شناسایی حملات در شبکههای کامپیوتری از جنبهٔ اطّلاعات مورد استفاده در مرحلهٔ یادگیری، به دو دستهٔ تشخیص نفوذ و تشخیص ناهنجاری تقسیم می شود.
در تشخیص ناهنجاری تنها اطّلاعات مربوط به ترافیک معمول شبکه مورد استفاده قرار میگیرند. برای تشخیص ناهنجاری رویکردها و روشهای متنوّعی ارائه شدهاند که در این پژوهش باید مروری اجمالی بر آنها صورت پذیرد. همچنین یکی از روشها باید برای تشخیص ناهنجاری در شبکه پیادهسازی شود.
۱. مقدمه
با رشد روزافزون استفاده از شبکه های کامپیوتری ،امنیت این شبکه ها اهمیت بسیاری پیدا میکند. یکی از جنبه های مهم امنیت، تشخیص ناهنجاری های احتمالی و دفع ناهنجاری های در حال رخ دادن است .یکی از ابتدائی ترین نوع تشخیص ناهنجاری ، دادن اطلاعات مفید به مدیر شبکه درباره ی ناهجاری است.
روش های تشخیص ناهنجاری به سه روش تقسیم می شود:
1) Anomaly Detection
2) Misuse Detection
3) Hybrid Anomaly and Misuse Detection
در روش اول که موضوع اصلی این پروژه است بیش تر تکنیک ها از مدل ترافیک شبکه برای تشخیص ناهنجاری استفاده می کنند.تکنیک های مختلفی در این روش مورد استفاده قرار می گیرد:
1) Statistical Models
1.1)NIDES/STAT
1.2)Haystack
2)Machine Learning and Data Mining Techniques
2.1)Time-Based Inductive Machine
2.2)Instance Based Learning
2.3)Neural Network
2.4)Audit Data Analysis and Mining
3)Computer Immunological Approach
4)Specification-Based Methods
روش های اجرا و توسعه ی IDS ها بر دو شیوه استوار است ،که در روش اول(host-based) هر سیستم وظیفه حفاظت خود را برعهده دارد در حالی که در روش دوم یک یا چند سیستم توزیع شده عهده دار تشخیص ناهنجاری و نفوذ می شوند و وظیفه کنترل کردن و مانیتورینگ فایروال ها و Router ها و Switch ها در
شبکه و پاسخ مناسب به تهدید را بر عهده دارند .
۲. کارهای مرتبط
در این پروژه برآنیم با به کارگیری بعضی از الگوریتم های Machine Learning سیستم را قادر به تشخیص رفتار ناهجارانه بر اساس رفتار طبیعی تعریف شده در سیستم کنیم:
1) OCNM یکی از الگورتم هاست که با پیش بینی MVS(minimum volume sets) approach به تشخیص ناهنجاری می پردازد. این الگوریتم با ساختن یک تایع تصمیم گیری باینری تشخیص می دهد که وضعیت فعلی نرمال است یا نه.
2) KOAD با اندازه گیری های چند متغیره به فضائی می رسد که مجموعه ای از ویژگی های نرمال را برای ما دسته بندی می کند.که این الگوریتم با استفاده از واژه نامه ای از عناصر تقریبا مستقل خطی به ویژگی نرمال می رسد.
همچنین با بهره گیری از معماری های مانیتورینگ به روش های تشخیض کارائی و دقت می بخشیم:
1)Distributed Approach که در بازه های زمانی مشخص بر اساس اندازه گیری های محلی هر node تصمیم می گیرد که ناهنجاری وجود دارد یا خیر و نتیجه ای به صورت باینری برای واحد اصلی ارسال می کند.
2)Centralized Approach در این روش برخلاف روش قبل تمام اندازه گیری ها به واحد مرکزی ارسال می شود و براساس روش های تشخیص به وضعیت فعلی پاسخ داده می شود.
در یکی از روش های مبتنی بر KOAD به نام maximum entropy estimation بر اساس متد behavior-based با تقسیم بندی پکت ها بر اساس چند متغیر مثل پروتکل و پورت مقصد به چند کلاس شروع می شود و بیشینه آنتروپی پایه توزیعی هر کلاس با یادگیری از یک مدل تراکمی با استفاده از مجموعه ای از داده های پرداخته شده و از قبل علامت گذاری شده تعیین می شود و توزیع تجربی پکت های کلاس های در حال مشاهده با توزیع های پایه از نقطه نظر آنتروپی مربوطه مقایسه می شود و در صورت تفاوت می توان نتیجه گرفت که نشانه هائی از ناهنجاری وجود دارد.
یکی از مرایای این روش این است که مدیر شبکه می تواند بر اساس دسته بندی های مختلفی که با استفاده از داده های پکت ها است شبکه را تحت نظر بگیرد و ناهنجاری به محض افزایش آنتروپی مربوطه و رسیدن به یک سطح مشخص شناسائی می شود و اطلاعات مربوط به نوع ناهنجاری را نگه داری می کند.
۳. آزمایشها
پیاده سازی روش Maximum Entropy Estimation به دو قسمت اصلی تقسیم می شود ،قسمت اول یافتن توزیع پایه و قسمت دوم مقایسه ترافیک شبکه و توزیع پایه و تشخیص ناهنجاری ها می باشد.در فاز اول پکت بر اساس اطلاعات پروتکل و پورت مقصد به کلاس های چند بعدی تقسیم می شود و این کلاس ها به عنوان دامنه های فضای احتمالی استفاده می شوند و آنتروپی پایه توزیعی هر کلاس با یادگیری از یک مدل تراکمی با استفاده از مجموعه ای از داده های پرداخته شده و پیش بینی آنتروپی بیشینه مشخص می شود.داده های پرداخته مجموعه داده های از پیش علامت گذاری شده با نشانه های ناهنجاری که توسط اتسان گذاشته شده است . در فاز دوم ترافیک مشاهده شده شبکه به عنوان ورودی گرفته شده و آنتروپی مربوط به کلاس پکت های مشاهده شده با توجه به پایه توزیع محاسبه شده و پکت هائی که به طور قابل توجه به آنتروپی نزدیک هستند نگه داری می شوند و اگر به رفتار ذکر شده ادامه دهند به عنوان ناهنجاری شناخته می شوند و پکت های مشخص کننده ساخته و ارسال می شوند که حاوی اطلاعات پورت و پروتکل ناهنجاری هستند.
۳.۱. دسته بندی و کلاسه کردن پکت ها
تاکید اصلی دسته بندی بر ناهنجاری های TCP و UDP است و کلاس بر اساس دو متغیر یعنی اطلاعات پروتکل و پورت مقصد که در هدر پکت ها قرار دارند به کلاس های مختلفی تقسیم بندی می شوند و این کلاس ها دامنه فضای احتمال در این روش هستند.
در بعد اول پکت ها بر اساس اطلاعات مربوط به پروتکل به چهر کلاس تقسیم می شوند که مبتنی بر TCP یا UDP بودن پکت ها جدا می شوند و دوم بر اساس اینکه پکت ها SYN و RST هستند تقسیم می شوند.
در بعد دوم بر اساس شماره پورت مقصد به 587 کلاس تقسیم می شوند چون معمولا پورت ها مشخص کننده سرویسی خاص روی دستگاه مقصد هستند .و براساس قدرت و نفوذ پورت ها در فضای اینترنت به سه دسته تقسیم می شوند:
1) Well known ports که رنج آن از 0 تا 1023 می باشد.
2) Registered ports که از 1024 تا 49151 است
3) Dynamic or/and Private ports که از 49152 تا 65535 است
پکت هائی که شماره پورتشان در دسته اول قرار دارد به کلاس هائی که هرکدام 10 عضو دارند تقسیم می شوند ولی پکت های پرت 80 که اکثریت ترافیک شبکه را شامل می شوند در یک کلاس تک عضوی قرار می گیرند.بر این اساس پکت های دسته اول به 104 کلاس تقسیم می شوند . در مورد دسته دوم 482 کلاس دیگر که هرکدام 100 پورت دارند به استثای آخرین کلاس که 28 پورت آخر این دسته را در خود جای داده است.در دسته سوم هم خود یک کلاس شامل همه پورت های این دسته است پس در این بعد در مجموع 1 + 104 + 482 = 587 کلاس وجود دارد.در مجموع کلاس های دو بعدی شامل 4*587 = 2348 کلاس هستند. توزیع پکت های مختلف بر اساس ترافیک امن و خوش خیم و کلاس بندی های بالا پیش بینی شده و توزیع پایه ای برای شناسائی ناهنجاری ها استفاده خواهد شد .
۳.۲. پیش بینی آنروپی بیشینه برای توزیع کلاس های پکت
پیش بینی آنروپی بیشینه چارچوبی برای بدست آوردن مدل توزیعی احتمالی پارامتری از داده های پرورش داده شده و مجموعه ای از محدودیت های این مدل.پیش بینی آنروپی بیشینه یک مدل با توزیع یکسان در میان تمام توزیع هاست که محدودیت ها را اقناع می کند . یک متریک ریاضی یکنواختی توزیع P آنتروپی آن است:
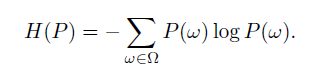
در این توزیع دامنه کلاس های تعریف شده در قسمت قبل است و مجموعه S شامل n بسته متوالی به عنوان داده پرورش یافته گرفته می شود و توزیع تجربی روی دامنه با داده های پرورش یافته برابر است با:

که تابع صورت کسر به ازای X درست مقدار یک و درغیر این صورت صفر می گیرد.
فرض می کنیم که مجموعه ای از توابع مشخصه ای fi می گیریم که هر یک از این توابع مقادیر 0 یا 1 می گیرند و با استفاده از پیش بینی آنروپی بیشینه به دنبال یک مدل تراکمی مثل P که رابطه زیر را برای تمام توابع مشخصه ای اقناع می کند و بیشینه آنتروپی را داشته باشد:
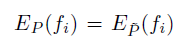
همچنین ثابت می شود که تحت چنین شرایط و محدودیت هایی پیش بینی آنروپی بیشینه یکتا است و شبیه پیش بینی احتمالی بیشینه با استفاده از تعمیم توزیع گبیس برای همه fi ها فرم ورودخطی زیر را دارد:
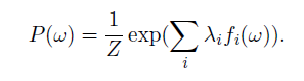
که ضریب توابع مشخصه ای در رابطه فوق وزن تابع است که عضو مجموعه ای از پارامترهای توابع مشخصه ای است .همچنین Z ثابت نرمال کردن است ممجموع فوق روی دامنه کلاسها بیش از 1 نشود.تفاوت دو توزیع P و Q معمولا توسط آنتروپی مربوطه یا Kullback-Leibler (KL) divergence تشخیص داده می شود:
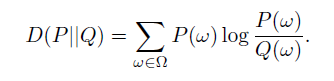
درجهت افزایش کارائی ،توابع مشخصه ای برا ی نشان دادن مهمترین خواص داده در مدل ورود-خطی گفته شده انتخاب می شوند و برعکس مدل ورود-خطی توزیع تجربی با کمترین توابع مشخصه ای و پارامترها را به نمایش در می آورد.
تابع پیش بینی آنروپی بیشینه شامل دو قسمت عمده است:یک.انتخاب مشخصه ها برای وجود و عدم وجود به انتخاب توابع آنها ،دو.پیش بینی پارامترها برای تعیین وزن توابع مشخصه ای.قسمت اول به انتخاب مهمترین خواص مورد نیاز برای مدل ورود-خطی می پردازد و در قسمت دوم پیش بینی پارامترها برای وزن دهی مناسب به هریک توابع مشخصه ای است.این دو قسمت به طور تکراری انجام می شوند تا بالاخره به یک مدل نهائی دست یابیم.در ادامه هریک از این دو قسمت را باز خاهیم کرد.
۳.۲.۱. انتخاب خواص برای ایجاد توابع مشخصه ای
مرحله انتخاب خواص یک الگوریتم حریصانه برای انتخاب بهترین تابع مشخصه ای که باعث کمینه شدن اختلاف مدل توزیعی و توزیع تجربی از میان یک مجموعه تابع کاندیدا است ،می باشد،فرض کنید دامنه تمام کلاس های از قبل تعریف شده باشد و رابطه دوم توزیع تجربی روی دامنه مذکور باشد و F مجموعه ی توابع مشخصه ای کاندیدا برای انتخاب باشد و مدل توزیعی ابتدائی روی دامنه تعریف شده برابر تساوی زیر باشد:
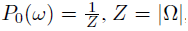
که توزیع مذکور یک توزیع همگن می باشد،حال Pi یک توزیع با انتخاب i تابع مشخصه ای است:
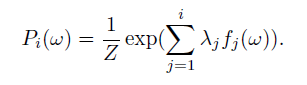
و می خواهیم 1+i امین تابع را طوری انتخاب کنیم که g یک عضو F باشد و دارای وزنی مشخص باشد - لاندا ضریب وزنی g می باشد - و داریم:
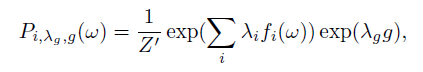
و g با بیش ترین gain به عنوان 1+i امین تابع انتخاب می شود که بیش ترین کاهش K-L divergence بدست آمده به وسیله g نتیجه داده می شود:
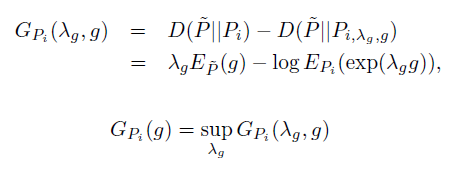
۳.۳. پیش بینی پارامتر ها برای وزن دهی به توابع
بعد از انتخاب تابع مشخصه ای جدید وزن تابع های موجود بروز می شود و یکسری داده ورودی و توابع انتخاب شده حالا زمان نتخاب پارامترهای وزن دهی به توابع است تا پیش بینی آنروپی بیشینه از روی پارامترهای تخصیص داده شده به توابع مشخصه ای که K-L divergence بین توزیع تجربی و مدل توزیعی را کمینه می کند:

۴. ساخت یک مدل و شناسائی ناهنجاری
مطابق شکل دو مرحله تا جائی تکرار می شود که به یک نقطه مطلوب ملاقات شود:

و آنتروپی مربوطه تفاوت توزیع پایه و توزیع کلاسهای مختلف در ترافیک عبوری شبکه را مشخص می کند که در صورت تفاوت زیاد این دو توزیع نشان می دهد که کلاس هائی که در داده های آزمایشی به ندرت با این حجم وجود داشته است به طور قابل توجهی افزایش می یابد به عبارت دیگر حضور یک ناهنجاری در شبکه مشاهده شده است. زمان را به تکه های با اندازه مساوی تقسیم می کنیم و برای کلاس های مختلف اختلاف بیش از یک مرز مشخص اگر بیش تر از یک تعداد مشخص اتفاق بیافتد یک هشدار به سیستم در مورد بروز ناهنجاری داده می شود تا پورت و پروتکل به دقت بیش تری مورد مشاهده توسط سیستم قرار گیرد.
۵. نتایج یک آزمایش
یک آزمایش در UMASS Internet gateway router که شامل هفت ساعت مشاهده داده های عبوری از ساعت 9:30 تا 10:30 به طول مدت یک هفته انجام شده است که در آغاز پکت ها توسط عامل انسانی نشانه گذاری شده بودند و به طور خاص یک گروه از جریان های با حجم زیاد و پورت های پرکاربرد بیشتر مورد توجه قرار گرفته است و سپس به دنبال بررسی روش برای یافتن ناهنجاری پرداخته شده است.و داده های یک روز جمع آوری شده و بااستفاده از آنها یعنی تحویل داده ها به الگوریتم و محاسبه مدل توزیعی و ساخت مدل با توجه با دیورژانس 0.01 که اختلاف مدل توزیعی و توزیع تجربی است به این نتیجه رسیده شد که الگوریتم 362 تابع مشخصه ای را به عضویت دامنه در می آورد که نسبت به تعداد کلی کلاسها عدد قابل تاملی است.
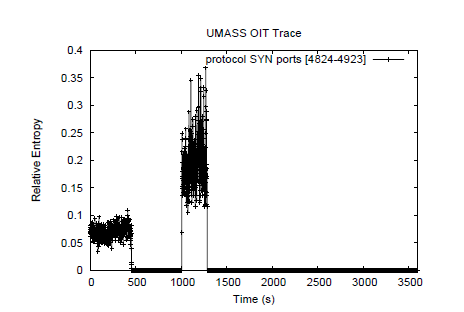
همچنین در آزمایش فوق با بررسی پورت اسکن در تاریخ مشخص با تکه های زمانی 1 ثانیه در بازه های 60 ثانیه و اختلاف مجاز 0.01 و تعداد 30 بار مورد بررسی قرار گرفته که یک دستگاه خارج شبکه UMASS در روی پورت 4899 به دستگاه های مختلفی در UMASS پکت SYN ارسال کرده است که تعداد این پکت ها بسیار زیاد است و یک هاست دیگر در زمانی دیگر روی همین پورت پکت های مشابهی را به هاست های مختلفی روی شبکه داخلی UMASS ارسال کرده است که باعث افزایش قابل توجه آنتروپی کلاس 4824 تا 4923 شده است که نمایان گر یک ناهنجاری از نوع پرت اسکنینگ روی شبکه است :
۶. کارهای آینده
پیاده سازی این مدل یا هرمدل مشابه یعنی بکارگیری روش های machine learning در شبکه نیازمند دسترسی به اطلاعات عبوری و داده کاوی است که به نظر کاری زمان گیر و فرسایشی برای یک گروه است چه برسد به یک تحقیق فردی!!!
اما به هر حال توانائی محقق در این پروژه یافتن روش های پیاده سازی و حدس اتفاقات است که سعی بر این شده که روشی عملی و قابل فهم بررسی و توضیح داده شود
۷. مراجع
Kabiri, Peyman, and Ali A. Ghorbani. "Research on Intrusion Detection and Response: A Survey." IJ Network Security 1.2 (2005): 84-102
Mahbod Tavallaee, Ebrahim Bagheri, Wei Lu, and Ali A. Ghorbani A Detailed Analysis of the KDD CUP 99 Data Set.
Daniel E. O'Leary: Intrusion-Detection Systems
Masayoshi Mizutani ,Keiji Takeda ,Jun Murai :Behavior Rule based Intrusion Detection
James Cannady, Jay Harrell :A Comparative Analysis of Current Intrusion Detection Technologies
Tarem Ahmed, Boris Oreshkin and Mark Coates: Machine Learning Approaches to Network Anomaly Detection