نویسهخوانی به عملیات تشخیص متن در عکس و تبدیل آن میباشد. در این پروژه از شما انتظار میرود تا متن فارسی را در تصاویر حاوی متون تایپ شده فارسی تشخیص دهید.

# مقدمه
**نویسهخوان نوری** که با سرواژهی **OCR** شناخته میشود، عبارت است از تشخیص (recognition) خودکار متون موجود در تصاویر اسناد و تبدیل آنها به متون قابل جستجو و ویرایش توسط رایانه. تصویر سند غالباً توسط روبشگر یا دوربین دیجیتال تولید میشود. این تصاویر شامل تعدادی پیکسل با رنگهای مختلف است که هر رنگ با ترکیب سه رنگ اصلی سبز، آبی و قرمز ساخته میشوند. از دید انسان، یک سند ممکن است ارزش اطلاعاتی زیادی داشته باشد، لیکن از دید رایانه تصویر یک سند با تصویر یک منظره تفاوتی ندارد، چرا که هر دوی آنها مجموعهای از پیکسلها هستند. برای اینکه بتوان از اطلاعات نوشتاری تصویر سند استفاده کرد، بایستی به نحوی نوشتههای موجود در سند را تشخیص دهیم. چنین کاری توسط نرمافزارهای نویسهخوان نوری انجام میشود.
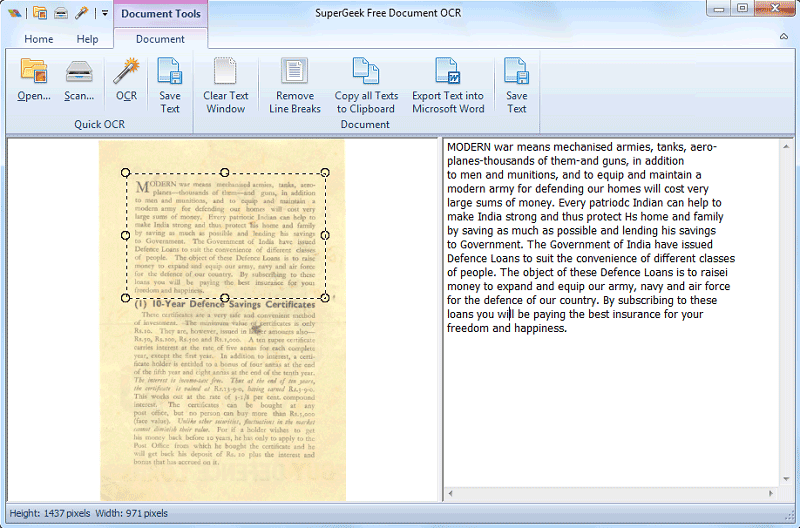
نویسهخوان نوری ابتدا تنها در مورد بازشناسی ارقام و حروف چاپی بکار گرفته میشد. پسوند نوری در این عبارت در مقابل عبارت مرکب مغناطیسی قرار داده شد تا این روش را از روش قدیمیتر بازشناسی نویسهها با مرکب مغناطیسی ،MICR، متمایز کند. با گذشت زمان و پیشرفت قابل توجه در این زمینه، روشهای بازشناسی دستنوشته و متون چاپی مطرح شدند که دامنهی کار را به کلمات و عبارات رساندند.

سامانهی نویسهخوان مثل یک نفر ماشیننویس، متن سند را میخواند و آن را به قالب مناسب برای ذخیره در رایانه تبدیل میکند. معمولاً اسکنر، تصاویر مورد نیاز برای تشخیص نویسه را فراهم میآورند. سامانهی نویسهخوان، اشیاء موجود در تصویر سند را که ارقام، حروف، علائم و کلمات هستند، بازشناسی کرده و رشتهی متناظر با آنها را در قالب مناسب ذخیره میکند. یک فایل تصویری، حجم زیادی دارد و جستجوی متنی در آن ممکن نیست. این در حالی است که فایل خروجی سامانهی نویسهخوان بسیار کم حجم و قابل جستجو است.
سامانههای نویسهخوان مثل بسیاری از سامانههای هوشمند دیگر، پیچیدگی زیادی دارند. پردازش تصویر و بازشناسی الگو دو مبحث اصلی در این سامانهها هستند. پیچیدگی این سامانهها برای زبانهای گوناگون، متفاوت است. به عنوان مثال نوشتن نویسهخوانی نوری برای زبانهای لاتین به دلیل اینکه حروف آنها به طور مجزا نوشته میشود آسانتر است از زبانهایی مثل فارسی و عربی که حروف یک کلمه به یکدیگر میچسبند. این موضوع به علاوهی جمعیت کم کاربران زبان فارسی، سبب شده سامانههای نویسهخوان زبان فارسی نقاط ضعف زیادی داشته باشند. البته در سالهای اخیر تلاشهای قابل تقدیری از سوی برخی شرکتهای فعال در زمینهی پردازش تصویر انجام شده که برخی از آنها منجر به محصولات قابل قبولی شده است.
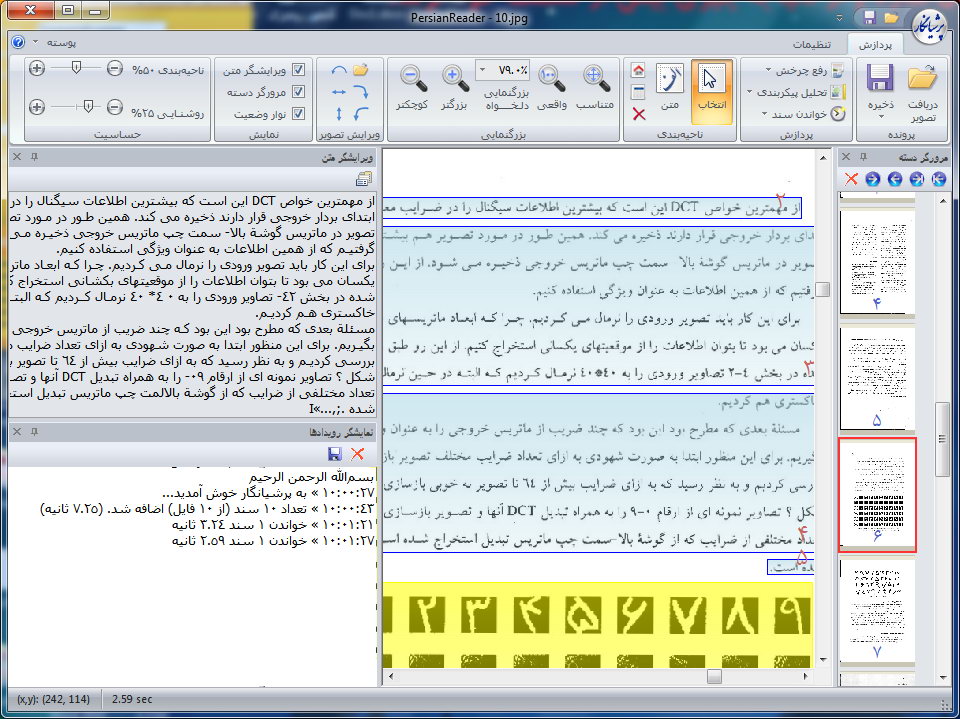
در نسخههای اولیهی نرمافزارهای موجود برای این کار به خصوص در زبان انگلیسی باید برای هر کاراکتر تصویری برای آموزش ردهبند در نظر گرفته میشد، و تنها برای یک فونت خاص نیز امکان پذیر بود. حالا سیستمهای پیشرفته قادر به تشخیص اکثر فونتها هستند با دقت بالا هستند و میتوانند با انواع فرمتهای ورودی و خروجی کار کنند و فایل خروجی بیشترین شباهت را با عکس ورودی از لحاظ ظاهر و چینش محتوا شامل جداول و عکسهای داخل متن دارد.
**انواع نویسهخوانی**
1. بازشناسی حروف: در این مورد به بازشناسی حروف به صورت تک تک در متون تایپ شده علاقهمندیم و متن را به صورت حرف حرف بازشناسی میکنیم. اصولا در زبانهایی مانند زبان انگلیسی برای شناسایی کلمات تنها کافی است تک تک حروف را بازشناسی کنیم و با استفاده از میزان فاصلهی میان کلمات آنها را تشخیص دهیم، زیرا در این زبانها حروف به یکدیگر نمیچسپند و همواره به صورت جدا نوشته میشوند.
2. بازشناسی کلمات: در بازشناسی کلمات، کلمات موجود در متون تایپ شده را به صورت کلمه کلمه بازشناسی میکنیم. یعنی در واقع در هر مرحله یک کلمه را انتخاب و بازشناسی میکنیم. این روش برای زبانهایی مانند زبان فارسی که کلمات آن به صورت مجموعه حروف به هم چسپیده هستند مناسب است.
3. بازشناسی حروف هوشمند: این روش با متون دستنویس سر و کار دارد و در هر مرحله یک یا چند حرف را از متن دستنویس بازشناسی میکند. معمولا این روش نیاز به تکنیکهای یادگیری ماشین دارد.
4. بازشناسی کلمات هوشمند: در اینجا کلمات در متن دستنویس بازشناسی میشوند و در هر مرحله یک یا چند کلمه تشخیص داده میشود.
# کارهای مرتبط
روش ارائه شده در این مقاله عمدتا براساس بازشناسی با استفاده از طرحهای عمودی و افقی رقمها در زبان فارسی همراه با سایر ویژگیهای آنهاست. در اینجا روشهایی ارائه شده است که توانایی بازشناسی ۱۰۰ درصدی ارقام در زبان فارسی را در کوتاهترین زمان میسر میکنند. از آنجا که در این مقاله هدف اصلی طراحی الگوریتم مناسب برای اجرای بر روی سختافزار است، فونت تک اندازه در نظر گرفته شده است. برای اجرای الگوریتم رقمخوان فارسی OCR، کد های VHDL مورد استفاده، جمع آوری و نصب در یک FPGA مناسب قرار گرفتند.[1]
بازشناسی حروف نوری (OCR) یک مزیت بسیار قدیمی و منحصر به فرد در زمینه شناسایی الگو است. در این مقاله یک روش بسیار قدرتمند برای تشخیص متن فارسی معرفی میکنیم. ما از اپراتورهای مورفولوژیکی، به ویژه اپراتور Hit / Miss استفاده کردیم تا هر زیر کلمه را توصیف کنیم و با استفاده از رویکرد تطبیق الگو سعی کردیم توصیف تولید شده را طبقهبندی کنیم. در این پیادهسازی تنها یک فونت در دو اندازه مختلف برای تأیید رویکرد الگوریتم استفاده شده است. نتیجهی موفقیت این پیاده سازی برابر با ۹۹.۹ درصد بوده است.[2]
بازشناسی حروف نوری (OCR) از اسکریپت های خط شکسته تعدادی مشکل چالش برانگیز در تقسیم بندی و به رسمیت شناختن فرآیندها به زبانهای مختلف از جمله فارسی را موجب میشود. برای غلبه بر این مشکلات، ما از یک روش تقسیمبندی کلمه تازه در زبان فارسی و یک روش تقسیمبندی مبتنی بر شناسایی برای غلبه بر مشکلات تقسیمبندی آن استفاده میکنیم. این روش قوی و انعطافپذیر است و همچنین تحمل سیستم را به تنوع فونت افزایش میدهد. نتایج پیادهسازی این روش در یک پایگاه داده جامع، درجه بالایی از دقت را نشان میدهد که با الزامات تجاری مورد استفاده قرار میگیرد. این روش با یک پیشپردازش و پردازش نهایی مناسب، یک چارچوب ساده و سریع برای توسعه کامل یک سیستم نویسهخوان فارسی ارائه میدهد.[3]
انگلیسی و چینی زبانهایی هستند که از متخصصان نویسهخوان علاقهی زیادی به مطالعه در مورد آنها دارند. در مقابل، تحقیق در زمینه شناخت حروف برای اسکریپتهای عربی و فارسی با مشکلات اساسی مواجه است که عمدتا مربوط به ویژگیهای منحصر به فرد آنهاست، مثل لغتنامه، اشکال مختلف یک کاراکتر در موقعیتهای مختلف در یک کلمه و اتصال حروف در کلمههاست. کار ارائه شده در این مقاله شامل سه مرحله عمده است، پس از دیجیتالی کردن متن، تصویر اولیه با استفاده از یک اسکنر 300 dpi به یک تصویر خاکستری تبدیل میشود، سپس مراحل پیش پردازش مختلف به فایل تصویر اعمال میشود. در مرحله بعد، زیر کلمات همهی کلمات به رسمیت شناخته شده و ویژگیهای عمده برای هر کلمه استخراج میشود.[4]
بسیاری از کارها بر روی OCR انگلیسی انجام شده است، اما OCR فارسی/عربی هنوز در حال توسعه است. یک فاز که معمولا در قسمت شناخت بخشی از یک سیستم OCR استفاده میشود، اندازه فونت متن را برآورد میکند. معمولا وقتی فونت اندازه متن پیدا می شود، عرض قلم محاسبه میشود. عرض قلم را میتوان برای تقسیمبندی حروف در OCR فارسی/عربی استفاده کرد. یک روش رایج برای برآورد اندازه قلم استفاده از مشخصات طرح ریزی است. در این مقاله روش جدیدی برای برآورد اندازه فونت متون چاپی فارسی/عربی معرفی شده است. این روش از نقطه در متن برای برآورد اندازه فونت استفاده میکند. از آنجا که متون فارسی/عربی دارای نقاط زیادی هستند، این روش میتواند دقیقا اندازه قلم را برآورد کند. یکی از مزایای اصلی روش ما، مقاومت شدیدی در برابر انحراف در حروف است.[5]
# آزمایشها
به دلیل وسیع بودن دامنهی اطلاعات مورد نیاز برای پروژه مانند پردازش سیگنال، کار با Open-CV، بازشناسی الگو و ... و همچنین کمبود وقت تاکنون پیادهسازیای برای پروژه انجام نشده است.
# کارهای آینده
1. افزایش تحقیقات در زمینهی نویسهخوانها و به خصوص نویسهخوانها در زبانهایی مانند فارسی که در آن کلمات با به هم چسپیدن حروف تولید میشوند.
2. کار بر روی کتابخانه Open-CV و تلاش برای تشخیص تصاویر حاوی متن فارسی نوشته شده.
3. تلاش در جهت تشخیص حروف فارسی (حروف جداگانه بدون حضور در کلمات) و ساختن یک ردهبند برای این کار
4. اقدام برای استفاده از موتورهای تشخیص متن در عکس و افزایش اطلاعات در آن باره
5. تلاش برای تولید نرمافزاری برای تشخیص و خواندن کلمات فارسی در متن و تبدیل آنها به نوشته
# ۵. ۵. مراجع
[1] N. Toosizadeh, M. Eshghi, "Design and implementation of a new Persian digits algorithm on FPGA chips", Signal Processing Conference, Antalya, Turkey, 2005
[2] M. Salmani Jelodar, M.J. Fadaeieslam, N. Mozayani, M. Fazeli, "A Persian OCR System using Morphological Operators", World Academy of Science, Engineering and Technology, 2005
[3] M. Zand, A. Naghsh Nilchi, S. A. Monadjemi, "Recognition-based Segmentation in Persian Character Recognition", International Journal of Computer and Information Engineering, Vol:2, No:2, 2008
[4] M. Kavianifar, A. Amin, "Preprocessing and structural feature extraction for a multi-fonts Arabic/Persian OCR", Document Analysis and Recognition, 1999
[5] M.H Shirali-shahreza, S. Shirali-Shahreza, "Persian/Arabic Text Font Estimation using Dots", Signal Processing and Information Technology, 2006
# ۶. ۶. لینکهای مفید
+ [کتابخانهی OpenCV برای پایتون](https://opencv-python-tutroals.readthedocs.org/en/latest/py_tutorials/py_tutorials.html)
+ [اوسیآر متنباز فارسی](https://github.com/reza1615/PersianOcr)
+ [طراحی و پیاده سازی OCR دست نویس فارسی با استفاده از عناصر ابتدایی تشکیل دهنده حروف ](http://www.matlabi.ir/ocr)
+ [نویسهخوان فارسی توسکا](http://tooska.co)
+ [نویسهخوان پرشیانگار](http://farsiocr.ir/project/نویسه-خوان-پرشیانگار)
+ [پیادهسازی نویسهخوان برای زبان هندی (کلمات در زبان هندی نیز مانند فارسی از چسپیدن حروف به هم ساخته میشوند.)](http://hacking-tesseract.blogspot.nl/)