هدف از انجام این پروژه طراحی و پیاده سازی یک سیستم است که تصویر دو اثر انگشت ورودی که برای احراز هویت به آن داده میشود را با هم مقایسه کرده و عددی را به عنوان میزان تشابه آن برگرداند. سپس برای پذیرش احراز هویت، یک آستانه را برای میزان شباهت تعیین کند که اگر میزان شباهت از آن مقدار بیشتر بود، سیستم آن مقایسه را به عنوان تطبیق بپذیرد و در غیر اینصورت آن را رد کند. این حد آستانه باید به گونه ای باشد که خطا روی پایگاه داده آزمون، کمترین میزان باشد. منظور از خطا، جمع مقدار FAR[^False Accept Rate] و FRR[^False Reject Rate] میباشد.
* برای دریافت دادههای آموزش و آزمون لطفا به آزمایشگاه دکتر آنالویی مراجعه نمایید.
# مقدمه
با توجه به افزایش روزافزونِ اهمیت و کاربرد تشخیص هویت در دنیای امروزه،اهمیت روش های تشخیص هویت نیز روز به روز افزایش پیدا می کند.یکی از روش های تشخیص هویت،علم بیومتریک یا زیست سنجشی[^Biometric] است.در این علم سعی می شود با توجه به مشخصات رفتاری یا فیزیولوژی انسان،هویت او تعیین شود.تشخیص هویت از روی وزن،قد، اثر انگشت،صورت،شبکیه یا عنبیه چشم و هندسه دست نمونه هایی از تشخیص فیزیولوژی و شناسایی از طریق امضا،صدا،،نحوه راه رفتن[^ gait] و میزان فشار بر روی کیبرد هنگام تایپ کردن[^Keystroke] نمونه هایی از تشخیص رفتاری انسان است.حال به بررسی معایب و مزایای هر کدام از روش های فوق می پردازیم[3].
# مقایسه تکنولوژی های بیومتریکزیست سنجشی
قبل از مقایسه تکنولوژی های بیومتریک،نیاز به تعریف پارامتر های اندازه گیری برای این تکنولوژی ها داریم.این پارامتر ها عبارتند از:
**+ عمومیت یا فراگیری:**[^Universality]
تعداد افرادی که شامل این ویژگی هستند را مشخص می کند.
**+ یکتایی:** [^Uniqueness]
احتمال اینکه دو فرد متفاوت دارای یک ویژگی برابر نباشند توسط این ویژگی بیان می شود.هر چه قدر میزان این ویژگی بیشتر بیان شده باشد میزان یکتایی افراد بر اساس این ویژگی بیشتر است.
**+ دوام و بقا:** [^Permanence]
تغییر نکردن ویژگی را با گذر زمان مشخص می کند.
**+ جمع آوری :** [^Collectability]
راحتی جمع آوری و اندازه گیری ویژگی را بیان می کند.این ویژگی را قابلیت ارزیابی نیز نامیده اند.
**+ کارایی :** [^Performance]
میزان دقت و مقبول بودن نتایج سیستم ما را نشان می دهد.
**+ مقبولیت:** [^Acceptability]
میزان علاقه مردم به استفاده از تکنولوژی مورد نظر را نشان می دهد.
**+ دور زدن:** [^Circumvention]
پایین بودن امکان تقلب و دور زدن سیستم را توسط فرد غیرمجاز نشان می دهد.
با توجه به پارامتر های فوق،جدول زیر محاسن و معایب هر کدام از روش ها را بیان می کند[3]:
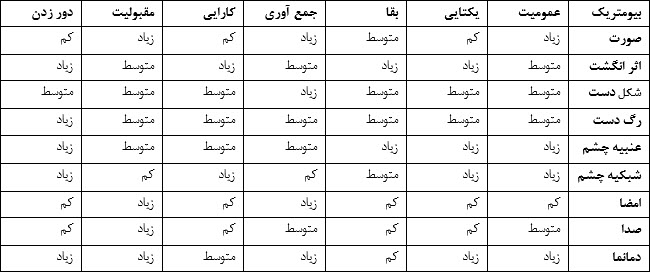
----------
**دلایل فراگیر شدن تشخیص اثر انگشت:**
مهم ترین دلایل فراگیر شدن تشخیص اثر انگشت عبارت است از[2]:
+ موفقیت این شیوه در کاربرد های مختلف قضایی،دولتی،تجاری و... در حدی که حتی در تلفن های همراه جدید نیز استفاده می شود.
+ باقی ماندن اثر انگشت مجرمان در صحنه جرم دلیل دیگر استفاده از این روش است
+ وجود پایگاه داده کاملی از آثار انگشت(به طوری که تا سال 2000 بیش از 70 میلیون اثر انگشت مختلف در پایگاه داده FBI موجود بوده است)
+ وجود دستگاه های ثبت اثر انگشت ارزان قیمت و کم حجم
یک سیستم تشخیص اثر انگشت هم برای مقایسه و هم برای تعیین هویت استفاده می شود:
**+ مقایسه:**
در این حالت،سیستم اثر انگشت ورودی را با انگشت ثبت شده یک کاربر خاص مقایسه می کند تا تعیین کند آیا هر دو اثر به یک انگشت مربوط هستند یا خیر.
**+ تعیین هویت:**
در حالت تعیین هویت،سیستم اثر انگشت ورودی را با کل نمونه های درون پایگاه داده مقایسه می کند تا غیر مجاز بودن یا تکراری بودن یک کاربر مشخص شود.مثلا مکان های صدور ویزا در آمریکا از سال 2004 تا کنون دارای این سیستم هستند تا افراد تحت تعقیب،مجرمان،تروریست ها و افراد متخلف را شناسایی شوند.
قبل از وارد شدن به طرح راه حل و کارهای مرتبط برای این پروژه، نیاز مند آشنایی با انواع سنسور های ثبت اثر انگشت و چگونگی تشخیص اثر انگشت هستیم.
# دستگاه های ثبت اثر انگشت:
براساس نوع دریافت اثر انگشت،دستگاه ها به دو مدل اسکن زنده[^live-scan] و آفلاین[^Off-line] تقسیم می شوند.در مدل های آفلاین،اثر انگشت توسط آغشته کردن انگشتان به جوهر و فشار دادن انگشتان بر روی کاغذ و عکس برداری یا اسکن از کاغذ،دریافت می شود.در حالیکه روش اسکن زنده با دیجیتال کردن اثر انگشتی که سنسور ها را لمس کرده عمل می کند.مهمترین مورد استفاده روش های آفلاین، تشخیص اثر انگشت مجرم در محل جرم است.اسکنر های دیجیتالی را بر اساس رزولوشن،تعداد پیکسل،مساحت سنسور،دقت و.... دسته بندی می کنند.
اسکنر های دیجیتالی زنده به پنج دسته بصری[^Optical] ، خازنی[^Capacitive]،حرارتی[^Thermal] ،فشاری[^Pressure-based ]و فراصوت[^Ultrasound] تقسیم می شوند[1].در شکل زیر ،نمونه ای از اثر انگشت که توسط هر کدام از اسکنر های فوق به دست آمده را می بینیم[53-1]:

علاوه بر اسکنر های بیان شده،حسگر های جارویی نیز به دلیل اندازه کوچک و قیمت پایین،کاربرد وسیعی در لپ تاپ ها،تلفن های همراه هوشمند،تبلت ها و سایر وسایل تجاری دارند. این اسکنر ها از طریق حرکت دست بر روی سطح اسکنر و سر هم کردن تکه های اسکن شده به دست می آیند.نمونه ای از این سنسور ها که توسط شرکت سامسونگ در گوشی های پرچم دار خود استفاده می شود را در تصویر زیر خواهیم دید:

# چگونگی تشخیص اثر انگشت:
پوست کف دست و کف پای[^VolarSkin] ما،الگویی متحرک از خط ها و شیارها را به وجود می آورد.در تمام قسمت های کف دست و پای ما،به صورت پیوسته پوست ما با خطوط نازکی چین خورده است.این خطوط برجسته روی انگشت را خطوط اصطکاکی[^FRICTION RIDGE] می نامیم.از طریق این خطوط ،به دلیل افزایش اصطکاک با اجسام،دست می تواند اشیا را نگه دارد و همچنین حس لامسه در تماس با سطح اشیا افزایش می یابد.علاوه بر موارد فوق،به وسیله همین خطوط اصطکاکی هویت افراد تشخیص داده می شود.زیرا این خطوط برای هر یک از انگشتان دست هر فرد منحصر به فرد و غیر قابل تغییر است.به عبارت دیگر به کمک اثر انگشت حتی می توان دوقلوهای همسان را از یکدیگر تمیز داد.جراحات سطحی ناشی از بریدگی یا سوختگی های عادی در سطح انگشتان،تنها به صورت موقت الگوی خطوط را از ناحیه آسیب دیده از بین می برند و پس از بهبود آسیب دیدگی،این خطوط دوباره ظاهر می شوند.طبق تحقیقات رویان شناسی،این خطوط اصطکاکی در ماه چهارم بارداری ظاهر می شود و تا هفته هجدهم برجسته نخواهند شد.به عقیده پژوهشگران رویان شناسی،این خطوط اصطکاکی تنها تحت تاثیر فاکتور های ژنتیکی قرار نمی گیرد و کشش های فیزیکی تصادفی هنگام رشد جنین نیز بر شکل گیری این الگو ها تاثیر خواهند گذاشت.[2]
به طور کلی الگوهای اصلی اثر انگشت به سه دسته کمانی[^Arch]، حلقه ای[^Loop] و مارپیچی[^whorl] تقسیم می شوند که شکل زیر نشان دهنده آنهاست[1]:

توسط این الگو ها می توان خصوصیاتی از قبیل مینوشیا[^Minutiae] را دریافت نمود.به محل هایی که خطوط اصطکاکی ناگهان قطع شده یا به دو یا چند شاخه تقسیم شده اند مینوشیا می گویند.در این روش از ساختار محلی مینوشیا برای یافتن سریع یک انطباق نسبی بین دو نمونه اثر انگشت استفاده و از انطباق کامل دو نمونه اطمینان حاصل می شود.
در این سیستم ها با دو نوع خطا مواجه هستیم:
خطای نوع اول FAR یا FMR[^False Match rate] نامیده می شود.تشخیص مثبت اشتباه زمانی رخ می دهد که سیستم برای بررسی یک اثر انگشت ثبت نشده،نتیجه مثبت(انطباق)را بازمی گرداند.
خطای نوع دوم FNR یا FNMR[^False non match Rate]نامیده می شود.تشخیص منفی اشتباه زمانی رخ می دهد که سیستم برای یک اثر انگشت ثبت شده،نتیجه منفی(تطابق اشتباه یا عدم تطابق)را باز می گرداند.در سیستم هایی که امنیت زیادی نیاز ندارند و سرعت بیشتر از امنیت اهمیت دارد،در اولویت اول سعی می شود FNMR کمتری نسبت به FMR داشته باشند.مثلا سیستم های مبتنی بر اثر انگشت مجموعه دیزنی،با نرخ بسیار پایین FNMR کار می کنند،اما در عوض نرخ FMR بالایی دارند.از سوی دیگر،سیستم تشخیص اثر انگشت یک عابربانک به کمترین نرخ FMR نیاز دارد در نتیجه FNMR بالایی خواهد داشت.
در نتیجه کاهش هم زمان نرخ هر دوی این خطاها غیر ممکن است و کاهش یکی از این خطاها با افزایش دیگری اتفاق می افتد.
# کارهای مرتبط
در شکل زیر،شمای کلی یک سیستم تشخیص اثر انگشت را مشاهده می کنید[2]
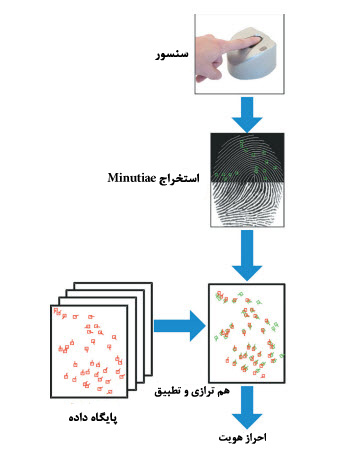
در مرحله ثبت اثر انگشت،اثر انگشت کاربر توسط حسگر اسکن شده و تبدیل به یک تصویر دیجیتال می شود.جدا کننده ی مینوشیا،تصویر اثر انگشت را برای تعیین جزئیات خاصی که به اصطلاح نقاط مینوشیا [^Minutiae Points]نامیده می شوند پردازش می کند.نقاط مینوشیا محل هایی را که خطوط اصطکاکی ناگهان قطع شده یا به دو یا چند شاخه تقسیم شده اند را مشخص می کند.
در مرجله تشخیص کاربر دوباره همان حسگر را لمس می کند و تصویر جدیدی از اثر انگشت ایجاد می شود.به این تصویر جدید، Query Print گفته می شود.نقاط مینوشیای این تصویر نیز استخراج شده و با نقاط مینوشیای نمونه های داخل پایگاه داده مقایسه می شود تا تعداد نقاط مینوشیا مشترک بدست آید.بدلیل تفاوت در نحوه قرارگیری انگشتان و میزان فشار،تصویر Query و تصویر درون پایگاه داده باید پیش از مقایسه رجیستر شوند.منظور از رجیستر،انطباق 2 تصویر بر روی یکدیگر برای تطبیق جفت مینوشیا های یکسان است.سپس واحد تطبیق تعداد جفت های یکسان دو نمونه را محاسبه می کند.منظور از جفت های یکسان نقاطی هستند که هم محل و هم جهت یکسانی داشته باشند.پس از این مرحله،هویت کاربر از طریق محاسبه امتیاز تطابق و مقایسه آن با میزان آستانه ای که مشخص شده است تشخیص داده می شود.
**استخراج خصوصیات**
با توجه به شکل،به طور کلی استخراج خصوصیات به 3 سطح تقسیم می شود.
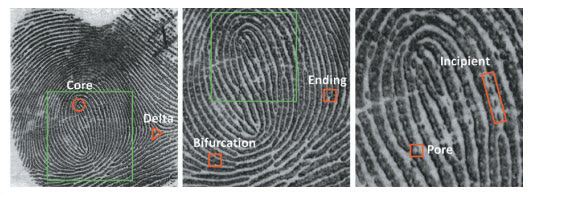
مرحله نخست-شکل چپ،برداشت جزئیات مقیاس بزرگ نظیر شکل جریان خطوط اصطکاکی،الگوی اصلی خطوط و نقاط تکی خواهد بود.مرحله دوم به دو شاخگی[^bifurcation] و انتهای لبه [^Ending Ridge]مربوط است و مرحله سوم شامل تمام خصوصیات ابعادی اثر انگشت مانند ضخامت خطوط،شکل آنها و آثار زخم و بریدگی است.
از خصوصیات به دست آمده در مرجله اول، می توان برای تقسیم بندی آٍثار انگشت به دسته هایی با الگو های فرمیِ کمانی،حلقه ای و یا مارپیچی استفاده کرد.در مورد این الگو ها قبلا توضیح داده شده است.
شکل زیر یک الگوریتم استخراج مینوشیا را نشان می دهد
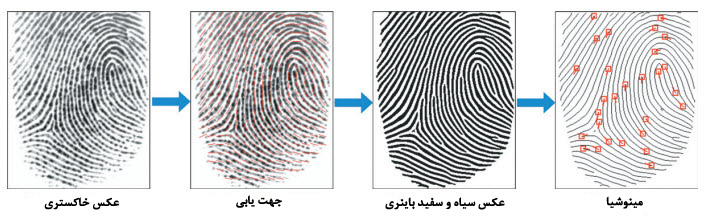
این الگوریتم نخست از روی شکل،جهت خطوط و میزان تکرار آنها را مشخص می کند.و توسط فیلتر براساس زمینه [^contextual filtering] کیفیت را بهبود داده و استخراج خطوط را آسان می کند. پس از بهبود تصویر،اسکلت های اصلی خطوط اصطکاکی استخراج شده و در نهایت الگوریتم برای شناسایی و حذف مینوشیا های اشتباه از یک هیوریستیک استفاده می کند سپس فاز انطباق آغاز می شود .
**مرحله انطباق**
همانطور که توضیح داده شد،در این مرحله امتیازی برای تطبیق دو اثر انگشت محاسبه می شود.یکی از مشکل ترین قسمت های احراز هویت توسط اثر انگشت این قسمت است.زیرا تفاوت های درون کلاسی [^Interclass Variation] که تفاوت بین تصاویر مختلف یک اثر انگشت را نشان می دهد و شباهت های مابین کلاس ها [^Interclass Similarity] در اثر انگشت زیاد است.مثلا میزان فشار انگشت و نحوه قرار گیری و چرخش انگشت بر روی تفاوت های درون کلاسی تاثیر می گذارد همینطور وجود تنها 3 مدل کلی الگو های اثر انگشت(کمانی،حلقه ای و مارپیچ)باعث ایجاد شباهت میان گروه های مختلف می شود.در شکل زیر نحوه چگونگی انطباق توضیح داده شده است:
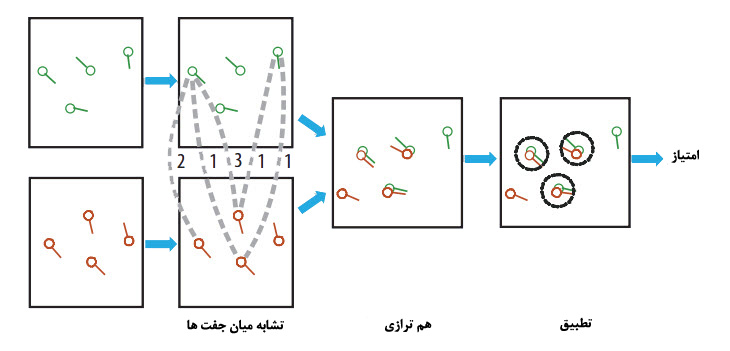
----------
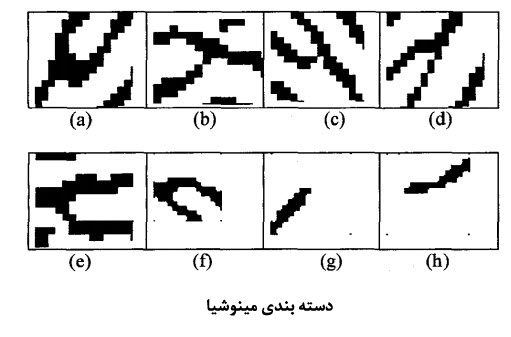
یک روش دیگر برای تشخیص اثر انگشت،استفاده از شبکه های عصبی است[3].در مقاله خانم آرنتس از یک شبکه عصبی Neocognitron برای تشخیص هویت استفاده شده است.همانطور که می دانید استفاده اصلی شبکه عصبی Neocognitron برای تشخیص دستخط است ولی می توان از محاسن این شبکه عصبی برای تشخیص هویت نیز استفاده کرد.در این روش فقط از دو نوع انتهای لبه و دوشاخگی به عنوان مینوشیا استفاده می شود.شکل زیر مثالی از این نوع مینوشیا هاست
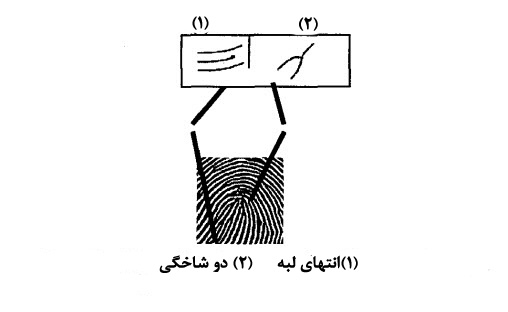
در این روش از 4 فاز زیر برای کلاسبندی مینوشیا استفاده می شود:
1. دریافت عکس[^Image Acquisition]
2. پیش پردازش عکس[^pre-processing]
3. استخراج مینوشیا [^minutiae Extractor]
4. تشخیص مینوشیا [^Minutiae Recognition]
پس از اجرای فاز اول که توسط سنسور ها انجام می پذیرد،نوبت به پیش پردازش عکس می رسد،این مرحله خود در 3 فاز اجرا می شود.شکل زیر نشان دهنده این 3 فاز است :
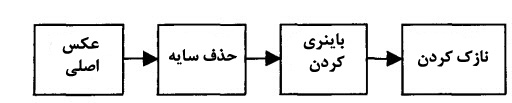
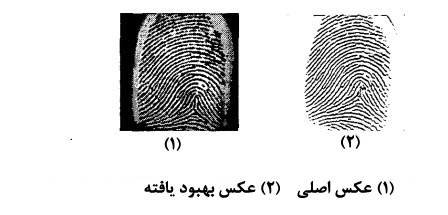
در اولین مرحله،پس از دریافت عکس حذف سایه ها اتفاق میافتد.سپس باینری کردن عکس ها انجام می شود.در این عکس با استفاده از تصویر خاکستری(در این نوع عکس هر پیکسل با عددی بین 0 تا 255 که نشان دهنده میزان خاکستری بودن پیکسل است نمایش داده می شود)،تصویری سیاه سفید(اصطلاحا تصویر باینری)بدست می آید.در این روش با قرار دادن مقدار 0 برای پیکسل هایی با مقدار خاکستری کمتر از 128 و 1 برای مقادیر خاکستری برابر یا بیشتر از 128 عکس خاکستری تبدیل به عکس سیاه سفید می شود.پس از بدست آمدن تصویر باینری،نوبت به نازک کردن[^thinning] لبه ها می رسد.شکل زیر تصویر پس از پیش پردازش را نمایش می دهد:
پس از اتمام پیش پردازش عکس ها،نوبت به استخراج مینوشیا می رسد.در این فاز، یک فضای 15*15 پیکسلی که حاوی یک مینوشیا است به 8 کلاس زیر تقسیم شده است:
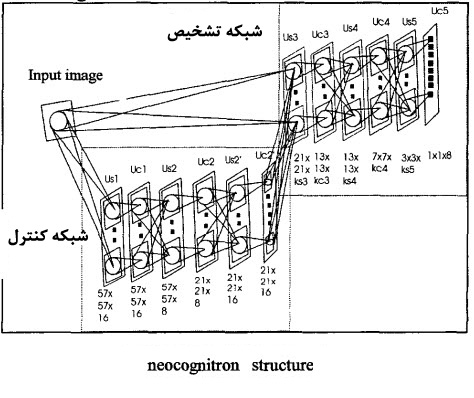
فضای به دست آمده به عنوان ورودی پترن برای نئوکوگنیترون[^Neocognitron] استفاده می شود.لازم به ذکر است که در هر عکس مابین 40 تا 100 مینوشیا موجود است که تعداد آن به کیفیت عکس و سایز سنسور و... مربوط است.سپس نوبت به کلاس بندی می رسد،برای کلاس بندی از 2 شبکه به نام های شبکه کنترل[^Control network] و شبکه شناسایی[^Recognition Network] استفاده می شود.کنترل شبکه از چند مرحله تشکیل داده شده است که هر مرحله وظیفه تشخیص لبه، خط و نقطه پایانی را دارد. در شبکه کنترل به ازای هر کلاس مینوشیا 20 نمونه برای آموزش داده می شود.پس از آموزش، خروجی این شبکه،به عنوان ورودی برای شبکه شناسایی استفاده می شود.شبکه شناسایی از سه لایه تشکیل داده شده است: US3, UC3, US4, UC4, US5, UC5که شماره هر لایه به عنوان حرف سوم لایه بیان شده.پس از آموزش بدون ناظر،سلول های S ویژگی ها را استخراج می کند و سلول های C نتیجه نهایی تشخیص را می دهد.شکل زیر،ساختار این شبکه ها را نمایش می دهد.
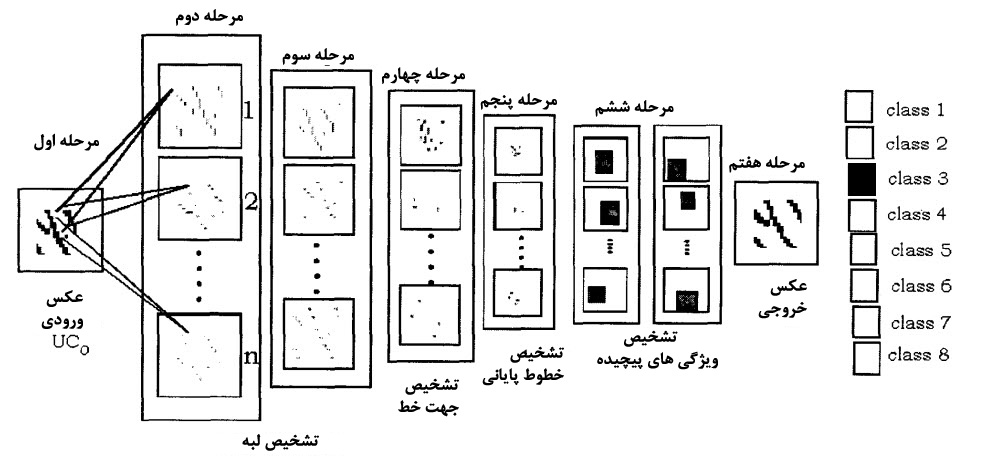
شکل زیر نمای کلی پردازش نکوگنیترون را نمایش می دهد.در مرحله نخست عکس ورودی داده می شود،در مرحله دوم و سوم لبه ها تشخیص داده شده است.در مرحله 4 ،جهت خطوط و در مرحله 5 ،خطوط پایانی تشخیص داده می شود.در مرحله 6 ،ترکیب ویژگی ها شناسایی می شود و در مرحله آخر نیز کلاس مینوشیا مشخص می شود.این روال برای تمام بلوک های 15 در 15 پیکسلی سنسور ها که ابعاد 256 در 256پیکسلی دارند انجام می شود.اگر یک مینوشیا شناسایی شود،موقعیت x,y آن مینوشیا به همراه نوع مینوشیای آن ذخیره می شود.تمام مینوشیا های یک اثر انگشت در یک ساختمان داده ذخیره می شود و از این طریق می توان تشخیص هویت را انجام داد.
این فرآیند زمانبر است.به خصوص اگر سایز سنسور بزرگ باشد.
با توجه با مسائلی که مطرح شد،دو سوال مطرح می شود:
سوال اول- با توجه به اینکه روند تشخیص هویت بر اساس اثر انگشت روندی بسیار طولانی و زمانبری است،اگر تعداد اثر انگشت ها در پایگاه داده زیاد باشد،با روش های عادی هم زمان تشخیص بیش از حد طولانی خواهد شد و هم نیازمند دقت بسیار بالایی هستیم.آقای جین [84]روشی را برای آن ارائه داده است که در زیر به شرح آن خواهیم پرداخت:
در این حالت،به جای استفاده از یک دسته بند [^classifier]از 2 دسته بند استفاده می کنیم.دسته بند اول با سرعت زیاد و با دقت پایین تر عمل می کند.برای این منظور از یک دسته بند KNN[^K Nearest Neighborhood] استفاده می کنیم که در آن k=10 است.به این معنا که توسط 10 نزدیکترین همسایه،دسته بند به ما 2 دسته با بالاترین احتمال را می دهد.طبق مشاهدات به احتمال 85.4% دسته با بیشترین همسایه،دسته واقعی مورد نظر ماست و به احتمال 12.6 % دومین دسته با بیشترین همسایه،دسته واقعی ماست.در نتیجه KNN ما دو دسته که 98% دقت دارند را به ما اعلام می کند.وظیفه دسته بند دوم تشخیص اینکه کدام یک از دو دسته اعلام شده توسط KNN ،دسته درست است را برعهده دارد.دسته بند دوم از نوع شبکه عصبی با یک لایه مخفی 20 نرونی، و 192 نرون ورودی است و 5 نرون خروجی به عنوان 5 کلاس خروجی در نظر گرفته شده است. این روش بر روی پایگاه داده NIST-4 اجرا شده است .دقت 90 درصد برای 5 کلاس و دقت 94.5 درصد برای 4 کلاس به دست آمده است..با این حال،این الگوریتم باز هم نیاز به 10 ثانیه زمان دارد تا بتواند یک اثر انگشت اسکن شده را دسته بندی کند و از این نظر می تواند بهتر شود.
سوال دومی که ممکن است ایجاد شود این است که اگر تصویر اسکن شده اثرانگشتی که نیاز به دسته بندی دارد،کیفیت پایینی داشته باشد یا سنسور کیفیت مناسبی نداشته باشد یا فضای اسکن شده کم باشد چه کار می توان کرد؟
یکی از روش ها استفاده از ویژگی ترکیبی مبتنی بر مشخصه های اصلی [115]است.
در این روش به جای استفاده از مینوشیای اثر انگشت که نسبت به چرخش،خطای اسکنر،مکان قرارگیری انگشت بر روی اسکنر و نویز حساس است یا استفاده از ویژگی های سراسری مثل نقاط منفرد حلقه و دلتا[^delta] که ممکن است در بخش اسکن شده وجود نداشته باشد از ویژگی دیگری استفاده می شود:
روش پیشنهادی بر این اساس است که اگر حداقل قسمتی از تصویر اسکن شده با حداقل نویز باشد،در این قسمت مینوشیا ها را بدست آورده،سپس از تعداد رگه های بین دو مینوشیا و زاویه بین آن دو استفاده کنیم.این ویژگی ترکیبی در شکل زیر نمایش داده شده است:

در این روش اگه تعداد رگه های بین دو مینوشیا برابر RC باشد،RCزاویه خواهیم داشت (در شکل بالا 7 خط مشخص شده است پس 7 زاویه خواهیم داشت)پس به همراه خود مقدار RC تعداد ویژگی های ترکیبی برابر برابر RC+1 است.علاوه بر این مختصات دو مینوشیا نیز نیاز است پس برداری که ما به وسیله آن ویژگی ترکیبی را نشان می دهیم برابر است با:
$${rf}_{ij}=\left[x_i,y_i,x_j,y_j,rc,{\theta{}}_1,{\theta{}}_2,…,{\theta{}}_{rc}\right] $$
حال سوال هایی که باقی می ماند چگونگی تخمین تعداد رگه و چگونگی پیدا کردن زاویه هاست
برای تخمین تعداد رگه بین دو نقطه A و Bاز 2 روش می توان استفاده کرد:
1. تخمین رگه توسط تعیین تعداد انتقال از صفر به یک در تصویر باینری
2. تعیین تعداد ماکسیمم های محلی بین A و B در تصویر خاکستری
در این روش از تصویر اسکلتی که از تصویر باینری به دست می آید استفاده می شود به این صورت که ناحیه بین a و b توسط یک ماسک 5*5 پیکسلی پیمایش می شود
برای تعیین زاویه نیز اگر o نقطه تلاقی رگهAB و خط $m_{1}m{2} $ باشد با توجه به شکل زیر:
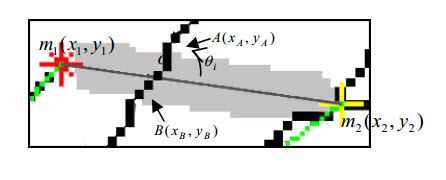
از فرمول زیر استفاده می شود:
$$
{\theta{}}_i=\left\vert{}\{tan}^{-1}{\left(\frac{y_B-y_A}{x_B-x_A}\right)-}\{tan}^{-1}{\left(\frac{y_2-y_1}{x_2-x_1}\right)}\right\vert{}$$
برای تطبیق نیز فقط کافی است پس از هم تراز کردن تصویر نقاط مرجع شناسایی شده و سپس امتیاز شباهت حساب شود.
# آزمایشها
قبل از توضیح در مورد روش پیاده سازی،به معرفی مجموعه دادگان می پردازیم.مجموعه دادگانی که در اینجا استفاده می شود،FVC نام دارد.این دادگان توسط دانشگاه بلونیا ایتالیا تهیه شده است و هر دو سال نسبت به بهبود آن اقدام میگردد.برای تهیه این دادگان،از 10 انگشت و به ازای هر انگشت،هشت اثر انگشت استفاده شده است.این آثار انگشت،توسط حسگر نوری و وضوح بالای 500dpi تهیه شده است.نمونه ای از این دادگان را در شکل زیر مشاهده می کنید.

حال به بیان الگوریتم احراز هویت می پردازیم.
عملیات اولیه پیاده سازی شده،توسط [این شخص](http://www.comp.hkbu.edu.hk/~vincent/resPaper.htm) اجرا شده است.
نمای کلی این برنامه توسط شکل زیر نمایش داده شده است:
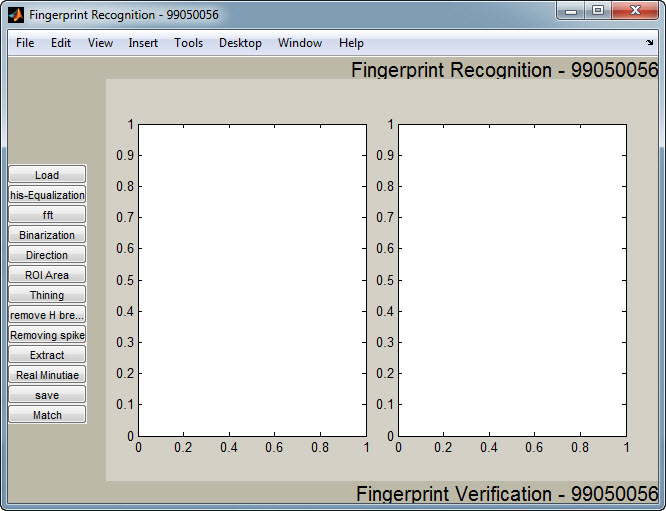
اولین مرحله پس از بارگذاری عکس،پیش پردازش است.این مرحله خود از دو زیر مرحله زیر تشکیل شده است:
1. برابر سازی[^Equalization]
در این مرحله با تبدیل مقادیر کم،به صفر و افزایش مقادیر زیاد باعث افزایش تفاوت(کنتراست)در عکس می شویم که باعث بهبود تشخیص خطوط اصطکاکی نسبت به زمینه سفید عکس می شود.
نویسنده توسط نمودار زیر تفاوت های ایجاد شده توسط این مرحله را نمایش می دهد
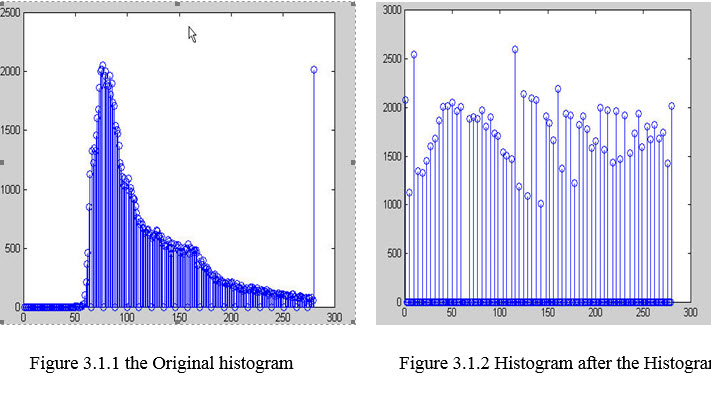
شکل زیر تفاوت عکس قبل و بعد از اجرای این مرحله را نمایش می دهد.

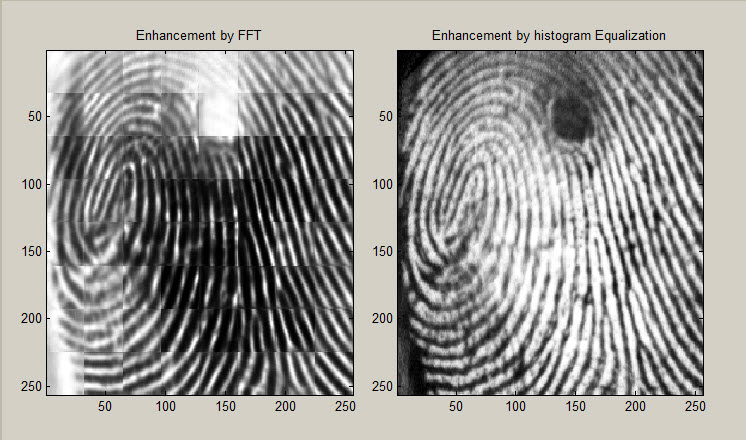
2. تبدیل سریع فوریه[^FTT]
توسط این مرحله،عکس تبدیل به قسمت های 32در32 پیکسلی شده،سپس پردازش بر روی هر قسمت به صورت موازی اجرا می شود.برای بهبود نتایج پردازش،از فرمول زیر استفاده می شود:
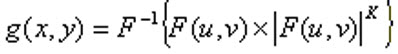
$$g\left(x,y\right)=F^{-1}\left\{F\left(u,v\right)\times {\left|F\left(u,v\right)\right|}^k\right\} $$
مقدار k در بازه مابین صفر تا 1 اختیار می شود که طبق محاسبات تجربی بهترین نتایج با مقدار k=0.45 به دست آمده است.
در شکل زیر تفاوت ایجاد شده پس از اچرای این مرحله در عکس،نمایش داده شده است:
پس از پیش پردازش،نوبت به باینری کردن تصاویر می رسد.در این فاز تصویر را به بلاک های 16در16 پیکسلی تقسیم می کند.سپس مقدار هر پیکسل را با میانگین هر بلاک مقایسه می کند، اگر مقدارپیکسل ،بیشتر از میانگین باشد مقدار آن پیکسل تبدیل به 1 و اگر کمتر باشد مقدار آن پیکسل تبدیل به صفر می شود.شکل زیر تاثیر این قسمت را نمایش می دهد:

پس از باینری کردن،نوبت به بخش بندی تصاویر می رسد.در این قسمت،سعی می شود به نواحی مورد علاقه[^Reign of interest] توجه شود.به این معنا که این نواحی حاویِ رگه شناسایی، و سایر نواحی که فقط حاوی تصویر زمینه[^Back ground] هستند حذف می شوند.این قسمت خود تقسیم به دو زیر مرحله می شود:
1. پیش بینی جهت بلاک
ابتدا یک بلاک wدرw پیکسلی (با مقدار پیش فرض16در16)انتخاب شده و مقادیر گرادیان محور xو y برای آن محاسبه می شود. برای این منظور از دو فیلتر سوبل[^sobel]استفاده می شود.
سپس توسط فرمول زیر،برای هر بلاک،حداقل مربعاتِ جهت بلاک محاسبه می شود:
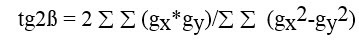
$$tan2β=2∑∑(gx∗gy)/∑∑(gx2−gy2)$$
با محاسبه گرادیان های محور افقی و عمودی،می توان توسط این فرمول زیر،مقدار E را حساب کرد و مقداری که کمتر از حد آستانه هستند را به عنوان تصویر پشت زمینه در نظر گرفته و حذف نمود.شکل زیر،تاثیر این قسمت از پروژه را نمایش می دهد:
2. اجرای عملگرهای مورفولوژیک[^Morphological operations]
این عملگر ها به دو عملگر باز[^open] که وظیفه حذف نویز پشت زمینه و عملگر بسته[^close] که برای یک دست کردن ناحیه استفاده می شود تقسیم می شوند.
پس از بخش بندی تصاویر،استخراج مینوشیا آغاز می شود.مرحله اول در استخراج مینوشیا،نازک سازی تصاویر است برای این منظور عرض خطوط اصطکاکی را تا زمانی که عرض آنها برابر با یک پیکسل شود کم می کنیم.برای این منظور عکس را به بلاک ها 3در3 پیکسلی تقسیم می کنیم.پیکسل های درون این بلاک را بررسی کرده و پیکسلی که نسبت به بقیه پیکسل ها بی ریط باشد را حذف می کنیم(برای درک بهتر می توان گفت پیکسلی که خارجی ترین پیکسل سیاه است حذف می شود)شکل زیر تاثیر این قسمت را بر روی عکس نمایش می دهد:

سپس مینوشیا های استخراج شده را علامت گذاری[^Minutia Marking] می کنیم.برای این منظور،تصویر را به بلاک های 3*3 تقسیم کرده،اگر مقدار نقطه میانی یک و مقدار یک پیکسل دیگر نیز یک باشد،شکل حاصل نقطه پایانی است:
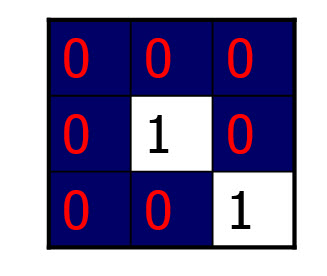
اگر نقطه میانی مقدار یک و دقیقا سه پیکسل دیگر نیز با مقدار یک نیز وجود داشته باشد،شکل حاصل نشانگر دوشاخگی است:
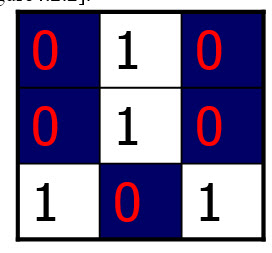
البته این الگوریتم دارای یک نقص است.شکل زیر یک انشعاب را نشان می دهد که طبق الگوریتم بالا سه بار در نظر گرفته می شود:
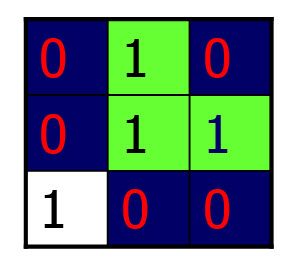
برای رفع نقیصه نیازمند یک تابع بررسی هستیم تا در صورت تشخیص یک انشعاب،بار دیگر آنرا انشعاب جدیدی در نظر نگیرد.
علاوه بر این تابع،فاصله بین دو نقطه پایانی محاسبه می شود.اگر مقدار آن کمتر از مقدار آستانه D باشد،فقط یکی از نقاط به عنوان نقطه انتهایی در نظر گرفته می شود و نقطه دیگر حذف می شود.شکل زیر این کاهش را نمایش می دهد:
در نتیجه توسط این الگوریتم علامت گذاری،تمام نقاط پایانی با یک شناسه منحصر به فرد مشخص می شود.این شناسه توسط تابع BWLABEL به هر کدام از این نقاط اختصاص داده می شود.
نقاط به دست آمده، در یک فایل با پسوند .dat ذخیره می شوند.برای عملیات تطبیق دو اثر انگشت،فایل مربوط به هر اثر انگشت توسط تابع match_end خوانده و با یکدیگر مقایسه می شود.
پس پردازش مینوشیا[^MINUTIA POSTPROCESSING]
پیش پردازش داده ها به تنهایی نمی تواند تمام عیوبی که هنگام ثبت اثر انگشت به وجود آمده است را از بین ببرد.به همین دلیل نیاز به یک پردازش مجزا بعد از یافتن مینوشیای اثر انگشت احساس می شود.این مرحله در دو قسمت اجرا می شود:
1. حذف مینوشیای اشتباه[^false minutiae removal]
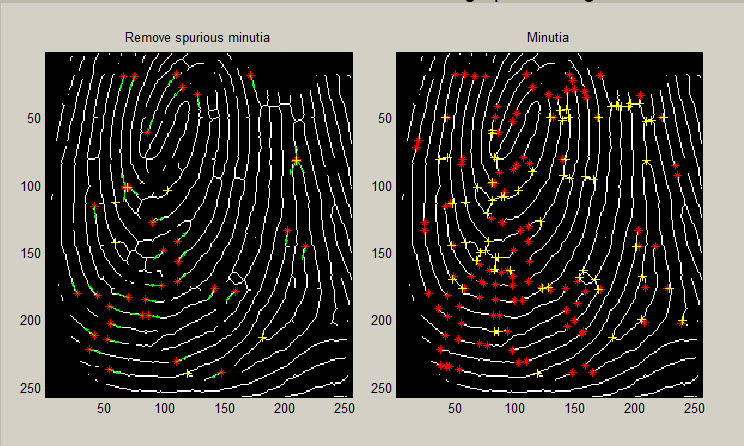
با توجه به اینکه ساز و کار احراز هویت در این پروژه،توسط مینوشیا مشخص می شود.تشخیص و از بین بردن مینوشیا های اشتباه بسیار حیاتی به نظر می رسد.حالات مختلفی می تواند باعث تشخیص اشتباه مینوشیا شود.مثلا ایجاد بریدگی و زخم و...شکل زیر تعدادی از این حالات را مشخص می کند
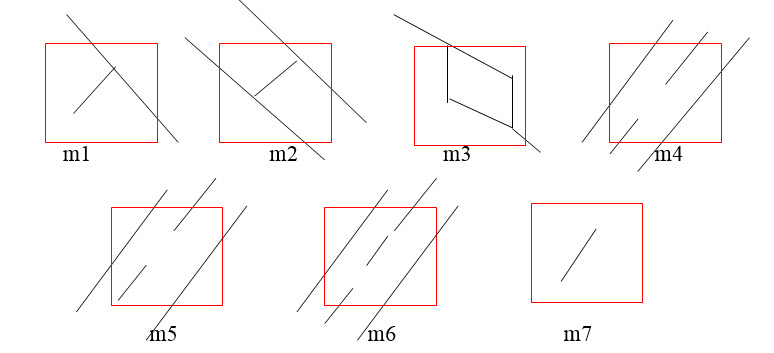
در [126] مدل های m1،m4،m5وm6 شناسایی و حذف می شوند.در [137]و[148] با توجه به بالا بودن کیفیت سنسور ها و آثار انگشت، مینوشیا های اشتباه کم به وجود می آیند و نیاز به تابعی برای حذف آنها احساس نمی شود.
در این پروژه حذف مینوشیا به صورت زیر انجام می شود:
اگر فاصله یک دوشاخگی و یک نقطه پایانی کمتر از مقدار آستانه D بود ،هر دوی آنها در راستای یک رگه هستند و هر دو حذف می شوند.
اگر فاصله دو دوشاخگی کمتر از D باشد و هر دو روی یک لبه قرار داشته باشند هر دو حذف می شوند.
اگر دو نقطه پایانی در فاصله کمتر از D باشند و جهت آنها تقریبا با یکدیگر در یک راستا باشد(همانند m4،m5وm6)مینوشیای به دست آمده به دلیل خراشیدگی یک لبه به وجود آمده و تمام این نقاط حذف می شوند.
اگر فاصله دو مینوشیا کمتر از مقدار D باشد یعنی طول لبه ای که حاوی این دو مینوشیا است کمتر از D باشد،هر دو مینوشیا حذف می شوند.(شکل m7)
2. یکی کردن نقاط پایانی و دو شاخگی[^Unify terminations and bifurcations]
با توجه به اینکه کوچکترین تغییری در وضعیت اثر انگشت یا حسگر ها،نوع مینوشیای تشخیص داده شده را تغییر می دهد،توصیه می شود نقاط پایانی و دوشاخگی با یکدیگر یکی شده و مینوشیا ها توسط مکانشان (x,y) و جهت آنها شناسایی شوند.
بیان این نکته لازم است که محاسبه جهت یک دوشاخگی چالش های خاص خود را دارد که بیان آن در این مطلب ضروری نیست.
انطباق مینوشیا:
آخرین قسمت برای احراز هویت،انطباق مینوشیاهای اثر انگشت با مینوشیاهای آثار انگشت درون پایگاه داده است.انطباق دو اثر انگشت در اینجا توسط تطبیق مینوشیا های تراز شده که از [159] مشتق گرفته،انجام می شود و دو مرحله دارد
1. مرحله تراز کردن
از هر تصویر یک مینوشیا انتخاب می شود و شباهت میان رگه های این مینوشیا با رگه مینوشیای دیگر مقایسه می شود .اگر میزان شباهت از یک حد آستانه بالاتر باشد،این دو مینوشیا منتخب شده و در اصل یکی در نظر گرفته می شوند و دو تصویر توسط این دو مینوشیا تطبیق داده می شوند.منظور از تطبیق تغییر محور مختصات و زاویه های مینوشیای دو عکس است به طوریکه این دو مینوشیای منتخب دو عکس بر روی هم کاملا منطبق شوند.
2. مرحله تطبیق
پس از تراز کردن،از یک عکس یک مینوشیا انتخاب شده و مینوشیای با x,y نزدیک به آن در عکس دیگر نیز انتخاب می شود.اگر زاویه مابین جهت این دو مینوشیا کمتر از یک حد آستانه باشد،این دو مینوشیا یکسان در نظر گرفته می شوند.
سپس نسبت تعداد مینوشیای یکسان را به تعداد کل مینوشیای درون تصاویر بر حسب درصد حساب کرده و آنرا به عنوان امتیاز برمیگرداند.امتیاز حاصل با حد آستانه مقایسه می شود و اگر مقدار آن بالاتر باشد دو اثر انگشت یکی در نظر گرفته می شوند.
کد پیاده سازی در [این پیوند](https://github.com/SaeedTk/Spr_fingerrecognition) قرار داده شده است
# نتایج آزمایش
آزمایشی اولی اجرا شده است،به این صورت است که نمونه اول هر انگشت را با نمونه اول انگشت های دیگر بر روی دادگان FVC2000 مقایسه کرده و نمودارهای زیر به دست آمده است:
نمودار امتیاز صحیح تشخیص داده شده و امتیاز غلط تشخیص داده شده:
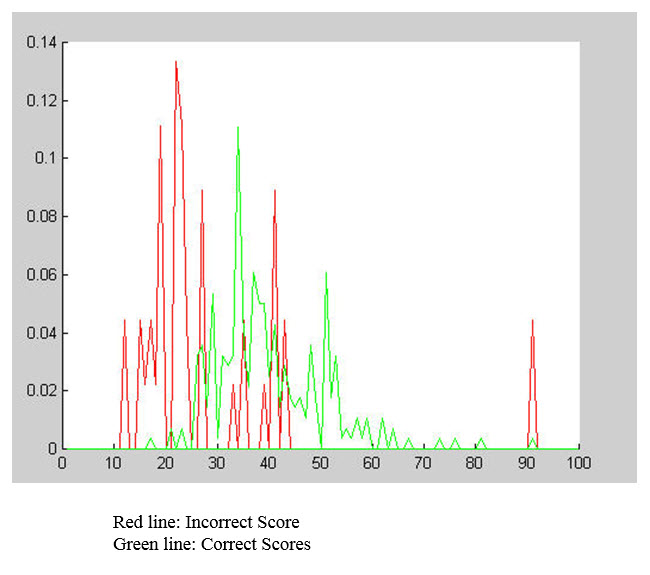
رنگ قرمز نشان می دهد که میانگین امتیازات برای نمونه های نایکسان برابر با 25% است در صورتیکه امتیازات برای نمونه های یکسان به طورمیانگین برابر با 35% است.
نمودار زیر میزان FAR و FRR را نمایش می دهد :
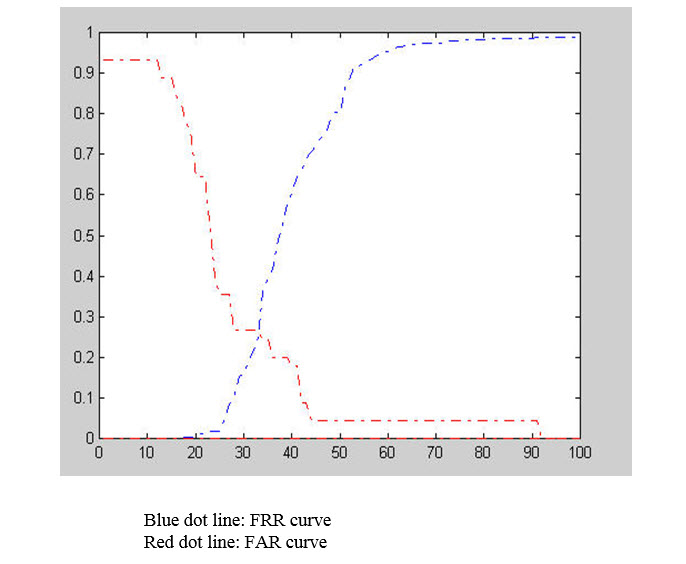
نقاط آبی میزان تشخیص نایکسان اشتباه[^FRR] و نقاط قرمز میزان تشخیص یکسان اشتباه[^FAR] را مشخص می کند.
با توجه به این شکل،اگر حد آستانه امتیاز را برابر با 33% در نظر بگیریم،25% داده ها به اشتباه یکسان تشخیص داده می شوند و 25% داده ها نیز به اشتباه نایکسان تشخیص داده می شوند و میزان verification نیز 75% خواهد بود.
دلیل پایین بودن دقت ها،بیشتر به دلیل کم بودن کیفیت آثار انگشت است.
علاوه بر این آزمایشات،میانگین امتیاز مابین اشیای یک کلاس نیز توسط اینجانب محاسبه شد:
|کلاس ها|میانگین امتیازات|
|:----------|:------------------:|
|کلاس اول |25.27|
|کلاس دوم |27.25|
|کلاس سوم |13.20|
|کلاس چهارم |9.5 |
|کلاس پنجم |6.47 |
|کلاس ششم |5.61 |
|کلاس هفتم| 4.32 |
|کلاس هشتم|4.73 |
|کلاس نهم |3.88 |
|کلاس دهم |2.91 |
همچنین میانگین امتیازات مابین تمام کلاس ها نیز محاسبه شد که مقدار آن برابر با 35% بود و نتایج آزمایش قبلی را تایید می نمود.
همچنین میانگین امتیازات ما بین کلاس های متفاوت نیز محاسبه گردید که بیان آن از حوصله بحث خارج است
----------
# کارهای آینده
# مراجع
[1] Maltoni, Davide, et al. Handbook of fingerprint recognition. springer, 2009.
[2]Anil K. Jain, Jianjiang Feng, Karthik Nandakumar, "Fingerprint Matching", Computer, February 2010
[3]Milene Arantes, Alessandro Noriaki Ide, Jose Hiroki Saito ,"A System For Fingerprint Minutiae Classification And Recognition",November 2002
[4]Tsai-Yang Jea, Venu Govindaraju,"A minutia-based partial fingerprint recognition system"," Pattern Recognition, Vol.38, No. 10, pp. 1672-1684, 2005.
[5]Xudong Jiang*, Wei-Yun Yau, Wee Ser,"Detecting the fingerprint minutiae by adaptive tracing the gray-level ridge",2001.
[6]Alessandro Farina, Zsolt M. Kovacss-vajna,Alberto Leone."Fingerprint minutiae extraction from skeletonized binary images",May 1999.
[7]Andrew K . Hrechak and James A . McHugh,"Automated Fingerprint Recognition Using Structural Matching",November 1989.
[8]Anil K. Jain,Salil Prabhakar, Lin Hong,"A Multichannel Approach to Fingerprint Classification",April 1999 .
[9]Anil K,Lin Hong."A personal Identification system using faces and fingerprints",August 1998 .
[10]D. K. Isenor and S. G. Zakyt."Fingerprint Identification Using Graph Matching",April 1985.
[11]ناصر مزینی،منیره عبدوس"تطبیق بخشی از اثرانگشت با استفاده از ویژگی ترکیبی مبتنی بر مشخصه های اصلی"نشریه علمی پژوهشی انجمن کامپیوتر ایران،1387.
[12]N. Ratha, S. Chen and A.K. Jain, "Adaptive Flow Orientation Based Feature Extraction in Fingerprint Images", Pattern Recognition, Vol. 28, pp. 1657-1672, November 1995.
[13]D.Maio and D. Maltoni. Direct gray-scale minutiae detection in fingerprints. IEEE Trans. Pattern Anal. And Machine Intell., 19(1):27-40, 1997.
[14]Image Systems Engineering Program, Stanford University. Student project By Thomas Yeo, Wee Peng Tay, Ying Yu Tai.
[15.
# نتایج آزمایش
اگر آزمایش را برای تمام داده های FVC2000 انجام دهیم خواهیم داشت:
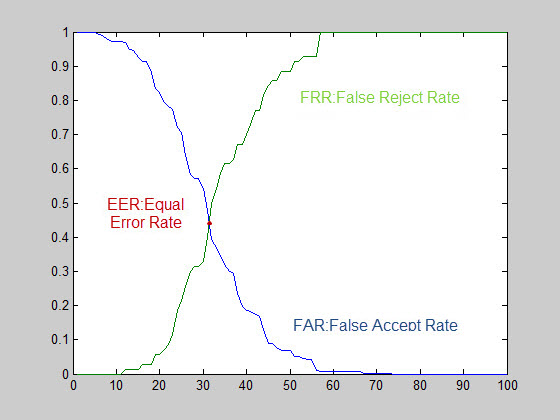
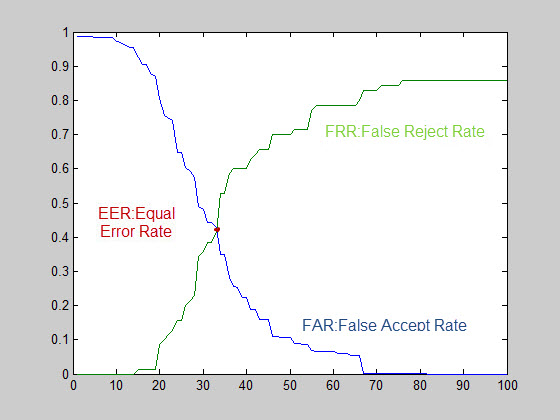
با نظر دستیار استاد محترم،تصمیم گرفته شد علاوه بر دادگان سال 2000،بر روی دادگان سال 2004 نیز آزمایشات انجام و منتشر شود،علاوه بر این،بهبود آزمایشات بر روی دادگان سال 2004 انجام شود. نمودار زیر مربوط به ROC[^relative operating characteristic or reciver operating characteristic] آزمایشات بر روی دادگان 2004 می شود:
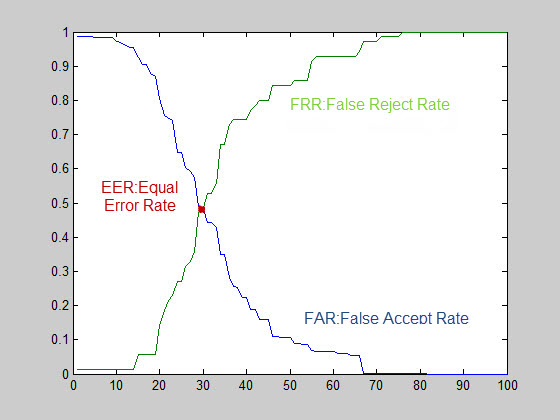
در این نمودار برای بازه آستانه[^threshold] مابین 0 تا 100 ،مقادیر FRR و FAR محاسبه می شود.همانطور که بر روی شکل توضیح داده شده است،خط سبز رنگ تغییرات FRR و خط آبی رنگ FAR را نمایش می دهد.محل برخورد دو خط را EER[^equal error rate] می نامند.این نقطه جایی است که بهترین میزان آستانه(به طوری که مجموع FRR و FAR کمترین باشد) در برنامه مشخص می شود.توضیح این نکته لازم است که بسته به کاربرد احراز هویت و امنیت مورد نظر،ممکن است نقطه ای غیر از EER به عنوان آستانه در نظر گرفته شود که البته بررسی بیشتر در این مورد،خارج از بحث ماست.
برای رسم ROC هر نمونه از اثر انگشت ،با تمام آثار انگشت درون دادگان مقایسه شد،در صورتی که تشخیص یکسان و نمونه ها،نایکسان بود،مقدار مربوط به متغیر FAR یک واحد افزایش و اگر تشخیص نایکسان و نمونه ها،یکسان بود مقدار مربوط به متغیر FRR یک واحد افزایش می یابد.در آخر مقادیر FRR و FAR به تعداد کل دادگان تقسیم می شود تا مقادیر واقعی FAR و FRR که مقداری کمتر از 1 دارند،به دست آید.
در کد ارائه شده تعدادی متغیر استفاده شده است که با توجه به اهمیت بعضی از آنها،توضیح کوتاهی نسبت به آنها ارائه می شود.
متغیر Threshold مقدار آستانه را مشخص می کند که در خارجی ترین حلقه،مقدار 0 تا 100 را می گیرد.
آرایه FARArray مقدار FAR را برای تمام مقادیر Threshold در خود ذخیره می کند به همین دلیل یک آرایه 100 خانه ای است.این مطلب در مورد FRRArray نیز به شکل مشابه صدق می کند.
آرایه GARArray برای ذخیره مقادیر GAR که برای رسم نمودار DET نیاز است استفاده می شود.البته برای کاهش زمان اجرا و به دلیل عدم نیاز به آن،از نمایش نمودار آن صرفه نظر شد ولی کد مربوط به تولید GAR آماده شده است.GAR[^Genuine accept rate] نرخ تشخیص درست یکسان را نمایش می دهد.
**بهبود نتایج:**
به نظر اینجانب،با اضافه کردن الگوهای اصلی اثر انگشت مثل الگوی کمانی، حلقه ای و مارپیچی، به برنامه،کیفیت تشخیص آثار انگشت بسیار بهبود پیدا می کرد که برای این تغییر باید تمام قسمت های دریافت تصاویر، تخمین جهت و استخراج رگه،دودویی کردن،تبدیل به تصویر اسکلتی و بهبود آن،استخراج مینوشیا ،پس پردازش و تطبیق و محاسبه امتیاز مشابهت تغییر می کرد که در این مدت کم عملی نبود ولی می توان آنرا به عنوان کار های آینده ذکر نمود.برای ایجاد بهبود بر روی کد ارائه شده،اول از همه نیاز به بررسی مشکلات کد فعلی داریم.برای اینکار در قدم اول،تصمیم به محاسبه میانگین امتیازات نمونه های مشابه نمودم.دلیل اینکار،بررسی ضعف های برنامه،فارغ از مقدار آستانه بود.در صورتیکه که می خواستیم زمان آستانه را به عنوان پارامتری برای بررسی کد وارد کنیم،علاوه بر اینکه اطلاعات اضافی به ما داده نمی شد،زمان اجرای برنامه بسیار طولانی می شد که در این مرحله منطقی نبود. این آزمایشات بر روی FVC2000 انجام پذیرفت.پس از مشاهده میانگین امتیازات اثر انگشت یک کلاس،شباهت ما بین تمام نمونه ها عدد پایینی بود،که باعث می شد با افزایش آستانه ،مقدار FRR به طور سریعی افزایش یابد.همچنین میانگین امتیازات مابین تمام کلاس ها نیز محاسبه شد که نتایج آزمایش قبلی را تایید می نمود.
پس مشکل اساسی در زمانی بود که دو اثر انگشت واقعا مربوط به یک اثر انگشت بودند ولی برنامه به دلیل امتیاز کمی که بین آن دو بدست می آمد آنها را نایکسان تشخیص می داد.برای حل این مسئله،باید دو قسمت استخراج مینوشیا و محاسبه امتیاز،بررسی و تغییر داده می شد.به جز نقص در امتیاز دهی در ویژگی های اصلی و سراسری که آن هم در اصل مربوط به قسمت تشخیص می شد،عیب خاصی در قسمت امتیاز دهی مشاهده نکردم.حتی نویسنده اصلی،ایده جالبی برای چرخواندن و تراز کردن عکس نیز استفاده کرده بود ولی پس از بررسی مقادیر مینوشیای استخراج یافته شده،متوجه شدم بدلیل اینکه هیچگونه اجماع و همفکری بر روی مینوشیا های استخراج شده وجود نداشت،ممکن بود یک اثر انگشت اولیه نامناسب،بر روی عملکرد برنامه و کارایی تشخیص آثار انگشت درون دادگان تاثیر بگذارد.به همین دلیل بهتر است فازی اضافه شود و در آن فاز از هر انگشت چندین نمونه برداشت شود و بعد از نظر سنجی از تمام نمونه ها،نمونه هایی که تفاوتشان با دیگر نمونه های همان کلاس بسیار زیاد است حذف شود.برای سادگی و افزایش سرعت برنامه،فقط بدترین نمونه را از آموزش حذف شده است،اما توصیه می شود برای دریافت نتیجه بهتر،از روش jury که در آن 20% از بهترین نتایج و 20% از بدترین نتایج حذف می شود،استفاده شود.مطمئنا با روش jury بهبود،بیشتر از نتایج ذکر شده نیز می شود.لذا نیازمند تولید کدی بود که به صورت خودکار و بدون دخالت انسان بدترین نمونه های درون یک کلاس،توسط نظرسنجی میان دیگر نمونه های آن کلاس حذف شود.با اینکار بهبودی در حد 6% حاصل شد.نمودار ROC زیر این بهبود را نمایش می دهد.
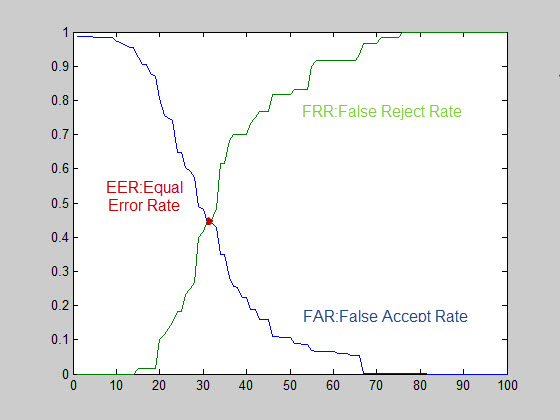
گاهی اوقات،نمونه های کاملا مشابه در نمودار ROC با یکدیگر نیز مقایسه می شوند که در صورتیکه بخواهیم نمودار ROC را با این روش رسم نماییم شکل حاصل به دست می آید که میزان FRR نسبت به حالت اول،نزدیک به 10% می شود.که باعث بهبود 10 درصدی مقدار EER نیز می شود.
# کارهای آینده
همانطور که توضیح داده شد،بزرگترین کمبود این پروژه نبود یک مقایسه گر،برای ویژگی های اصلی است.در صورتیکه می توانستم ویژگی های اصلی و سراسری را نیز در قسمت های استخراج و سایر قسمت ها اضافه کنیم،با اضافه کردن وزنی برای ویژگی های سراسری و وزنی برای ویژگی های محلی،می شد بهترین نتایج را بدست آورد و حتی یادگیری ماشین را برای این قسمت نیز استفاده کرد.همچنین می توانستیم با ترکیب این روش و روش رای گیری،مقدار نتایج را بهبود ببخشیم.
ایده دیگر استخراج چندین نمونه اثر انگشت و ترکیب تمام آنها به عنوان نمونه مرجع است.منظور از ترکیب،اضافه کردن تمام مینوشیا های استخراج شده از نمونه های مختلفِ یک اثر انگشت در یک نمونه مرجع است.در این صورت برای حالات مختلف قرارگیری اثر انگشت، یا در صورتیکه که انگشت فرد دارای زخم سطحی است،نتیجه بهتری به دست می آید.
ایده دیگر،بهبودِ قسمت حذف مینوشیای اشتباه است.در صورتیکه سطح انگشت دارای زخم سطحی باشد،این زخم ممکن است باعث تشخیص انتهای لبه اشتباه شود.برای حل این روش باید متدی برای حذف دو مینوشیای در یک امتداد با فاصله کم اضافه کرد که در [5] توضیحاتی در مورد این روش داده شده است.
ایده دیگر امتیاز دهی بیشتر به مینوشیا های مرکزی است.ممکن است بنا به عدم فشار مناسب و یا عدم زاویه مناسب هنگامِ نمونه برداری اثر انگشت،مینوشیا های اطراف کیفیت مناسبی نداشته باشند،به همین دلیل بهتر است به مینوشیا های مرکزی امتیاز بیشتری داده شود چون اعتبار آنها بیشتر به نظر می رسد.البته تاثیر این روش کمتر از ایده های دیگر است و بررسی مفید بودن آن،نیاز به آزمایش عملی دارد.اما می توان توسط یک ماشین یادگیری بررسی نمود که مینوشیای مرکزی معتبر تر است یا مینوشیای اطراف؟و سپس توسط این ماشین یادگیری نسبت به امتیاز دهی مینوشیا ها اقدام نمود.
# مراجع
[1] Maltoni, Davide, et al. Handbook of fingerprint recognition. springer, 2009.
[2]Anil K. Jain, Jianjiang Feng, Karthik Nandakumar, "Fingerprint Matching", Computer, February 2010
[3]Milene Arantes, Alessandro Noriaki Ide, Jose Hiroki Saito ,"A System For Fingerprint Minutiae Classification And Recognition",November 2002
[4]Anil K. Jain,Salil Prabhakar, Lin Hong,"A Multichannel Approach to Fingerprint Classification",April 1999 .
[5]ناصر مزینی،منیره عبدوس"تطبیق بخشی از اثرانگشت با استفاده از ویژگی ترکیبی مبتنی بر مشخصه های اصلی"نشریه علمی پژوهشی انجمن کامپیوتر ایران،1387.
[6]N. Ratha, S. Chen and A.K. Jain, "Adaptive Flow Orientation Based Feature Extraction in Fingerprint Images", Pattern Recognition, November 1995.
[7]D.Maio and D. Maltoni. Direct gray-scale minutiae detection in fingerprints. IEEE Trans. Pattern Anal. And Machine Intell, 1997.
[8]Image Systems Engineering Program, Stanford University. Student project By Thomas Yeo, Wee Peng Tay, Ying Yu Tai.
[9] Lin Hong. "Automatic Personal Identification Using Fingerprints", Ph.D. Thesis, 1998.
# پیوندهای مفید
+ [Biometric System Laboratory](http://biolab.csr.unibo.it)
+ [Biometrics Research Group](http://biometrics.cse.msu.edu)
+ [FVC Data Set](http://bias.csr.unibo.it/fvc2002/databases.asp)