پیدا کردن یک قطعه آهنگ با شنیدن بخشی از آن، نیاز به نمایهسازی مجموعه آهنگها دارد، درست مثل جستجوی واژهها.
# مقدمه
در این سیستم قطعه های کوتاه آهنگ ( معمولاً بین 3 تا 30 ثانیه ) که قسمتی از آهنگ مورد نظر کاربر می باشد به عنوان ورودی نمایه سازی می شود و این نمایه با پایگاه داده ای که شامل نمایه هایی از آهنگ های شناخته شده توسط برنامه می باشد، مقایسه شده تا آهنگ مورد نظر شناسایی شود.
وجود نویز، سرعت پخش قطعه و ... از جمله مشکلاتی است که در روند نمایه سازی ورودی کاربر وجود دارد. همچنین در مرحله ی نمایه سازی صوتی از آهنگ ها و به دنبال آن ایجاد پایگاه داده ، با مشکل حجم زیاد نمونه در آهنگ ها مواجه هستیم.
به طور کلی ساختار یک سیستم نمایه سازی صوتی به صورت زیر می باشد:
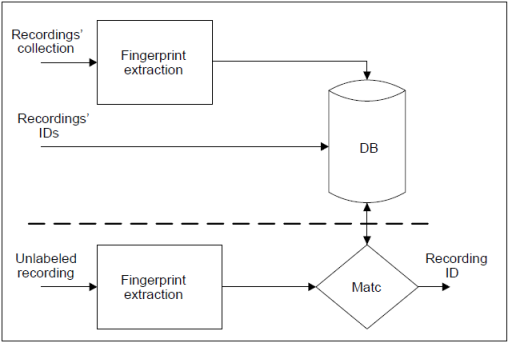
حل مساله نمایه سازی صوتی شامل دو قسمت اصلی می باشد : 1- استخراج نمایه ها 2- الگوریتم تطبیق نمایه ها
در بخش استخراج نمایه ها با توجه به اینکه نمونه های ما سیگنال ها می باشد می توانیم با تبدیل سریع فوریه بر روی پنجره های کوچک زمانی در نمونه های آهنگ، طیف نگاره (spectrograms) آهنگ مورد نظر را بدست آوریم. سپس در طیف نگاره نقاط peak ( زوج مرتبی از زمان و فرکانس که دارای فراوانی بیشتر در یک همسایگی است ) را مشخص می کنیم و در نهایت با نگاه کردن به نقاطpeak طیف نگاره و ترکیب فرکانس نقاط همراه با تفاوت زمان بین آنها، می توانیم یک تابع hash تعریف کنیم که یک نمایه منحصر به فرد برای آهنگ ایجاد کند.
در این قسمت پایگاه داده ی ما دارای 2 جدول، یکی برای آهنگ و اطلاعات مربوط به آن و دیگری برای نمایه ها.
در جدول مربوط به نمایه ها علاوه بر hash و id مربوط به آهنگ یک offset هم وجود دارد که به پنجره ی زمانی طیف نگاره مربوط است و در بخش بعدی ( تطبیق نمایه ها ) مورد استفاده قرار می گیرد.
در بخش دوم از تکنیک های بازیابی اطلاعات برای تطبیق نمایه ها و جستجوی آهنگ مورد نظر استفاده می شود و همچنین می توان در این بخش از offset نمایه ها کمک گرفت به این صورت که تفاوت بین offset نمایه های موجود در پایگاه داده و قطعه آهنگ ورودی میتواند معیاری برای ارزیابی و یافتن آهنگ مورد نظر باشد.
# کارهای مرتبط
مفهوم نمایه سازی سیستم ها بیش از 100 سال است که وجود دارد. نمایه سازی صوتی در سال های اخیر بسیار مورد توجه قرار گرفته است. برنامه هایی از جمله soundhound و shazam به گونه ای طراحی شده که می تواند بر روی گوشی موبایل اجرا شود و در مکان های عمومی مانند ماشین برای تشخیص آهنگ مورد استفاده قرار بگیرد. شرکت دیگری با نام gracenote نیز برنامه ای مشابه در این زمینه ارائه داده که از کاربرد های آن در تشخیص صدا و طراحی سیستم ارتباطی داخل ماشین (Ford’s SYNC in-car communications system ) می باشد.
وجود مشکلاتی از قبیل وجود نویز، سرعت پخش متفاوت و ... باعث شده تا تلاش برای بهبود الگوریتم های موجود ادامه یابد تا با وجود این مشکلات، همچنان بهترین پاسخ در کمترین زمان به کاربر داده شود و به در راستای همین هدف طی سال های اخیر مقاله هایی در رابطه بهبود الگوریتم های موجود در این زمینه ارائه شده است.
ساده ترین راه که به ذهن هر فردی میرسد مقایسه مستقیم شکل موج دیجیتال شده می باشد. برای پیاده سازی این روش از متد hash ( مانند MD5 یا CRC ) برای بدست آوردن یک نمونه از یک فایل باینری استفاده می شود و در نهایت به جای مقایسه کل یک فایل تنها نمونه به دست آمده را ( مقادیر hash ) مقایسه می کنیم. با توجه به اینکه این hash ها با اضافه شدن تنها یک بیت می توانند به کلی تغییر کنند این روش بر بیت های فایل تکیه دارد و نمی تواند روش خوبی باشد. این مشکل باعث شد تا به جای استفاده از تکنیک فوق، روش هایی که با عنوان content-based identification مطرح هستند به کار گرفته شوند.
بساختار کلی یک Content-based Audio Identification به صورت زیر است :
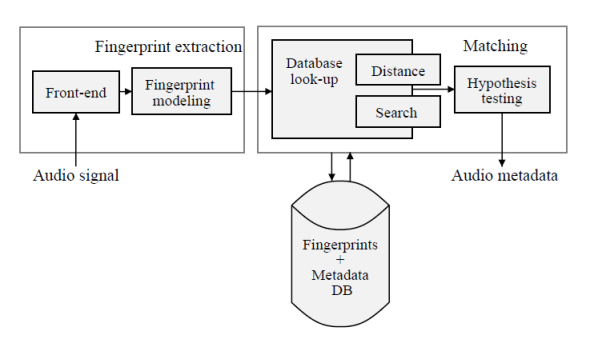
با توجه به شکل بالا قسمت بدست آوردن نمایه ها شامل دو بخش Front-end و Fingerprint modeling است.
در بخش Front-end یک سیگنال صوتی به مجموعه ای از ویژگی های مرتبط با سیگنال تبدیل می شودو مجموعه ای از رویه ها جهت کاهش اندازه، بدست آوردن پارامترهای ادراکی، قویتر کردن سیگنال اصلی (مانند حذف نویز) و... بر روی سیگنال اعمال می شوند.
شکل زیر روند کلی این بخش را نشان داده و کنار هر رویه انواع الگوریتم هایی که برای پیاده سازی آن موجود هستند را بیان کرده است :
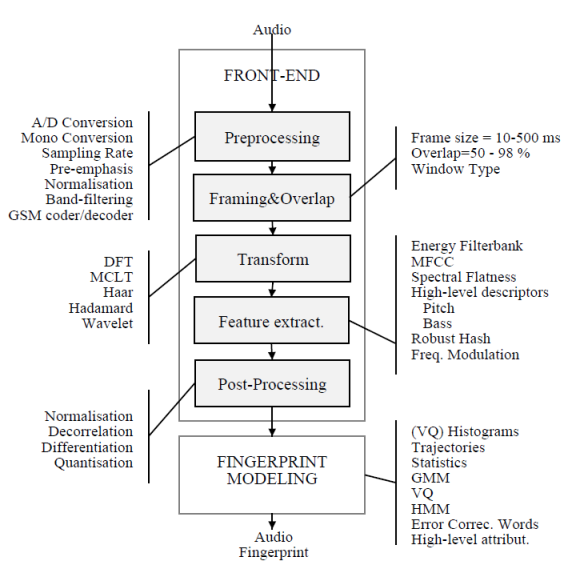
در ایجا به طور مختصر به توضیح هر کدام از رویه های ذکر شده در شکل فوق می پردازیم:
**مرحله Preprocessing :** در ابتدا سیگنال در صورت نیاز دیجیتال شده و به یک فرمت عمومی تبدیل می شوند. گاهی اوقات یک صوت برای شبیه سازی یک کانال نیز پیش پردازش می شود.
**مرحله Framing & Overlap :** سیگنال به فریم هایی با سایز قابل تغییر تقسیم می شوند و برای اطمینان بیشتر فریم های متوالی همپوشانی نیز دارند. ( نرخ تعداد فریم در هر ثانیه و درصد همپوشانی در پیچیدگی سیستم تاثیر گذار است )
**مرحله Transform :** در این مرحله در صورت انتخاب تبدیل مناسب، میزان افزونگی (داده هایی زائد مانند نویز) کاهش میابد. تبدیلی به کار برده شده در این بخش معمولاً تبدیل فوریه است.(از سایر تبدیل ها مانند DCT نیز می توان استفاده کرد)
**مرحله Feature Extract :** در این مرحله نیز سعی بر کاهش سایز و نویز می باشد و برای این مسئله الگوریتم های زیادی مطرح شده است. برای مثال الگوریتم MFCC ( ابتدا log و سپس DCT ) ، الگوریتم SFM ( برآورد صدا یا نویز بودن برای هر بخش از یک طیف )
**مرحله Post-Processing :** برای بهتر مشخص شدن تغییرات زمانی می توان مشتقات بالاتر بر حسب زمان را به سیگنال مورد نظر اضافه کرد. همچنین با کوانتیزه کردن می توان میتوان سیگنال را در برابر تحریف مقاوم کرد.
در نهایت هم توالی از بردارهای ویژگی توسط Fingerprint Modeling دریافت شده و با توجه به نوع ایندکس کردن و روش هایی که می خواهیم در بازیابی اطلاعات استفاده کنیم یک مدل (بردار) را جهت ذخیره سازی در ساختمان داده انتخاب کرده وپس از انجام محاسباتی بر روی بردار های ورودی به این قسمت، سیگنال مورد نظر را به صورت یک مدل (معمولا برداری است که عناصر آن با توجه به روش مورد استفاده تعیین می شود) ذخیره می کنیم.
پس از بدست آمدن نمایه ها نوبت به تطبیق می رسد. (Matching) برای یافتن فاصله بین بردار های ویژگی در صورتی که کوانتیزه باشند می توان از الگوریتم Manhattan distance استفاده کرد همچنین برای بردار ها الگوریتم Nearest Neighbor را نیز می توان به کار برد. (با توجه به مدلی که نمایه ها ذخیره شده اند الگوریتم های دیگری نیز جهت تعیین فاصله وجود دارند)
پس از مقایسه و درادن امتیاز، در آخرین مرحله که Hypothesis Testing نام دارد باید مرزی تعیین شود که اگر امتیاز بدست آمده از آن مرز بیشتر بود پاسخ قابل قبول است. تعیین این مرز آسان نیست چرا که به مدل نمایه ها ، شباهت نمایه های داخل ساختمان داده، اندازه ساختمان داده و... بستگی دارد.
در آخر باید گفت مراحل گفته شده در بالا ممکن است همگی در کنار هم پیاده سازی نشود و مهمترین نکته این است که در زمان ساخت ساختمان داده و ایندکس کردن طوری این کار را انجام دهیم که در هنگام جستجو که به صورت آنلاین اجرا میشود، در کمترین زمان به بهترین جواب برسیم.
#پیاده سازی
[Audio-Fingerprinting](https://github.com/sa-matiny/Audio-Fingerprinting)
# آزمایشها[Audio-Fingerprinting](https://github.com/sa-matiny/Audio-Fingerprinting)
در پیاده سازی این برنامه 6 فایل اصلی وجود دارد که در ادامه به طور مختصر به بیان عمل آنها می پردازیم:
+ **database.py**
کلاس Database در این فایل تعریف شده که برای کار با پایگاه داده (استخراج یا افزودن اطلاعات به آن) می باشد.(تنها شمای کلی کلاس در این فایل موجود است)
+ **database_sql.py**
کلیه توابع تعریف شده در کلاس Database که شمای آن در database.py موجود بود در این قسمت پیاده سازی شده است. پایگاه داده مورد استفاده MySql می باشد. همچنین در انتهای این فایل کلاس cruser جهت اتصال به پایگاه داده تعریف شده است.
+ **decoder.py**
این بخش کار با فایل و استخراج اطلاعات از فایل های صوتی را بر عهده دارد. تابع ()find_files فایل های صوتی موجود در فولدری که آهنگ ها در آن قرار دارند را می دهد. تابع ()read با استفاده از کتابخانه ی pydub اطلاعات موجود در فایل صوتی را استخراج کرده و به صورت آرایه ای از channel ها برمیگرداند.
+ **fingerprint.py**
وظیفه ی اصلی ساخت نمایه ها به این قسمت مربوط است. 3 کتابخانه ی اصلی استفاده شده در این بخش matplotlib ، numpy و scipy جهت ساخت spectoram برای هر channel از یک فایل صوتی و پردازش آن است. تابع ()fingerprint با اعمال تبدیل فوریه بر روی پنجره های کوچک زمانی تعریف شده بر روی channel ها، نمودار spectrogram را می دهد که پس از اعمال log بر روی نمودار و یافتن نقاط ماکزیمم محلی (نقاط پیک)، این نقاط را برای ساختن hash ارسال می کند.
تابع ()get_2D_peaks با اعمال فیلتر ماکسیمم نقاط پیک را تعیین می کند و تابع ()generate_hashes با دریافت نقاط پیک و یافتن فرکانس ها و زمان ها، با استفاده از کتابخانه hashlib ساختن hash ها را انجام می دهد.
+ **recognize.py**
وظیفه ی این قسمت دریافت آهنگ ورودی است که برای این منظور کلاس MicrophoneRecognizer طراحی شده است. همچنین کلاس BaseRecognizer یک کلاس پایه است که تابع ()recognize_ آن، با استفاده از تابع های ()find_matches و ()align_matches اقدام به جستجو در پایگاه داده و یافتن جواب می کند.
+ **__init__.py**
فایل اصلی که مدیریت کلیه فایل ها را بر عهده دارد. در این فایل کلاس FingerMusics وجود دارد که برای هر شئ از این کلاس اقدام به بدست آوردن اطلاعات موجود در پایگاه داده ها می کند. دو تابع ()fingerprint_directory و ()fingerprint_file به ترتیب برای ایجاد نمایه ها از آهنگ های موجود در یک فولدر و یا ایجاد نمایه تنها برای یک آهنگ ورودی و در نهایت ثبت آنها در پایگاه داده می باشد. هر دو این توابع برای آهنگی که در پایگاه داده موجود نباشد تابع ()_fingerprint_worker را فراخوانی می کنند که این تابع پس از بدست آوردن channel های هر آهنگ (با استفاده از تابع ()read در decoder.py) و فراخوانی تابع ()fingerprint از فایل fingerprint.py ، نمایه ها را بدست می آورد.
تابع ()find_matches از کلاس FingerMusics پس از نمایه سازی آهنگ ورودی، hash های مشابه را از پایگاه داده استخراج میکند. و در آخر تابع align_matches، hash های مشابه یافت شده را دسته بندی می کند و هر آهنگی که تعداد بیشتری hash از آن در hash های مشابه وجود داشته باشد امتیاز بیشتری میگیرد (این امتیاز در خروجی به عنوان confidence یعنی درجه اطمینان نمایش داده می شود) و هر آهنگی که امتیاز بیشتری داشت به عنوان خروجی انتخاب می شود.
# آزمایشها
در این پروژه تمرکز بیشتر به بخش ایجاد نمایه ها می باشد به گونه ای که حجم نمایه های تولید شده، بیش از حد زیاد نباشد و همچنین به گونه ای این نمایه ها تعیین شوند که هنگام جستجو بتوان بهترین نتیجه را نمایش داد.
ایجاد نمایه ها به صورت offline انجام می شود بنابراین زیاد بودن زمان تولید نمایه ها تا حدی قابل چشم پوشی است همچنین در بخش جستجو که به صورت online انجام می شود گرچه پارامتر زمان با زیاد شدن تعداد آهنگ ها اهمیت زیادی پیدا می کند و استفاده از تکنیک های بازیابی اطلاعات می تواند کمک زیادی کند اما در این پروژه بیشتر تاکید بر صحیح بودن جواب بازگشتی در شرایط مختلف همچون وجود نویز و یا کوتاه بودن زمان پخش آهنگ است.
**آزمایش 1:**
برای بررسی عملکرد کد، 40 آهنگ را به عنوان ورودی به آن داده و برنامه در زمان 3800 ثانیه نمایه سازی را انجام داده و نتایج را در پایگاه داده ذخیره می کند.
| حجم آهنگ ها (mp3) | حجم نمایه ها در پایگاه داده |
|:-----------:|:-------------:|
| 186.9MG | 238MG |
برای بررسی اینکه آهنگ ورودی کاربر حداقل چند ثانیه باشد تا برنامه جواب درست را بدهد تعدادی آزمایش انجام داده و نتایج آن مطابق جدول زیر است: (البته باید در نظر داشت علاوه بر مدت پخش آهنگ ورودی، محتوای آن نیز تاثیر دارد برای مثال ورودی ثانیه 4 تا 6 آهنگ و یا ثانیه 10 تا 12 باشد)
| مدت پخش (ثانیه) | تعداد آزمایش ها | تعداد جواب های صحیح | دقت برنامه (درصد) |
|:-----------:|:-------------:|:--------:|---------:|
|2|20|12|%60|
|3|20|18|%90|
|4|20|19|%95|
|5|20|20|%100|
|6|20|20|%100|
با بیشتر کردن تعداد آزمایش ها در جدول بالا قطعاً به نتایج بهتری می رسیم. با این وجود از جدول فوق می توان این موضوع را دریافت که زمان5 یا 6 ثانیه زمان مناسبی است و برنامه جواب قابل قبولی می دهد. پس از این نوبت به بررسی تاثیر نویز روی جواب است که برای این کار همزمان با پخش آهنگ ورودی، یک فایل صوتی دیگر را پخش می کنیم و volume آن را (صدای نویز) را هربار افزایش می دهیم با این کار مقدار کمیت بازگشتی confidence که میزان اطمینان برنامه از درست بودن جواب را نشان می دهد کاهش می یابد. این برنامه حتی هنگام پخش 2 آهنگ متفاوت که هر دو در پایگاه داده موجود هستند برای اختلاف volume تقریبا 15 جواب درست را در 95% مواقع می دهد که نشان از میزان مطلوبیت آن است.
این نکته را نیز باید در نظر داشت که کلیه آزمایش ها هم با وسایل با کیفیت پخش نسبتاً خوب انجام شده و هم کیفیت خود آهنگ ها مطلوب بوده است که تغییر کیفیت این موارد می تواند بر روی جواب تاثیر داشته باشد.
# کارهای آینده
# مراجع
+ Wang, Avery. "An Industrial Strength Audio Search Algorithm." ISMIR. 2003.
+ A Review of Algorithms for Audio Fingerprinting (P. Cano et al. In International Workshop on Multimedia Signal Processing, US Virgin Islands, December 2002)
+ Hatch, Wes., "A Quick Review of Audio Fingerprinting." March 2003.
+ HA Van Nieuwenhuizen, WC Venter, MJ Grobler. "The Study and Implementation of Shazam's Audio Fingerprinting Algorithm for Advertisement Identification."2012.
+ HA van Nieuwenhuizen, WC Venter, LMJ Grobler. “Comparison of Algorithms for Audio Fingerprinting.”2010
+ Pavel Golik, Boulos Harb, Ananya Misra, Michael Riley, Alex Rudnick, Eugene Weinstein. "MOBILE MUSIC MODELING, ANALYSIS AND RECOGNITION".2012
# پیوندهای مفید
+ [Audio Fingerprinting with Python and Numpy](http://willdrevo.com/fingerprinting-and-audio-recognition-with-python.html)
+ [Echoprint]( http://echoprint.me/how