پیشنهاد دادن آنچه مخاطب از آن استقبال خواهد کرد، برعهده سامانههای توصیهگر است. این سامانهها که امروز، ما کاربر بسیاری از آنها هستیم، سعی میکنند از روی علاقهمندیهای ما و دیگران تصمیماتی بگیرند، مثلا اینکه ما چه کتابهایی را خواندهایم و افراد دیگرانی که علایقی مشابه ما داشتهاند، مثلا چه کتابهایی را خواندهاند، پیشنهاد مناسبی به ما بدهند.

# مقدمه
سامانه توصیهگر یا سامانه پیشنهادگر را میتوان یک سیستم فیلترینگ تلقی کرد از این منظر که اطلاعات را به منظور ارائه دادن اطلاعاتی که به خواستههای کاربر نزدیکتر و برای او مفیدترباشد براساس الگوریتمی که در اختیار دارد قغربال کرده و در قالب موردنظر به کاربر ارائه میدهد.
سامانه توصیهگر امروزه کاربرد بسیار گستردهای در زمینههای مختلف از قبیل شبکههای اجتماعی، پایگاه های خرید و فروش اینترنتی کتاب، موسیقی و، فیلم و غیره ، شرکتهای مسافرتی، و بسیاری کاربرد های دیگر.
امکان دارد این ابهام به وجود آید که چه زمانی از سامانه توصیهگر استفاده میشود و چه زمانی سامانه جستجوگر:
۱. وقتی که کاربر میداند دقیق چهچیزی نیاز دارد از جستجوگر و وقتی نمیدانند دقیقاً چه میخواهند از توصیهگر
۲. وقتی از کلمات کلیدی میتوانند برای توصیف نیاز خود استفاده کنند از جستجوگر و زمانی که نمیتوانند از توصیهگر
حال نگاهی به تاریخچه سامانه توصیهگر میاندازیم، اولین تلاش ها در قبل از سال ۱۹۹۰ بود که کامپیوتری به عنوان مسئول کتابخانه به نام [۱] Grundy تولید شد با اینکه بسیار ابتدایی بوده، ولی جرقهی اولیه برای ایجاد سامانههای توصیهگر پیچیدهتر بوده. در اوایل دهه ۹۰ به دلیل بالا رفتن سرسامآور مقدار دادهها و طرح راه حلی برای رویارویی با مساله ی سربار اطلاعات در وب الگوریتم فیلترینگ تجمعی به وجود آمد که در پایین توضیح داده خواهد شد[۲]،. بعد از آن سامانه توصیهگر پیشرفت زیادی کرد برای نشان دادن اطلاعاتی که کاربر به دیدن آنها علاقهمند است کرد[۳] که فقط کافی بود کاربر دست به نمرهدادن و نشان دادن علاقهی خود به برخی مباحث و کارهای کوچک دیگری بزند تا سیستم به او نزدیکترین پیشنهادات را بدهد که امروزه کاربرد آن بسیار بالا و علاقه نسبت به آن بسیار بالا رفته و در تمامی سایت های معروف توصیهگر کاربرد بالایی دارد مثل Netflix ، Good Reads ،و انواع شبکه های اجتماعی و ...، امروزه سیستم های توصیه گر به عنوان نمونه ای از سیستم های تصمیم یار شناخته می شوند که به عنوان یک شاخه ی مستقل مورد تحقیق و پژوهش قرار گرفته است.
سامانههای توصیهگر به صورت کلی مجموعهای از پیشنهادات را به کاربر برمیگرداند که به صورت کلی بر سه محوریت کلی دادهها دستهبندی میشوند:
۱. محتوا محور : به این منظور که سامانه توصیهگر بر اساس سلایق گذشته کاربر و همچنین بازخورد او نسبت به پیشنهاداتی که به او شده است نزدیکترین و بهترین پیشنهاد به او ارائه میشود.
۲. فیلترینگ تجمعی :در این رویکرد سلیقهی کاربر در نظر گرفته میشود و به دنبال کاربرانی میرویم که سلایق آن ها نزدیک به سلیقهی کاربر مورد نظر ما باشد سپس انتخاب های دیگر کاربران مشابه را که کاربر موردنظر انتخاب نکرده به او پیشنهاد میکنیم، همچنین تفاوت این رویکرد با رویکرد قبلی واضح است که در رویکرد اول به مقایسه محتواها برای یافتن پیشنهاد بهتری میگردیم با اینکه در این رویکرد به مقایسه کاربر ها میپردازیم.
۳.رویکرد ترکیبی : همانطور که از اسم این رویکرد معلوم است ترکیبی از دو رویکرد بالا میباشد.
# کارهای مرتبط
قبلتر اشاراتی به کاربرد ها و استفادههای گسترده سامانه توصیهگر در عصر حاضر کردیم و حال به صورت دقیقتر و با نگاهی کاربردیتر به آنها میپردازیم.
ابتدا با چند مثال در برخی از زمینههایی که سامانهتوصیهگر کاربرد دارد میپردازیم:
-شبکههای اجتماعی مانند linkedin ،facebook ،twitter و ...
-کتابخانههای الکتریکی برای گرفتن پیشنهاد کتاب و مقاله و انواع نوشته ها مانند which book ،my independent bookshop ،good reads و ...
ـ پایگاههای پیشنهاد و فروش فیلم و موسیقی مانندpandora radio ،spotify ،last.fm ،imdb ،flixter ،netflix و ...
ـ شرکتهای رزرواسیون و مسافرتی و ...
و هزاران کاربرد دیگر که و...
با اینکه دامنه کاربرد این سامانه بسیار گسترده است ولی از همه بیشتر در عرصه خرید و فروشهای اینترنتی کاربرد دارد.
حال به انواع رویکردها و شیوههای استفاده از سامانه توصیهگر که به صورت خلاصه به آن اشاراتی شد میپردازیم:
**۱.فیلترینگ تجمعی(collaborative filtering) :**
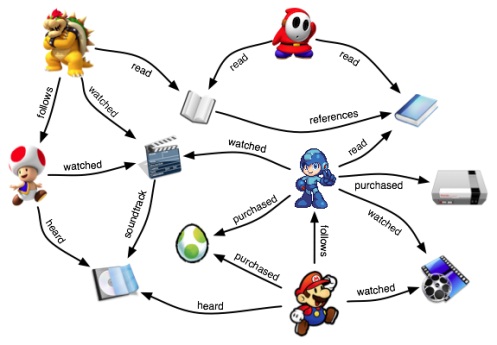
فیلترینگ تجمعی که به صورت خلاصه به آن cp میگویند رویکردی میباشد که در آن تمرکز بر روی شباهت کاربران به یکدیگر میباشد تا از این طریق بتوان پیشنهادات بهتری به کاربر موردنظر داد به این منظور که براساس نمرهدهی و نشاندادن علاقهی کاربران مشابه کاربر مورد نظر م،ا به او پیشنهاد میکنیم و. کاربران مشابه از طریق پیدا کردن علاقههای مشترک مشخص میشوند، یکی از خوبیهای cp این است که سیستم بدون هیچ درکی نسبت به محتوا میتواند پیشنهادات خوبی به کاربر بدهد که در این رویکرد الگوریتمهای متفاوتی مانند[۸] k-nearest approach و[۹] pearson correlation میتوان بهکاربرد.
برای جمع کردن اطلاعات از کاربران برای اینکه سامانه توصیهگر بتواند به کاربران پیشنهاداتی بکند چندین راه وجود دارد مانند:
درخواست نمرهدهی به اقلام از کاربر، درخواست جستجو کردن از کاربر، درخواست ایجاد لیستی از اقلام موردنظر از کاربر، نشان دادن چند نمونهی مختلف و درخواست ترجیح دادن بین آنها از کاربر، آنالیز کردن تعداد بازدید از اقلام مختلف، مشاهده اقلام خریداری شده توسط کاربر و ...
حال به برخی از مشکلات این رویکرد میپردازیم که عبارتند از : این رویکرد نیازمند اطلاعات و کاربران زیاد برای اینکه بتواند توصیههایی به کاربر بکند میباشد و از طرف دیگر جمع کردن این همه اطلاعات هزینه زیادی میبرد
**فیلترینگ محتوا محور(content based filtering)**

تفاوت این رویکرد با رویکرد قبلی در اینجاست که دیگر به کاربران مشابه به کاربر موردنظر برای پیشنهاد دادن به او نگاه نمیکنیم بلکه موضوعات و موارد مرتبط به آنهایی که قبلاً نسبت به آنها علاقهمندی نشان داده را به او پیشنهاد میکنیم.
از الگوریتم های کاربردی برای اینکار میتوان vector space representation را نام برد.
برای استفاده از این رویکرد نیاز به پردازش زبان طبیعی داریم تا بتوانیم کلمات کلیدی متعلق به ریشهی کلمات نسبت داده شده به یک مقاله یا کتاب یا هر قلم دیگری را بیرون بکشیم تا بتوانیم آنها را در مجموعههای مختلف جاسازی کنیم که در هرکدام از این مجموعهها موضوعات مرتبط به هم قرار دارند تا به کمک موضوعات قبلی مورد علاقه کاربر به او پیشنهاداتی بکنیم
از مشکلات این رویکرد میتوان به کم بودن اطلاعاتی که براساس آنها باید به کاربر پیشنهاداتی داد
اشاره کرد
http://www.boute.ir/projects/edit/169/
**توصیهگر ترکیبی( hybrid recommender systems )**
این رویکرد که رویکرد ترکیبی دو رویکرد قبلی میباشد میتواند در برخی موارد بهتر و بهینهتر باشد که این ترکیب میتواند به چند مدل پیادهسازی شود،میتوان به صورت جداگانه به هرکدام پرداخت سپس نتایج را با همدیگر ترکیب کرد یا فواید هرکدام از رویکرد ها را به دیگری اضافه کرد یا اینکه کاملاً آن دو را با هم ترکیب کنیم، نشان داده شده که با ترکیب این دو رویکرد میتوان ضعفهای هر کدام وقتی به تنهایی استفاده میشوند را پوشش داد که بهترین مثال این رویکرد netflix می باشد.
این رویکرد خود دارای زیرمجموعههای دیگری همچون demographic و knowledge base میباشد و دارای انواع مختلفی از ترکیب رویکرد ها میباشد.
# آزمایشها و انواع مختلفی از ترکیب رویکرد ها میباشد.
# آزمایشها
فارغ از اینکه کدام الگوریتم را انتخاب کنیم سه راه ارزیابی بهینه بودن آنها وجود دارد:
۱-کیفیت پیشنهادات: خیلی واضح است که میخواهیم پیشنهاداتی که به کاربر میدهیم مفید و کاربردی باشند و میخواهیم کارکرد بهتری نسبت به یک الگوریتم احمقانه داشته باشد که از میانگین نظرات برای دادن پیشنهاد استفاده میکند
۲-سرعت: اکثر سامانه های توصیهگر در اینترنت کارکرد دارند و به صورت آنلاین میباشند پس باید قابلیت پاسخگویی بسیار سریعی داشته باشند، یعنی نمیتوانند زمان زیادی را صرف اینکه چه پیشنهادی بدهند بکنند.
همچنین مسئله دیگری که باید در سرعت الگوریتم در نظر گرفته شود این است که سامانه های توصیهگر عموماً با dataset های عظیمی سر و کار دارند، پس باید قابلیت پاسخگویی در زمان کوتاه با توجه به وسعت dataset داشته باشند.
۳-راحتی به روز رسانی: به دلیل اینکه dataset یک سامانه توصیهگر دائماً در حال بروز رسانی میباشد الگوریتم مورد استفاده برای سامانه توصیهگر باید قابلیت تطبیق دادن خود با اطلاعات جدید وارد شده به dataset را داشته باشد و آنها را در پیشنهادات بعدی خود استفاده کند به جای اینکه زمان زیادی را صرف build کردن دوباره بر اساس اطلاعات جدید بکند کمتر مورد تایید قرار میگیرد.
# کارهای آینده
# مراجع
[1] E. Rich, “User modeling via stereotypes,” Cognitive Science, vol. 3, no. 4, pp. 329–354, October 1979
[2] D. Goldberg, D. Nichols, B. M. Oki , and D. Terry, “Using collaborative filtering to weave an information tapestry,” Communications of the ACM, vol. 35, no. 12, pp. 61–70, 1992
[3] P. Resnick, N. Iacovou, M. Suchak, P. Bergstrom, and J. Riedl, “GroupLens: an open architecture for collaborative filtering of netnews,” in ACM CSCW ’94 , pp. 175–186, ACM, 1994
[4] J. B. Schafer, J. A. Konstan, and J. Riedl, “E-Commerce recommendation applications,” Data Mining and Knowledge Discovery , vol. 5, no. 1, pp. 115–153, Janaury 2001
[5] Francesco Ricci and Lior Rokach and Bracha Shapira, [Introduction to Recommender Systems Handbook], Recommender Systems Handbook, Springer, 2011, pp
[6] Terveen, Loren; Hill, Will (2001). ["Beyond Recommender Systems: Helping People Help Each Other"]. Addison-Wesley. p. 6. Retrieved 16 January 2012
[7] Hosein Jafarkarimi; A.T.H. Sim and R. Saadatdoost [A Naïve Recommendation Model for Large Databases], International Journal of Information and Education Technology, June 2012
[8] Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. (2000). ["Application of Dimensionality Reduction in Recommender System A Case Study"](http://glaros.dtc.umn.edu/gkhome/node/122)
[9] Allen, R.B. (1990). "User Models: Theory, Method, Practice". International J. Man-Machine Studies
# پیوندهای مفید
+ [داده های ارزیابی نمونه](http://archive.ics.uci.edu/ml/datasets/Entree+Chicago+Recommendation+Data)
+ [Machine Learning Course - Recommender Systems](https://class.coursera.org/ml-003/lecture/preview)