**درشت**اینترنت و شبکه های کامپیوتری در معرض تعداد فزاینده ای از حملات اینترنتی هستند. با انواع جدید حملات که به طور مداوم پدیدار می شوند توسعۀ رویکرد های وفقی و انعطاف پذیر براساس امنیت، یک چالش سخت است. در این زمینه تکنیک های تشخیص نفوذ در شبکه بر مبنای ناهنجاری، تکنولوژی ارزشمندی برای حفاطت از سیستم های مورد هدف و شبکه ها در مقابل فعالیت های بدخواهانه است.
# مقدمه
سیستم امانههای تشخیص نفوذ (IDS)[^ Intrusion Detection System] ابزارهایی امنیتی هستند که مانند سایر اندازه گیرها مثل نرم افزارهای آنتی ویروس و دیوار آتش و نمودار های کنترل دسترسی، امنیت اطلاعات در سیستم امانههای ارتباطی را تقویت می نمایند.
کار قابل توجهی توسط CIDF در حال اجرا بوده است، گروهی که توسط DAPRA در سال 1988 به وجود آمد و اساسا در راستای هماهنگ سازی و تعریف یک چارچوب مشترک در زمینۀ IDS فعالیت می کند. با ادغام شدن در IEFT در سال 2000 و با پذیرفتن نام مخفف جدید IDWG ، این گروه یک ساختار کلی برای IDS ها بر مبنای 4 نوع ماژول کاربردی تعریف کرده است. این ساختار در شکل شماره 1 مشخص است.[2]
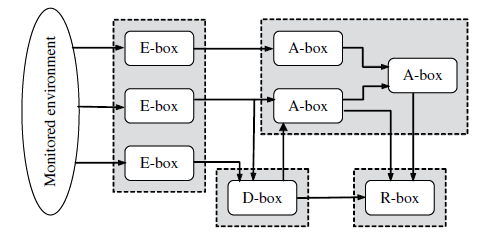
بلوک های E یا جعبه های رویداد : این بلوک ها از المان های حسگر که سیستمامانهی هدف را نمودار می کنند تشکیل شده اند. برای تحلیل اطلاعات رویدادها به بلوکهای دیگری نیاز است.
بلوک های D یا جعبه های پایگاه اطلاعاتی : وظیفۀ این المان ها، ذخیرۀ اطلاعات بلوک های E برای فرآیندهای بعدی بلوک های A و R است.
بلوک های A یا جعبه های تحلیل اطلاعات : ماژول های پردازش برای تحلیل رویدادها و تشخیص رفتارهایی که بالقوه مشکل سازند می باشند و ممکن در صورت نیاز یک هشدار تولید کنند.
بلوک های R یا جعبه های پاسخ : کارکرد اصلی این بلوک ها عملیات اجرایی است تا اگر نفوذی رخ دهد واکنش مناسب برای خنثی کردن آن تهدید اجرا شود.
بسته به منبع اطلاعات مورد بررسی ( بلوک های E )، یک IDS می تواند بر مبنای میزبان یا بر مبنای شبکه باشد. یک IDS بر مبنای میزبان، رویدادها را مانند فراخوانی های سیستم و هویت دهی به پردازش ها تحلیل می کند و اساسا به اطلاعات سیستم عامل ارتباط دارد. در سوی دیگر یک IDS بر مبنای شبکه، رویدادهای مرتبط با شبکه مانند حجم ترافیک، آدرس های IP، پورت های مورد استفاده، پروتکل مورد استفاده و ... را تحلیل می کند. موضوع بحث ما IDS های بر مبنای شبکه است. [2]
بسته به نوع تحلیل انجام شده ( بلوک های A )، IDS ها به دو دستۀ برمبنای امضا و برمبنای ناهنجاری تقسیم می شوند. روش های برمبنای امضا به دنبال الگوهای تعریف شده یا امضاها در داده های تحلیل شده می گردند. برای این منظور یک پایگاه دادۀ امضاها بر اساس حملات شناخته شده تعیین شده و برای مقایسه مورد استفاده قرار می گیرد. در سوی دیگر شناسایی کننده های برمبنای ناهنجاری، تلاش می کنند تا رفتار طبیعی سیستمی که باید حفاظت شود را تخمین بزنند و مواقعی که انحراف نمونۀ مورد بررسی از یک آستانۀ از پیش تعیین شده فراتر رود یک هشدار ناهنجاری تولید کنند. یک امکان دیگر در این روش، مدل کردن رفتار غیرطبیعی سیستم و ایجاد هشدار در زمان هایی است که اختلاف نمونۀ مورد بررسی با این مدل از یک حد معین کمتر باشد. [2]
تفاوت اصلی سیستم های مبتنی بر امضا و سیستم های مبتنی بر ناهنجاری در مفاهیم "حمله" و "ناهنجاری" نهفته است. یک حمله می تواند به عنوان "دنباله ای از عملیات که امنیت سیستم را در خطر قرار می دهند" تعریف شود درحالیکه ناهنجاری فقط "یک رویداد که از نظر امنیتی مظنون است" تعریف می شود. با توجه به این تعاریف، مزیت ها و ایرادات هریک بیان می شود.[2]
روش های برمبنای امضا نتایج بسیار خوبی در حفاظت از سیستم در مقابل حملات معین و کاملا شناخته شده دارند اما قادر به تشخیص نفوذهای ناآشنا و جدید نیستند حتی اگر نفوذهای جدید با نفوذهای شناخته شده تفاوت بسیار کمی داشته باشد.
در مقابل، مزیت اصلی تکنیک های تشخیص مبتنی بر ناهنجاری، توانایی بالقوه در تشخیص رویدادهایی که قبلا مشاهده نشده، است. اگرچه به عنوان ایراد این تکنیک ها باید گفت با وجود دقیق نبودن ویژگی های روش امضا، به طور معمول نرخ رویدادهایی که به اشتباه به عنوان حمله شناخته شده اند در سیستم های مبتنی بر ناهنجاری بیشتر از سیستم های مبتنی بر امضا است.
با توجه به توانایی های تضمین شدۀ سیستم های تشخیص نفوذ در شبکه بر مبنای ناهنجاری (A-NIDS)، این رویکرد در حال حاضر در مرکز توجه تحقیقات و توسعه در زمینۀ مشخیص نفوذ است.
**روش های A-NIDS**
با اینکه رویکردهای A-NIDS متفاوتی وجود دارد، در قواعد کلی همۀ آنها متشکل از ماژول ها یا مراحل اولیۀ زیر هستند:
1. پارامتری سازی
2. مرحلۀ آموزش
3. مرحلۀ تشخیص
در شکل شماره 2 ارتباط این 3 ماژول نشان داده شده است.**
### تعریف مسأئله**
اولین گام در تشخیص ناهنجاری فرموله کردن مسأله به شکل یک مسألهی الگوشناسی است. پس از این گام، الگوریتمهایی که برای تشخیص ناهنجاری به کار گرفته میشوند باید بهنحوی پیادهسازی شوند که توانایی یادگیری لحظه به لحظه (Online) را داشته باشند. مهمترین مسأله در الگوریتمهای تشخیص ناهنجاری توانایی بهروز کردن نمایهها یا الگوهای عادی به صورت پویا است.
نکتهی مهم در این رویکرد این است که تشخیص نفوذ را زیرمجموعهای از تشخیص ناهنجاری درنظر بگیریم. به طور کلی میتوان در مواجهه با یک ترافیک چهار حالت را مد نظر قرار داد:
1. نفوذ اما هنجار: یک سامانۀ تشخیص ناهنجاری ممکن است در شناسایی این دسته از نفوذها ناموفق عمل کند. چراکه رفتاری شبیه به رفتاری که برای سامانه عادی قلمداد می شود توسط مهاجم اتخاذ شده است. یعنی یک سامانۀ تشخیص ناهنجاری، به اشتباه خروجی منفی برای آن ثبت میکند.
2. غیرنفوذ اما ناهنجار:این موقعیت، همان موقعیتی است که یک سامانۀ تشخیص ناهنجاری FP تولید میکنداگرچه رفتار غیرعادی است، اما نفوذ نیست.
3. غیرنفوذ و هنجار:موقعیتی که سامانه، منفی صحیح ایجاد میکند. هم رفتار عادی است و هم نفوذی صورت نگرفته است.
4. نفوذ و ناهنجار: موقعیتی که سامانه، مثبت صحیح ایجاد میکند. یعنی رفتاری که شبیه به رفتار عادی سامانه نیست و یک حمله واقعاً صورت گرفته است.[6]
** رویکردهای افزایشی در تشخیص ناهنجاری**
واضح است که اگر سامانۀ تشخیص ناهنجاری را در شبکه قرار دهیم، این سامانه باید ترافیک را لحظه به لحظه دریافت و ضبط کند، سپس مرحلۀ پیشپردازش روی دادۀ ضبطشده انجام شود که در همین مرحله استخراج ویژگیها نیز انجام میشود و سپس داده به سمت موتور تشخیص ناهنجاری ارسال میشود. مهمترین مرحلهای که در اینجا از آن صحبت میکنیم و نتایج آزمایش روی آن انجام شده است، موتور تشخیص ناهنجاری است.
انواع ناهنجاری:
همانطور که در دستهبندی موجود در تصویر مشخص است،در یک سامانهی تشخیص ناهنجاری با دریافت هر رفتار شبکه، یک وضعیت برای آن ایجاد میشود، در صورتی که وضعیت مثبت صحیح یا منفی صحیح باشد، سامانه عملکرد درستی دارد و در غیر اینصورت خطا وجود دارد. خطای مثبت اشتباه مسئلهی بسیار مهمی در سامانههای تشخیص ناهنجاری محسوب میشود، این مسئله درست برخلاف سامانههای تشخیص نفوذ است که مسئلهی منفی اشتباه در آنها بیشتر دیده میشود.
### انواع ناهنجاری
ناهنجاری نقطهای: یک نمونۀ داده میتواند با توجه به معیارهای درنظر گرفتهشده ناهنجاری محسوب شود. این مقایسه بدون توجه به سایر دادههای قبل و بعد آن انجام میشود.
ناهنجاریهای متنی: تشخیص این ناهنجاریها با استفاده از ویژگیهای رفتاری و ویژگیهای متنی صورت میگیرد. ویژگیهای متنی، مشخصکنندۀ ویژگیهای یک نمونه در یک همسایگی مشخص است. ویژگیهای رفتاری مسئول مشخص کردن مشخصههایی هستند که با ویژگیهای متنی نمیتوان آنها را تعیین کرد.
برای تشخیص این نوع ناهنجاری مدلی پیشنهاد شده است که از هر دو نوع ویژگیهای متنی و رفتاری بهره میبرد. البته باید توجه داشت که این نوع ناهنجاری نیز یک ناهنجاری نقطهای است و دادهها به صورت دستهای دیده نمیشوند.
ناهنجاری جمعی: در برخی مواقع، ناهنجای در یک جریان از دادهها نمایان میشود، یعنی در مقایسه با کل مجموعهداده یک بخشی از دادهها که به نوعی (زمانی یا مکانی) به یکدیگر وابسته هستند، یک تغییر را مشخص میکنند. [6]
مانند همهی رویههای یادگیری ماشین، سه حالت با نظارت، نیمه نظارتی و بدون نظارت در الگوریتمها وجود دارد.
** مجموعهدادۀ استفاده شده**
مجموعهدادۀ KDD99که دارای ۴۱ ویژگی میباشد، دارای مقادیری غالبا به صورت عددی است، اما پرچمهای موجود در بسته، نوع پروتکل، نوع سرویس و برخی دیگر از مشخصهها به صورت نمادین تولید شده است.
| | | |
| ----------------- | -------------- | ----------- |
| مجموعهدادۀ اصلی | ۴۸ میلیون داده | ۲۲ نوع حمله |
| مجموعهدادۀ آموزش | ۱۶۹ هزار داده | ۲۲ نوع حمله |
| مجموعهدادۀ آزمون | ۳۱۱ هزار داده | ۳۹ نوع حمله |
به طور کلی تمام حملات استفاده شده در این مجموعهداده در ۴ دسته تقسیم میشوند:
·حملات U2R
·حملات R2L
·حملات Probe
·حملات DoS
و دستۀ آخر مربوط به ترافیک عادی است که با برچسب Normal مشخص میشود.[7]
# روش آزمایش:
در این مرحله با استفاده از ابزار Weka، روش آبشاری بررسی شده است، روش آبشاری با دریافت مجموعهدادۀ KDD99این مجموعهداده را با توجه به نوع سرویس یا ویژگی چهارم مجموعۀ داده تقسیمبندی میکند. سپس هر دسته از سرویسها را به عنوان مجموعهدادۀ آموزش به یک درخت میدهد . نوع درخت در روش آزمایششده درخت ITIاست.
خوشهبندی قبل از درخت نیز توسط دو روش K-Means و SOMانجام شده است.
الگوریتم K-Means:
الگوریتم K-meansدر مقالات Sarasammaو Wei-Yiاستفاده شده است. هر دو با استفاده از ابزار Wekaو مقدار K=10یک مجموعۀ آموزشی ۱۶۹ هزار نمونهای که به صورت تصادفی از مجموعۀ دادهی اصلی انتخاب شده است را ایجاد کردهاند.
پروژه پیادهسازی شده از طریق آدرس زیر قابل دسترسی است:
https://github.com/Sahar-amuee/Service-Classifie-of-KDD99.git
پروندههای نام برده شده در این قسمت همگی در آدرس بالا موجود است.
** استفاده از Service Classifier:**
در این حالت مجموعۀ آموزش و مجموعۀ آزمون هر دو بر اساس نوع سرویس بخش بندی میشوند، سپس به ازای هر سرویس یک درخت ITIکه در ادامه توضیح داده میشود، آموزش میبیند.
کد مربوط به این بخش را در پرونده prepare_dataset میباشد.[8]
** تشخیص ناهنجاری با درخت تصمیم ITI**
پس از آموزش، یک درخت تصمیم دودویی ایجاد میشود. در این درخت دو کلاس "صفر" برای ترافیک عادی و "یک" برای ترافیک ناهنجار تعریف میشود. البته این رویکرد در درخت تصمیم ID3نیز قبلاً پیادهسازی شده است.
درخت تصمیم ITIتوسط Utgoffپیادهسازی شده است و به صورت یک ابزار جداگانه از طریق خط فرمان در دسترس است.
در ITI یک درخت تصمیم افزایشی یا دستهای ساخته می شود، در حالت افزایشی هر نمونه به یک درخت کامل اضافه میشود و درخت بازسازی میشود، و در حالت دستهای پس از بررسی همۀ نمونهها، درخت کامل ایجاد میشود. رویکرد افزایشی از لحاظ هزینه معمولاً بهینهتر است.
استفاده از این الگوریتم به این صورت است که یک زیرمسیر شامل پروندۀ نامها و پروندۀ داده ایجاد میشود، این نوع استفاده از دادهها قالب C4.5 است که در برنامههای یادگیری ماشین مانند Wekaهم قابل استفاده است.
پروندۀ دارای پسوند names در سطر اول شامل تمامی برچسبهای کلاس مجاز برای هر رکورد داده است. سطر اول با یک نقطه در انتهای آن تمام میشود. در سطرهای بعدی به ترتیب نام هر ویژگی با نوع آن مشخص میشود که باز هم انتهای هر سطر با نقطه مشخص خواهد شد. برای درخت تصمیم ITI نیازی به مشخص کردن نوع متغیر ویژگی نیست.
پروندۀ دیگر با پسوند dataشامل دادهها است. این پرونده در هر سطر شامل یک نمونۀ واقعی است. هر جفت متغیر/ مقدار با یک کاما از جفت بعدی جدا شده است و در انتها نام برچسب کلاس قرار دارد. اگر از علامت سؤال در برچسب استفاده شده باشد یعنی مقدار کلاس این نمونه مشخص نیست .
برنامۀ ITI پس از مشخص کردن مسیر پروندهها، نصب و اجرا میشود، این برنامه از طریق خط فرمان در دسترس است.این ابزار از لینک http://people.cs.umass.edu/~lrn/iti/ در دسترس است.
# نتایج آزمایش:
در این آزمایش ابتدا مجموعۀ دادۀ اصلی به صورت تصادفی مرتب شد و ۱۶۹ هزار نمونه از آن انتخاب شد که به عنوان مجموعۀ آموزش به ردهبندها (Classifiers) وارد میشود.
اولین آزمایش با استفاده از درخت تصمیم ITI انجام شده است، سپس مجموعۀ داده بر اساس نوع سرویس تقسیم شده است، و به ازای هر سرویس، یک درخت آموزش داده شده است. نتایج در جدول زیر قابل مشاهده است:
| | | | |
| ------------ | ------------------------- | -------- | ------ |
| نوع حمله | نرخ نمونه در مجموعۀ آزمون | درخت ITI | ITI+SC |
| U2R | ۲۲۸ | ۷۸٫۳۶٪ | ۶۷٫۴۵٪ |
| R2L | ۱۶۱۸۹ | ۱۸٫۱۲٪ | ۲۱٫۰۹٪ |
| PROBE | ۴۱۶۶ | ۹۴٫۶۷٪ | ۹۵٪ |
| Normal | ۶۰۵۹۳ | ۹۸٪ | ۹۸٫۳۲٪ |
| DoS | ۲۲۹۸۵۳ | ۹۴٫۹۳٪ | ۹۷٪ |
| نرخ دقت کلی | مجموع: ۳۱۱۰۲۹ | ۹۱.۵۱٪ | ۹۳.۲۵٪ |
| تشخیص اشتباه | |۲.۰۶٪ | ۱.۹۳٪ |
# کارهای آینده
هریک از انواع حملات در صورت تشخیص به عنوان یک ناهنجاری مشخص میشوند و رفتاری عادی یا هنجار همان نمونههای Normal میباشند.
**همانطور که مشخص شده، عملکرد یک سامانهی تشخیص نفوذ با بررسی نمونههای نفوذ که از قبل برای سامانه تعریف نشده، سنجیده میشود و به همین دلیل در مجموعه دادهی آزمون تعداد نمونههای حمله نزدیک به ۲ برابر شده است.**
# روش آزمایش
برای انجام آزمایشها، از درخت تصمیم استفاده شده است. در برخی از مقالات مرجع، از روشی موسوم به روش آبشاری برای تشخیص ناهنجاری استفاده شده است. البته کدی که بتوان با آن، روش آبشاری را پیادهسازی کرد، موجود نیست، در مقابل اغلب درختهای تصمیم پیادهسازی شده و در دسترس هستند. در ادامه روش کار مطرح شده است.
### روش آبشاری [^Cascaded Classification]
در این مرحله با استفاده از یک اسکریپ بَش که در [گیتهاب](https://github.com/Sahar-amuee/Service-Classifie-of-KDD99.git) موجود است، روش آبشاری بررسی شده است، روش آبشاری با دریافت مجموعهدادۀ KDD99، این مجموعهداده را با توجه به نوع سرویس یا ویژگی چهارم مجموعۀ داده تقسیمبندی میکند.
در روش آبشاری، که اولین بار در سال ۲۰۰۷، معرفی شده است، پژوهشگران با بررسیهایی دریافتهاند که یکی از گلوگاههای روشهای تشخیص ناهنجاری با درخت تصمیم این است که رفتار شبکه برای دستههای مختلف رفتارها، بسیار متفوات است، و به همین دلیل اگر از یک درخت تصمیم استفاده شود، امکان اشتباه بسیار زیاد است[10].
به همین دلیل روشی معرفی شده است که در آن ابتدا تمامی رفتارهای دریافتشده به نحوی دستهبندی میشوند، سپس به ازای هر دسته یک درخت تصمیم جداگانه به صورت افزایشی یا به صورت دستهای ساخته میشود.

### مولفهی دستهبندی
دستهبندی را میتوان با دو رویکرد متفاوت خوشهبندی و ردهبندی انجام داد. در روش خوشهبندی دستهها یا گروههای ورودی که بر اساس آنها یک درخت ساخته میشود، بر اساس میزان شباهت و بدون توجه به یک مشخصهی خاص دستهبندی میشوند. اما در ردهبندی با در نظر گرفتن یکی از مشخصهها، به ازای مقادیر مختلف این مشخصه یک دسته یا گروه تشکیل میشود.
**الگوریتم K-Means:**
الگوریتم K-means در مقالات Sarasamma و Wei-Yi استفاده شده است [7] هر دو با استفاده از ابزار Wekaو مقدار K=10 یک مجموعۀ آموزشی ۱۶۹ هزار نمونهای که به صورت تصادفی از مجموعۀ دادهی اصلی انتخاب شده است را ایجاد کردهاند. در این حالت دستهها بیشترین شباهت را به یکدیگر دارند، این روش با استفاده از ابزار Weka بررسی شده است و خروجی آن در ادامه مطرح میشود.
** الگوریتم Service Classifier:**
در این حالت مجموعۀ آموزش و مجموعۀ آزمون هر دو بر اساس نوع سرویس بخش بندی میشوند، سپس به ازای هر سرویس یک درخت ساخته میشود، برای ایجاد یک ردهبند سرویس از یک اسکریپت استفاده شده است که در کد مربوط به آن در پرونده [prepare_dataset](https://github.com/Sahar-amuee/Service-Classifie-of-KDD99/blob/master/prepare_dataset) میباشد [8].
خروجی این مرحله دستههایی است که هر یک سرویس ویژهای را دارا هستند، برخی از سرویسها که بر اساس آن دستهها ایجاد میشوند عبارتند از:
+ HTML
+ SMTP
+ telnet
+ FTP
+ SSL
### مولفهی درخت تصمیم
واضح است که اگر سامانۀ تشخیص ناهنجاری را در شبکه قرار دهیم، این سامانه باید ترافیک را لحظه به لحظه دریافت و ضبط کند، سپس مرحلۀ پیشپردازش برای دادۀ ضبطشده به صورت کامل انجام شود که در همین مرحله استخراج ویژگیها نیز صورت میگیرد و سپس داده به سمت موتور تشخیص ناهنجاری ارسال میشود. مهمترین مرحلهای که در اینجا از آن صحبت میکنیم و نتایج آزمایش روی آن انجام شده است، موتور تشخیص ناهنجاری است. معمولاً درختهای تصمیم که در این آزمایشها تمرکز زیادی روی آنها صورت گرفته است، در دو حالت دستهای و افزایشی عمل میکنند. در حالت دستهای آموزش در یک مرحله انجام میشود و درخت در این مرحله ساخته میشود، در روش افزایشی درخت به صورت برخط و با دریافت دادههای تدریجی به صورت مستمر بهروز میشود.
** تشخیص ناهنجاری با درخت تصمیم ITI**
پس از آموزش، یک درخت تصمیم دودویی ایجاد میشود. در این درخت دو کلاس "صفر" برای ترافیک عادی و "یک" برای ترافیک ناهنجار تعریف میشود. البته این رویکرد در درخت تصمیم ID3 نیز قبلاً پیادهسازی شده است.
درخت تصمیم ITI توسط Utgoff پیادهسازی شده است و به صورت یک ابزار جداگانه از طریق خط فرمان در دسترس است.
در ITI یک درخت تصمیم افزایشی یا دستهای ساخته می شود، در حالت افزایشی هر نمونه به یک درخت کامل اضافه میشود و درخت بازسازی میشود، و در حالت دستهای پس از بررسی همۀ نمونهها، درخت کامل ایجاد میشود. رویکرد افزایشی از لحاظ هزینه معمولاً بهینهتر است.
استفاده از این الگوریتم به این صورت است که یک زیرمسیر شامل پروندۀ نامها و پروندۀ داده ایجاد میشود، این نوع استفاده از دادهها قالب C4.5 است که در برنامههای یادگیری ماشین مانند Wekaهم قابل استفاده است.
پروندۀ دارای پسوند names در سطر اول شامل تمامی برچسبهای کلاس مجاز برای هر رکورد داده است. سطر اول با یک نقطه در انتهای آن تمام میشود. در سطرهای بعدی به ترتیب نام هر ویژگی با نوع آن مشخص میشود که باز هم انتهای هر سطر با نقطه مشخص خواهد شد. برای درخت تصمیم ITI نیازی به مشخص کردن نوع متغیر ویژگی نیست.
پروندۀ دیگر با پسوند data شامل دادهها است. این پرونده در هر سطر شامل یک نمونۀ واقعی است. هر جفت متغیر/ مقدار با یک کاما از جفت بعدی جدا شده است و در انتها نام برچسب کلاس قرار دارد. اگر از علامت سؤال در برچسب استفاده شده باشد یعنی مقدار کلاس این نمونه مشخص نیست .
برنامۀ ITI پس از مشخص کردن مسیر پروندهها، نصب و اجرا میشود، این برنامه از طریق خط فرمان در دسترس است. این ابزار از [وبگاه اصلی](http://people.cs.umass.edu/~lrn/iti/) قابل دریافت است.
# نتایج آزمایش
در این آزمایش ابتدا مجموعۀ دادۀ اصلی به صورت تصادفی مرتب شد و ۱۶۹ هزار نمونه از آن انتخاب شد که به عنوان مجموعۀ آموزش به ردهبندها [^Classifiers] وارد میشود.
اولین آزمایش با استفاده از درخت تصمیم ITI انجام شده است، در ابتدا مجموعۀ داده بر اساس نوع سرویس تقسیم شده است، و به ازای هر سرویس، یک درخت آموزش داده شده است. مولفهی دستهبندی مجموعه دادهی آموزش و آزمون، از الگوریتم Service Classifier استفاده کرده است. این ردهبندی باعث میشود با دریافت نمونههای جدید که بر اساس نوع حمله است، میتواند به خوبی بر اساس نوع سرویس درخت مناسب را پیدا کند. استفاده از خوشهبندی اگرچه در این آزمایش مدنظر نبوده، اما پس از بررسی به علت کند بودن بیشاز حد، حذف شده است.
| | | | |
| ------------ | ------------------------- | -------- | ------ | -----------
| نوع حمله | نرخ نمونه در مجموعۀ آزمون | درخت ITI | ITI+SC | ITI+K-Means
| U2R | ۲۲۸ | ۷۸٫۳۶٪ | ۶۷٫۴۵٪ |۲۵٪
| R2L | ۱۶۱۸۹ | ۱۸٫۱۲٪ | ۲۱٫۰۹٪ |۱٫۵۶٪
| PROBE | ۴۱۶۶ | ۹۴٫۶۷٪ | ۹۵٪ |۸۰٫۴۶٪
| Normal | ۶۰۵۹۳ | ۹۸٪ | ۹۸٫۳۲٪ |۹۹٪
| DoS | ۲۲۹۸۵۳ | ۹۴٫۹۳٪ | ۹۷٪ |۹۵٪
| نرخ دقت کلی | مجموع: ۳۱۱۰۲۹ | ۹۱٫۴۷٪ | ۹۳٫۲۲٪ |۹۰٫۶۵٪
| تشخیص اشتباه | |۲٫۰۶٪ | ۱٫۹۳٪ |۰٫۴۵٪
همانطور که مشاهده میشود، اگر از مولفهی Service Classifier استفاده شود، پاسخهای بهتری در حملات R2L که سختترین نوع ناهنجاری هستند، به دست میآید. تشخیص دادههای هنجار، در الگوریتم K-Means بهتر است، دلیل اصلی این مسئله شباهت زیاد دادههای هنجار و به طور کلی رفتار عادی شبکه است که در دستهی نرمال به خوبی مدل میشوند، اما مشاهده میشود استفاده از الگوریتمهای خوشهبندی در تشخیص ناهنجاری عملکرد بسیار ضعیفی دارد. به همین دلیل هم روش ردهبندی بر اساس سرویس در گامهای بعدی پروژه نیز لحاظ خواهد شد.
# بهبود روشهای مطرحشده
برای بهبود روشی که در مرحلهی قبلی بررسی شد، از منبع دیگری استفاده شده است. در پژوهش [11] محققان با هدف بهبود روشهای تشخیص نفوذ، از روش کاهش ویژگیها در ردهبند استفاده کردهاند. برای استفاده از ایدهی این پژوهشگران در یک سامانهی تشخیص ناهنجاری باید مولفهای قبل از مولفهی دستهبندی اضافه شود که ویژگیهای مهم را استخراج کند.
انتخاب مهمترین ویژگیها، در این مقاله با استفاده از information gain به دست میآید. در این روش، هر یک از ویژگیها بر اساس تعداد مقادیر مجاز خود دستهبندی میشوند. از آنجایی که مقادیر در مجموعهدادهی KDD99 به صورت گسسته است، این روش ممکن است، در صورتی که هر یک از ویژگیها مقادیر پیوسته داشته باشند به راحتی مقادیر را در بازههای مجاز قرار میدهیم و فرمولهای میزان اطلاعاتی که هر ویژگی به ما میدهد را محاسبه میکنیم. فرآیند کلی روش آبشاری بهبود یافته قابل مشاهده است:

##انتخاب ویژگیها بر اساس Information Gain
روش مذکور نسبتاً ساده است، در این روش ابتدا با داشتن تمام مجموعهدادهی آزمایشی، با داشتن برچسب کلاس، تعداد برچسب هر کلاس را میشماریم و مطابق فرمول زیر اطلاعات کل این مجموعهداده را محاسبه میکنیم:

گفتنی است اگرچه در مجموعهدادهی KDD99 چندین نوع حمله به تفکیک مشخص شده است، اما در این نوع روش تشخیص دو کلاس هنجار و ناهنجار وجود دارد، بنابراین به دست آوردن اطلاعات بسیار ساده خواهد شد.
در مرحلهی بعدی به ازای هر ویژگی و بر اساس مقادیر مجاز تعریفشده، (مانند فرمول مطرحشده در بالا، با این تفاوت که به جای هر کلاس، مقدارهای مجاز برای ویژگی درج میشود)، مقدار اطلاعاتی که هر ویژگی تولید میکند را محاسبه میکنیم، سپس مقدار دریافتی یا Gain هر ویژگی از فرمول زیر محاسبه میشود:

در نهایت مقدار Gain برای ویژگیها مرتب میشود، و دوازده ویژگی برتر انتخاب میشوند. گفتنی است ویژگی سرویس که ساخت درخت بر اساس آن شکل میگیرد، Gain بالایی دارد، و نشان میدهد ردهبندی دادهها بر اساس این ویژگی بیاساس نیست.
| |
| ---------- | ------------------------ | --------- |
| ردیف | نام ویژگی| Gain |
| ۱ | src_byte | ۰٫۹۳۹۹۳۵ |
| ۲ | service | ۰٫۸۳۲۵۹۷ |
| ۳ | count | ۰٫۸۰۷۷۵۱ |
| ۴ | dst_byte | ۰٫۷۸۱۹۴۵ |
| ۵ | logged_in | ۰٫۵۸۲۹۸۲ |
| ۶ | dst_host_srv_diff_host_rate| ۰٫۴۴۱۰۵۸ |
| ۷ | dst_host_diff_srv_rate | ۰٫۴۲۱۸۸۹ |
| ۸ | dst_host_count | ۰٫۴۰۴۱۰۹|
| ۹ | srv_count |۰٫۳۶۵۵۶۹ |
| ۱۰ | flag | ۰٫۳۲۸۱۱۲ |
| ۱۱ | dst_host_serror_rate | ۰٫۳۰۶۳۲۸ |
| ۱۲ | dst_host_srv_serror_rate | ۰٫۳۰۴۹۵۸ |
پس از انتخاب ویژگیها مناسب، نوبت به استفاده از ردهبند سرویسها میباشد که مانند معماری اولیه است، پس از آن به ازای هر سرویس یک پرونده حاوی دادههای هر سرویس ایجاد میشود و به ازای هر پرونده یک درخت تصمیم ایجاد میشود.
## درخت تصمیم J48
در مقالاتی که بررسی شد، دو درخت تصمیم ITI و ID3 به عنوان ردهبندی نهایی مورد استفاده قرار گرفت. در آزمایشهای صورتگرفته مشخص شد درخت تصمیم C4.5 که در ابزار Weka با عنوان الگوریتم J48 پیادهسازی شده است، پاسخهای بهتری تولید میکند. این درخت تصمیم ارتقاء یافتهی درخت تصمیم ID3 است، در هر مرحلهی ساخت درخت تصمیم، J48 ویژگی را انتخاب میکند که با بیشترین دقت میتواند دادهها را بر اساس مقادیر مجاز این ویژگی تقسیم کند. این درخت تصمیم چند ویژگی مهم دارد:
+ توانایی مدیریت ویژگیها با مقادیر مجاز پیوسته، برای اینکار بازه و حد آستانه برای ویژگیها تعریف میشود
+ توانایی مدیریت دادههای آموزشی که برخی ویژگیها در آنها لحاظ نشده است [^Missing attribute values]
+ هرس شدن درخت در انتهای کار، این الگوریتم در حالت دستهای پس از تولید درخت به سمت بالا حرکت میکند و شاخههایی که در دستهبندی کمک زیادی نمیکنند را با یک برگ جایگزین میکند.
آزمایشهای انجامشده برای درخت تصمیم J48 با استفاده از ابزار وکا صورت گرفته است و نرخ تشخیص به صورت زیر محاسبه شده است:
| | | |
| ------------ | ------------------------- | -------- |
| نوع حمله | نرخ نمونه در مجموعۀ آزمون | SC+J48 |
| U2R | ۲۲۸ | ۸۴٫۴۰٪ |
| R2L | ۱۶۱۸۹ | ۵۲٫۷۹٪ |
| PROBE | ۴۱۶۶ | ۹۷٫۰۳٪ |
| Normal | ۶۰۵۹۳ | ۹۹٫۶۴٪ |
| DoS | ۲۲۹۸۵۳ | ۹۶٫۳۳٪ |
| نرخ دقت کلی | مجموع: ۳۱۱۰۲۹ | ۹۴٫۶۹٪ |
| تشخیص اشتباه | |۱٫۰۵٪ |
برای انجام آزمایشها مانند مرحلهی قبل در اسکریپت prepare_dataset برچسب مربوط به حمله را به یکی از ۴ دستهی حمله یا نرمال تبدیل میکنیم. این کار را میتوان حذف کرد و در نتیجهها با شمارش و سپس تبدیل برچسب هر حمله به یکی از دستهها نیز انجام داد.
همانطور که به مشاهده میشود، درخت تصمیم J48 در تمام دستهها خصوصاً دستهی حملات پیچیدهی U2R موفق عمل کرده است. در نموداری که در ادامه آورده میشود، دادههای هر چهار آزمون به صورت گرافیکی با یکدیگر مقایسه شدهاند:

همانطور که در نمودار نیز مشخص است، هنوز نرخ اشتباه در روش K-means بسیار بهتر است، اما نرخ دقت کلی در روش درخت تصمیم J48 به مراتب از سایر روشها بهتر است.
# کارهای آینده
+ در آینده با توجه به مرجع [12]، مولفهی اول که تاکنون توسط روش information gain انجام میشده است، با استفاده از الگوریتم ژنتیک انجام خواهد شد. پیادهسازی روش information gain به دلیل استفاده از فرمول با یک اسکریپت بَش انجام شده است، اما پیادهسازی الگوریتم ژنتیک برای انتخاب ویژگیها به زمان بیشتری نیاز دارد.
+ همچنین استفاده از درختهای تصمیم در حالت افزایشی به دلیل پیچیدگیهای مربوط به انتخاب پنجرهی زمانی مناسب، پاسخ مناسبی تولید نکرده است که در ادامه با بررسی دقیقتر پنجرههای زمانی یادگیری جریانی با استفاده از درختهای تصمیم افزایشی بررسی و پیادهسازی میشود. یادگیری جریانی یکی از چالشهای بسیار مهم در حوزهی یادگیری ماشین است.
+ در آخر نیز از آنجایی که به ازای هر دسته یک بار الگوریتم یادگیری درخت صدا زده میشود، باید این روند با استفاده از یک اسکریپت خودکار شود.
# مراجع
[1] Kabiri, Peyman, and Ali A. Ghorbani. "Research on Intrusion Detection and Response: A Survey." IJ Network Security 1.2 (2005): 84-102.
[2] P.Garcia-Teodoro, J.Diaz-Verdego,G.Macia-Fernandez, E.Vazquez. "Anomaly-based network intrusion detection techniques, systems and challenges". Computers & Security Volume28, issue 1-2, (2009): 18-28.
[3] Este´vez-Tapiador JM, Garcı´a-Teodoro P, Dı´az-Verdejo JE. "Anomaly detection methods in wired networks: a survey and taxonomy". Computer Networks (2004):27(16):1569–84.
[4] Bridges S.M., Vaughn R.B. "Fuzzy data mining and genetic algorithms applied to intrusion detection". In: Proceedings of
the National Information Systems Security Conference; (2000):13–31.
[5] Li W. "Using genetic algorithm for network intrusion detection". C.S.G. Department of Energy; (2004): 1–8.
[6] Monowar Hussain Bhuyan1, D K Bhattacharyya1 and J K Kalita2. "Survey on Incremental Approaches for Network Anomaly Detection". International Journal of Communication Networks and Information Security (IJCNIS),Vol. 3, No. 3,(2011) .
[7]Suseela T. Sarasamma and Qiuming A. Zhu. "Min–Max Hyperellipsoidal Clustering forAnomaly Detection in Network Security". IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, AUGUST (2006),VOL. 36, NO. 4.
[8]Wei-Yi Yu and Hahn-Ming Lee. "An Incremental-Learning Method for Supervised Anomaly Detection by Cascading Service Classifier and ITI Decision Tree Methods ". Department of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei, 106, Taiwan, R.O.C ,(2009)
[9] Mahbod Tavallaee, Ebrahim Bagheri, Wei Lu, and Ali A. Ghorbani. "A Detailed Analysis of the KDD CUP 99 Data Set".Proceedings of the 2009 IEEE Symposium on Computational Intelligence in Security and Defense Applications (CISDA 2009)