
در این پروژه باید سامانهای را توسعه دهید که با یادگیری ویژگیهای اسکن مغزی بیماران مبتلا به اسکیزوفرنی، قادر باشد تا این بیماری را از روی ویژگیهای استخراج شده از تصویر اسکن مغزی، تشخیص دهد.مجموعه داده و نحوه ارزیابی پروژه خود را میتوانید از ا[ین مسابقه](https://www.kaggle.com/c/
-2014-mri) دریافت کنید.
----------
[لازم به ذکر است نوشتار ذیل تحقیقاتی است و پیاده سازی شامل آن نمی شود.]
#** مقدمه**
##اختلال روانگسیختگی یا اسکیزوفرنی
روانگسیختگی یا اسکیزوفرنی یا شیزوفرنی (Schizophrenia) یک اختلال روانی است که مشخصهٔ آن ازکارافتادگی فرایندهای فکری و پاسخگویی عاطفی ضعیف است.[۲] این بیماری در بین همهٔ بیماریهای عمدهٔ روانشناختی از همه وخیمتر میباشد و معمولاً خود را به صورت توهم شنیداری، توهمهای جنون آمیز یا عجیب و غریب، یا تکلم و تفکر آشفته نشان میدهد و با اختلال در عملکرد اجتماعی یا شغلی قابل توجهی همراه است. شروع علائم معمولاً در دوران نوجوانی رخ میدهد.

اختلال عمدتاً ادراک را تحت تأثیر قرار میدهد، به صورتی که فرد مبتلا به آن نمی تواند تشخیص دهد که چه چیزی واقعی و چه چیزی وهم و خیال است اما معمولاً به مشکلات مزمن در رفتار و احساسات نیز میانجامد. افراد مبتلا به اسکیزوفرنی در معرض افسردگی اساسی و اختلال اضطراب و احتمال سوء مصرف مواد مخدر در طول زندگی هستند.[۴] مشکلات اجتماعی از قبیل بیکاری طولانی مدت، فقر و بیخانمانی نیز در بین این بیماران شایع است. امید به زندگی متوسط افراد مبتلا به این اختلال به دلیل افزایش مشکلات سلامت جسمی و نرخ خودکشی بالاتر، ۱۲ تا ۱۵ سال کمتر از کسانیست که مبتلا به آن نیستند.[۳]
فرد مبتلا به اسکیزوفرنی ممکن است دچار توهمهایی شوند (اغلب به صورت شنیدن صداها)، یا دچار خیالات و آشفتگی فکری و کلامی باشد. مورد دوم ممکن است از از دست دادن قطار اندیشه، تا جملات بینظم در معنی، تا تناقض شناخته شده به عنوان آشفته گویی متغیر باشد. گوشهگیری اجتماعی، نامرتبی لباس و بهداشت، و از دست دادن انگیزه و قضاوت تماماً موارد عادی موجود در اسکیزوفرنی میباشند.[۵] اغلب الگوی قابل مشاهدهای از مشکل عاطفی وجود دارد، برای مثال عدم پاسخگویی به محرکات.[۶] اختلال در شناخت اجتماعی با اسکیزوفرنی مرتبط است،[۷] همچنین علائم پارانویا؛ انزوای اجتماعی به طور معمول اتفاق میافتد.[۸] همچنین معمولاً مشکلات در کار و حافظهٔ بلند مدت، توجه، عملکرد اجرایی، و سرعت پردازش رخ میدهد.[۳] فرد ممکن است تا حد زیادی ساکت باشد، در وضعیتهای حرکتی عجیب و غریب، یا در جلوههای بیموردی از اضطراب قرار بگیرد، که همهٔ اینها نشانههایی از جنون میباشند.[۹]
##عوامل مؤثر
به نظر میرسد عوامل مهم مؤثر در شیوع این بیماری این پنج دلیل باشند:
1. ژنتیک
2. محیط اولیه
3. نوروبیولوژی (کنش ها و واکنش های الکتریکی سیستم عصبی و ساختار مغز انسان)
4. سوء مصرف مواد مخدر
5. فرایندهای روانی و اجتماعی
##عصبشناسی
بررسیهای برگرفته از تست روانشناسی عصبی و تکنولوژیهای تصویربرداری از مغز برای بررسی تفاوتهای اجرایی در فعالیت مغز نشان دهنده تفاوتهایی هستند که به نظر میرسد اغلب در **لب قدامی مغز هیپوکامپها و لب گیجگاهی** رخ میدهند.[۱۰] حجم **ماده خاکستری و سفید** افراد مبتلا نسبت به گروه سالم نیز کاهش مییابد. **افزایش حجم مایع مغزی- نخاعی** و**کاهش حجم مغز**در مناطقی از **قشر پیشانی و لبهای گیجگاهی** نیز گزارش شدهاند. معلوم نیست که آیا این تغییرات حجمی تدریجی هستند یا قبل از شروع بیماری به وجود میآیند.[۱۱] این تفاوتها به فقدان شناخت عصبی مرتبط اند که اغلب ابتلاء به اسکیزوفرنی را به همراه دارند.[۱۲]
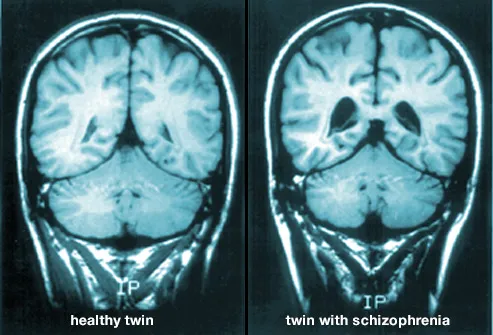
##اهمیت موضوع
به گزارش ***سازمان بهداشت جهانی***: [۱۳]
> حدود **۰.۳-۰.۷** از مردم جهان در حال حاضر از اختلال اسکیزوفرنی رنج میبرند. طبق آخرین آمار در سال ۲۰۱۱، حدود **۲۴ میلیون نفر** در سراسر جهان تحت تأثیر اسکیزوفرنی قرار گرفتند.
اسکیزوفرنی هزینههای جانی و مالی بسیاری دارد.[۳] اسکیزوفرنی به کاهش امید به زندگی از ۱۲–۱۵ سال منتج میشود، به دلیل به همراه داشتن چاقی، بی حرکتی در طول زندگی روزمره، سیگار کشیدن و افزایش قابل ملاحظه احتمال خودکشی.[۳]
اسکیزوفرنی یکی از علل عمده ناتوانی است. حدود سه چهارم از افراد مبتلا به اسکیزوفرنی همراه با عود کردن بیماری از ناتوانی مداوم برخوردارند.[۱۴] تنها برخی به طور کامل بهبود مییابند.[۱۵] بسیاری از افراد مبتلا به اسکیزوفرنی، برای مابقی زندگی خود با پشتیبانی دیگران زندگی میکنند.[۳]

در حال حاضر اسکیزوفرنی با پرسش سوال از افراد در مورد احساسات آن ها یا چیزی هایی که دوست دارند، تشخیص داده می شود؛ اما در برخی از موارد متخصصان نمی توانند به سادگی از این روش برای تشخیص استفاده کنند؛ زیرا برخی از افراد نمی توانند به راحتی احساسات خود را بیان کنند و یا نمیتوانند با متخصصان سلامت روانی ارتباط برقرار کنند و مشکلات خود را با آن ها در میان بگذارند. از سویی دیگر عدم تشخیص میتواند باعث ایجاد مشکلات جدی در زندگی افراد شود و حتی می تواند منجر به خودکشی افراد شود.
همان طور که پیشتر اشاره شد، بخشی از شبکه عصبی مغز در افراد اسکیزوفرن تحت تاثیر قرار می گیرد که با **MRI** میتوان این بیماری را تشخیص داد. اسکن مغز افراد برای تشخیص اینکه افراد دچار اسکیزوفرنی هستند یا نه، تنها ده دقیقه طول می کشد، چه بسا ده دقیقهای که میتواند باعث بهبود کامل جنون بیمار شود، اما در حال حاضر دستگاه های MRI به صورت گسترده در همه جا یافت نمی شود و برخی از افراد با شرایط خاص (مثلا افرادی که در بدن آن ها از ضربان ساز استفاده شده است) نمی توانند از دستگاه های MRI استفاده کنند.
در آخر باید توجه داشت اگر چه راهکارهایی برای شروع روش های درمانی خاص وجود دارند؛ اما با قطعیت نمی توان گفت که این روش های درمانی تا چه اندازه ای به بیماران خاص کمک می کنند[۱۶]؛ اما می توان گفت الگوهای ایجاد شده از ناحیه های مغز توسط محققان، می توانند به آن ها کمک کنند تا **میزان بهبود** افراد را به درستی تشخیص دهند.
#**پردازش تصاویر**
پردازش تصاویر دارای دو شاخه عمدهٔ بهبود تصاویر و بینایی ماشین است. بهبود تصاویر دربرگیرندهٔ روشهایی چون استفاده از فیلتر محوکننده و افزایش تضاد برای بهتر کردن کیفیت دیداری تصاویر و اطمینان از نمایش درست آنها در محیط مقصد (مانند چاپگر یا نمایشگر رایانه)است، در حالی که بینایی ماشین به روشهایی میپردازد که به کمک آنها میتوان معنی و محتوای تصاویر را درک کرد تا از آنها استفاده شود.
در معنای خاص پردازش تصویر عبارتست از هر نوع پردازش سیگنال که ورودی یک تصویر است و خروجی پردازشگر تصویر میتواند یک تصویر یا یک مجموعه از نشانهای ویژه یا متغیرهای مربوط به تصویر باشد. اغلب تکنیکهای پردازش تصویر شامل برخورد با تصویر به عنوان یک سیگنال دو بعدی و بهکار گرفتن تکنیکهای استاندارد پردازش سیگنال روی آنها میشود. پردازش تصویر اغلب به پردازش دیجیتالی تصویر اشاره میکند ولی پردازش نوری و آنالوگ تصویر هم وجود دارند.[۲۷]
پردازش تصویر در بسیاری از شاخه های علمی از جمله پزشکی ، باستان شناسی، حمل و نقل ، رباتیک ، کنترل صنعتی ،سیستم های دفاعی و .. وارد شده و باعث تحولی چشمگیر در این زمینه ها شده است .
یکی از سیستم های پر استفاده تصویربرداری ام آر آی می باشد، که تصاویر بدون پردازش آن برای بهبود ادراک بهتر تصاویر توسط انسان و پردازش داده های تصویر برای ادراک ماشین نیازمند پردازش های وسیع و گسترده ای روی آن هست، برای مثال حذف نویز، اختصاص رنگ، بازسازی تصاویر در کامپیوتر به صورت سه بعدی و درون یابی اطلاعات جهت تولید برش های لازم از ارگان تحت تصویربرداری (در این پروژه مغز) می باشد.
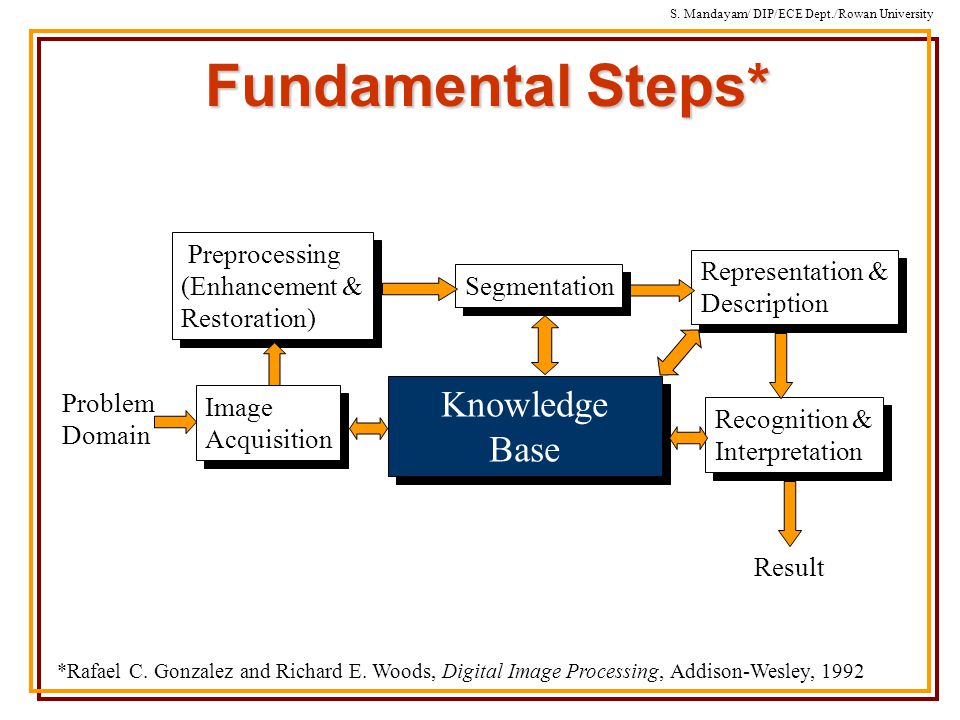
1. مرحله preprocessing (پیش پردازش) : پس از تصویربرداری پیش پردازش انجام می شود. هدف اصلی بهبود تصویر است به عنوان مثال حذف نویز و ارتقاء رنگ ها از داده های تصویری در این مرحله انجام می شود.
2. مرحله segmentation (بخش بندی) :
بخش بندی تصویر روشی است برای نام گذاری هر پیکسل به طوری که پیکسل هایی که دارای ویژگی های یکسان هستند نام یکسان دارند. پس هر قطعه شامل پیکسل هایی است با ویژگی های یکسان.
هدف از بخش بندی یک تصویر این است که عکس را طوری به قسمت هایی تبدیل کنیم که برای تحلیل و بررسی و پردازش قابل درک تر و آسان تر باشند. با این عمل یافتن مرز ها یا اشیا سهل تر خواهد شد.
بخشبندی، یکی از شاخه های اصلی در علم پردازش تصویر است که مهمترین کارکرد آن، تصحیح مرزهای مخدوش بین بخشهای مختلف تصویر است. هدف از بخش بندی، جداسازی اجزای اصلی تشکیل دهنده ی تصویر است. دقت بخش بندی تصویر، اثر مستقیمی در کارایی کل سیستم میگذارد به طوری که میتواند موفقیت یا شکست احتمالی تحلیل نهایی تصویر را تعیین کند. در کاربردهای هوایی وسنجش از دور، تنها شناسایی اشیای روی زمین برای بخش بندی مورد نظر است. بخش بندی به طور گستردهای در علم سنجش از دور به کار میرود. این پیش پردازش به عنوان مثال فرایند تقسیم یک تصویر به گروه های همگن تعریف میشود به طوری که هر ناحیه همگن باشد ولی اجتماع هیچ یک از دو ناحیه ی مجاور آن همگن نباشد.
خروجی مرحله بخش بندی، مرز یک ناحیه و یا تمام نقاط درون یک ناحیه است. در این مرحله باید توجه داشت:
+ نمایش مرزی زمانی مفید است که مشخصات خارجی شکل (مانند گوشه ها یا خمیدگی ها ) مهم باشد و نمایش ناحیه ای وقتی مفید است که خواص درونی بخش های تصویر( مانند بافت شکل ) مورد توجه باشد.
3. مرحله representation and describtion (توضیح و توصیف یا انتخاب ویژگی) : در این مرحله، روشی برای برجسته کردن ویژگی های مورد نظر اجرا می شود. برای مثال در تشخیص بیماری اسکیزو فرنی تفاوتهایی در لب قدامی مغز هیپوکامپها و لب گیجگاهی و کاهش حجم ماده خاکستری و سفید افراد که در تصویر MRI باعث تمایز بیمار از شخص سالم می شود.
4. مرحله recognition and interpretion (تشخیص و تفسیر) : طی این مرحله با استفاده از اطلاعات توصیف گر ها ، یک برچسب به هر شی نسبت داده می شود (در این پروژه: مبتلا به اسکیزوفرنی یا سالم) .
#**الگوریتم های تشخیص**
تشخیص الگو شاخهای از مبحث یادگیری ماشینی است. میتوان گفت تشخیص الگو، دریافت دادههای خام و تصمیم گیری بر اساس دستهبندی دادهها است. روشهای تشخیص الگو، الگوهای مورد نظر را از یک مجموعه دادهها با استفاده از دانش قبلی در مورد الگوها یا اطلاعات آماری دادهها، جداسازی میکند. الگوهایی که با این روش دستهبندی میشوند، گروههایی از اندازهگیریها یا مشاهدات هستند که نقاط معینی را در یک فضای چند بعدی تشکیل میدهند. این ویژگی اختلاف عمده تشخیص الگو با تطبیق الگو است، که در آنجا الگوها با استفاده از موارد کاملا دقیق و معین و بر اساس یک الگوی مشخص، تشخیص داده میشوند. مسئله دسته بندی یکی از مسائل اصلی مطرح شده در یادگیری ماشین است و بسیاری از مسائل را می توان به صورت یک مسئله دسته بندی مطرح کرده و حل کرد.[۳۴]
شایان توجه است مدل یادگیری برای این مسئله، یادگیری با ناظر است یعنی سیستم با استفاده از یک مجموعه از مثال های برچسب گذاری شده(توسط انسان)، دسته بندی را یاد می گیرد. در این روش ابتدا سامانه به وسیلهی داده های آموزشی که به صورت دستی و به وسیله ی انسان برچسب گذاری شده اند آموزش دیده، با یادگیری از طریق این داده ها به تشخیص خودکار بیماری اسکیزوفرنی در عکس ها می پردازد. روش های با ناظر به داده های برچسب گذاری شده برای ساخت یک مدل آماری نیاز دارند. استفاده از داده های آموزشی نامناسب باعث افت شدیدی در دقت کلاس بندی شده و این اهمیت داده های آموزشی مناسب را نشان میدهد.
این دسته روش، اولین بار توسط Pang و lee با بررسی چند مدل classifier مورد پژوهش قرار گرفتند [۳۲] . آنها روش های SVM - Naive bayes - MAX Entropy را مورد بررسی قرار دادند و بین آنها SVM را دارای بالاترین و Naive bayes را دارای پایین ترین دقت ارزیابی کردند[۳۳] .
پیش از توضیح الگوریتم ها لازم است به FNC و SBM پرداخته شود.[۲۹] و [۳۰]
####مجموعه Functional Network Connectivity :
مجموعه FNC از FMRI (تصویرسازی تشدید مغناطیسی کارکردی) [۲۸] ، به دست میآید و هماهنگی بین مناطق مختلف مغز را توصیف می کند.
####مجموعه Source-Based Morphometry :
مجموعه SBM از اسکن MRI (تصویرسازی تشدید مغناطیسی)[۳۱] مشتق شده و غلظت ماده خاکستری را در مناطق مخنلف مغز نشان می دهد.
در [این مسابقه](http://mlsp2014.conwiz.dk/competition.htm) تصویر اسکن مغزی افرادی در بازه سنی ۱۸-۶۵ سال وجود دارد. training data شامل۴۶ بیمار اسکیزوفرن و ۴۰ فرد سالم است. test set تشکیل شده از ۱۱۹,۷۴۸ سوژه بدون label میباشد.
مجموعه داده های برای یادگیری که شامل ۸۶ فرد می باشد، شامل سه مجموعه ی زیر است :
+ فایل train_labels.csv : به هر فرد یک Id و یک برچسب داده شده است. به فرد سالم برچسب صفر و به بیمار اسکیزوفرنی برچسب یک داده شده است.
+ فایل train_FNC.csv : برای هر فرد 378FNC معین شده و اعدادی که به هر FNC نسبت داده شده، که این مقادیر در واقع از ارتباط بین هر جفت نقشه های مغز به دست آمده است.
+ فایل train_SBM.csv :شامل 32SBM برای هر فرد است. این مقادیر وزن های استانداردی هستند که غلظت ماده خاکستری در مناطق مختلف مغز را نشان می دهند.
در ادامه نمونه هایی از الگوریتم هایی که برای دسته بندی جهت تشخیص بیماری اسکیزوفرنی استفاده شده اند، معرفی می شوند.
##روش SVM :
الگوریتم SVM اولیه در ۱۹۶۳ توسط Vladimir Vapnik ابداع شد و در سال ۱۹۹۵ توسط Vapnik و Corinna Cortes برای حالت غیرخطی تعمیم داده شد. ماشین بردار پشتیبانی یکی از روشهای یادگیری با نظارت است که از آن برای طبقهبندی و رگرسیون استفاده میکنند.
این روش از جمله روشهای نسبتاً جدیدی است که در سالهای اخیر کارایی خوبی نسبت به روشهای قدیمیتر برای طبقهبندی از جمله شبکههای عصبی پرسپترون نشان داده است. مبنای کاری دستهبندی کننده SVM دستهبندی خطی دادهها است و در تقسیم خطی دادهها سعی میکنیم خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد. حل معادله پیدا کردن خط بهینه برای دادهها به وسیله روشهای QP که روشهای شناخته شدهای در حل مسائل محدودیتدار هستند صورت میگیرد.[۳۵]
الگوریتم SVM از یک تکنیک که kernel trick نامیده می شود، برای تبدیل دادهها استفاده میکند و سپس بر اساس این تبدیل، مرز بهینه بین خروجیهای ممکن را پیدا میکند. به عبارت ساده تبدیلات بسیار پیچیده را انجام میدهد، سپس مشخص میکند چگونه دادههایتان را بر اساس برچسبها یا خروجیهایی که تعریف کرده اید، جدا کنید.
لذا یکی از روشهایی که در حال حاضر به صورت گسترده برای مسئله دستهبندی مورد استفاده قرار می گیرد، روش ماشین بردار پشتیبان است. شاید به گونه ای بتوان محبوبیت کنونی روش ماشین بردار پشتیبان را با محبوبیت شبکههای عصبی در دهه گذشته مقایسه کرد. علت این قضیه نیز قابلیت استفاده این روش در حل مسائل گوناگون میباشد، در حالیکه روشهایی مانند درخت تصمیمگیری را نمیتوان به راحتی در مسائل مختلف بکار برد.[۳۶] و [۳۷]
به طور ساده تر این الگوریتم پیش بینی می کند یک نمونه در کدام کلاس یا گروه قرار می گیرد.
این الگوریتم برای تفکیک دو کلاس از هم، از یک صفحه استفاده می کند به طوریکـه ایـن صـفحه از هـر طرف بیشترین فاصله را تا هر دو کلاس داشته باشد . نزدیک ترین نمونه های آموزشی به این صفحه "بردارهای پشتیبان" نام دارند.

به عنوان مثال، صفحه ی H1 و H2 دو کلاس را از هم تفکیک کرده اند، اما کلاس H3 در شرایط این الگوریتم صدق مـی کند.

روش کلی بردارهای پشتیبان:
فرض کنید n نمونه آموزشی در یک فضای حقیقی با ابعاد p و دو کلاس داریم، برای هر نمونه می توان نوشت:
که Ci خروجی هر کلاس برای نمونه آموزشی i ام است می خواهیم صفحه ای را پیدا کنیم که نقاط کلاس Ci=1 را از نقاط کلاس Ci=-1 جدا کنیم معادله این صفحه به صورت w.x-b=0 نوشته می شود که wبردار نرمال و عمود بر صفحه است و پارامتر |b/|w فاصله ی صفحه از مبدا بردار نرمـال، را مـشخص مـی کند برای هر نمونه اگر w.x-b>=1 آنگاه نمونه Xi متعلق به کلاس اول خواهد بود و در غیر این صورت اگر w.x-b=<-1 آنگاه نمونه Xi متعلق به کلاس دوم خواهد بود .مقادیر b و w باید به نحوی انتخاب شوند تا شرط مـاکزیمم بـودن فاصـله تامین شود. در مسئله ی بهینه سازی می توان دو رابطه ی بالا را به صورت 1=<(Ci(w.Xi - b نوشت که در این مسئله به دنبال مینیمم کردن مقادیر b و ||W|| هستیم. برای اینکه از ورود نقاط به حاشیه جلو گیری کنیم، شرایط زیر را اضافه می کنیم. برای هر i:
برای کلاس اول : 1 =< w . xi - b
برای کلاس دوم : w . xi - b => -1

##روش درخت تصمیم:
ساختار درخت تصمیم در یادگیری ماشین، یک مدل پیش بینی کننده می باشد که حقایق مشاهده شده در مورد یک پدیده را به استنتاج هایی در مورد مقدار هدف آن پدیده نقش می کند. تکنیک یادگیری ماشین برای استنتاج یک درخت تصمیم از داده ها، یادگیری درخت تصمیم نامیده می شود. هر گره داخلی متناظر یک متغیر و هر کمان به یک فرزند، نمایانگر یک مقدار ممکن برای آن متغیر است. یک گره برگ، با داشتن مقادیر متغیرها که با مسیری از ریشه درخت تا آن گره برگ بازنمایی می شود، مقدار پیش بینی شده متغیر هدف را نشان می دهد. یک درخت تصمیم ساختاری را نشان می دهد که برگ ها نشان دهندهی دسته بندی و شاخه ها ترکیبات فصلی صفاتی که منتج به این دسته بندی ها را بازنمایی می کنند. یادگیری یک درخت می تواند با تفکیک کردن یک مجموعهی منبع به زیرمجموعه هایی براساس یک تست مقدار صفت انجام شود. این فرآیند به شکل بازگشتی در هر زیرمجموعهی حاصل از تفکیک تکرار می شود. عمل بازگشت زمانی کامل می شود که تفکیک بیشتر سودمند نباشد یا بتوان یک دسته بندی را به همهی نمونه های موجود در زیرمجموعهی بدست آمده اعمال کرد.[۳۸]
از ویژگی های مثبت درخت تصمیم میتوان گفت:
+ درخت تصمیم از نواحی تصمیم گیری ساده استفاده میکند.
+ مقایسه های غیر ضروری در این ساختار حذف میشوند.
+ آماده سازی داده ها برای یک درخت تصمیم ساده یا غیر ضروری است.
+ درختهای تصمیم قادر به شناسایی تفاوتهای زیرگروه ها میباشد.
اما ویژگی منفی درختهای تصمیم، به صورت نمایی بزرگ شدن هنگام بزرگ شدن مسئله میباشد. همچنین اکثر درختهای تصمیم تنها از یک ویژگی برای شاخه زدن در گرهها استفاده میکنند(مانند مسئله بیماری اسکزوفرنی) در صورتی که ممکن است ویژگی ها دارای توزیع توأم باشند. ساخت درخت تصمیم حافظه زیادی را مصرف میکند زیرا برای هر گره باید معیار کارایی برای ویژگیهای مختلف را ذخیره کند تا بتواند بهترین ویژگی را انتخاب کند [۳۹]. با این حال می توان با استفاده از الگوریتم های ذیل، میتوان درخت تصمیم بهینه ای تشکیل داد.از انواع این الگوریتم ها میتوان به الگوریتم CART و Hunt و ID3 و C4.5 و SPRINT اشاره کرد که در ادامه به معرفی برخی از این الگوریتم ها میپردازیم.

###الگوریتم ID3 :
ویژگی این روش [۴۱] ساخت درخت تصمیم از بالا به پائین است. در آن از آزمونی آماری به نام بهره مطالعاتی(Gain Information) استفاده میشود تا مشخص گردد هر کدام تا چه حد قادر است به تنهایی داده های آزمایشی را دستهبندی کند. با انتخاب این صفت برای هر یک از مقادیر ممکن، شاخهای ایجاد شده و داده های آموزشی بر اساس ویژگی هر شاخه مرتب میشوند. به دنبال آن عملیات فوق برای مثالهای قرار گرفته در هر شاخه تکرار میشود تا بهترین ویژگی برای گره بعدی انتخاب شود. عملکرد الگوریتم جستجوی حریصانه است که در آن انتخابهای قبلی هرگز مورد بازبینی قرار نمیگیرند.
$$Gain Information(S,A) = Entropy(S) - \sum_{v \in (A) } (\frac{{S}_{v}} {S}) Entropy({S}_{v}) $$
$$Entropy(S) = \sum_{i=1}^{c} pi\log_{2}^{pi}$$
###الگوریتم CART :
الگوریتم[۴۲] CART یک روش تقسیم بندی بازگشتی باینری است . داده ها در این الگوریتم بصورت خام استفاده میشوند و هیچگونه پاکسازی نه نیاز است نه پیشنهاد میشود . درختان بدون استفاده از یک قانون متوقف کننده به رشد حداکثری خود میرسند و سپس اصلاح میشوند (که این کار قسمت به قسمت انجام میشود .) اصلاح تا ریشه ادامه دارد و با اصلاح پیچیدگی کار بالا میرود. قسمت بعدی برای اصلاح بخشی است که کمترین کمک را به کارکرد کلی درخت در پردازش اطلاعات میکند (و ممکن است در یک زمان بیشتر از یک بخش حذف شود). هدف مکانیزم CART تولید تنها یک درخت نیست بلکه تولید یک سری درختان اصلاح شده تو در توست که همه آن درختان بهینه داوطلب هستند . درخت با اندازه مناسب یا “درخت درست ” به وسیله ارزش گذاری عملکرد پیشگویانه هر درخت در توالی اصلاح ، شناخته میشود . CART هیچگونه اندازه عملکرد داخلی برای انتخاب درخت براساس پردازش اطلاعات پیشنهاد نمی کند زیرا این ها قابل اطمینان نیستند . به جای آن عملکرد درخت در آزمایش داده های جداگانه (یا از طریق تائید میانه ) اندازه گیری میشود و انتخاب درخت تنها پس از ارزشیابی آزمایش داده ها صورت میگیرد . اگر هیچ آزمایش داده ای وجود نداشته باشد و تائیدیه میانی انجام نشده باشد CART نمیتواند بهترین درخت توالی را مشخص کند . این با روش هایی مانند C4.5 که مدل های برتر را بر اساس اندازه هایپردازش داده ایجاد میکنند همسان نیست .
درخت ابتدا با تعیین متغیر Xj از میان تمام متغیر ها ساخته می شود، این متغیر "بهترین پیش بینی" را برای Y(متغیر پاسخ) خواهد داشت. بعد از انتخاب این متغیر، افراد بر اساس مقادیر Xj به دو گروه مختلف در درخت تقسیم می شوند. در این صورت افرادی که MRI آن ها ویژگی های MRI بیمار اسکیزوفرنی را دارد به یک گروه و سایر افراد به گروه دیگر تقسیم می شوند. این فرایند در هر گره به وجود آمده تکرار می شود. مجموعه افراد با $\Omega$ نشان داده می شود. "بهترین پیش بینی" اول با X1 نشان داده می شود. بر اساس مقادیر X1 افراد به دو گروه $\Omega1`$ و $\Omega2 $ تقسیم می شوند. که در آن :
$$ { \Omega }_{ 1 }=\left\{ i:{ x }_{ i1 }={ 0 } \right\} { , }\quad { \Omega }_{ 2 }=\left\{ i:{ x }_{ i1 }={ 1 } \right\} { ,\quad { i\quad =\quad { 1,2,... } } } $$
گام بعدی الگوریتم ساختن درخت، تشخیص متغیر بعدی است که "بهترین پیش بینی" را برای متغیر Y داشته باشد، اما در داخل هر گروه $\Omega1`$ یا $Omega1\$ ، زیرگروه های بعدی بر اساس مقادیر Xi2 و Xi3 تعریف می شوند. این فرایند آنقدر به صورت بازگشتی ادامه می یابد تا به شرایط ملاک توقف برسیم. در آخر بعد از ساختن درخت ممکن آن را هرس نماییم.
###الگوریتم Hunt :
توسعه این درخت[۴۰]، با یک روش بازگشتی با جداسازی داده های آموزشی به زیر مجموعه هایی که به طور تکرار شونده تخلیص میشوند، میباشد.
برای مثال مجموعه ${ D }_{ t }$ داده های آموزشی ما است که در نظر داریم تصمیمی در مورد تعلق یک مقدار به گره t-ام اتخاز کنیم. آنگاه داریم:
- اگر ${ D }_{ t }$ شامل رکوردهایی باشد که متعلق به کلاس یکسان ${ y }_{ t )$ هستتند، آنگاه t یک گره برگ است که با ${ y }_{ t }$ برچسب گذاری می شود.
- اگر ${ D }_{ t }$ یک مجموعه ی خالی باشد، آنگاه t یک گره برگ با یک مقدار پیش فرض برای کلاس ${ y }_{ d }$ می باشد.
- اگر ${ D }_{ t }$ شامل رکوردهایی باشد که متعلق به بیش از یک کلاسند، یک صفت را برای جداسازی داده ها به زیرمجموعه هایی کوچکتر تست می کنیم. و همان طور که اشاره شد برای هر زیر مجموعه روند را به صورت بازگستی به کار می گیریم.
##روش Random Forest :
جنگل تصادفی[۴۳]، درخت تصمیم های زیادی را تولید می کند. برای طبقه بندی یک شیء جدید از برداری ورودی در انتهای هر یک از درختان جنگل تصادفی قرار میدهد. هر درخت پدیدآورنده یک طبقه بندی میشود و گوییم این درخت به آن کلاس “رأی” میدهد. جنگل طبقه بندیای که بیشترین رأی را داشته باشد (بین همه درخت های جنگل) انتحاب میکند.
$$f(x,{\theta}_{k}) , k=1 , 2 , ... , K$$
درحالتی که ${\theta}_{k}$ ها بردارهای رندوم مستقل از توزیع هستند و هر درخت در ورودی x برای برچسب رأی گیری میکند. حال (X = (X1, X2, ... , Xp مجموعهای است از P متغیر، Xj= (X1 j ,X2 j ,...,Xnj ) m و Y صفت تحت بررسی ما یعنی ابتلا به اسکیزوفرنی است و n تعداد افراد نمونه است. همچنین b شماره درخت و B تعداد کل درختان است. مقدار اولیه b را برابر یک قرار می دهیم. در گام k-ام ، $\theta k$ نمونه مستقل و با توزیع یکسان از مجموعه داده ها انتخاب می گردد. همچنین x نیز نمونه تصادفی از مجموعه متغیر های پیش بین مورد مطالعه انتخاب می گردد. تابع پیش بین h با استفاده از x و تتایk ساخته می شود. گام ها B مرتبه تکرار شده تا به تعداد B درخت برسیم. اگر P > Q باشد، x به به کلاس 1 (بیماران اسکیزوفرنی) تعلق دارد و برعکس، اگر P < Q باشد، پیش بینی می نماید که به کلاس 0 (افراد سالم) تعلق دارد.
$$ { P\quad =\quad \sum _{ K=1 }^{ E }{ I\left( h\left( x,{ \theta }_{ k } \right) \right) } }=\quad { 1 } $$
$$ { Q\quad =\quad \sum _{ K=1 }^{ E }{ I\left( h\left( x,{ \theta }_{ k } \right) \right) } }=\quad { 0 } $$
##روش فرایند گوسی :
این روش بر مبنای الگوی یادگیری ماشین های بیزی می باشد. در یادگیری بیزی اطلاعات اولیه در مورد داده ها را مدل سازی میکنیم، سپس به صورت یکپارچه با اطلاعات حاصل از داده های نمونه گیری شده ، ادغام میکنیم. ساختمان استنتاج الگوریتم های بیزی سیار شبیه روند طبیعی استدلال در انسان هاست. در واقع داشتن پیش فرض هایی در رابطه با یک حقیقت و استنتاج به وسیله ی تابعی که امکان پذیربودن رخدادی را به شرط داشتن پارامترهای پیش فرض برای بدست آوردن امکان پذیر بودن رخداد مورد نظر، اساس کار استدلال و آموزش بیزی بوده، که بسیار مشابه روند استدلالی در انسان است. مدل بر اساس فرض داشتن یک فرایند گوسی روی داده های ورودی است. داده های آموزشی : {( D = {(Xi , Yi داده های تست : {( D={(X_i , Y_iبر اساس عملیات ریاضی که در فرآیند گوسی انجام می دهد، به داده های خروجی برچسبی را نسبت می دهد ، در این نمونه مقاله به بیماران اسکیزوفرنی عدد ۰ و به افراد سالم 1 نسبت میدهد.
# **کارهای مرتبط**
در مقام تحقیق در راهحل های ارائه شده در این مسابقه باید خاطر نشان کرد:
+ راه حل رتبه نخست [۲۶] این مسابقه بر پایه [۲۵]Gaussian process classification و در ادامه استفاده از توزیع برنولی برای شانس موفقیت است.
+ رتبه دوم مسابقه [۲۲] ابتدا از random vector استفاده کرده سپس با استفاده از random forest و استفاده از Gini-index مسئله را حل میکند.
+ رتبه سوم این مسابقه [۲۳] از متود کمتر شناخته شده تری برای حل مسئله استفاده میکند، [۲۴] (Distance Weighted Discriminant (DWD
+ رتبه هشتم و نهم مسابقه [۲۱] از رگرسیون خطی و svm برای دسته بندی و تفکیک داده ها استفاده کردهاند و با استفاده از sci-kit پایتون مسئله را حل کرده اند.
+ رتبه شانزدهم مسابقه با استفاده از [۱۷] Bayesian analysis مسئله را حل کرده است.
# **آزمایشها**
# **کارهای آینده**
در صورت دسترسی داشتن به سابقه خانوادگی بیماری اسکیزوفرنی در بیمار و یا دسترسی به اطلاعات مهمی نظیر سن فرد، جنسیت، استفاده از مواد مخدر، استفاده از داروهای متنوع، میتوانیم با دخیل کردن این اطلاعات هنگام کلاس بندی، شاهد اعتلای درصد درستی نتیجه باشیم.
# **مراجع**
+ [1]:[صفحه رسمی مسابقه تشخیص اسکیزوفرنی](http://mlsp2014.conwiz.dk/competition.htm)
----------
+ [2]:"Schizophrenia" Concise Medical Dictionary. [انتشارات دانشگاه آکسفورد]
+ [3]:van Os J, Kapur S. [Schizophrenia](http://xa.yimg.com/kq/groups/19525360/611943554/name/Schizophrenia+-+The+Lancet.pdf)
+ [4]:Buckley PF, Miller BJ, Lehrer DS, Castle DJ. [Psychiatric comorbidities and schizophrenia](http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2659306/).
+ [5]:Carson VB (2000). [Mental health nursing: the nurse-patient journey](http://books.google.com/books?id=QM5rAAAAMAAJ)
+ [6]:_[Schizophrenia](http://books.google.com/books?id=x3fmsV55rigC&pg=PA21)_. Wiley-Blackwell; 2003.
+ [7]:Brunet-Gouet E, Decety J. Social brain dysfunctions in schizophrenia: a review of neuroimaging studies.
+ [8]:_[Schizophrenia](http://books.google.com/books?id=x3fmsV55rigC&pg=PA21)_. Wiley-Blackwell; 2003
+ [9]:Ungvari GS, Caroff SN, Gerevich J. The catatonia conundrum: evidence of psychomotor phenomena as a symptom dimension in psychotic disorders.
+ [10]:Kircher, Tilo and Renate Thienel. _[The Boundaries of Consciousness](http://books.google.com/?id=YHGacGKyVbYC&pg=PA302)_. Amsterdam: Elsevier; 2006
+ [11]:[Coyle 2006](https://fa.wikipedia.org/wiki/%D8%A7%D8%B3%DA%A9%DB%8C%D8%B2%D9%88%D9%81%D8%B1%D9%86%DB%8C#CITEREFCoyle2006)
+ [12]:Green MF. Cognitive impairment and functional outcome in schizophrenia and bipolar disorder. _Journal of Clinical Psychiatry_.
+ [13]:World Health Organization. [Schizophrenia](http://www.who.int/mental_health/management/schizophrenia/en/)
+ [14]:Smith T, Weston C, Lieberman J. Schizophrenia (maintenance treatment). _Am Fam Physician_
+ [15]:Warner R. Recovery from schizophrenia and the recovery model. _Curr Opin Psychiatry_. 2009
+ [16]:Marshall M, Rathbone J. Early intervention for psychosis. _Cochrane Database Syst Rev
+ [17]:[ What is Bayesian analysis](https://www.stata.com/features/overview/bayesian-intro/)
+ [18]:https://kaggle2.blob.core.windows.net/forum-message-attachments/51131/1432/Lebedev_AV_MLSP_2014_Sch.pdf
+ [19]:https://kaggle2.blob.core.windows.net/forum-message-attachments/51131/1459/Lebedev_AV__MLSP2014_Sch.pdf
+ [20]:C. E. Rasmussen and C. K. I. Williams. Gaussian Processes for Machine Learning. The MIT
+ [21]:https://github.com/gabegaster/kaggle_schizophrenia_2014
+ [22]:https://www.kaggle.com/c/mlsp-2014-mri/discussion/9854
+ [23]:https://www.kaggle.com/c/mlsp-2014-mri/discussion/9967
+ [24]:J. S. Marron, Michael Todd, Jeongyoun Ahn. Distance Weighted Discrimination. Journal of the
American Statistical Association; Volume 102, Issue 480, 2007
+ [25]:1. C. E. Rasmussen and C. K. I. Williams. Gaussian Processes for Machine Learning. The MIT
Press, 2006.
+ [26]:https://www.kaggle.com/c/mlsp-2014-mri/discussion/9907
+ [27]:https://fa.wikipedia.org/wiki/پردازش_تصویر
+ [28]: https://en.wikipedia.org/wiki/Functional_magnetic_resonance_imaging
+ [29]: https://www.ncbi.nlm.nih.gov/pubmed/22255319
+ [30]: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2751641/
+ [31]: https://en.wikipedia.org/wiki/Magnetic_resonance_imaging
+ [32]:1. Sentiment Analysis - A multimodal approach by Lucas Carstens
+ [33]:Bo Pang; Lillian Lee and Shivakumar Vaithyanathan (2002)."Thumbs up? Sentiment Classification using Machine Learning Techniques
+ [34]:http://www.boute.ir/iust-ai-94/mlsp-2014-mri#fn-functional%20network%20connectivity
+ [35]:http://www.boute.ir/iust-ai-94/face-recognition
+ [36]:http://www.bigdata.ir/1394/05/svm
+ [37]:http://www.analyticsvidhya.com/blog/2014/10/support-vector-machine-simplified
+ [38]:لعبت عزیزی "گزارش تحقیق درس یادگیری ماشین"
+ [39]:_Y. Yuan and M.J. Shaw, Induction of fuzzy decision trees.Fuzzy Sets and Systems 69 (1995), pp. 125–139._
+ [40]:http://mines.humanoriented.com/classes/2010/fall/csci568/portfolio_exports/lguo/decisionTree.html
+ [41]:http://profsite.um.ac.ir/~monsefi/machine-learning/pdf/Decision-Tree-1.pdf
+ [42]:Application and Comparison of Random Forest and CART in Genetic Association Study in Coronary Artery Disease
+ [43]:https://kaggle2.blob.core.windows.net/forum-message-attachments/51131/1459/Lebedev_AV__MLSP2014_Sch.pdf