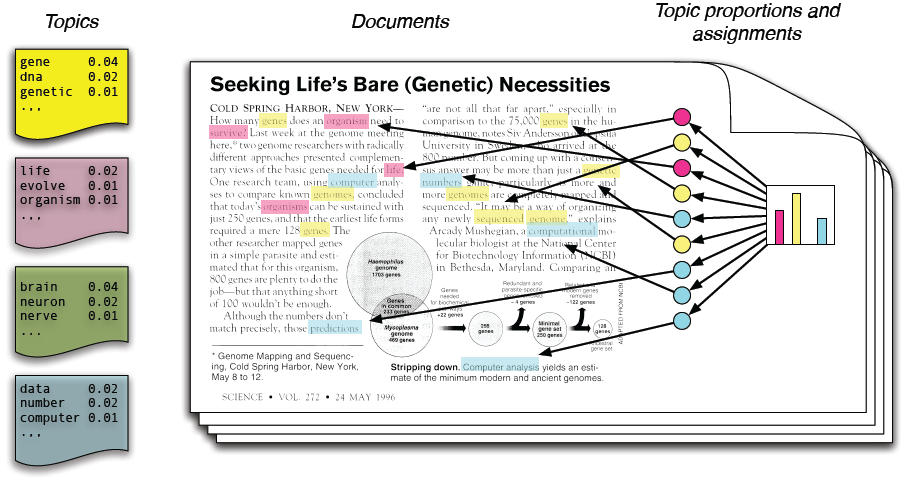
در مدلسازی موضوعی، فرض میکنیم که مجموعه متون ورودی از روی چند موضوع نامعلوم ساخته شدهاند و باید این موضوعات را پیدا کنیم. هر موضوع یک توزیع احتمال نامعلوم روی واژهها است و هر متن توزیع احتمالی روی موضوعها.
این پروژه توسط یک بنگاه تجاری تعریف شده است.
۱. مقدمه
با افزایش حجم اسناد و اطلاعات و از طرفی نمایش آنها به صورت دیجیتال در قالب اخبار، وبلاگها، مقالات علمی، کتابهای الکترونیکی، عکس، صوت و تصویر و شبکههای اجتماعی پیدا کردن مطالبی که به دنبال آن هستیم مشکل میشود. ازاینرو نیاز به ابزار محاسباتی جدیدی برای سازماندهی، جستجو و درک این حجم عظیم اطلاعات هستیم.
تابهحال کار ما روی اسناد آنلاین به دو طریق انجام میگرفت: یکی جستجو و دیگری پیوندها. کلمهی کلیدی را در یک موتور جستجو وارد و مجموعهای از اسناد مرتبط با آن را مشاهده میکردیم. در این اسناد اگر پیوند مفیدی به اسناد دیگر میدیدیم با کلیک روی آن به مجموعه اسناد دیگر دسترسی پیدا میکردیم. این دو روشهای قدرتمندی برای کار کردن با آرشیوهای الکترونیکی بودند اما مشکلاتی نیز وجود داشت.
روش جستجویی که در بالا شرح داده شد مبتنی بر ظاهر یک کلمه بود و هنگام انجام عمل جستجو تمامی اسنادی که حاوی آن کلمهی کلیدی هستند به عنوان نتیجه برگردانده میشوند. این اسناد اگرچه دربردارندهی آن کلمه هستند ولی ممکن است متعلق به موضوعات مختلفی باشند درحالیکه ما احتمالاً فقط به دنبال یک موضوع خاص هستیم. برای اینکه جستجوی دقیقتری داشته باشیم بایستی ابتدا موضوع مورد علاقهی خود را در بین اسناد جستجو کرده و سپس جستجوی خود را محدود به این اسناد جدید کنیم و میتوانیم در این اسناد جدید دوباره موضوع خود را محدودتر کنیم و همینطور پیش برویم تا جایی که به طور دقیق به اسناد مورد نیاز خود دسترسی پیدا کنیم.
به عنوان مثال فرض کنیم میخواهیم در آرشیو یک روزنامه به دنبال یک موضوع باشیم. موضوعات در دستههای سیاسی، اقتصادی، فرهنگی، ورزشی و حوادث قرار دارند. مثلاً میخواهیم در موضوع سیاسی جستجو کنیم. داخل این موضوع زیرموضوعهای سیاست داخلی و خارجی وجود دارد که یکی را انتخاب میکنیم و همینطور پیش میرویم تا دقیقاً به اسناد مورد نیازمان دسترسی پیدا کنیم.
البته اینگونه کار کردن با اسناد بهسادگی امکانپذیر نیست؛ زیرا هر چه حجم اسناد و اطلاعات افزایش مییابد دستهبندی فوق برای انسان کار مشکل و یا غیرممکنی میشود؛ بنابراین نیاز به تکنیکهای یادگیری ماشین داریم تا بتوانیم از طریق کامپیوتر دستهبندی فوق را انجام دهیم. پژوهشگران حوزهی یادگیری ماشین برای این کار مجموعهای از الگوریتمها تحت عنوان مدلسازی موضوعی آماری را توسعه دادهاند.
الگوریتمهای مدلسازی موضوعی روشهای آماری هستند که کلمات داخل یک متن را تحلیل کرده و از این طریق موضوعات داخل متون را استخراج میکنند. همچنین ارتباط این موضوعات با یکدیگر و نیز تغییر آنها در طول زمان را مشخص میکنند. این الگوریتمها نیازی به هیچ فرض اولیهای در مورد موضوعات متون و یا برچسبگذاری متون ندارند. بلکه ورودی آنها متن اصلی است. الگوریتمهای مدلسازی موضوعی به ما این امکان را میدهند تا سازماندهی و خلاصهسازی آرشیوهای الکترونیکیمان را در ابعادی که از عهدهی انسان برنمیآید انجام دهیم.
در مدلسازی موضوعی سه هدف زیر را دنبال میکنیم:
پیدا کردن موضوعات نامعلوم که در مجموعه اسناد وجود دارند. (شایع هستند)
تفسیر کردن اسناد بر اساس موضوعات آنها.
استفاده کردن از این تفاسیر برای سازماندهی کردن، خلاصه کردن و جستجو کردن متنها.
۲. کارهای مرتبط
یکی از کارهای انجام شده در مورد مدل سازی موضوعی ۱۰۰۰۰۰ مقاله سایت ویکی پدیا است. این کار از TMVE برای نمایش آن به صورت گرافیکی استفاده میکند. این کار یک مرورگر است که ویژگی های زیر را دارد:
می تواند موضوعات را به ترتیب تکرار بیشتر زیر هم مرتب کند.
روی هر موضوعی کلیک می شود کلمات پر تکرار آن موضوع ، موضوعات مرتبط با آن موضوع و همچنین اسناد مربوطه را نشان می دهد و به همین ترتیب اگر روی اسناد کلیک شد متن سند را نشان می دهد.
در هر موضوع مشخص است که چه کلماتی با چه درصد هایی وجود دارند.
یک صفحه از مرورگر شامل تمام موضوعات با ۵ کلمه پر تکرار آن ها باشد.
صفحه ای دیگر شامل همه ی کلمات به ترتیب تکرار آنها است که مشخص شود که به طور کلی هر کلمه ای چند بار تکرار شده است.

۲.۱. مدل LSA 1
روش آنالیز معنایی پنهان یا LSA از جمله روشهای شناختهشده در کاهش بعد به شمار میرود. ایدهی اصلی پشتوانهی LSA، درست کردن یک ماتریس از وقوع همزمان کلمه/متن و سپس بیان این ماتریس بسیار بزرگ در یک زیرفضای کاهش بعد یافته با استفاده از «تجزیهی مقادیر تکین» یا SVD 2 میباشد. با تصویر کردن کلمات و متون در زیرفضای کاهش بعد یافته، میتوان آنها را به صورت برداری بیان نمود.
این مدل تکنیک دیگری در پردازش زبانهای طبیعی برای بررسی ارتباط بین یک مجموعه از اسناد و لغاتی که در آن اسناد وجود دارند میباشد. این روش مفاهیم پنهان در اسناد را کشف میکند. مطابق این الگوریتم برای هر سند مجموعهای از مفاهیم مرتبط با آن مشخص میشود. الگوریتم LSA فرض میکند کلماتی که معانی نزدیک به هم دارند در یک قطعه از متن قرار میگیرند. این الگوریتم گاهی در بازیابی اطلاعات با نام LSI 3 شناخته میشود.
قدم اول در این الگوریتم این است که متن را به صورت یک ماتریس نمایش دهیم. در این ماتریس هر سطر نشاندهندهی یک کلمه و هر ستون نشاندهندهی یک متن میباشد. به هر درایه توسط الگوریتم دیگری یک وزن داده میشود. یک روش وزن دهی tf-idf است. سپس با الگوریتم SVD سعی در کاهش تعداد سطرهای ماتریس میکنیم (کاهش ابعاد). این کار به سه دلیل زیر انجام میگیرد:
+ماتریس اولیه بسیار بزرگ است.
+در ماتریس اولیه اصطلاحاً نویز وجود دارد. به عنوان مثال کلماتی که به ندرت مورد استفاده قرار میگیرند باید حذف گردند.
+ماتریس اولیه یک ماتریس خلوت است؛ بنابراین کلماتی که به هم نزدیک هستند را در یک سطر قرار میدهیم.
کلمات سپس با کسینوس گرفتن از زاویهی بین هر دو بردار که سطرهای ماتریس میباشند با هم مقایسه میشوند. مقادیر نزدیک به یک بیانگر کلماتی هستند که تشابه بیشتری دارند و مقادیر نزدیک به صفر بیانگر کلماتی هستند که تشابه کمتری دارند.
۲.۲. مدلهای احتمالی
مدلهای موضوعی زیرمجموعهای از حوزهی مدلهای احتمالی هستند. همانطور که گفتیم مجموعهی اسناد ما شامل کلمات قابل مشاهده است و موضوعاتی که به دنبال آن میگردیم ساختارهای پنهان هستند. بهطورکلی مدلهای احتمالی متغیرهای آشکار و متغیرهای پنهان را با هم تلفیق کرده و نتیجه را مشخص میکنند.
۲.۲.۱. مدل PLSA4
هافمن تکنیک آماری جدیدی به نام «آنالیز معنایی پنهان احتمالاتی» یا PLSA را ارائه داد و برای نخستین بار از آن در بازیابی اطلاعات استفاده نمود. در سالهای اخیر این روش در زمینههایی چون فیلتر کردن اطلاعات، کندوکاو در در وب و طبقهبندی متون به طور موفقی به کار رفته است. در مقایسه با روش استاندارد تحلیل معنایی زبان یعنی LSA که از جبر خطی ریشه میگیرد و منجر به تجزیهی مقادیر تکین از جداول همآیی میشود، این روش بر اساس ترکیب احتمالاتی فاکتورهایی است که از یک مدل کلاس پنهان نشأت میگیرد و باعث ایجاد شیوههای اصولیتر در تحلیل زبان و متون گردیده که دارای زیربنای آماری محکمی میباشد. روش PLSA نه تنها بیان مناسبی از متون در اختیار ما قرار میدهد، بلکه یک روش دستهبندی بدون سرپرست نیز به شمار میرود. با توجه به تئوری آماری مناسبی که این روش دارد امکان انتخاب و کنترل مدل را فراهم میسازد.
۲.۲.۲. مدل LDA5
این روش سادهترین روش است. ابتدا ایدههای اساسی که این روش مبتنی بر آنهاست را توضیح میدهیم. این روش فرض میکند که اسناد موضوعات متعددی را نمایش میدهند؛ یعنی از کلماتی تشکیل شده است که هر یک متعلق به یک موضوع است و نسبت موضوعات داخل یک متن با هم متفاوت است. با توجه به این نسبتها میتوانیم آن متن را در یک موضوع خاص دستهبندی کنیم.
مجموعهی ثابتی از کلمات را به عنوان واژهنامه در نظر میگیریم. روش LDA فرض میکند که هر موضوع توزیعی روی این مجموعه کلمات است؛ یعنی کلماتی که مربوط به یک موضوع هستند در آن موضوع دارای احتمال بالایی هستند. فرض میکنیم این موضوعات از قبل مشخص هستند. حال برای هر سند از مجموعه اسنادی که در اختیار داریم کلمات را در دو مرحلهی زیر تولید میکنیم:
به طور تصادفی توزیع احتمالی را روی موضوعات انتخاب میکنیم.
برای هر کلمه از سند:
به طور تصادفی موضوعی را با استفاده از توزیع احتمال مرحلهی قبل مشخص میکنیم.
به طور تصادفی کلمهای را از واژهنامه با توزیع احتمال مشخصشده انتخاب میکنیم.
در این مدل احتمالی، اینکه هر سند از چندین موضوع تشکیل شده است را منعکس میکند. مرحلهی اول این قسمت را منعکس میکند که موضوعات مختلف در یک متن با نسبتهای متفاوتی سهیم هستند. قسمت دوم مرحلهی دوم هم بیانگر این است که هر کلمه در هر سند از یکی از موضوعات استخراج شده است و قسمت اول مرحلهی دوم هم بر این نکته تأکید دارد که این موضوع از توزیع احتمال موضوعات روی اسناد انتخاب شده است. ذکر این نکته لازم است که در این روش همهی اسناد مجموعهی یکسانی از موضوعات را در اختیار دارند ولی هر سند این موضوعات را با نسبتهای متفاوتی ارائه میکند.
۳. آزمایشها
۴. کارهای آینده
۵. مراجع
[1] Blei, David M. "Probabilistic topic models." Communications of the ACM 55.4 (2012): 77-84.
[2] Mark Steyvers, Tom Griffiths. "Probabilistic topic models.".
[3] Blei, D.M., Ng, A. Y., & Jordan, M. I. (2003). LatentDirichlet Allocation. JournalofMachine Learning Research,3,993-1022.
[4] Cohn, D. & Hofmann,T. (2001). The missinglink: A probabilistic model of documentcontentand hypertext connectivity. Neural InformationProcessingSystems 13, 430-436.
[5] Hofmann,T. (1999). Probabilistic LatentSemantic Analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence.
[6] Hofmann,T. (2001). Unsupervised Learning byProbabilistic LatentSemantic Analysis. Machine LearningJournal,42(1), 177-196.
[7] Landauer, T. K., & Dumais, S. T. (1997). A solutionto Plato’s problem: the LatentSemantic Analysis theory of acquisition,induction,and representation of knowledge. PsychologicalReview, 104, 211-240.
[8] Steyvers, M., Smyth,P., Rosen-Zvi, M., & Griffiths, T. (2004). Probabilistic Author-Topic Models for Information Discovery. The TenthACM SIGKDDInternationalConference onKnowledgeDiscovery and DataMining. Seattle, Washington.
[9] Asuncion, A., Welling, M., Smyth, P., Teh, Y. on smoothing and inference for topic models. in Uncertainty in Artificial Intelligence(2009).
[10] Blei, D., Griffiths, T., Jordan, M. the nested chinese restaurant process and bayesian nonparametric inference of topic hierarchies. J. ACM 57,2 (2010), 1–30.
[11] Blei, D., Jordan, M. modeling annotated data. in Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(2003 ), acmPress, 127–134.
[12] Yuening Hu, Jordan Boyd-Graber, Brianna Satinoff, Alison Smith,. Interactive topic modeling (2013 ), Kluwer Academic Publishers.
[13] Chyi-Kwei Yau, Alan Porter, Nils Newman, and Arho Suominen. 2014. Clustering scientific documents with topic modeling. Scientometrics 100, 3 (September 2014), 767-786.
۶. پیوندهای مفید
Latent Semantic Analysis
Single Value Decomposition
Latent Semantic Indexing
Probabilistic Latent Semantic Analysis
Latent Dirichlet Allocation