1. **چکیده**
در میان انواع متعدی از نرم افزارهای مخرب، بات نت ها گسترده ترین و جدی ترین تهدیدی است که امروزه به طور معمول در حملات سایبری رخ می دهد. طبق آخرین گزارشات در سال 2013 میلادی بیش از 61 درصد ترافیک وب توسط شبکههای بات تولید میشود. به منظور مقابله موثر شبکههای بات، نیازمند بررسی دقیق کانالهای فرمان و کنترل در آنها هستیم. این مسأله تبدیل به یکی از چالشهای بزرگ برای سیستمهای امنیتی در سراسر جهان شده است، زیرا مهاجمین به سرعت در حال تغییر استراتژیهای خود برای کانالهای فرمان و کنترل هستند.
در این بروژه سعی شده است که ضمن معرفی اجمالی روشهای شناسایی بات نت، با استفاده از تکنیک های خوشهبندی(فازی، غیرفازی) و طبقه بندی الگو، رفتارهای شبکههای بات شناسایی و پیش بینی گردد.
**کلمات کلیدی**: شبکههای بات، دادهکاوی، خوشهبندی، طبقهبندی، امنیت شبکه، پیشبینی رویداد شبکه، تشخیص ناهنجاری.
2. **مقدمه**
در میان انواع متعدی از نرم افزارهای مخرب ، بات نت ها گسترده ترین و جدی ترین تهدیدی است که امروزه به طور معمول در حملات سایبری رخ می دهد. بات نت ها مجموعه از رایانه های در خطر هستند که از راه دور به وسیله bot master تحت زیرساخت مشترک C&C کنترل می شوند. تفاوت اصلی بین بات نت با سایر انواع بد افزارها وجود زیر ساخت C&C است که به بات ها اجازه می دهد که دستورات و command ها را دریافت کنند. Bot master باید مطمئن شود که ساختار C&C شان به اندازه کافی قوی است که هزاران بات توزیع شده در سراسر جهان را مدیریت کند و همچنین دربرابر هر گونه تلاش برای از بین بردن بات نت ها مقاوت کند.از بات نت ها در جرایم سازمان یافته به منظور نفوذ در سیستم های امنیتی دولت ها، بانک ها و شرکت ها استفاده فراوانی می شود و کاربرد حملات DDOS و تکنیک های دیگر در آن بسیار متداول است. در سالهای اخیر بر روی روشهای تشخیص و جلوگیری از باتنتها تحقیقات زیادی انجام شده است، اما باتنتها نیز به همان اندازه در حال رشد و گسترش هستند. مهاجمین برای محکم سازی زیربنای ارسال فرامین خود از انواع روشهای مختلف از قبیلِ رمزنگاری، پروتکلهای ارتباطی جدید و … استفاده میکنند. معماری اولیهی Command and Control (کانالهای فرمان و کنترل) باتنتها به صورت متمرکز بود، ولی به دلیل وجود Single point of failure (در این حالت کل باتنت از بین میرود)، امروزه از پروتکل ارتباطی نظیر به نظیر غیر متمرکز استفاده میکنند. در باتنتهای غیرمتمرکز با شناسایی تعدادی از میزبانهای آلوده به بات نمیتوان کل شبکه باتنت را از کار انداخت. باتنتهای غیر متمرکز به دو دسته ی نظیر به نظیر و Hybrid (ترکیبی) تقسیم میشوند. در یک باتنت نظیر به نظیر، باتها میتوانند با سایر باتها ارتباط برقرار کرده و ترافیک فرمان و کنترل را مبادله کنند.
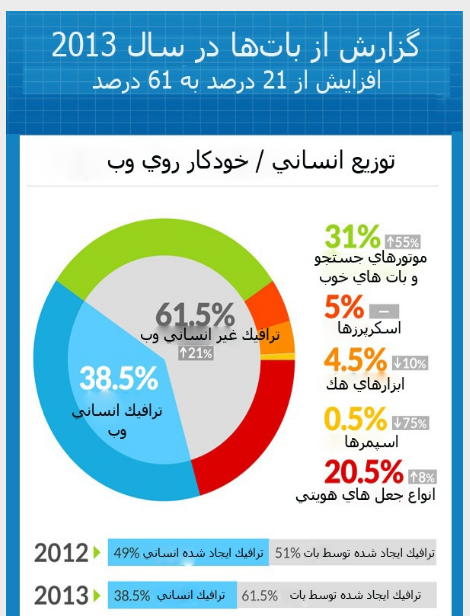
[شکل: ترافیک ایجاد شده توسط بات نت ها در سال 2013 و مقایسه آن با سال 2012](http://www.khabaronline.ir/detail/327613/ict/internet)
3.معماری بات نت ها
بات نت ها با توجه به سازوکاری که برای فرمان- کنترل خود استفاده میکنند از دو معماری کلی استفاده میکنند. معماری متمرکز و نامتمرکز:
1.3معماری متمرکز:
در معماری متمرکز که عمومی ترین معماری نیز میباشد، یک کارگزار فرمان- کنترل وجود دارد و تمام بات ها دستورات خود را از این کارگزار دریافت میکنند. حسن این معماری پیاده سازی آسان و امکان آرایش دهی سریع بات ها است به این معنی که با ارسال دستورات در مدت زمان کوتاهی میتوان بات ها را برای هدف خاصی آرایش داد. عیب اساسی این روش این است که اگر به دلیلی کارساز فرمان- کنترل از دسترس خارج شود، عملا بات نت از کار میافتد.
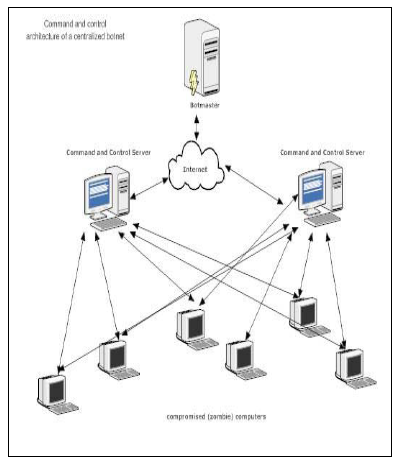شکل: معماری متمرکز شبکه های بات نت [8]
2.3معماری غیرمتمرکز:
در معماری نامتمرکز خلاف روش قبلی کنترل مرکزی وجود ندارد بلکه بات ها به صورت یک شبکه نظیر به نظیر با هم در تعامل میباشند. سرکرده دستورات خود را به یک یا چند بات ارسال میکند و با استفاده از قراردادهای نظیر به نظیر این دستورات در تمام بات نت منتشر میشود. حسن این روش است که تمام باتها به کارساز فرمان کنترل وابسته نیستند. توزیع ترافیک در این بات نت ها شناسایی آنها را دشوار کرده است. این باتنت ها مقیاس پذیری بالایی دارند اما پیاده سازی آنها پیچیده و دشوار است.
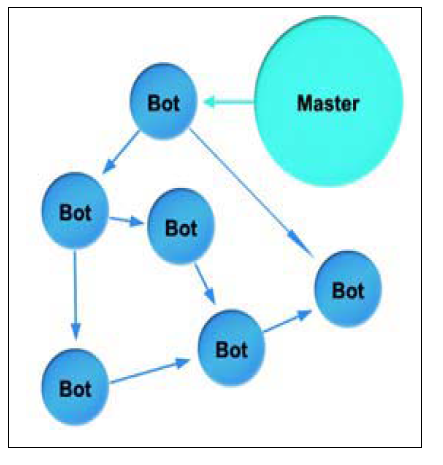شکل: معماری غیرمتمرکز شبکه های بات نت [8]
**4. روشهای شناسایی باتنت:**
1.4 روشهای مبتنی بر امضاء (Signature-Based):
این روشها بر اساس الگو و امضاء حملات عمل میکنند، یعنی سامانه تشخیص نفوذ دارای یک بانک اطلاعاتی است که در آن امضاء یا الگوی حملات شناخته شده وجود دارد و هر زمان که یکی از این الگوها در ترافیک شبکه مشاهده شود به عنوان حمله شناسایی میشود. به این روشها، قانون-محور (Rule-Based) نیز گفته میشود، زیرا با دنبالهای از دستورات If-Else پیاده سازی میشوند. از مزایای این روشها میتوان به سریع بودن، دقیق بودن و سربار کم آنها اشاره کرد. اما ایراد عمده این روش ها آن است که نسبت به تشخیص حملات Zero-Day ضعیف هستند. حملات Zero-Day به حملاتی گفته میشود که امضاء آنها در بانک امضاء سامانه تشخیص نفوذ وجود ندارد، یا به عبارتی دیگر، جدید هستند و مشابه آنها قبلا مشاهده نشده است.
2.4. روشهای مبتنی بر ناهنجاری (Anomaly-Based):
این روش ها سعی میکنند با الگوریتمها و تکنیکهای هوش مصنوعی (مثل شبکه های عصبی، خوشه بندی، درخت تصمیم و ...)، به مرور زمان ترافیک نرمال شبکه را بشناسند و سپس هر ترافیکی که خارج از نرم شبکه باشد را به عنوان نفوذ و تهدید تشخیص دهند. البته چالش اساسی این روشها تعریف ترافیک نرمال و یادگیری است که به آن Training گفته میشود و عملی زمان گیر است. روشهای مبتنی بر ناهنجاری دارای خطای (False Positive) بیشتری نسبت به روشهای مبتنی بر امضاء هستند و سربار آنها نیز بیشتر است. این روشها فقط قادراند وجود حمله و نفوذ را تشخیص دهند و نه نوع آن را.
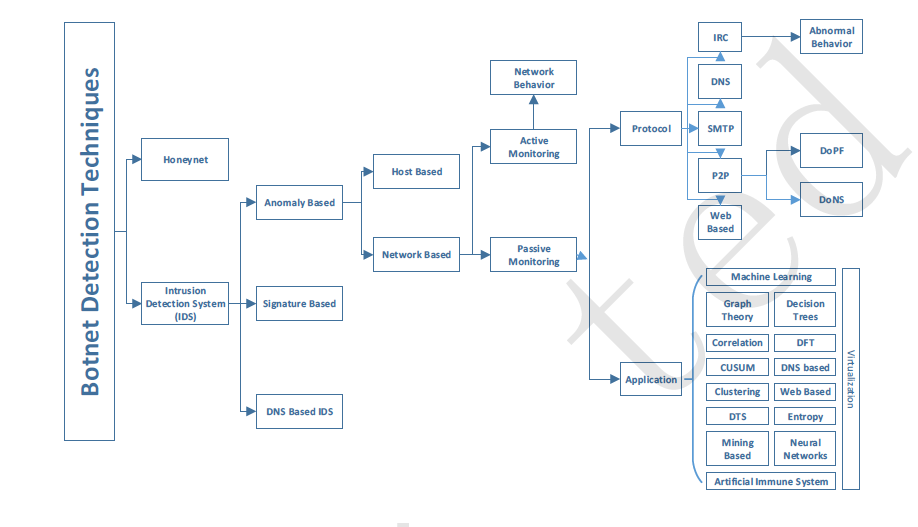 شکل: روش های شناسایی شبکه های بات نت [2]
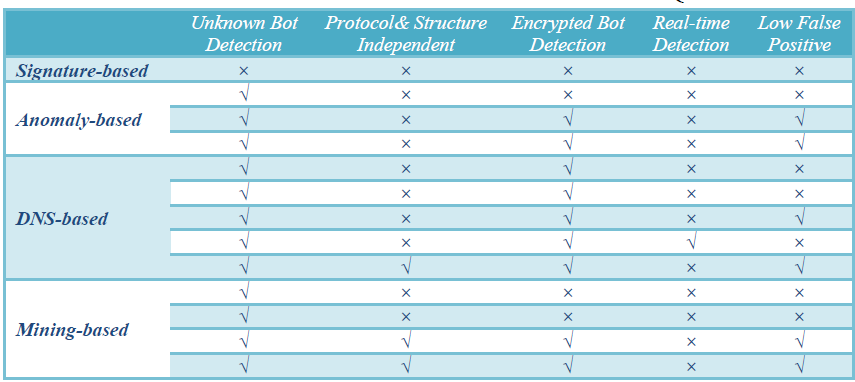 شکل: مقایسه روش های شناسایی شبکه های بات[7]
5.**پیاده سازی یادگیری در سیستم های مبتنی برناهنجاری**
1.5طبقه بندی (Classification): در روش طبقه بندی به نمونه های آزمایشی نیاز داریم تا از روی پارامترهای داخلی توانایی شناسایی و پیش بینی نوع شبکه بات مهیا شود. این روش، بدلیل اینکه به روش با نظارت صورت می پذیرد از دقت بالایی برخوردار است. در یک بیان دیگر، در این روش، ابتدا حمله را Simulate میکنیم و بعد نتیجه را به Classifier میدهیم،
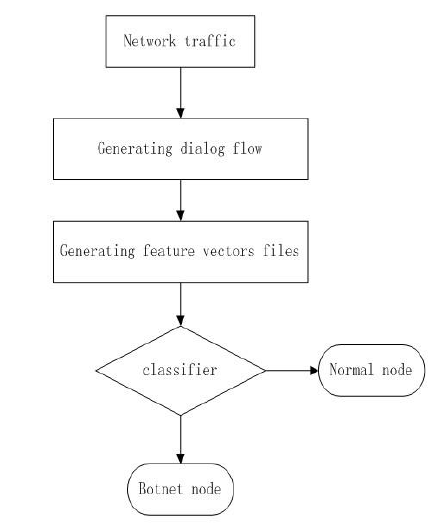 شکل: معماری روش طبقه بندی [10]
2.5خوشه بندی(Clustering):در آمار و یادگیری ماشینی، خوشهبندی یا آنالیز خوشه به فرایند گروهبندی اشیاء مشابه یکدیگر با هم است. خروجی الگوریتم خوشهبندی میتواند به دو صورت باشد: (۱) گروهبندی اشیا به مجموعههای مجزا یا (۲) خوشهبندی سلسله مراتبی که یک درخت برای تقسیمبندی اشیا پیدا میکند. از الگوریتمهای مشهور برای خوشهبندی میتوان به k-means اشاره کرد. در این روش احتیاجی به نمونه های آزمایشی نداریم، یعنی کلاس داده ها مشخص نیست. این روش بصورت بدون نظارت و با بررسی ترافیک شبکه آن دسته از اتصالاتی که شباهت یکسان دارد را در یک خوشه قرار می دهد.
**6کارهای مرتبط**
1.6چوی و همکاران [11] یک روش شناسایی بات نت مبتنی بر ناهنجاری شناسایی کرده اند که با نظارت بر فعالیت گروهی در سرویس DNS بات نت ها را در چرخه حیات خود تشخیص می دهند.
2.6جی یو و همکاران [1][12] یک روش مبتنی بر خوشه بندی برای شناسایی بات نت ها در مرحله حمله ارائه کرده اند. در این روش ابتدا ترافیک ارتباطی و حملات مشابه خوشه بندی شده و سپس یک همبستگی بین خوشه ای انجام می شود. روش فوق برمبنای غیربرخط کار می کند. [4]
7**آزمایشها**
1.7 **داده مورد استفاده در پروژه:داده های مورد استفاده در این پروژه شامل خروجی یک روز سیستم منبع باز مدیریت امنیت اطلاعات Open Source [OSSIM](https://en.wikipedia.org/wiki/OSSIM)) Security Information Management) که طبق پروتکل نت فلو، اطلاعات ترافیکی شبکه را جمع آوری می کند استفاده شده است.
 شکل: شمای کلی داده مورد استفاده در پروژه
**زمان ابتدا و انتها **در این فیلد تاریخ و ساعت ترافیک انتقالی میان دو سیستم درج شده است.
**زمان اتصال**: میزان زمان اتصال دو سیستم به یکدیگر بر حسب ثانیه
**-آدرس آی پی مبدا**: آدرس آی پی کلاینت/سرور مبدا در این ستون قرار دارد.
**-آدرس آی پی مقصد**:آدرس آی پی کلاینت/سرور مقصد در این ستون قرار دارد.
**-پورت مبدا**:پورت سیستم درخواست دهنده
**-پورت مقصد**:پورتی که سیستم مبدا از آن برای اتصال به سیستم مقصد استفاده می کند در این فیلد قرار می گیرد.
**-پروتکل**:نوع پروتکل ارتباطی میان دو سیستم از قبیل TCP، UDP و ICMP
**نوع Flag**:وضعیت نهایی بسته های ارسالی از سیستم مبدا به مقصد
**تعداد Packet**:تعداد بسته(Packet) ارسال شده در حین ارتباط
**تعداد بایت**: تعداد بایت ارسال شده در مجموع Packet های ارسالی
گفتنی است تعداد رکوردهای مورد استفاده در این پروژه، 34 میلیون رکورد از ترافیک یک روز سیستم های تشخیص نفوذ است.
2.7 **آماده سازی داده:** اهمیت آماده سازی داده ها به دلیل این واقعیت است که؛ "فقدان داده با کیفیت برابر با فقدان کیفیت در نتایج کاوش است.

شکل: مراحل پاکسازی داده
7.2.1" **جداسازی لیست سفید(White List)**: در این پروژه با بررسی آی پی های سرورهای 100 تارنمای برتر ایران در سایت الکسا، یک دیتابیس از تمامی آی پی های این 100 سایت ایجاد گردید که با حذف این آی پی ها از مجموع ترافیک دریافتی حدود سه و نیم میلیون از رکوردها حذف گردیدند.
7.2.2" **جداسازی ارتباطات ناقص** : با استفاده از وضعیت نهایی بسته های ارسالی از سیستم مبدا به مقصد آن دسته از ترافیکی که اتصالات آن یک طرفه و ناقص بود حذف گردیدند. مجموع این ترافیک در حدود 4 میلیون رکورد بود.
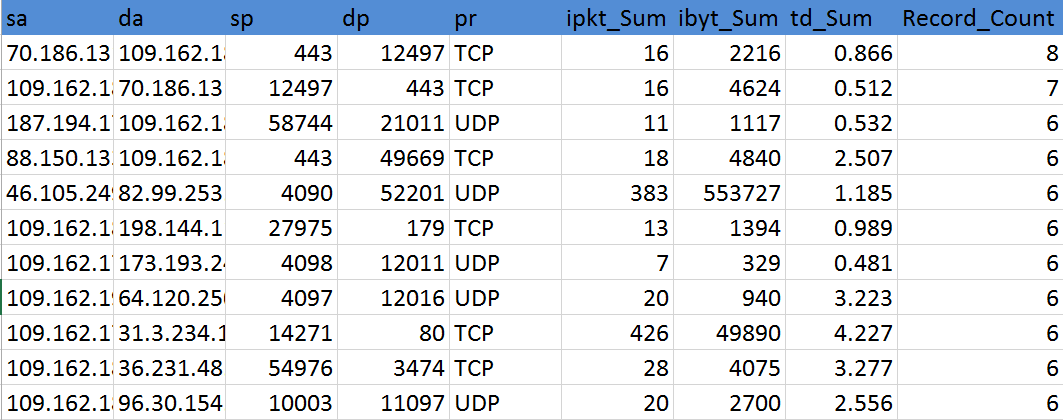
7.2.3" **تجمیع دادهها**: در این بخش داده های باقی مانده پس از مراحل جداسازی لیست سفید و جداسازی ارتباطات ناقص براساس فیلدهای آی پی مبدا، آی پی مقصد، پورت مبدا، پورت مقصد و نوع پروتکل برای محاسبه ویژگی های کلی ذیل تجمیع گردید:
1- میزان بسته ارسالی در طول روز
2- میزان بایت ارسالی در طول یک روز
3- مدت کل اتصال در یک روز
4- تعداد اتصال میان دو سیستم در طول روز
در این مرحله از میان 26 میلیون رکورد باقی مانده بیش از 10 میلیون رکورد تجیمع گردیدند
7.3" **کاهش ابعاد**:
بسترهای دادهای که دارای ابعاد زیادی هستند علیرغم فرصتهایی که به وجود میآورند، چالشهای محاسباتی زیادی را ایجاد میکنند. یکی از مشکلات داده های با ابعاد زیاد اینست که در بیشتر مواقع تمام ویژگیهای دادهها برای یافتن دانشی که در دادهها نهفته است مهم و حیاتی نیستند. به همین دلیل در بسیاری از زمینه ها کاهش ابعاد داده یکی از مباحث قابل توجه باقی مانده است.[19]
7.3.1"**روشهای مبتنی بر استخراج ویژگی**: این روشها یک فضای چند بعدی را به یک فضای با ابعاد کمتر نگاشت میکنند. در واقع با ترکیب مقادیر ویژگی های موجود، تعداد کمتری ویژگی بوجود میآورند بطوریکه این ویژگیها دارای تمام (یا بخش اعظمی از) اطلاعات موجود در ویژگیهای اولیه باشند. این روش ها به دو دستهی خطی و غیر خطی تقسیم میشوند.
در این پروژه برای کاهش ابعاد از روش های مبتنی بر استخراج ویژگی استفاده شده است. این ویژگی ها از روابط خطی زیر بوجود آمده اند:
the number of flows per hour: ساعت/ تعداد اتصال میان دو سیستم در طول روز
the number of packets per flow: تعداد اتصال میان دو سیستم در طول روز/ میزان بسته ارسالی در طول روز
the average number of bytes per packets: میزان بسته ارسالی در طول روز / میزان بایت ارسالی در طول یک روز
the average number of bytes per second: مجموع ثانیه های یک روز/ میزان بایت ارسالی در طول یک روز
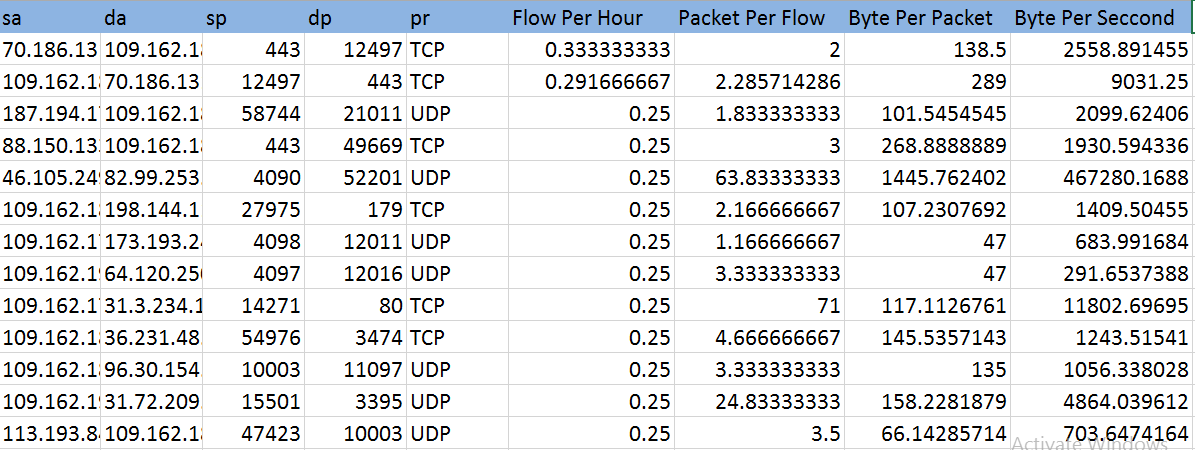
7.3.2":**روشهای مبتنی بر انتخاب ویژگی**: در این روش ها سعی شد تا با انتخاب زیرمجموعه ای از ویژگی های اولیه، ابعاد داده ها را کاهش دهیم. در پارهای از اوقات تحلیل های دادهای نظیر طبقه بندی برروی فضای کاسته شده نسبت به فضای اصلی بهتر عمل میکند. گفتنی است پس از بررسی های صورت گرفته فیلدهای ذیل جهت داده نهایی برای ورود به الگوریتم های طبقه بندی و خوشه بندی لحاظ گردید. 1: Flows Per Hour 2:Packets Per Flow 3:Bytes Per Packets 4:Bytes Per Second 5: Malware

7.4"**جمع آوری لیست سیاه**: در این مرحله با بررسی سایت های شرکت های امنیتی همچون [Zeus tracker](https://zeustracker.abuse.ch)، دیتابیسی از آی پی های سرورهای بات نت شامل منطقه جغرافیایی بات نت، آی پی سرور مرکزی(C&C) و نوع بات نت از قبیل:
1-Zeus
2- Pushdo
3- GameOver_Zeus_P2P
4- Sality-Virus
5- Glupteba
6- Pushdo_SpamBot
7- ZeroAccess
جمع آوری گردید.

7.5"**ادغام دو پایگاه داده**: با استفاده از دستور Left Outer Join، دیتابیس اطلاعات شبکه های بات نت براساس فیلد آی پی درون پایگاه داده اصلی(نت فلو) ادغام شد.
SELECT *
FROM NetFlow
LEFT OUTER JOIN BotnetIp
ON NetFlow.IP = BotnetIp.IP
***روش بانظارت Supervised learning***
7.6" **طبقه بندی Classification**: طبقه بندی در واقع ارزشیابی ویژگیهای مجموعه ای از دادهها و سپس اختصاص دادن آنها به مجموعهای از گروههای از پیش تعریف شده است. این متداولترین قابلیت داده کاوی می باشد. در طبقه بندی می توان با استفاده از دادهها برای تولید یک مدل یا نمایی از یک گروه بر اساس ویژگیهای دادهها به کار برد. سپس می توان از این مدل تعریف شده برای طبقه بندی مجموعه دادههای جدید استفاده کرد. همچنین میتوان با تعیین نمایی که با آن سازگار است برای پیش بینیهای آتی از آن بهره گرفت.
7.7.1": **درخت تصمیم گیری Decision Trees **:ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده می باشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد مقدار هدف آن پدیده نقش می کند. تکنیک یادگیری ماشین برای استنتاج یک درخت تصمیم از داده ها، یادگیری درخت تصمیم نامیده می شود. هر گرهء داخلی متناظر یک متغیر و هر کمان به یک فرزند، نمایانگر یک مقدار ممکن برای آن متغیر است. یک گرهء برگ، با داشتن مقادیر متغیرها که با مسیری از ریشهء درخت تا آن گرهء برگ بازنمایی می شود، مقدار پیش بینی شدهء متغیر هدف را نشان می دهد. یک درخت تصمیم ساختاری را نشان می دهد که برگ ها نشان دهندهء دسته بندی و شاخه ها ترکیبات فصلی صفاتی که منتج به این دسته بندی ها را بازنمایی می کنند. یادگیری یک درخت می تواند با تفکیک کردن یک مجموعهء منبع به زیرمجموعه هایی براساس یک تست مقدار صفت انجام شود. این فرآیند به شکل بازگشتی در هر زیرمجموعهء حاصل از تفکیک تکرار می شود. عمل بازگشت زمانی کامل می شود که تفکیک بیشتر سودمند نباشد یا بتوان یک دسته بندی را به همهء نمونه های موجود در زیرمجموعهء بدست آمده اعمال کرد. [20]
7.7.1.1 **انواع درخت تصمیم**:
1) درخت تصمیم C 4.5
2) درخت تصمیم Cart
3) درخت تصمیم Chaid
,....

7.8" **طراحی یک سیستم یادگیری**: طراحی یک سیستم یادگیری به طور کلی از مراحل زیر تشکیل شده است:
الف- انتخاب Training experience ( آزمون یا روشی که سیستم از طریق آن می تواند اطلاعاتی را که برای یادگیری نیاز دارد کسب نماید. )
ب- انتخاب تابع هدف ( Target Function ): فیلد هدف در این پروژه فیلد کیفی Malware است.
پ-انتخاب الگوریتم : الگوریتم نهایی جهت شناسایی الگو درخت تصمیم C4.5 هست.
ت-طراحی نهایی
7.9": **شبه کد الگوریتم درخت تصمیم C4.5**:
1.Check for base cases
2.For each attribute _a_
3. Find the normalized information gain ratio from splitting on _a_
4.Let _a_best_ be the attribute with the highest normalized information
gain
5.Create a decision _node_ that splits on _a_best_
6.Recur on the sublists obtained by splitting on _a_best_, and add those
nodes as children of _node_
8"**مطالعه موردی بات نت ZeuS و GameOver Zeus**:
بات نت GameOver Zeus یک شاخهی خطرناک از بدافزار بانکی زئوس است، اما برخلاف خود زئوس شبکهی رایانههای فرمانبر قربانی در این نسخه به صورت توزیعشده میباشد و معماری نظیر به نظیر دارد که شناسایی فرمانده را سختتر میکند، در این معماری فرمانها و دستورالعملهایی که برای قربانیان ارسال میشود ممکن است از طریق یک رایانهی فرمانبر دیگر باشد و مستقیم از طرف فرمانده نباشد. اما بدافزار اصلی GameOver Zeus مانند همهی بدافزارهای بانکی، سعی در جعل ظاهر وبگاه بانکی و سرقت اطلاعات محرمانهی قربانیان دارد، همانطور که مطرح شد مدت بسیار کمی پس از خاموشی شبکهی رایانههای فرمانبر GameOver Zeus، نسخهی جدید این بدافزار به نام newGOZ که از الگوریتم تولید نام دامنهی جدید استفاده میکرد کشف شد. این الگوریتم روزانه نزدیک به ۱۰۰۰ نام دامنهی جدید تولید میکرد، این الگوریتم از روشی موسوم به FastFlux یا شار تغییرات سریع برای مخفیسازی زیرساخت خود استفاده میکند. روش شار تغییرت سریع منجر میشود مهاجم بتواند به صورت تصادفی کارگزارهای فرماندهی و کنترل را تغییر دهد و زیرساخت خود را مخفی نگه دارد.
بیش از یک میلیون آلوده به این بات در جهان شناسایی گردیده است. تقریباً 25% کامپیوترهای آلوده در ایالات متحده آمریکا قرار دارند. ضرر و تلفات در سطح جهان صدها میلیون دلار برآورد شده است.10 کشور در عملیات شناسایی و مقابله جهت رفع آن مشارکت کلیدی داشته اند.([+](http://www.biya2forum.com/archive/index.php/t-15862.html))

شکل: Top Banking [Botnets](http://www.secureworks.com/cyber-threat-intelligence/threats/top-banking-botnets-of-2013/) of 2013
9."**نتایج**:با اعمال الگوریتم درخت تصمیم در نرم افزاز IBM Spss Modeler16 در فاز انتهایی، به ترتیب یک و سه Rule برای شناسایی بات نت های Zeus و GameOver Zeus شناسایی شد:
Rule For Zeus :
Rule for Zeus
if Flow per Hour <= 0.125
and packets per flow > 12.500
and packets per flow <= 13.500
and bytes per packets > 75.191
and bytes per packets <= 77.769
and bytes per second > 4874.010
and bytes per second <= 8505.260
then ZeuS
Rule For GameOver Zeus
Rule 1 for GameOver_Zeus_P2P
if packets per flow > 10.500
and bytes per packets > 151.400
and bytes per packets <= 175.667
and bytes per second > 446,875
then GameOver_Zeus_P2P
Rule 2 for GameOver_Zeus_P2P
if packets per flow > 9.500
and bytes per packets > 172.200
and bytes per packets <= 175.667
and bytes per second > 446,875
then GameOver_Zeus_P2P
Rule 3 for GameOver_Zeus_P2P
if packets per flow <= 3.500
and bytes per packets <= 40.163
and bytes per second <= 4.557
then GameOver_Zeus_P2P
10.": **ارزیابی**: با استفاده از داده های Test و Train الگوریتم درخت تصمیم C4.5 نتایج ذیل حاصل گردید:

همانطور که مشاهده می کنید این الگوریتم با دقت بالای هفتاد درصد دو بات نت فوق را شناسایی می کند. گفتنی است با توجه به تک Rule بات نت Zeus دقت این الگوریتم برای شناسایی آن برابر با صد در صد می باشد.
***روش بی نظارت Unsupervised learning***
11" **خوشه بندی:** خوشه بندی یکی از شاخه های یادگیری بدون نظارت می باشد و فرآیند خودکاری است که در طی آن، نمونه ها به دسته هایی که اعضای آن مشابه یکدیگر می باشند تقسیم می شوند که به این دسته ها خوشه گفته میشود. بنابراین خوشه مجموعه ای از اشیاء می باشد که در آن اشیاء با یکدیگر مشابه بوده و با اشیاء موجود در خوشه های دیگر غیر مشابه می باشند.
11.1" **روشهای خوشهبندی**:
روشهای خوشهبندی را میتوان از چندین جنبه تقسیمبندی کرد:
11.1.1" خوشهبندی انحصاری (Exclusive or Hard Clustering) و خوشهبندی با همپوشی (Overlapping or Soft Clustering):
در روش خوشهبندی انحصاری پس از خوشهبندی هر داده دقیقأ به یک خوشه تعلق میگیرد مانند روش خوشهبندی K-Means. ولی در خوشهبندی با همپوشی پس از خوشهبندی به هر داده یک درجه تعلق بازاء هر خوشه نسبت داده میشود. به عبارتی یک داده میتواند با نسبتهای متفاوتی به چندین خوشه تعلق داشته باشد. نمونهای از آن خوشهبندی فازی است.
11.1.2"خوشهبندی سلسله مراتبی (Hierarchical) و خوشهبندی مسطح(Flat):
در روش خوشه بندی سلسله مراتبی، به خوشههای نهایی بر اساس میزان عمومیت آنها ساختاری سلسله مراتبی نسبت داده میشود. مانند روش Single Link. ولی در خوشهبندی مسطح تمامی خوشههای نهایی دارای یک میزان عمومیت هستند مانند K-Means.
11.2"**معرفی الگوریتم خوشه بندی Kmeans**:یکی از روش های معتبر خوشه بندی، خوشه بندی Kmeans است که براساس کمترین فاصله های هر داده از مرکز یک خوشه(میانگین) خوشه بندی را انجام می دهد.
11.2.1"**الگوریتم Kmeans:**
الف- مقدار دهی اولیه: K نقطه را بعنوان مرکز اولیه در نظر می گیرد
ب- تکرار
پ- تعداد K خوشه را با تخصیص تمام نقاط به نزدیکترین مرکز تشکیل می دهد.
ت- مراکز هر خوشه دوباره محاسبه می شوند.
ج-تا زمانی که مراکز خوشه ها تغییر نکند یا تعداد تکرار به پایان نرسد الگوریتم ادامه می دهد.
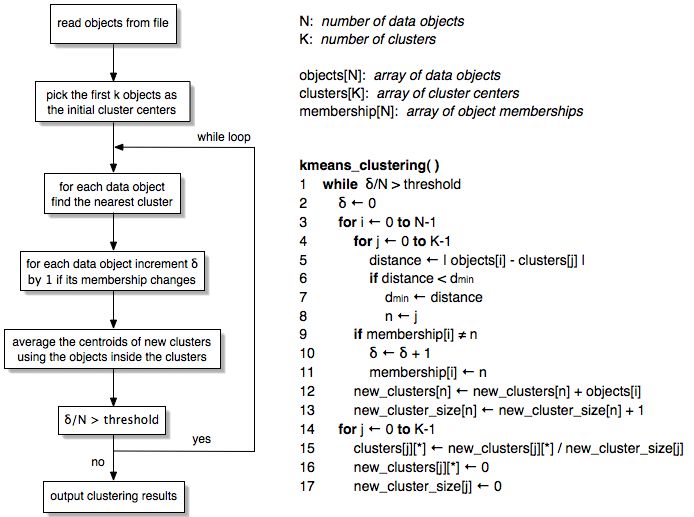
11.3" **ورودی های الگوریتم**: فیلدهای ورودی به الگوریتم Kmeans عبارت اند از:
1)Flow Per Hour
2)Byte Per Second
3)Packet Per Flow
4)Byte Per Packet
11.3" **نتایج**: با اعمال الگوریتم Kmeans بروری دادههای موجود، دراین فاز نتایج ذیل حاصل گردید:
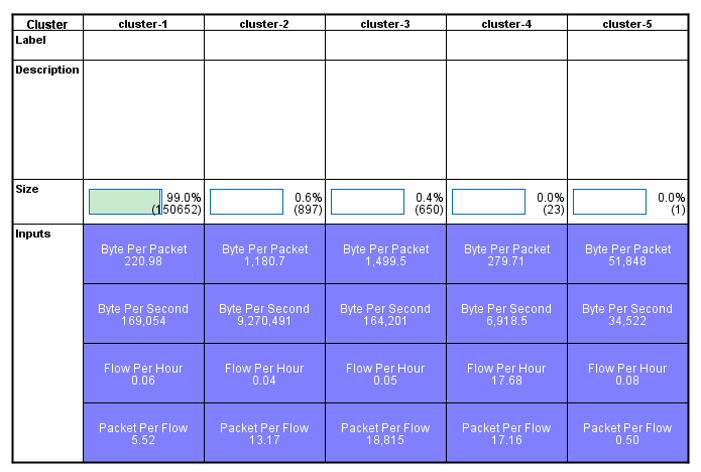
همانطور که در شکل فوق مشاهده می کنید پس از اجرا الگوریتم خوشه بندی و بررسی تعداد خوشه های (K) متفاوت، در بالاترین دقت داده های موجود به پنج دسته مختلف تقسیم بندی گردیده اند. بیش از 99 درصد داده های درون خوشه یک قرار گرفته اند.
با بررسی و آنالیز صورت گرفته در تمامی خوشه ها با استفاده از دیتاست لیست سیاه مشخص گردید که تمامی تراکنش های بات نت Zeus در درون خوشه دوم قرار گرفته و اکثر ارتباطات موجود در خوشه یک، شامل ترافیک های نرمال می باشد.
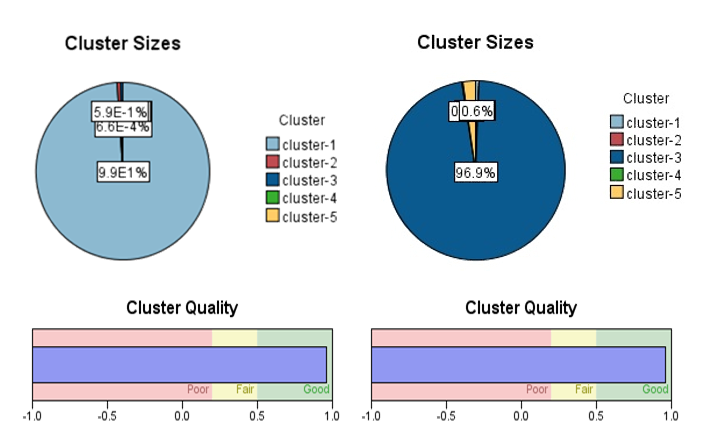
11.4"**معیار ارزیایی:** معیار ارزیابی در خوشه بندی فوق معیار Silhouette Ranking Measure است. در این ارزیابی همانطور که در شکل ذیل مشاهده می نمایید داده ها به صورت های 1- تمامی داده ها 2- داده های نمونه مورد بررسی قرار گرفته اند که در هر دو صورت دقت الگوریتم بالای 95 درصد بوده است.
12" روش **Graph Mining** :
یک گراف از مجموعهای غیر خالی از اشیاء به نام رأس تشکیل شده، که آن را با V نشان میدهیم، و مجموعهای شامل یالها، که رأسها را به هم وصل میکنند و با E نمایش میدهیم. یک چنین گرافی را با (G = (V,E نشان میدهیم.
یک گراف ارتباطی رخدادهای شبکه برای مشخص نمودن میزان و نحوه اتصالات آی پی های گوناگون مورد استفاده قرار می گیرد. در این گراف حمله های بات نت با اتصال یک گره های آغازین نماینده نفوذگر (C&C) در یک نقطه مشخص شبکه است. گره ها و یالها نمایند عملیات و کارهایی است که توسط نفوذگر انجام شده است.
با رسم تمامی اتصالات با استفاده از نرم افزار تحلیل گراف NodeXl، شبکه ارتباطی زیر شناسایی گردید:
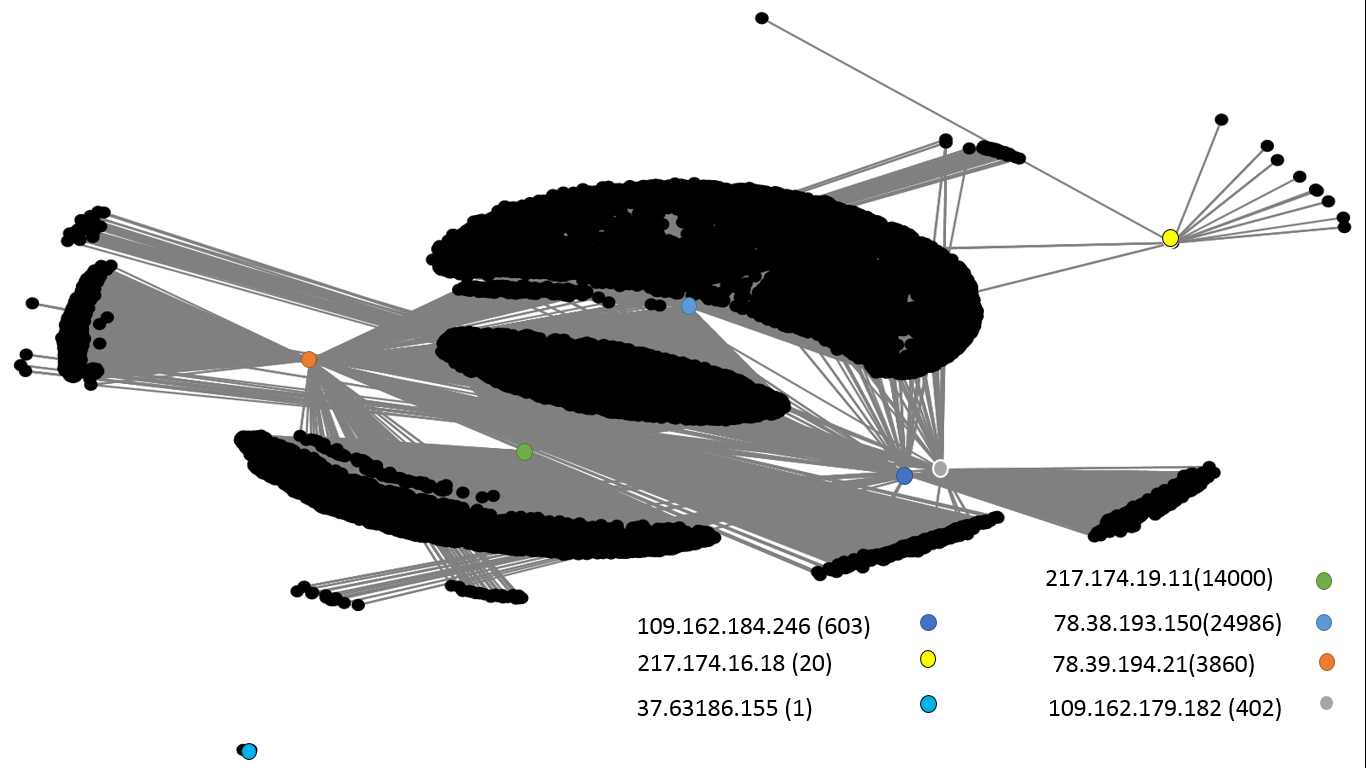
با آنالیز صورت گرفته در میان نودهای مرکزی (نودهای موثر) همانطور که در شکل فوق مشاهده می کنید 8 سرور بات نت Zeus با مدل ساختاری شبکه ای آن شناسایی گردیده است.
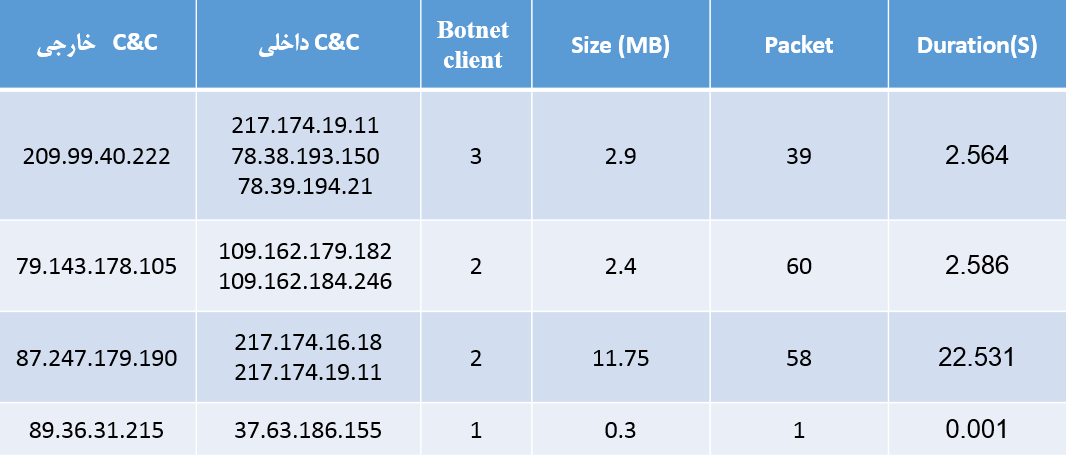
با بررسی آی پی های سرورهای داخلی و خارجی بات نت Zeus و تحلیل رفتار آنها جدول زیر که شامل شناسایی زیرسرورهای بات نت Zeus در داخل ایران، میزان حجم ارسالی، تعداد بسته و .... است مشخص گردید
13" **کارهای آینده(پیشنهادی):**
1- پیاده سازی الگوریتم های فوق در زبان R (در این پروژه از نرم افزار داده کاوی IBM Spss Modeler استفاده شده بود)
2- بررسی الگویتم های خوشه بندی فازی
3- بررسی سایر الگوریتم های درخت تصمیم از قبیل Chaid،CART و ...
4- گسترش مباحث مرتبط با گراف
5- بررسی الگوریتم PageRank جهت بهبود پروژه
6- بررسی الگوریتم های شبکه عصبی در جهت افزایش دقت
7- استفاده از روش های Big Data همچون BotCLoud در شناسایی بات نت ها
14**مراجع**
[1] Guofei Gu , Roberto Perdisci , Junjie Zhang , and Wenke Lee , " BotMiner: Clustering Analysis of Network Traffic for Protocol- and Structure-Independent Botnet Detection" : Damballa, Inc. Atlanta, GA 30308, USA
[2]Karim et al. J Zhejiang,"Botnet detection techniques: review, future trends and issues": Journal of Zhejiang University-SCIENCE C (Computers & Electronics)
[3]رضا شریف نیای دیزبنی، مهدی آبادی , "یک روش شهرت دهی برای تشخیص بات نت های نسل جدیدمبتنی بر شناسایی نام های دامنه الگوریتمی" : دهمین کنفرانس بین المللی انجمن رمز ایران
[4] موسی یحیی نژاد, مهدی آبادی,"روشی برای تشخیص بات نت ها در مرحله فرمان و کنترل با استفاده از خوشه بندی ": هشتمین کنفرانس بین المللی انجمن رمز ایران
[5]ALEXANDER V. BARSAMIAN , "NETWORK CHARACTERIZATION FOR BOTNET DETECTION USING
STATISTICAL-BEHAVIORAL METHODS": Hanover, New Hampshire
[6] Robert F. Erbacher,Adele Cutler,Pranab Banerjee,Jim Marshall,"A Multi-Layered Approach to Botnet Detection"
[7]Maryam Feily,Alireza Shahrestani, "A Survey of Botnet and Botnet Detection": 2009 Third International Conference on Emerging Security Information, Systems and Technologies
[8]Hossein Rouhani Zeidanloo, Mohammad Jorjor Zadeh,M. Safari, Mazdak Zamani,"A Taxonomy of Botnet Detection Techniques"
[9]Pedram Amini1, Reza Azmi , MuhammadAmin Araghizadeh,"Botnet Detection using NetFlow and Clustering": ACSIJ Advances in Computer Science: an International Journal, Vol. 3, Issue 2, No.8 , March 2014
[10]Chunyong Yin , Lei Yang, Jin Wang,"Botnet Detection Based on Degree Distributions of Node Using Data Mining Scheme":International Journal of Future Generation Communication and Networking
[11]Hyunsang Choi, Heejo Lee, and Hyogon Kim,"BotGAD: Detecting Botnets by Capturing Group Activities
in Network Traffic"
[12]Guofei Gu ,"CORRELATION-BASED BOTNET DETECTION IN ENTERPRISE NETWORKS":In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the College of Computing
[13]S.S.Garasia, D.P.Rana, R.G.Mehta,"HTTP BOTNET DETECTION USING FREQUENT PATTERNSET MINING": INTERNATIONAL JOURNAL OF ENGINEERING SCIENCE & ADVANCED TECHNOLOGY
[14]Mohammad M. Masud, Jing Gao,Latifur Khan,"Mining Concept-Drifting Data Stream to Detect Peer to
Peer Botnet Traffic"
[15]Shishir Nagaraja, Prateek Mittal, Chi-Yao Hong, Matthew Caesar, Nikita Borisov,"BotGrep: Finding P2P Bots with Structured Graph Analysis": University of Illinois at Urbana-Champaign
[16]J´erˆome Fran¸cois, Shaonan Wang, Radu State, and Thomas Engel,"BotTrack: Tracking Botnets using NetFlow and
PageRank": Interdisciplinary Centre for Security, Reliability and Trust (SnT)
[17]Mohammad M. Masud, Jing Gao, Latifur Khan, Jiawei Han,Bhavani Thuraisingham ,"Peer to Peer Botnet Detection for Cyber-Security: A Data Mining Approach"
[18]Carl Livadas, Bob Walsh, David Lapsley, Tim Strayer,"Using Machine Learning Techniques to Identify Botnet Traffic":Internetwork Research Department BBN Technologies
[19]Mohammad sedegh sheikhani "Dimensionality Reduction"
.[20]لعبت عزیزی "گزارش تحقیق درس یادگیری ماشین"