##چکیده
محیط روبوکد یک محیط شبیه سازی شدهی دو بعدی است که در آن تعدادی ایجنت که به صورت تانک هستند با هم به مبارزه میپردازند. هر تانک یک ایجنت است که دارای تعدادی سنسور برای گرفتن اطلاعات و تعدادی اکشن است. هدف از این پروژه افزایش مهارت یک تانک برای از بین بردن حریفهای خود با استفاده از یادگیری ماشین به صورت تقویتی میباشد.
# مقدمه
## روبوکد چیست؟ [^Robocode]
[روبوکد](http://robocode.sourceforge.net/) یک بازی برنامه نویسی [^Programming game] است که هدف در آن برنامه نویسی کردن یک ربات برای شکست دادهن بقیه ربات ها در زمین شبیه سازی شده بازی است. در روبوکد یک بازیکن تنها میتواند روبات را قبل از شروع مسابقه برنامه ریزی کند و در طی مسابقه هیچ تاثیری در بازی نمیگذارد. در واقع با نوشتن یک هوش مصنوعی برای عامل این محیط به او یاد میدهیم که در شرایط مختلف چگونه رفتار کند (تصویر ۱)

### بررسی عامل
در محیط روبوکد (تصویر ۱ ) عامل به صورت یک تانک میباشد. این تانک شامل ۶ چرخ برای حرکت یک رادار برای تشخیص محیط اطراف و یک لوله برای شلیک گلوله است.
چرخ ها - که میتواند با آنها حرکت رو به جلو و عقب و چرخش را انجام دهد - لوله تانک جز عملگر های این عامل هستند. سنسور این عامل راداری میباشد که بالای سر ربات فرار دارد. عامل روبوکد فقط توانایی دیدن اجسامی را دارد که در رو به روی رادار قرار داشته باشند. رادار یک عملگر هم محسوب میشود چرا که ربات قابلیت چرخاندن رادار را دارد. عامل روبوکد دارای انرژی میباشد که با حرکت کردن و شلیک گلوله کاهش مییابد و با صدمه رساندن به حریف افزایش پیدا میکند. عامل روبوکد توانایی شلیک گلوله با سه قدرت مختلف دارد. قدرت بیشتر انرژی بیشتری را از ربات میگیرد ولی در صورت اصابت خسارت زیادی وارد میکند.
عامل روبوکد باید موفق شود با مصرف کمترین انرژی دشمنان خود را شکست دهند.

### بررسی محیط
محیطی که عامل در آن قرار دارد یک زمین مسطح به شکل مستطیل است که دور آن با دیوار محسور شده است. (تصویر ۳) همانطور که گفته شد عامل فقط توانایی مشاهده کردن رو به روی رادار را دارد و محیط به طور کامل قابل مشاهده نیست. موجودیت های داخل محیط عبارت اند از ربات های دوست و دشمن و تیر های شلیک شده. تیر ها بر اساس قوانین مشخص حرکت میکنند و حالت بعدی آنها قابل پیشبینی است اما حالت بعدی عامل های دیگر بستگی به تصمیم آنها دارد.
کد نوشته شده برای ربات از طریق یک رابط به صورت نا همگام [^asyncronous] از محیط اطراف اطلاعات دریافت میکند تصمیم میگیرد و دستور یک عمل را صادر میکند. این کار به صورت دنباله دار تا پیروزی یکی از طرفین ادامه پیدا میکند. عملکرد کند عامل احتمال کسر امتیاز را افزایش میدهد.

## یادگیری تقویتی[^ Reinforcement learning]
به صورت کلی یادگیری تقویتی بخشی از یادگیری ماشین است که از [علوم روانشناسی رفتار گرا](https://en.wikipedia.org/wiki/Behaviorism) الهام گرفته است. در یادگیری تقویتی میخواهیم یادبگیریم که چه کنیم یا در واقع میخواهیم موقعیت را به یک رفتار و عملکرد نظیر کنیم به طوری که بیشترین پاداش را دریافت کنیم. در این نوع یادگیری بر خلاف یادگیری های دیگر به یادگیرنده گفته نمیشود که عملکرد درست کدام است، بلکه این خود یادگیرنده است که باید با امتحان کردن رفتار های مختلف و دریافت پاداش [^Reward] یا جزا[^Punishment] در شرایط مختلف بهترین عمل را پیدا کند. در یادگیری به همراه ناظر [^Supervised] یک مجموعه از داده های مطلوب به عامل داده میشود ولی در مسائلی که توسط یادگیری تقویتی حل میگردند پیدا کردن یک مجموعه از داده های مطلوب کار بسیار دشواری است زیرا این مسائل عمداتاً از پیچیدگی بالایی برخوردارند و بسیار تعاملی هستند.
یکی از چالش های پیش رو در این نوع یادگیری انتخاب بین استخراج [^Exploite]بیشتر و کاوش[^Explore] بیشتر است. عامل باید با تکرار عمل های نسبتا مطلوب خود در گذشته دقت آنها را افزایش دهد اما از جهتی این کار باعث میشود که عامل از تجربه رفتار های جدید باز ماند.

## محاسبه باز خورد [^Feedback]
مهم ترین شاخصهای که یادگیری تقویتی را از سایر یادرگیری های دیگر متمایز میکند این است که ارزش انجام یک عمل را حساب میکند به جای اینکه مجموعهای از اعمال های درست را دریافت کند. در واقع بازخورد فقط به ما میگوید که عمل انجام شده چقدر خوب یا بد بوده است و به ما بهترین عمل یا بدترین عمل را نمیگوید. در مسئله ساده [n-armed bandit](https://en.wikipedia.org/wiki/Multi-armed_bandit) محاسبه بازخورد کار بسیار سادهای است که درواقع همان میزان جایزه دریافت شده از دستگاه میباشد. اما در مسائل دیگر این کار میتواند پیچیده باشد.
## محیط در یادگیری تقویتی
به طور خلاصه هر آنچه عامل با آن در تعامل است را محیط میگویند. در مسئلهای که میخواهیم آنرا با یادگیری تقویتی حل کنیم در ابتدا باید بتوانیم محیط را با فرآیند تصمیم گیری ماکُو [^ Markov Decision Process (MDP)] مدل سازی کنیم.
فرآیند تصمیم گیری مارکو به صورت چندتایی زیر تعریف میشود$$(S,A,P_{0}(0,0),R_{0}(0,0),\gamma)$$
که در آن S مجموعهی متناهی از حالتها[^States] ، A مجموعه متناهی از عملیاتها [^Actions] ، P تابع احتمال اینکه از حالت s به s' با عمل a برویم، R پاداش [^Reward] دریافتی با رفتن از حالت s به s' با عمل a و گاما، که عددی بین صفر و یک است، ضریب اهمیت پاداش فعلی و پاداش های احتمای در آینده میباشند.
با توجه به تعریف بالا اولین چالش پیش رو نگاشت کردن حالت های مسئله به مجموعهی متناهی از حالت هاست به طوری که با انجام یک عمل به حالتی دیگر برویم.

## یادگیری کیو [^ Q Learning]
این مسئاله رو مدل MDP تعریف میشود. هدف عامل در این الگوریتم بیشینه کردن پاداش دریافتی با پیدا کردن بهترین عمل در هر حالت است. این الگوریم دارای تابعی است که ارزش هر عمل را با توجه به حالت میدهد.
$$ Q: S \times A \Rightarrow \mathbb{R}. $$
چالش ما بدست آوردن مقدار Q است. عامل دارای یک آرایهی دو بعدی بر اساس حالت و عمل است و قبل از شروع یادگیری Q دارای های مقادیر مساوی است. سپس هر بار که عامل عملی را انجام میدهد مقدار Q بروز میشود.
$$ Q_{t+1}(s_{t}, a_{t}) = Q_{t}(s_{t},a_{t}) + \alpha_{t}(s_{t},a_{t}).\lgroup R_{t+1} + \gamma .maxQ_t(s_{t+1},a) - Q_{t}(s_{t},a_{t}) \rgroup $$
در فرمول بالا آلفا ضریب یادگیری است که توابع مختلفی برای بدست آوردن آن ارائه شده است. هرچه آلفا بزرگتر شود یه این معنی است که اهمیت مقدار های پیشین کم است و تاثیر پاداش کنونی افزایش مییابد و هرچه آلفا کمتر باشد به این معنی است که بیشتر به داده های قبلی تکیه کردهایم و پاداش های جدید کم اهمیت تر است. در حالتی که آلفا یک باشد Q برابر با پاداش کنونی میشود و در حالت آلفای صفر یادگیری متوفق میشود. معمولا برای آلفا تابعی را انتخاب میکنیم که در شروع مقدار زیادی داشته باشد و رفته رفته به صفر میل کند.
$$ \alpha(t) = \frac{1}{t+1} $$
Initialize Q(s,a) arbitrarily
Repeat (for each episode):
Initialize s
Repeat (for each step of episode):
Choose a from s using policy drived from Q
(e.g. epsilon-greedy)
Take action a, obsere r, s'
Q(s,a) <- Q(s,a) + alpha * (r + gamma * max(Q(s',a')-Q(s,a))
s <- s';
until s is terminal
# کارهای مرتبط
## استفاده از یادگیری تقویتی در حرکت عامل روبوکد
پاتریک هلوپتزک از دانشگاه واشنگتون در پروژه خود [4] که درباره استفاده از یادگیری تقویتی برای حرکت عامل بازی روبوکد است برای نگاشت کردن محیط بازی روبوکد به MDP حالت بازی را با استفاده از پارامتر های موقعیت تانک حریف، زاویه بین تانک خودی و تانک حریف، فاصله تا حریف و اینکه آیا حریف در چند ثانیه آخیر شلیک کرده است یا نه، ساخته است. نکتهای که وجود دارد این است که اگر بخواهیم تمامی زاویه ها و تمامی موقعیت ها را در نظر بگیریم تعداد حالت ها بسیار زیاد خواهد شد و این امر یادگیری را بسیار دشوار میکند زیرا عامل تونایی تجربه کردن تمامی حالات را عملا ندارد. برای همین در این پروژه زمین به ۷ بخش عمودی و افقی تقسیم شده است. یعنی در کل ۴۹ حالت برای موقعیت تانک حریف.همین طور ۸ حالت برای زاویه و ۶ حالت برای فاصله. با این تقسیم بندی ۴۷۰۴ حالت خواهیم داشت. عمل های موجود نقاطی است که عامل میتواند به آنها حرکت کند. اگر بخواهیم تمامی نقاط را به عنوان عمل در نظر بگیریم تعداد عمل ها بسیار زیاد خواهد شد. در این پروژه ۴۹ موقعیت برای حرکت به آنها در نظر گرفته شده است. این ۴۹ نقطه تقاطع ۷ دایره به مرکزیت تانک حریف و ۷ خط که از مرکز دایره ها میگذرند است.
## استفاده از یادگیری تقویتی در انتخاب قدرت
در پروژهای دیگری [5] که روی هوش مصنوعی برای بازی روبوکد کار شده از شبکهی عصبی برای چرخاندن لوله تنفگ و از یادگیری تقویتی برای یادگیری شدت شلیک استفاده شده است. برای این کا زمین بازی را به چند قسمت مانند تصویر ۵ تقسیم کرده است. همان طور که گفته شد شلیک گلوله باعث کاهش انرژی میشود و مورد اصابت قرار دادن حریف باعث افزایش انرژی میشود. کم شدن یا زیاد شدن انرژی به عنوان تابع پاداش استفاده شده است. در این پروژه محیط اطراف به ۵ ناحیه کمتر از ۱۰ متر، کمتر از ۱۰۰متر کمتر از ۲۵۰متر، کمتر از ۵۰۰ متر و کمتر از ۱۰۰۰ متر تفسیم شده است و در هر حالت ۳ عمل شلیک گلوله با قدرت های ۰.۵ ، ۱.۵ و ۳ تعریف شده است که در مجموع جدول کیو اندازع ۳ در ۵ پیدا میکند که نسبت به پروژه قبل بسیار کوچک است و امر یادگیری را تسریع میبخشد اما دقت کم میشود ولی از آنجایی که انتخاب قدرت شلیک به پیچیدگی تصمیم گیری برای حرکت نیست میتوان به همین دقت هم بسنده کرد

# آزمایشها
نکته اولی که در آزمایش الگوریتم های یادگیری تقویتی وجود دارد این است که مانند بسیاری از الگوریتم های دیگر یادگیری ماشین هیچ داده اولیهای در دسترس نیست. زیرا همانطور که پیشتر توضیح داده شد این الگوریتم ها برای محیط های بسیار تعاملی مناسب هستند که نمیتوان عمل بهینه را تخمین زد. پس تنها راهی که وجود دارد این است که عامل خود وارد محیط شود و شروع به آزمایش کند و از محیط جزا یا پاداش دریافت کند. راه سریع تری که وجود دارد استفاده از محیط های شبیه سازی شده است.
محیط روبوکد علاوه بر مد قابل مشاهده یک مد برای شبیه سازی دارد که به سرعت انجام میشود و قابل مشاهده نیست. ما برای تست الگوریتم های یادگیری تقویتی از مد شبیه سازی استفاده میکنیم که بتواینم تعداد تست بیشتری را انجام دهیم.
ما برای آزمایش عملکرد روبات آن را در مقابل یک روبات دیگر قرار میدهیم تا با آن روبات به مبارزه بپردازد. روباتی که به عنوان حریف در نظر گرفته شده است Crazy نام دارد که یکی از روبات های نمونهی روبوکد است. این روبات به صورت تصادفی حرکت های مارپیچ انجام میدهد و به دور خود میچرخد و هر موقع که با ربات حریف رو به رو بشود شلیک میکند.
روباتی که ما میخواهیم آزمایشات را روی آن انجام دهیم دارای یک الگوریتم ساده برای شلیک است. این روبات همواره لولهی تانک را به سمت روبات حریف نگه میدارد و در صورت جا به جا شدن حریف دوباره لوله را به سمت او نشانه میرود. اگر فاصله اش تا حریف کمتر از ۲۵۰ متر بود شلیک میکند و اگر این فاصله از ۵۰ متر هم کمتر بود با قدرت ۳ که انرژی زیادی مصرف میکند شلیک میکنید.
برای حرکت این روبات از الگوریتم Q-Learning استفاده کردهایم. برای تبدیل محیط به مدل ماکوُو هر حالت را با توجه به ۵ فاکتور تولید کرده ایم که عبارت اند از: انرژی روبات حریف، انرژی خود روبات، فاصله تا حریف زاویه نسبت به حریف و فاصله تا دیوار است. انرژی به دو بازه زیر ۱۰ و بالا ۱۰ تقسیم شده است. فاصله تا حریف یه ۳ بازه زیر ۱۰۰ زیر ۵۰۰ و بالا ۵۰۰ تقسیم شده است. زاویه به ۴ بازه ۹۰ درجه تقسیم شده است و فاصله تا دیوار به ۲ بازه زیر ۵۰ و بالا ۵۰. در کل ۹۶ حالت برای مدل مارکوو به وجود میآید. عامل برای حرکت ۴ عمل اصلی حرکت به جلو عقب و چرخش به طرفین را دارد. بدین صورت جدول state-action دارای ۳۸۴ خانه میشود.
برای پیاده سازی یک یادگیری تقویتی ما نیاز به یک تابع ارزش گزاری هم داریم. تابع ارزش گزاری که ما از آن استفاده میکنیم بسیار ساده است. این تابع برای ارزش
دهی به یک state-action هشت فاکتور زیر را در نظر میگیرد و هر کدام از شروط که محقق بود به میزان ارزش آن شرط به عامل پاداش یا جزا میدهد.
| Condition | Reward |
|:------:|:------:|
| -10 | hitAWall |
| 0 | collisionWithEnemy |
| 0 | collisionAndKillEnemy |
| 1 | livingReward |
| -1 | hitByBullet |
| 0 | myBulletHitsRobot |
| -10 | distanceToEnemyLessThan50 |
| 1 | distanceToEnemyLessThan200 |
## تست ۱
برای تست ابتدا ۵ هزار بار بازی را اجرا میکنیم که یادگیریای وجود ندارد و عامل سعی میکند به صورت حریصانه عمل کند و از آنجایی که مقادیر Q به روز نمیشوند نمیتوان انتظار نتیجهی خوبی را داشت.
نتایج:
| Robot Name | Total Score | Survival |
|:----------|:------------------:|:------------------:|
| LearningRobot | 642317 (75%) | 245150 |
| Crazy | 211159 (25%) | 4450 |

## تست ۲
حال میخواهیم یادگیری را دخیل کنیم. برای این تست ۱۰هزار بار با الگوریتم e-greedy روبات را در مقابل حریف قرار میدهیم و بعد از آپدیت شدن مقادیر و تخمین best policy هزار با سیاست greedy بازی را اجرا میکنیم.
نتایج:
| Robot Name | Total Score | Survival |
|:----------|:------------------:|:------------------:|
| LearningRobot | 1378354 (65%) | 490000 |
| Crazy | 740550 (35%) | 58150 |
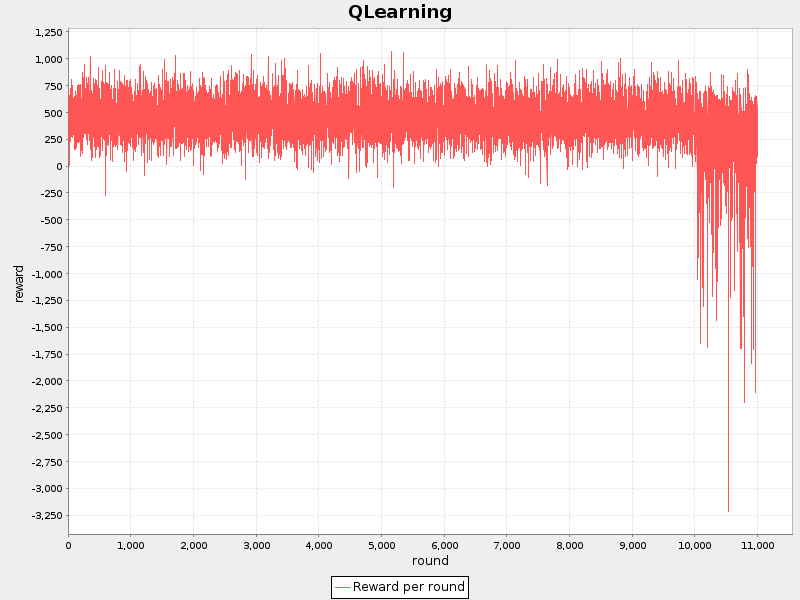
میزان ثابت ها:$$ \alpha: 0.2 $$$$ \gamma: 0.8$$$$ \epsilon: 0.05$$
### نتیجه گیری
همانطور که از مقایسه تصویر ۸ با تصویر ۷ به دست میآید میزان پاداش دریافتی افزایش یافته است. این بدان معنی است که با استفاده از الگوریتم Q-Learning توانستهایم به میزان پاداش بیشتر دست یابیم . اما نکتهی قابل ذکر اینجاست که با توجه به نتایج بازی در تست ۲ تعداد برد های ما نسبت به حریف ۱۰ درصد کاهش یافته است. این در حالی است که ما پاداش بیشتری دریافت کرده ایم. از این تناقض میتوان نتیجه گرفت که تابع ارزش دهی کارایی تعریف نکردهایم.
# کارهای آینده
# مراجع
[Github](https://github.com/bardia73/QLearning-Robocode.git)
>1- O'Kelly, Jackie, and J. Paul Gibson. "RoboCode & problem-based learning: a non-prescriptive approach to teaching programming." ACM SIGCSE Bulletin 38, no. 3 (2006): 217-221.
> 2- S. Russell and P. Norvig. "Artificial Intelligence: A Modern Approach Prentice Hall.", 2003, Second Edition
> 3- Richard S. Sutton and Andrew G. Barto. "Reinforcement Learning An Introduction".
> 4 - Patrick Haluptzok. "MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT" University of Washington 2003
> 5 - Jon Lau Nielsen, Benjamin Fedder Jensen. "Modern AI for games: RoboCode"