موضوع تخصیص داده شده به کلمهی n-اُم از سند d است. w کلمات مشاهدهشده است که ${w}_{d,n}$ کلمهی n-اُم از سند d است.
با توجه به تعاریف بالا الگوریتم LDA را میتوان با فرمول زیر که شامل متغیرهای آشکار و پنهان فوق میباشد بیان کرد:
$$P({ \beta }_{ 1:K },{ \theta }_{ 1:D },{ z }_{ 1:D },{ w }_{ 1:D })=\prod { P({ \beta }_{ i }) } \prod { P({ \theta }_{ d }) } (\prod { P({ z }_{ d,n }|{\theta}_{d})P({w}_{d,n}|{\beta}_{1:K},{z}_{d,n}) } )$$
از فرمول بالا میتوان به مجموعهای از وابستگیها پی برد. مثلاً موضوع تخصیص داده شده به هر کلمه در یک سند (${z}_{d,n}$) بستگی به نسبت موضوعات برای آن سند (${θ}_{d}$) دارد و یا کلمهی مشاهدهشده در هر سند (${w}_{d,n}$) بستگی به موضوع اختصاص داده شده به آن کلمه (${z}_{d,n}$) و همهی موضوعات (${β}_{1:k}$) دارد؛ یعنی ${z}_{d,n}$ موضوع مربوط به آن کلمه را مشخص میکند و بعد احتمال حضور آن کلمه در آن موضوع یعنی ${w}_{d,n}$ مشخص میشود.
اکنون میخواهیم احتمال موضوعات مشخصشده را حساب کنیم؛ یعنی همانطور که قبلاً ذکر شد با وجود متغیرهای آشکار با چه احتمالی متغیرهای پنهان حضور دارند. این کار با فرمول زیر محاسبه میشود:
$$P({ \beta }_{ 1:K },{ \theta }_{ 1:D },{ z }_{ 1:D }|{ w }_{ 1:D })=\frac { P({ \beta }_{ 1:K },{ \theta }_{ 1:D },{ z }_{ 1:D },{ w }_{ 1:D }) }{ P({ w }_{ 1:D }) } $$
صورت کسر با توجه به فرمول قبل محاسبه میشود. مخرج کسر هم بهراحتی از کلمات مشاهدهشده به دست میآید.
تعداد ساختارهای موضوعی پنهان بسیار زیاد است و محاسبهی آن بهراحتی امکانپذیر نیست. این موضوع به علت صورت کسر بالا است. به همین علت برای محاسبهی این عبارت آن را تخمین میزنند. الگوریتمهای مدلسازی موضوعی عبارت بالا را اینگونه تخمین میزنند که به جای توزیع بالا از یک توزیع احتمال دیگر که نزدیک به مقدار واقعی باشد استفاده میکنند. این الگوریتمها معمولاً به دو دسته تقسیم میشوند: دستهی اول الگوریتمهایی هستند که بر اساس نمونهبرداری عمل میکنند و دستهی دوم الگوریتمهای مبتنی بر تغییرات هستند. در الگوریتمهای دستهی اول با استفاده از نمونهبرداری از یک توزیع تجربی استفاده میشود درحالیکه در الگوریتمهای دستهی دوم بهجای نمونهبرداری از جایگزینهای قطعی استفاده میشود. در این دسته از الگوریتمها مسئله به یک مسئلهی بهینهسازی تبدیل میشود.
# ۳. آزمایشها
## ۳. ۱. مجموعه داده
مجموعه آزمایش همشهری یکی از معتبرترین منابع در زبان فارسی است. نسخه ۱ همشهری شامل بیش از ۱۶۰۰۰۰ سند، ۶۵ درخواست و قضاوتهای مرتبط است که از سال ۱۳۷۵ تا ۱۳۸۱ توسط افراد مختلف با موضوعات مختلف نوشته شده است. نسخه ۲ همشهری نسبت به نسخه قبل بزرگتر و جامعتر است که تصاویر مقالات را نیز در بر دارد. مولفان روزنامه همشهری بصورت دستی مقالات خود را به دستههای مختلفی تقسیم کردند و آن را در سایت پیکره همشهری قرار دادند. تمام اسناد در این مجموعه به ۸۲ موضوع مختلف بر اساس دسته اخبار موجود در سایت روزنامه دستهبندی شدهاند. بعنوان مثال siasi به معنی سیاسی است در فارسی و political در انگلیسی است. نامهای انگلیسی و فارسی دستههای اصلی (۱۶ دسته مهم از بین ۸۲ دسته موجود که بیشترین اسناد را دارند) پیکره در جدول زیر آمده است.
| تگ دسته | نام دسته به فارسی | نام دسته به انگلیسی |
|:-------------:|:----------------------:|:-------------------------:|
| Adabh | هنری - ادبی | Art-Literature |
| Akhar | اخبار کوتاه | Short news |
| Bankb | بورس و بانک | Stock market & Banking |
| Econw | اقتصاد جهانی | World’s Economy |
| Ejtem | اجتماعی | Society |
| Elmif | علمی و فرهنگی | Science & Culture |
| Eqtes | اقتصادی | Economy |
| Gards | گردشگری | Tourism |
| Gungn | گوناگون | Miscellaneous |
| Havad | حوادث | Social event |
| Ikaba | فناوری اطلاعات | Information Technology |
| Kharj | اخبار خارجی | Foreign news |
| Shahr | شهر تهران | Tehran & Municipal affairs|
| Shrst | شهرستانها | Iran cities(except Tehran)|
| Siasi | سیاسی | Politic |
| Vrzsh | ورزشی | Sport |
از ۸۲ دسته موجود تنها ۱۲ دسته بیش از ۱۰۰۰ سند دارند که ۷۲ درصد مجموعه را شکل میدهند.
## ۳. ۲. پیشپردازش متن
در مرحلهی پیشپردازش متن، روی دادههای ورودی عملیاتی انجام میشود تا به صورتی درآیند که برای پردازش مناسبتر باشنداین عملیات ممکن است حذف بعضی کلمات و یا تغییر شکل آنها باشد.
### ۳. ۲. ۱. فیلتر کردن
فیلتر کردن شامل حذف کلماتی است که اطلاعات مفیدی در مورد متن در اختیار قرار نمیدهندبهعنوان مثال صفحات وب دارای تگهای اضافی میباشند که این تگها باید حذف شوند.
### ۳. ۲. ۲. نرمال سازی و اصلاح نویسه ها
یکی از مشکلات زبان فارسی وجود چند نمونه ی مختلف از یک نویسه است، که کار جستجو در متون فارسی را مشکل می کند. در این مرحله کاراکترهای غیر استاندارد با کاراکترهای استاندارد جایگزین می شوند وکاراکترهای اضافی نیز بسته به نوع پردازش از بین می روند تا واژه های یکسان در تمامی متن به یک صورت نوشته شده باشند.
### ۳. ۲. ۳. ریشه یابی
پروسه ریشه یابی کلمات را به صورت عبارت پایه آن در می آورد. برای مثال، کلمه "روش هایم"، "روشی"، "روشمند" هر سه از ریشه روش هستند. روش های ریشه یابی اغلب مبتنی بر زبان هستند.
### ۳. ۲. ۴. حذف کلمات توقف
کلمه ایست به کلمه ای گفته می شود که به تنهایی معنای خاصی را نمی رساند. یک روش ابتدایی برای حذف کلمات توقف مقایسه هر کلمه با مجموعه ای از کلمات توقف شناخته شده است. روش دیگر این است که ابتدا عملیات برچسب زنی اجزای سخن صورت گرفته و سپس تمامی تکه هایی که اسم، فعل و یا صفت نیستند را حذف کرد.
## ۳. ۳. نتایج اولیه
برای پیادهسازی از کتابخانهی gensim در زبان پایتون استفاده شدهاست. همچنین مدلهای موضوعی ساخته شده از روش LDA استفاده میکنند.
نتایج حاصل از پیادهسازی اولیه بر روی دادههای پیکرهی همشهری با ۴۰ مو ضوع به صورت زیر است:
----------
Top 10 terms for topic #0: ایران, تهران, تیم, کشور, مجلس, اسلامی, سازمان, سال, شورای, وی
Top 10 terms for topic #1: تیم, فوتبال, بازی, بورس, جام, ریال, سهام, میلیارد, ملی, سرمایه
Top 10 terms for topic #2: بورس, تیم, سهام, ریال, میلیارد, سرمایه, فوتبال, شاخص, سهم, هزار
Top 10 terms for topic #3: عراق, انتخابات, آمریکا, مجلس, فیلم, جمهوری, هستهای, شهرداری, جشنواره, ایران
Top 10 terms for topic #4: قتل, فیلم, شهرداری, بورس, دادگاه, متهم, مجلس, پرونده, شورای, عراق
Top 10 terms for topic #5: فیلم, جشنواره, قتل, دادگاه, پرونده, متهم, تهران, سینمای, شهرداری, ایران
Top 10 terms for topic #6: بورس, نفت, مجلس, فیلم, جشنواره, انتخابات, سهام, آمریکا, عراق, اسلامی
Top 10 terms for topic #7: شهرداری, فیلم, جشنواره, تهران, شهر, منطقه, عراق, شهری, شهردار, جامعه
Top 10 terms for topic #8: بورس, فیلم, شاخص, ریال, واحد, میلیارد, جشنواره, شهرداری, تهران, سود
Top 10 terms for topic #9: نفت, ریال, اوپک, عراق, میلیارد, آموزش, سود, مجلس, فیلم, قیمت
Top 10 terms for topic #10: آموزش, ریال, نفت, دانش, پرورش, انتخابات, سود, آموزان, شاخص, میلیارد
Top 10 terms for topic #11: فیلم, نفت, بیمه, کتاب, نمایشگاه, شاخص, جشنواره, ریال, واحد, عراق
Top 10 terms for topic #12: عراق, هستهای, شاخص, نفت, واحد, انتخابات, بورس, ایران, سرمایه, هزار
Top 10 terms for topic #13: کشتی, شاخص, کیلوگرم, واحد, عراق, وزن, نفت, بورس, فوتبال, بازی
Top 10 terms for topic #14: کشتی, عراق, شاخص, واحد, بورس, هستهای, کیلوگرم, انتخابات, نفت, ریال
Top 10 terms for topic #15: عراق, بیمه, هستهای, دانش, آموزان, آموزش, پرورش, مدارس, انتخابات, اجتماعی
Top 10 terms for topic #16: کتاب, مجلس, استان, نمایشگاه, عراق, انتخابات, لایحه, فیلم, کمیسیون, اسرائیل
Top 10 terms for topic #17: اسرائیل, عراق, بیمه, فلسطین, فلسطینی, نفت, غزه, استان, لبنان, صهیونیستی
Top 10 terms for topic #18: بیمه, نفت, مجلس, زنان, شهرداری, اسرائیل, هستهای, نمایشگاه, زیست, آب
Top 10 terms for topic #19: انتخابات, بیمه, کشتی, نمایشگاه, شهرداری, آب, اسرائیل, عراق, پزشکی, شاخص
Top 10 terms for topic #20: زیست, آب, محیط, استان, خودرو, بورس, ریال, نفت, دادگاه, حفاظت
Top 10 terms for topic #21: زنان, بیمه, انتخابات, کشتی, درصد, هستهای, استقلال, جوانان, پرسپولیس, نمایشگاه
Top 10 terms for topic #22: زنان, مجلس, انتخابات, دادگاه, روزنامه, مطبوعات, کمیسیون, کشتی, عراق, لایحه
Top 10 terms for topic #23: بیمه, انتخابات, خودرو, استان, قوه, مطبوعات, زنان, قضائیه, قتل, آب
Top 10 terms for topic #24: سود, عراق, کره, آمریکا, روسیه, میلیون, خالص, استان, هزار, سهام
Top 10 terms for topic #25: هستهای, سود, درصد, کره, زنان, عراق, شرکت, بیمه, سهام, میلیون
Top 10 terms for topic #26: بیمه, بورس, دانشگاه, زیست, سیمان, محیط, نمایشگاه, انتخابات, پارس, شبکه
Top 10 terms for topic #27: سیمان, دانشگاه, بورس, نمایشگاه, گذاری, سرمایه, پارس, پزشکی, استان, دانشجویان
Top 10 terms for topic #28: موسیقی, کتاب, زیست, شبکه, استان, محیط, ساعت, هستهای, خودرو, پخش
Top 10 terms for topic #29: نمایشگاه, موسیقی, آب, زیست, خودرو, کودکان, سازمان, سرمایه, محیط, مصرف
Top 10 terms for topic #30: والیبال, زنان, آب, کشتی, دادگاه, مسابقات, استقلال, عراق, پلیس, اروپا
Top 10 terms for topic #31: استان, زیست, استقلال, پرسپولیس, شبکه, ساعت, محیط, تیم, زنان, سازمان
Top 10 terms for topic #32: موسیقی, جشنواره, فیلم, کتاب, شبکه, اتحادیه, اروپا, هستهای, ترکیه, جمهوری
Top 10 terms for topic #33: شبکه, فوتبال, کره, پخش, پیکان, اروپا, اتحادیه, والیبال, جشنواره, سود
Top 10 terms for topic #34: روزنامه, نگاران, نمایشگاه, مطبوعات, انجمن, جشنواره, شبکه, زنان, آب, قوه
Top 10 terms for topic #35: لبنان, سوریه, فلسطین, فوتبال, حزب, حریری, مطبوعات, مجلس, شبکه, موسیقی
Top 10 terms for topic #36: فوتبال, لبنان, زنان, سازمان, بیمه, نرم, فدراسیون, بازی, والیبال, بودجه
Top 10 terms for topic #37: شبکه, نرم, پخش, کتاب, آمریکا, نگاران, روزنامه, شرکت, خودرو, کاربران
Top 10 terms for topic #38: استان, آب, هند, پاکستان, گاز, قیمت, سهام, زنان, نرم, جشنواره
Top 10 terms for topic #39: مطبوعات, روزنامه, لبنان, نگاران, استان, موسیقی, قیمت, پارس, سود, حجاریان
----------
## ۳. ۴. ارزیابی
یکی از چالشهای اساسی موجود در مدلسازی موضوعی نحوهی ارزیابی موضوعات ارائهشده توسط ماشین است. شاید حتی دو انسان خبره نیز نتوانند به سر اینکه یک متن دارای چه موضوعی است به توافق برسند. از طرف دیگر بیان موضوعات با استفاده از چند کلمه کار ارزیابی را سختتر میکند. میتوان برای ارزیابی اسنادی را به ماشین داد تا توزیع موضوعات برای آن سند توسط ماشین مشخص شود سپس موضوعی را که دارای بیشترین احتمال برای آن سند است را به عنوان موضوع آن سند در نظر گرفت و موضوع پیشنهاد شده را با قضاوت یک انسان مقایسه نمود. البته که این کار مستلزم صرف زمان زیادی است.
در زیر چند نمونه از معیارهای کمی برای ارزیابی بیان شده است.
### ۳. ۴. ۱.معیار perplexity برای ارزیابی مدلسازی موضوعی
معمولترین راه برای ارزیابی یک مدل احتمالی اندازهگیری لگاریتم احتمال وقوع برای یک مجموعه دادهی آزمون که قبلاً مشاهده نشده، میباشد.
این روش با جداسازی مجموعهی داده به دو قسمت انجام میگیرد. یک از قسمتها برای یادگیری استفاده میشود و قسمت دیگر برای تست روش در نظر گرفته میشود. برای مدل LDA مجموعهی دادهی تست، مجموعهای از اسناد $ (\boldsymbol w_d)$ است که قبلاً مشاهده نشده باشد و مدل با استفاده از ماتریس موضوعات $(\boldsymbol \Phi)$ و یک پارامتر $ \alpha$ برای توزیع موضوعات روی اسناد توصیف میشود.
برای محاسبهی معیار لگاریتم احتمال وقوع از فرمول زیر استفاده میکنیم.
$$\mathcal L (\boldsymbol w) = \log p(\boldsymbol w | \boldsymbol \Phi, \alpha) = \sum_d \log p(\boldsymbol w_d | \boldsymbol \Phi, \alpha).$$که در آن $\boldsymbol w_d$ اسناد مشاهده نشده، موضوعات دادهشدهی $\boldsymbol \Phi$ و $ \alpha$ پارامتر توزیع احتمال موضوعات $(\boldsymbol \theta d)_d$ برای اسناد است.
احتمال وقوع اسناد مشاهده نشده در زمان آموزش میتواند برای مقایسهی مدلهای موضوعی مختلف استفاده شود. مدلهای با احتمال وقوع بالاتر مدلهای بهتری هستند.
معیاری که بهطور سنتی برای ارزیابی مدلهای موضوعی استفاده میشود perplexity اسناد مشاهده نشده است که از طریق فرمول زیر محاسبه میشود.
$$\text{perplexity}(\text{test set } \boldsymbol w) = \exp \left\{ - \frac{\mathcal L(\boldsymbol w)}{\text{count of tokens}} \right\}$$که تابعی نزولی از لگاریتم احتمال وقوع اسناد مشاهده نشده است. هر چه میزان perplexity کمتر باشد مدل بهتر است.
محاسبهی احتمال $p(\boldsymbol w_d | \boldsymbol \Phi, \alpha)$ یک سند کار سادهای نیست درنتیجه سنجش $\mathcal L(\boldsymbol w)$ و همچنین perplexity کار غیرممکنی است. [۸] روشهای مختلفی برای تقریب زدن این احتمال استخراج کرده است.
**معیار perplexity به قضاوتهای انسان نزدیک نیست.**
در [۹] نشان داده است که بهصورت شگفتآوری پیشبینی احتمال وقوع (و همارز آن perplexity) و قضاوتهای انسان در اغلب موارد مرتبط نیست و حتی در بعضی موارد اندکی متضاد هستند.
آنها آزمایش بزرگی روی دادههای آمازون انجام دادند. برای هر موضوع آنها پنج کلمه (مرتبشده بر اساس بیشترین تکرار $p(w|k) = \phi_{kw} )$ را انتخاب کردند و کلمهی ششم را بهصورت تصادفی به آن اضافه کردند. سپس آنها لیستی از ۶ کلمه را به شرکتکنندگان در آزمایش ارائه کردند و از آنها درخواست کردند تا کلمهی مزاحم را تشخیص دهند.
اگر همهی شرکتکنندگان میتوانستند کلمهی مزاحم را تشخیص دهند آنها میتوانستند نتیجه بگیرند که آن کلمات توضیحدهندهی خوبی برای آن موضوع هستند؛ اما درصورتیکه اکثر شرکتکنندگان یکی از کلمات داخل موضوع را بهعنوان کلمهی مزاحم انتخاب میکردند، به این معنی بود که آنها نتوانستهاند یک ارتباط منطقی در بین کلمات پیدا کنند و نتیجهاش این است که آن موضوع یک موضوع خوب نیست.
نتایج آنها ثابت کرد که برای یک موضوع، پنج کلمهای که بیشترین تکرار را در موضوع خود دارند معمولاً توصیف خوبی از یک معنی مربوط را ارائه نمیکند یا حداقل اینکه آنقدرها خوب نیست که بتواند یک کلمهی مزاحم را متمایز کند.
### ۳ .۴. ۲. چسبندگی موضوعات برای ارزیابی مدلهای موضوعی
عدم ارتباط perplexity به قضاوتهای انسانی انگیزهای برای کار بیشتر در زمینهی مدل کردن قضاوتهای انسانی شد. این کار بهخودیخود امری سخت و پیچیده است به دلیل اینکه قضاوتهای انسانی بهروشنی قابلتعریف نیست. بهطور مثال دو انسان خبره ممکن است بر روی مفید بودن یک موضوع اتفاقنظر نداشته باشند.
روشهای مدل کردن قضاوتهای انسانی در دو دسته مورد توجه قرار میگیرند:
روشهای ذاتی (درونی) [^Intrinsic] : که از هیچگونه منبع خارج از مجموعهداده استفاده نمیکنند درحالیکه روشهای غیر ذاتی (خارجی)[^extrinsic] از موضوعات اکتشافی مانند بازیابی اطلاعات برای کارهای خارجی یا آمارهای خارجی برای ارزیابی موضوعات استفاده میکنند.
بهعنوان یک روش اولیه ذاتی، [۱۰] معیارها را بر اساس سه نمونهی اولیه از موضوعات ناچیز و بیارزش تعریف میکند. سه نمونه اولیه برای موضوعات بیارزش شامل توزیع یکنواخت کلمات، پیکرهی تجربی توزیع کلمات و توزیع یکنواخت اسناد میشوند.
$$p(w | \text{topic}) \propto 1 \qquad p(w | \text{topic}) \propto \text{count}(w \text{ in corpus}) \qquad
p(d | \text{topic}) \propto 1$$سپس میزان اهمیت یک موضوع بر اساس شباهتها و تفاوتها (KL divergence, cosine, and correlation) برای این سه نمونه محاسبه میشود. بههرحال میزان اهمیت یک تابع پیچیده با پارامترهای آزاد است که بهصورت اختیاری انتخاب میشوند بنابراین خطر overfitting دو مجموعه دادهی آزمایش بالاست.
قسمت اصلی در بحث چسبندگی موضوعات معیار ذاتی UMASS و معیار غیر ذاتی UCI هستند. هر دو معیار از یک ایدهی کلی استفاده میکنند هر دو معیار مجموع
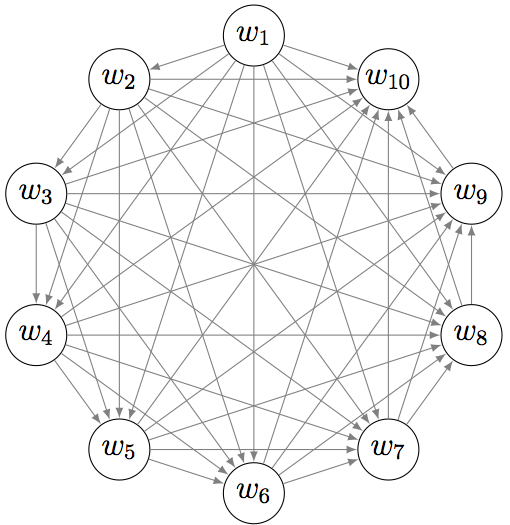
$$\text{Coherence} = \sum_{i \lt j} \text{score}(w_i, w_j)$$امتیازهای هر دو جفت از کلمات $w_1,..., w_n$ که برای توصیف یک موضوع استفاده شدهاند را محاسبه میکنند. اغلب n کلمه با بیشترین تکرار (p(w|k). این معیار میتواند بهصورت مجموع تمام یالهای گراف کامل مشاهده شود.
اگرکه $D(w_i)$ را تعداد اسناد شامل کلمهی $w_i$، $D(w_i, w_j)$ را تعداد اسناد شامل هر دو کلمهی $w_i$ و $w_j$ و $D$ را مجموع کل اسناد داخل پیکره در نظر بمیگیریم. پیکرهای که برای محاسبه استفاده میشود بهعنوان زیرنویس $D$ نوشته میشود. بهطور مثال $D_{\text{Wikipedia}}(w_i)$ تعداد اسناد پیکرهی ویکیپدیایی است که شامل کلمهی $w_i$ است. هنگامیکه هیچ زیرنویسی نوشته نمیشود بدین معنی است که پیکرهای که استفاده میشود همان پیکرهای است که مدل با آن آموزش دیده است.
**معیار غیر ذاتی UCI**
معیار غیر ذاتی UCI که در [۱۱] معرفیشده است از تابع محاسبه امتیاز PMI استفاده میکند.
$$\text{score}_{\text{UCI}}(w_i, w_j) = \log \frac{p(w_i, w_j)}{p(w_i)p(w_j)}$$که در آن$ p(w_i)$ احتمال مشاهدهی $w_i$ در یک سند تصادفی و $p(w_i,w_j)$ احتمال مشاهدهی همزمان $w_i$ و $w_j$ در یک سند تصادفی است. این احتمالات بهصورت تجربی از یک مجموعه دادهی خارجی مانند ویکیپدیا تخمین زده میشوند.
$$p(w_i) = \frac{D_{\text{Wikipedia}}(w_i)}{D_{\text{Wikipedia}}} \qquad \text{and} \qquad p(w_i, w_j) = \frac{D_{\text{Wikipedia}}(w_i, w_j)}{D_{\text{Wikipedia}}}$$برای محاسبهی این احتمالات انتخاب هر پیکرهای آزاد است. دلیلی که برای عدم استفاده از دادههای مدل آموزش بیان میشود این است که انتخاب همان مجموعهداده آمار کلمات نویز و غیرمعمول را تقویت میکند.
بههرحال تعدادی معیار ذاتی چسبندگی موضوع نیز توسعه یافتهاند که نسبت به معیار perplexity بیشتر به قضاوتهای انسانی مرتبط هستند [Mimno11a. ۱۲]
**معیار ذاتی UMass**
معیار ذاتی UMass که در [۱۲] معرفیشده است از تابع امتیاز زیر محاسبه میشود.
$$\text{score}_{\text{UMass}}(w_i, w_j) = \log \frac{D(w_i, w_j) + 1}{D(w_i)}$$که در آن تابع احتمال شرطی لگاریتمی $\log p(w_j|w_i) = \log \frac{p(w_i, w_j)}{p(w_j)}$ با اضافه کردن ۱ به $D(w_i, w_j)$ هموارشده است.
این تابع امتیاز متقارن نیست به دلیل اینکه این تابع یک تابع افزایشی از احتمال $p(w_j|w_i)$ است که در آن $w_i$ متداولتر از $w_j$ است کلمات بر اساس کاهش میزان تکرار $p(w|k)$ مرتبشده است.
# ۴. بهبود نتایج
## ۴. ۱. افزایش دادههای آموزش
برای افزایش دقت نتایج و همچنین چسبندگی بیشتر کلمات موضوعات اسناد آموزش به ۲۰۰ هزار سند افزایش یافت. با افزایش دادههای آموزش مشکلاتی نیز به وجود میآید از جمله اینکه زمان پردازش اطلاعات بسیار بالا میرود که برای حل این مشکل از اجرای موازی بر روی چند هسته که داخل کتابخانهی برنامهی gensim نیز موجود است کمک گرفتیم. همچنین حجم زیاد اطلاعات جای گیری آنها را در حافظهی اصلی غیرممکن میساخت به همین دلیل مجبور به ذخیرهی اطلاعات بر روی حافظه جانبی و پردازش تکه به تکهی اطلاعات شدیم. نتایج حاصل از مدلسازی موضوعی با ۴۰ موضوع در زیر آمده است:
----------
Top 10 terms for topic #0: ایران, گذاری, پارس, سرمایه, قیمت, سیمان, داروسازی, بهار, قند, آزادی
Top 10 terms for topic #1: ایران, آمریکا, گفت, سازمان, کرد, اروپا, هستهای, کشورهای, روسیه, کشور
Top 10 terms for topic #2: سال, زمین, جمعیت, جهان, قرار, منطقه, آب, مناطق, شده_است, دو
Top 10 terms for topic #3: میکند, زندگی, میشود, دست, کنید, نیست, میکنند, باشد, کردن, کار
Top 10 terms for topic #4: شرکت, ایران, صنایع, گاز, تولید, سال, نفت, کشور, سرمایه, میلیون
Top 10 terms for topic #5: میشود, بیماری, استفاده, مصرف, میکند, بدن, مواد, درمان, غذایی, میکنند
Top 10 terms for topic #6: قانون, گفت, مجلس, دادگاه, کرد, رئیس, جلسه, هیات, روزنامه, مطبوعات
Top 10 terms for topic #7: نمایشگاه, کشتی, سال, برگزار, کیلوگرم, تهران, ایران, وزن, خیابان, ساعت
Top 10 terms for topic #8: درصد, بورس, سال, سهام, هزار, میلیارد, میلیون, ریال, شرکت, افزایش
Top 10 terms for topic #9: عراق, افغانستان, نیروهای, کشور, کرد, جنگ, نظامی, دولت, گفت, ترکیه
Top 10 terms for topic #10: برگزار, فرهنگی, اسلامی, میشود, روز, فرهنگ, مراسم, همایش, برگزاری, گفت
Top 10 terms for topic #11: حج, گفت, کرد, سال, کشور, زائران, اسپانیا, زیارت, سازمان, تهران
Top 10 terms for topic #12: چای, ایران, سال, کشور, ماه, گفت, سبز, دندانها, برگ, کرد
Top 10 terms for topic #13: کتاب, زبان, آثار, چاپ, کار, هنر, شعر, فرهنگ, ترجمه, ادبیات
Top 10 terms for topic #14: موسیقی, سال, ایران, اجرا, ایرانی, گروه, اجرای, استاد, ارکستر, ساز
Top 10 terms for topic #15: امام, حضرت, الله, قرآن, علی, مردم, اسلام, پیامبر, اسلامی, خدا
Top 10 terms for topic #16: سال, جهان, جهانی, جنوبی, کشور, کشورهای, کره, آلمان, ژاپن, ایتالیا
Top 10 terms for topic #17: فیلم, جشنواره, نمایش, سینما, سینمای, فیلمهای, تئاتر, سینمایی, میشود, بازی
Top 10 terms for topic #18: ورزش, ورزشی, فدراسیون, بدنی, تربیت, مسابقات, ملی, کمیته, المپیک, وزنه
Top 10 terms for topic #19: دانشگاه, دانشجویان, علمی, علوم, آموزش, کشور, پزشکی, عالی, آزمون, وزارت
Top 10 terms for topic #20: دولت, کشور, سال, اقتصادی, سازمان, بخش, برنامه, بودجه, قانون, گفت
Top 10 terms for topic #21: مردم, اسلامی, انتخابات, سیاسی, کشور, مجلس, کرد, جمهوری, انقلاب, شورای
Top 10 terms for topic #22: زنان, زن, خانه, خانواده, مرد, ازدواج, زندگی, مردان, کار, پدر
Top 10 terms for topic #23: پلیس, کرد, قتل, حادثه, شدند, دو, روز, قرار, گزارش, کردند
Top 10 terms for topic #24: کار, نیست, فکر, سال, میکنم, باشد, کردم, کنید, کرد, آقای
Top 10 terms for topic #25: آموزش, دانش, کودکان, پرورش, آموزان, آموزشی, اجتماعی, مدارس, کودک, مدرسه
Top 10 terms for topic #26: قیمت, تومان, شرکت, هزار, ریال, افزایش, سال, فروش, تن, سود
Top 10 terms for topic #27: جامعه, اقتصادی, توسعه, سیاسی, اجتماعی, کشور, مردم, جهانی, میشود, ایجاد
Top 10 terms for topic #28: ایران, جمهوری, رئیس, کشور, کرد, دو, روابط, اسلامی, گفت, دیدار
Top 10 terms for topic #29: اسرائیل, فلسطین, لبنان, کرد, حزب, رژیم, گفت, دولت, فلسطینی, وزیر
Top 10 terms for topic #30: تیم, بازی, فوتبال, جام, ملی, ایران, دو, کرد, گل, جهانی
Top 10 terms for topic #31: تهران, حمل, ترافیک, راه, نقل, تلفن, میشود, شهر, رانندگی, سال
Top 10 terms for topic #32: فرهنگی, اسلامی, گفت, فرهنگ, کرد, کشور, ایران, توسعه, سازمان, افزود
Top 10 terms for topic #33: تهران, شهر, شهرداری, شهری, منطقه, طرح, آب, شهردار, شهروندان, گفت
Top 10 terms for topic #34: آمریکا, استفاده, شرکت, اینترنت, سال, آمریکایی, جدید, روزنامه, بوش, قرار
Top 10 terms for topic #35: استان, گفت, کشور, افزود, کشاورزی, سازمان, سال, کرد, طرح, آب
Top 10 terms for topic #36: کشور, ایران, صنعت, تولید, اطلاعات, مواد, هند, گفت, بخش, زمینه
Top 10 terms for topic #37: انسان, فلسفه, نیست, میکند, نظر, جهان, جامعه, دین, باشد, دو
Top 10 terms for topic #38: نفت, بازار, قیمت, کاهش, افزایش, دلار, سال, تولید, اوپک, نفتی
Top 10 terms for topic #39: زیست, مصرف, محیط, تولید, خودرو, میشود, بنزین, آلودگی, حفاظت, خودروهای
----------
## ۴. ۲. ریشهیابی کلمات
همانطورکه در نتایج حاصل از مرحلهی قبل مشاهده میشود در بعضی از موضوعات کلمات به صورت مفرد و جمع تکرار شده است یا بعضی از افعال به شکلهای مختلف در یک موضوع آمدهاند. برای اینکه بتوانیم موضوعات را به صورت یکسان نشان دهیم قبل از مدلسازی کلمات داخل اسناد را ریشهیابی کردیم تا نتایج به صورت یکسانتری نمایش دادهشوند.
نتایج حاصل در زیر آمده است.
[خروجی ریشهیابی شده کلمات به صورت گرافیکی](https://dl.dropboxusercontent.com/s/h2pqoke67q9vzd3/TopicWithLemmaZoomableCircles.html)
----------
Top 10 terms for topic #0: استان, طرح, هزار, گفت#گو, کشور, سال, میلیون, شد#شو, افزود#افزا, کرد#کن
Top 10 terms for topic #1: بیمار, شد#شو, داد#ده, غذا, استفاده, داشت#دار, بود#باش, کرد#کن, مواد, توانست#توان
Top 10 terms for topic #2: شهر, سودان, کیش, شد#شو, تهران, کرد#کن, جزیره, کاروان, مرکزی, مشروطه
Top 10 terms for topic #3: نمایشگاه, ساعت, هنر, روز, آثار, موزه, نقاش, خیابان, برگزار, فرهنگ
Top 10 terms for topic #4: بود#باش, داشت#دار, کرد#کن, توانست#توان, داد#ده, گرفت#گیر, شد#شو, کار, جامعه, اجتماع
Top 10 terms for topic #5: شورا, مجلس, کرد#کن, گفت#گو, کشور, دولت, رئیس, داشت#دار, مرد#میر, سیاسی
Top 10 terms for topic #6: فیلم, سینما, نمایش, جشنواره, کارگردان, کرد#کن, ساخت#ساز, بازیگر, سال, تئاتر
Top 10 terms for topic #7: روزنامه, مطبوعات, کرد#کن, زندان, نگار, گفت#گو, کارگر, شد#شو, خبرنگار, انجمن
Top 10 terms for topic #8: قانون, حقوق, شد#شو, کرد#کن, بود#باش, مجلس, ماده, شورا, نامه, دادگاه
Top 10 terms for topic #9: کتاب, دانشگاه, سال, دکتر, استاد, ایران, فرهنگ, دوره, شد#شو, قرآن
Top 10 terms for topic #10: شد#شو, نیرو, حادثه, مسافر, انتظامی, کرد#کن, نفر, داد#ده, رانندگی, گفت#گو
Top 10 terms for topic #11: کتاب, چاپ, نویسنده, ترجمه, داستان, رمان, ناشر, نوشت#نویس, شد#شو, زبان
Top 10 terms for topic #12: اطلاعات, کشور, سیاسی, کرد#کن, گفت#گو, داشت#دار, عموم, وزارت, دولت, بود#باش
Top 10 terms for topic #13: سال, کرد#کن, چین, آمریکا, آلمان, فرانسه, کره, ژاپن, داد#ده, شد#شو
Top 10 terms for topic #14: فرهنگ, تاریخ, شعر, میراث, شهر, ایران, بنا, بود#باش, شد#شو, آثار
Top 10 terms for topic #15: کرد#کن, کشور, گفت#گو, ایران, وزیر, جمهوری, رئیس, آمریکا, خارجه, گزارش
Top 10 terms for topic #16: تیم, ایران, ورزش, کشت#کش, فدراسیون, مسابقات, ملی, قهرمان, رقابت, تهران
Top 10 terms for topic #17: عراق, زن, صدام, جنگ, کشور, شد#شو, کرد#کن, آمریکا, آمریکایی, بغداد
Top 10 terms for topic #18: دانش, آموزان, مدرسه, مدارس, شد#شو, درس, کلاس, کرد#کن, محیط, آموزش
Top 10 terms for topic #19: کرد#کن, شد#شو, پلیس, گفت#گو, داد#ده, دادگاه, قتل, داشت#دار, دستگیر, گرفت#گیر
Top 10 terms for topic #20: موسیقی, ایران, کرد#کن, اجرا, داشت#دار, هنر, شد#شو, سال, کار, تلفن
Top 10 terms for topic #21: نفت, شرکت, ایران, سرمایه, بازار, سهام, بورس, قیمت, گذاشت#گذار, دلار
Top 10 terms for topic #22: آب, سال, شد#شو, جنگل, کشاورزی, کشور, زیست, محیط, منطقه, گفت#گو
Top 10 terms for topic #23: فلسطین, اسرائیل, هوا, کرد#کن, انرژی, رژیم, صهیونیست, شد#شو, عرفات, آلودگی
Top 10 terms for topic #24: ورزش, بردار, وزنه, ورزشکار, کرد#کن, المپیک, ایران, قهرمان, داشت#دار, ملی
Top 10 terms for topic #25: سال, کشور, اقتصاد, دولت, درصد, کرد#کن, بخش, شد#شو, بانک, افزایش
Top 10 terms for topic #26: اسلام, فرهنگ, ایران, انقلاب, کرد#کن, امام, الله, جمهوری, گفت#گو, کشور
Top 10 terms for topic #27: کودک, نوجوان, باخت#باز, شد#شو, کرد#کن, مایکروسافت, بود#باش, داد#ده, ویندوز, داشت#دار
Top 10 terms for topic #28: داشت#دار, کودک, داد#ده, خانواده, کرد#کن, شد#شو, بود#باش, زندگی, زن, افراد
Top 10 terms for topic #29: کرد#کن, بود#باش, انسان, داشت#دار, گفت#گو, دین, شد#شو, داد#ده, تاریخ, فلسفه
Top 10 terms for topic #30: تیم, باخت#باز, فوتبال, کرد#کن, بازیکن, جام, باشگاه, داشت#دار, گل, داد#ده
Top 10 terms for topic #31: آموزش, دانشگاه, علم, پرورش, فرهنگ, کشور, سازمان, دانشجو, برنامه, تربیت
Top 10 terms for topic #32: اینترنت, استفاده, شد#شو, اطلاعات, برنامه, شبکه, کرد#کن, داد#ده, شرکت, تلویزیون
Top 10 terms for topic #33: کرد#کن, نیرو, عربستان, گفت#گو, کشور, ارتش, سعودی, داد#ده, آمریکا, نظام
Top 10 terms for topic #34: خودرو, تولید, قیمت, هزار, مصرف, شد#شو, بازار, سال, شرکت, گفت#گو
Top 10 terms for topic #35: کشور, آمریکا, ایران, جهانی, سازمان, کرد#کن, المللی, جهان, داد#ده, منطقه
Top 10 terms for topic #36: مرد#میر, کرد#کن, سیاسی, اسلام, داشت#دار, انتخابات, انقلاب, حزب, داد#ده, بود#باش
Top 10 terms for topic #37: شهر, سازمان, طرح, تهران, بهداشت, خدمات, پزشک, شد#شو, کرد#کن, گفت#گو
Top 10 terms for topic #38: تهران, شهر, شهردار, منطقه, کرد#کن, شد#شو, خیابان, شهروند, گفت#گو, ترافیک
Top 10 terms for topic #39: کرد#کن, شد#شو, داشت#دار, گفت#گو, بود#باش, داد#ده, رفت#رو, کار, زد#زن, آمد#آ
----------
## ۴. ۳. استفاده از عبارات اسمی
نتایج بالا نشاندهندهی آن است که عبارات فعلی موضوعات را به خوبی نشان نمیدهند به طور مثال افعال موجود در موضوع شمارهی ۳۹ دید واحدی مبنی بر وجود موضوع خاصی را منتقل نمیکنند. برای بهتر شدن نتایج در این مرحله جملات داخل اسناد با استفاده از یک برچسب گذار صرفی تحلیل شدهاند و کلماتی که در جمله نقش اسمی یا صفت را داشتهاند نگهداری شدهاند و افعال و کلمات ربط و ... در نظر گرفته نشده است. نتایج حاصل بهبود خوبی را نشان میدهند.