اینترنت و شبکه های کامپیوتری در معرض تعداد فزاینده ای از حملات اینترنتی هستند. با انواع جدید حملات که به طور مداوم پدیدار می شوند توسعۀ رویکرد های وفقی و انعطاف پذیر براساس امنیت، یک چالش سخت است. در این زمینه تکنیک های تشخیص نفوذ در شبکه بر مبنای ناهنجاری، تکنولوژی ارزشمندی برای حفاطت از سیستم های مورد هدف و شبکه ها در مقابل فعالیت های بدخواهانه است.
۱. مقدمه
سیستم های تشخیص نفوذ (IDS) ابزارهایی امنیتی هستند که مانند سایر اندازه گیرها مثل نرم افزارهای آنتی ویروس و دیوار آتش و نمودار های کنترل دسترسی، امنیت اطلاعات در سیستم های ارتباطی را تقویت می¬نمایند.
کار قابل توجهی توسط CIDF در حال اجرا بوده است، گروهی که توسط DAPRA در سال 1988 به وجود آمد و اساسا در راستای هماهنگ سازی و تعریف یک چارچوب مشترک در زمینۀ IDS فعالیت می کند. با ادغام شدن در IEFT در سال 2000 و با پذیرفتن نام مخفف جدید IDWG ، این گروه یک ساختار کلی برای IDS ها بر مبنای 4 نوع ماژول کاربردی تعریف کرده است. این ساختار در شکل شماره 1 مشخص است.
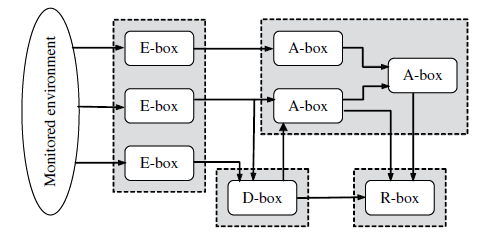
بلوک های E یا جعبه های رویداد : این بلوک ها از المان های حسگر که سیستم هدف را نمودار می کنند تشکیل شده اند. برای تحلیل اطلاعات رویدادها به بلوکهای دیگری نیاز است.
بلوک های D یا جعبه های پایگاه اطلاعاتی : وظیفۀ این المان ها، ذخیرۀ اطلاعات بلوک های E برای فرآیندهای بعدی بلوک های A و R است.
بلوک های A یا جعبه های تحلیل اطلاعات : ماژول های پردازش برای تحلیل رویدادها و تشخیص رفتارهایی که بالقوه مشکل سازند می باشند و ممکن در صورت نیاز یک هشدار تولید کنند.
بلوک های R یا جعبه های پاسخ : کارکرد اصلی این بلوک ها عملیات اجرایی است تا اگر نفوذی رخ دهد واکنش مناسب برای خنثی کردن آن تهدید اجرا شود.
بسته به منبع اطلاعات مورد بررسی ( بلوک های E )، یک IDS می¬تواند بر مبنای میزبان یا بر مبنای شبکه باشد. یک IDS بر مبنای میزبان، رویدادها را مانند فراخوانی های سیستم و هویت دهی به پردازش ها تحلیل می کند و اساسا به اطلاعات سیستم عامل ارتباط دارد. در سوی دیگر یک IDS بر مبنای شبکه، رویدادهای مرتبط با شبکه مانند حجم ترافیک، آدرس های IP، پورت های مورد استفاده، پروتکل مورد استفاده و ... را تحلیل می کند. موضوع بحث ما IDS های بر مبنای شبکه است.
بسته به نوع تحلیل انجام شده ( بلوک های A )، IDS ها به دو دستۀ برمبنای امضا و برمبنای ناهنجاری تقسیم می شوند. روش های برمبنای امضا به دنبال الگوهای تعریف شده یا امضاها در داده های تحلیل شده می گردند. برای این منظور یک پایگاه دادۀ امضاها بر اساس حملات شناخته شده تعیین شده و برای مقایسه مورد استفاده قرار می گیرد. در سوی دیگر شناسایی کننده های برمبنای ناهنجاری، تلاش می کنند تا رفتار طبیعی سیستمی که باید حفاظت شود را تخمین بزنند و مواقعی که انحراف نمونۀ مورد بررسی از یک آستانۀ از پیش تعیین شده فراتر رود یک هشدار ناهنجاری تولید کنند. یک امکان دیگر در این روش، مدل کردن رفتار غیرطبیعی سیستم و ایجاد هشدار در زمان هایی است که اجتلاف نمونۀ مورد بررسی با این مدل از یک حد معین کمتر باشد.
تفاوت اصلی سیستم های مبتنی بر امضا و سیستم های مبتنی بر ناهنجاری در مفاهیم "حمله" و "ناهنجاری" نهفته است. یک حمله می تواند به عنوان "دنباله ای از عملیات که امنیت سیستم را در خطر قرار می دهند" تعریف شود درحالیکه ناهنجاری فقط "یک رویداد که از نظر امنیتی مظنون است" تعریف می شود. با توجه به این تعاریف، مزیت ها و ایرادات هریک بیان می شود.
روش های برمبنای امضا نتایج بسیار خوبی در حفاظت از سیستم در مقابل حملات معین و کاملا شناخته شده دارند اما قادر به تشخیص نفوذهای ناآشنا و جدید نیستند حتی اگر نفوذهای جدید با نفوذهای شناخته شده تفاوت بسیار کمی داشته باشد.
در مقابل، مزیت اصلی تکنیک های تشخیص مبتنی بر ناهنجاری، توانایی بالقوه در تشخیص رویدادهایی که قبلا مشاهده نشده، است. اگرچه به عنوان ایراد این تکنیک ها باید گفت با وجود دقیق نبودن ویژگی های روش امضا، به طور معمول نرخ رویدادهایی که به اشتباه به عنوان حمله شناخته شده اند در سیستم های مبتنی بر ناهنجاری بیشتر از سیستم های مبتنی بر امضا است.
با توجه به توانایی های تضمین شدۀ سیستم های تشخیص نفوذ در شبکه بر مبنای ناهنجاری (A-NIDS)، این رویکرد در حال حاضر در مرکز توجه تحقیقات و توسعه در زمینۀ مشخیص نفوذ است.
روش های A-NIDS
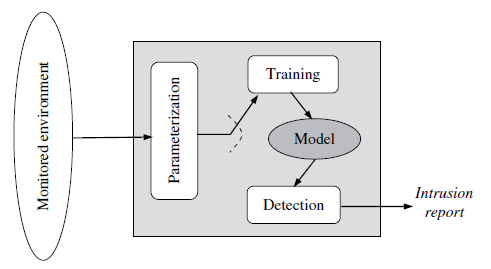
با اینکه رویکردهای A-NIDS متفاوتی وجود دارد، در قواعد کلی همۀ آنها متشکل از ماژول ها یا مراحل اولیۀ زیر هستند:
پارامتری سازی
مرحلۀ آموزش
مرحلۀ تشخیص
در شکل شماره 2 ارتباط این 3 ماژول نشان داده شده است.
توضیح تصویر
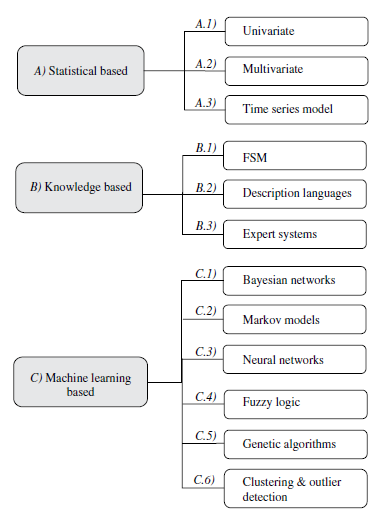
بر طبق نوع پردازش مرتبط با مدل رفتاری سیستم، روش های تشخیص مبتنی بر ناهنجاری می توانند به 3 دست تقسیم شوند. روش مبتنی بر آمار ، روش مبتنی بر دانش و روش مبتنی بر یادگیری ماشین . در روش مبتنی بر آمار رفتار سیستم از یک نقطه نظر تصادفی نمایش داده می شود. روش مبتنی بر دانش تلاش می کند تا رفتار مطلوب را از اطلاعات سیستمی در دسترس ( ویژگی های پروتکل، نمونه های ترافیک شبکه و ..) بدست آورد و روش مبتنی بر یادگیری ماشین بر اساس پایه گذاری یک مدل صریح یا ضمنی که دسته بندی الگوهای تحلیل شده را ممکن می سازد است.
روش های A-NIDS مبتنی بر یادگیری ماشین
همانطور که گفته شد روش مبتنی بر یادگیری ماشین بر اساس پایه گذاری یک مدل صریح یا ضمنی که دسته بندی الگوهای تحلیل شده را ممکن می سازد است. یک ویزگی این روش این است که دادۀ تعیین شده باید مدل رفتاری را یاد بگیرد.
یک A-NIDS مبتنی بر یادگیری ماشین قابلیت تغییر استراتژی اجرایی خود با توجه به نیاز به اطلاعات جدید، داراست اگرچه این ویزگی این روش را برای همۀ شرایط مطلوب می سازد، ایراد اصلی آن ماهیت پرهزینۀ منابع آن است.
از میان روش های A-NIDS مبتنی بر یادگیری ماشین به روش الگوریتم های ژنتیک اشاره می کنیم.
روش الگوریتم های ژنتیک
الگوریتم های ژنتیک در جستجوی اکتشافی عمومی دسته بندی می شوند و یک کلاس ویژه از الگوریتم های تکاملی هستند که از تکنیک هایی الهام گرفته از بیولوژی تکاملی مانند وراثت، جهش، انتخاب و ترکیب استفاده می کنند.
مزیت اصلی این زیرمجموعه از A-NIDS های مبتنی بر یادگیری ماشین، استفاده از یک روش جستجوی عمومی پایدار و انعطاف پذیر است که از جهات مختلف به سوی جواب می رود در حالیکه هیچ دانش قبلی دربارۀ رفتار سیستم در نظر گرفته نشده است.
ایراد اصلی آن درگیر کردن منابع مصرفی به میزان زیاد است.
۲. کارهای مرتبط
در یک دسته بندی کلی می توان سیستم های تشخیص نفوذ در شبکه را مانند شکل شماره 3 ارائه کرد:
با مطالعه کارهای نسبتا قدیمی که بین سال های 1980 و 2005 صورت گرفته است، به چند مورد به طور اجمالی اشاره می کنیم:
در یک رویکرد اولیه از روش مبتنی بر آمار، در سال 1985، Denning , Neumann مدلی تک متغیره ارائه دادند که هر یک از متغیرهای سیستم هدف را به عنوان یک متغیر مستقل تصادفی گاوسی در نظر می گرفت. بعدها مدل های چندمتغیره که ارتباط و همپوشانی بین دو یا چند متغیر سیستم را در نظر می گرفت ارائه شد. این مدل ها مفید هستند چرا که داده های آزمایشی نشان داده اند که در این حالت سطح بهتری از تمایز بین حالات عادی و نفوذ، قابل دستیابی است. Ye در سال 2002 مدلی از سیستم های چندمتغیره مبتنی بر آمار ارائه کرده است.
در سیستم های خبره که یکی از روش های مبتنی بر دانش است، داده های مورد بررسی براساس مجموعه ای از قوانین در سه مرحله طبقه بندی می شوند: 1. با استفاده از دادۀ آزمایشی کلاس ها و صفات مختلف معین می شوند. 2. مجموعه ای از قوانین، پارامترها و فرآیندها استخراج می شود. 3. داده های مورد بررسی متناظرا طبقه بندی می شوند. Anderson در سال 1995 در این زمینه کار کرده است.
اما در زمینۀ روش های مبتنی بر یادگیری ماشین، یکی از مدل های مورد استفاده مدل Bayesian است. در این مدل ارتباط احتمالاتی بین متغیرهای مهم سیستم هدف کدگذاری می شود. این روش عموما در ترکیب با نمودارهای آماری استفاده می شود. Heckerman در سال 1995 ضمن انجام این کار، مزیت های آن را نشان داده است. یکی از این مزیت ها، توانایی کدگذاری وابستگی های بین متغیرها و پیش بینی رویدادهاست و همچنین توانایی ترکیب شدن با دانش قبلی و داده های قبلی.
۳. آزمایشها
۴. کارهای آینده
۵. مراجع
[1] Kabiri, Peyman, and Ali A. Ghorbani. "Research on Intrusion Detection and Response: A Survey." IJ Network Security 1.2 (2005): 84-102.
[2] P.Garcia-Teodoro, J.Diaz-Verdego,G.Macia-Fernandez, E.Vazquez. "Anomaly-based network intrusion detection techniques, systems and challenges". Computers & Security Volume28, issue 1-2, (2009): 18-28.
[3] Este´vez-Tapiador JM, Garcı´a-Teodoro P, Dı´az-Verdejo JE. "Anomaly detection methods in wired networks: a survey and taxonomy". Computer Networks (2004):27(16):1569–84.
[4] Bridges S.M., Vaughn R.B. "Fuzzy data mining and genetic algorithms applied to intrusion detection". In: Proceedings of
the National Information Systems Security Conference; (2000):13–31.
[5] Li W. "Using genetic algorithm for network intrusion detection". C.S.G. Department of Energy; (2004): 1–8.