توضیحات مربوط به صفت در [پروژهی دیگری](http://www.boute.ir/iust-pr-93/attribute-detection) آمده است. در رتبهبندی صفت به جای نگاه صفر و یکی به صفت به آن به صورت یک متغییر نسبی[^Relative] نگاه میکنیم. برای مثال اگر خندان بودن را یک صفت بدانیم، یک فرد میتواند از دیگری خندانتر باشد. برای سادهتر شدن موضوع به شکل زیر توجه کنید:

این نگاه به صفات کاربردهای بسیار زیاد صنعتی دارد. برای مثال میتوان به شلوغ بودن یا نبودن خیابان در مسئله کنترل ترافیک و موارد مشابه اشاره کرد. همچنین از نظر تئوری مسئله بسیار قوی است.
برای انجام این پروژه شما ابتداً باید با روشهای تشخیص صفت آشنا شوید، سپس به مقالهی Relative Attributes مراجعه کرده و آن را پیاده سازی نمایید.
* این پروژه توسط یک بنگاه تجاری تعریف شده است.
# مقدمه
ابتدا لازم است در مورد چرایی استفاده از صفات برای عمل تشخیص، توضیحاتی داده شود و روشهای جدید استفاده از صفات معرفی شود. پس از آن به رتبهبندی صفات میپردازیم.
در چند سال اخیر، روش جدیدی در حوزهی بینایی ماشین مطرح شده است. این روش پیشنهاد میدهد در عملیات تشخیص[^Recognition] به جای نامگذاری [^Naming] از توصیف[^Describing] استفاده نماییم.
استفاده از روش جدید، مزیتهای زیر را دارد:
* گزارش دادن جنبههای غیر معمول یک شیء آشنا. منظور این است که در یک تصویر نه تنها یک سگ را شناسایی کند، خالدار بودن آن را نیز شناسایی کند.
* ذکر صفات اشیاء ناآشنا. برای مثال اگر قبلاً کالسکه جزء اشیایی که میشناسد نباشد، در صورت مشاهدهی آن بتواند بگوید این شی ۴ چرخ دارد.
* شناسایی شیء جدید بدون نمونههای بصری از پیش مشاهده شده یا نمونههای قبلی کم.

کاری که صورت میگیرد این است که به جای شناسایی نوع موجودیت، روی شناسایی صفات تمرکز میکنیم که قابلیت توصیف، مقایسه و دستهبندی راحتتر اشیا –به خصوص شیء جدید- را میدهد.
صفاتی که قابل شناسایی هستند به دو دسته تقسیم میشوند:
* صفات معنایی[^Semantic]
قسمتها. مثلاً دماغ دارد.
شکل. مثلاً استوانهای شکل است.
جنس. مثلاً خزدار است.
* صفات نسبیت[^Descriminative]
دستهبندی صفات به روش قدیمی(استفاده از تمام ویژگیها برای شناسایی اینکه آیا یک شیء صفت مورد نظر را دارد یا نه) قابلیت تعمیم کمی برای صفات بین کلاسی دارد. دلیل این موضوع این است که ویژگیهای بیربط (مثل رنگ در یادگیری شکل) گاهی اوقات برای یادگیری صفات دیگر از مجموعهای از اشیا میتواند مورد استفاده قرار گیرد ولی برای مجموعهای دیگر از اشیا هیچ کمکی نمیکند و چه بسا موجب افزایش خطا شود.
در روش جدید شناسایی صفات این مشکل حل شده است. ابتدا ویژگیهایی که قادر به پیشبینی صفات در یک کلاس هستند را انتخاب میکنیم و فقط از آنها برای تمرین دادن کلاسبند[^Classifier] صفات استفاده میکنیم.
برای مثال برای یادگیری شناساگر خال، ویژگیهایی را انتخاب میکنیم که میتوانند بین سگهای خالدار و بدون خال تمایز قائل شوند، گربههای بیخال و باخال، اسبهای بیخال و باخال و ... . پس فقط از این ویژگیها برای تمرین دادن شناساگر خال بین همهی اشیا استفاده میکنیم.
تجربیات نشان میدهد که روش جدید مبتنی بر صفت فایدههای زیادی دارد. اول اینکه میتوانیم به صورت موثر اشیا را کلاسبندی کنیم. این مزیت زمانی قدرت خود را نشان میدهد که نمونههای تمرین کمی در اختیار باشند. احتمالاً دلیل آن این است که صفات میتوانند بین کلاسهای مختلف به اشتراک گذاشته شوند.
بنابراین کاری که این روش میکند این است که از اشتراک ویژگیها بین کلاسهای مختلف استفاده میکند.
برای مثال اگر بخواهیم کلاسبند «چرخ» را آموزش دهیم، ویژگیهایی را انتخاب میکنیم که در شناسایی ماشینهای چرخدار و بدون چرخ خوب عمل میکنند. به این ترتیب به کلاسبند کمک میکنیم که در مورد ویژگی «فلزی بودن» که در هر دو کلاس موجود است، گیج نشود.
مزیت دیگر روش جدید این است که میتونه حتی بدون استفاده از هیچ گونه مثال تصویری و فقط با استفاده از توصیف متنی اقدام به یادگیری کند.
حال سراغ رتبهبندی صفات می رویم.
پیش از این فقط به شناسایی صفات در تصویر اکتفا میکردیم. حال کاری که میکنیم این است که میزان صفات موجود در تصاویر مختلف را مقایسه میکنیم. برای مثال تشخیص میدهیم که پوست بدن خرس از پوست بدن زرافه خزدار تر است. بنابراین رابطهای بین اشیاء جدید(از قبل دیده نشده) و اشیا از پیش دیده شدهی موجود در DataSet با استفاده از صفات برقرار میکنیم.
همچنین ویژگی دیگر این روش این است که توصیف متنی با جزئیات بیشتری را ارائه میدهد.
در اصل، مشکلی که در شناسایی صفات در تصویر وجود دارد این است که ما فقط در مورد وجود یا عدم وجود یک صفت نظر میدهیم. شاید این روش فقط در مورد صفات مبتنی بر عضویت[^Part-based] مثل «پا دارد» و صفات دودویی[^Binary] مثل «خال دارد یا ندارد» کاربرد داشته باشد ولی در واقعیت ما با طیف گستردهای از صفات روبرو هستیم. برای مثال در مورد خندان بودن یا نبودن یک فرد در تصویر، افراد مختلف نظرات متفاوتی میدهند ولی اگر میزان خندان بودن را در مقایسه با یک تصویر دیگر در نظر بگیریم جوابها یکسانتر و آسانتر خواهد بود.
همچنین این روش، پتانسیل بهبود «یادگیری فعل و انفعالی[^Interactive]» را دارد. برای مثال در جستجوی تصویری، رویهی بهتری را پیشنهاد میدهد. مثلاً به جستجوهای «کفشهای مشابه ولی درخشانتر را برایم پیدا کن» و «عکسهایی از شیکاگو که در روزهای آفتابیتر گرفته شدهاند را برایم پیدا کن».
در رتبهبندی صفت به جای نگاه صفر و یکی به صفت به آن به صورت یک متغییر نسبی[^Relative] نگاه میکنیم. برای مثال اگر خندان بودن را یک صفت بدانیم، یک فرد میتواند از دیگری خندانتر باشد. برای سادهتر شدن موضوع به شکل زیر توجه کنید:  این نگاه به صفات کاربردهای بسیار زیاد صنعتی دارد. برای مثال میتوان به شلوغ بودن یا نبودن خیابان در مسئله کنترل ترافیک و موارد مشابه اشاره کرد.
# مقدمه
ابتدا لازم است در مورد چرایی استفاده از صفات برای عمل تشخیص، توضیحاتی داده شود و روشهای جدید استفاده از صفات معرفی شود. پس از آن به رتبهبندی صفات میپردازیم. همچنین لازم به ذکر است که در تمام این متن، هر جا از کلمهی «ماشین» نام برده شود، منظورمان سیستم هوشمندی است که قرار است عمل رتبهبندی صفات را برای تصاویر مختلف انجام دهد.
در چند سال اخیر، روش جدیدی در حوزهی بینایی ماشین مطرح شده است. این روش پیشنهاد میدهد در عملیات تشخیص اشیاء در تصویر[^Recognition]، به جای نامگذاری [^Naming] از توصیف[^Describing] استفاده نماییم.
استفاده از روش جدید، مزیتهای زیر را دارد:
* ارائه توصیفاتی غیر معمول برای یک شیء آشنا. منظور این است که در یک تصویر، نه تنها یک سگ را شناسایی کند، بلکه خالخالی بودن آن را نیز شناسایی کند.
* ذکر صفات اشیاء ناآشنا. برای مثال اگر در ماشین، کلاسی به نام کالسکه وجود نداشته باشد و اصلاً در مورد این شی به ماشین چیزی یاد نداده باشیم، با این حال در صورت نشان دادن یک عکس کالسکه به ماشین، بگوید که این شی دارای ۴ چرخ است.
* شناسایی شیء جدید بدون نمونههای از پیش مشاهده شده یا نمونههای قبلی کم.

کاری که صورت میگیرد این است که به جای شناسایی نوع موجودیت، روی شناسایی صفات تمرکز میکنیم که قابلیت توصیف، مقایسه و دستهبندی راحتتر اشیا –به خصوص شیء جدید- را میدهد.
صفاتی که قابل شناسایی هستند به دو دسته تقسیم میشوند:
* صفات معنایی[^Semantic]
قسمتها. مثلاً دماغ دارد.
شکل. مثلاً استوانهای شکل است.
جنس. مثلاً خزدار است.
* صفات نسبیت[^Descriminative]
دستهبندی صفات به روش قدیمی(استفاده از تمام ویژگیها برای شناسایی اینکه آیا یک شیء صفت مورد نظر را دارد یا نه) قابلیت تعمیم کمی برای صفات بین کلاسی دارد. دلیل این موضوع این است که ویژگیهای بیربط گاهی اوقات برای یادگیری صفاتی از مجموعهای از اشیا میتواند مورد استفاده قرار گیرد ولی برای مجموعهای دیگر از اشیا هیچ کمکی نمیکند و چه بسا موجب افزایش خطا شود. (مثل استفاده از ویژگی رنگ در یادگیری شکل اشیاء)
در روش جدید شناسایی صفات این مشکل حل شده است. ابتدا ویژگیهایی که قادر به پیشبینی صفات در یک کلاس هستند را انتخاب میکنیم و فقط از آنها برای تمرین دادن ردهبند[^Classifier] صفات استفاده میکنیم.
برای مثال برای یادگیری شناساگر خالخالی بودن، ویژگیهایی را انتخاب میکنیم که میتوانند بین سگهای خالدار و بدون خال تمایز قائل شوند، گربههای بیخال و باخال، اسبهای بیخال و باخال و ... . پس فقط از این ویژگیها برای تمرین دادن شناساگر خالخالی بودن بین همهی اشیا استفاده میکنیم.
تجربیات نشان میدهد که روش جدید مبتنی بر صفت فایدههای زیادی دارد. اول اینکه میتوانیم به صورت موثر اشیا را ردهبندی کنیم. این مزیت زمانی قدرت خود را نشان میدهد که نمونههای تمرین کمی در اختیار باشیم. احتمالاً دلیل آن این است که صفات میتوانند بین کلاسهای مختلف به اشتراک گذاشته شوند.
بنابراین کاری که این روش میکند این است که از اشتراک ویژگیها بین کلاسهای مختلف استفاده میکند.
برای مثال اگر بخواهیم ردهبند «چرخ دار بودن» را آموزش دهیم، ویژگیهایی را انتخاب میکنیم که در شناسایی ماشینهای چرخدار و بدون چرخ خوب عمل میکنند. به این ترتیب به ردهبند کمک میکنیم که در مورد ویژگی «فلزی بودن» که در هر دو کلاس موجود است، گیج نشود.
مزیت دیگر روش جدید این است که میتواند حتی بدون استفاده از هیچ گونه مثال تصویری و فقط با استفاده از توصیف متنی اقدام به یادگیری کند.
حال سراغ بحث اصلی این مقاله یعنی «رتبهبندی صفات» میرویم.
پیش از این فقط به شناسایی صفات در تصویر اکتفا میکردیم. حال کاری که میکنیم این است که میزان صفات موجود در تصاویر مختلف را مقایسه میکنیم. برای مثال تشخیص میدهیم که پوست بدن خرس از پوست بدن زرافه خزدار تر است. بنابراین رابطهای بین اشیاء جدید(از قبل دیده نشده) و اشیا از پیش دیده شدهی موجود در DataSet با استفاده از صفات برقرار میکنیم.
همچنین ویژگی دیگر این روش این است که توصیف متنی با جزئیات بیشتری را ارائه میدهد.
در اصل، مشکلی که در شناسایی صفات در تصویر وجود دارد این است که ما فقط در مورد وجود یا عدم وجود یک صفت نظر میدهیم. شاید این روش فقط در مورد صفات مبتنی بر عضویت[^Part-based] مثل «پا دارد» و صفات دودویی[^Binary] مثل «خال دارد یا ندارد» کاربرد داشته باشد ولی در واقعیت ما با طیف گستردهای از صفات روبرو هستیم. برای مثال در مورد خندان بودن یا نبودن یک فرد در تصویر، افراد مختلف نظرات متفاوتی میدهند ولی اگر میزان خندان بودن را در مقایسه با یک تصویر دیگر در نظر بگیریم جوابها یکسانتر و آسانتر خواهد بود.
همچنین این روش، پتانسیل بهبود «یادگیری تعاملی[^Interactive]» را دارد. برای مثال در جستجوی یک تصویر، رویهی بهتری را پیشنهاد میدهد. مثلاً به جستجوهای «کفشهای مشابه ولی درخشانتر را برایم پیدا کن» و «عکسهایی از شیکاگو که در روزهای آفتابیتر گرفته شدهاند را برایم پیدا کن» میتوان اشاره کرد.
**در ادامه سعی میکنم کاری که در «رتبهبندی صفات» صورت میگیرد را با جزئیات بیشتری توضیح دهم.**
از رتبهبندی صفات در دو زمینه میتوان استفاده کرد:
1. **بهبود ردهبند zero-shot:** اگر بخواهیم به صورت مختصر توضیح دهیم ردهبند zero-shot یک ردهبند چند کلاسه است که زمانی مورد استفاده قرار میگیرد در training set همهی کلاسها معرفی نشده باشند.
2. **ساخت ماشینی که تصاویر را تشریح میکند**: برای مثال اگر ۳ تصویر داشته باشیم، این ماشین میگوید که فرد موجود در تصویر دوم از فرد موجود در تصویر اول جوانتر و از فرد موجود در تصویر سوم پیرتر است.
**روال کار**: برای هر صفت ${ a }_{ m }$، مجموعهای از زوجهای مرتب ${ O }_{ m }=\left\{ \left( i,j \right) \right\} $ و مجموعهای از زوجهای نامرتب ${ S }_{ m }=\left\{ \left( i,j \right) \right\} $ داده شده است که $\left( i,j \right) \in { O }_{ m }\quad \Longrightarrow \quad i\quad >\quad j$ یعنی مقدار صفت ${ a }_{ m }$ در عکس i بیشتر از عکس j است و $\left( i,j \right) \in { S }_{ m }\quad \Longrightarrow \quad i\quad \sim \quad j$ یعنی مقدار صفت ${ a }_{ m }$ در هر دو تصویر i و j یکسان است.
حال کاری که ماشین میکند این است که برای هر کدام از صفات بر اساس مجموعههای مرتب و نامرتب داده شده، یک تابع امتیازدهی ${ r }_{ m }\left( { x }_{ i } \right) ={ w }_{ m }^{ T }{ x }_{ i }$ را پیشنهاد میدهد[^Ranking Function] به صورتی که به بهترین حالت ممکن محدودیتهای زیر را ارضاء کند:
$$\forall \left( i,j \right) \in { O }_{ m }\quad :\quad { w }_{ m }^{ T }{ x }_{ i }>{ w }_{ m }^{ T }{ x }_{ j }$$
$$\forall \left( i,j \right) \in { S }_{ m }\quad :\quad { w }_{ m }^{ T }{ x }_{ i }={ w }_{ m }^{ T }{ x }_{ j }$$
برای اینکه محدودیتهای بالا به بهترین حالت ارضاء شوند، بهینهسازی فرمول زیر با نام max-margin learning to rank برگرفته از [16] پیشهاد شده است. به عبارتی زمانی محدودیتهای بالا به بهترین حالت ارضاء میشوند که فرمول زیر کمترین مقدار را داشته باشد.
$$min\quad \left( \frac { 1 }{ 2 } { \left| \left| { w }_{ m }^{ T } \right| \right| }_{ 2 }^{ 2 }+C\left( \sum { { \xi }_{ ij }^{ 2 } } +\quad \sum { { \Upsilon }_{ ij }^{ 2 } } \right) \right) \\ s.t\quad { w }_{ m }^{ T }\left( { x }_{ i }-{ x }_{ j } \right) \ge 1-{ \xi }_{ ij }^{ },\forall \left( i,j \right) \in { O }_{ m }\\ \left| { w }_{ m }^{ T }\left( { x }_{ i }-{ x }_{ j } \right) \right| \le { \Upsilon }_{ ij },\forall \left( i,j \right) \in S_{ m }\\ { \xi }_{ ij }^{ }\ge 0;\quad { \Upsilon }_{ ij }\ge 0$$
فقط توجه شود که منظور از margin، فاصلهی امتیازی دو نزدیکترین عکس است.
همانطور که در دو عکس زیر نیز مشخص است بردار w ارائه شده توسط روش ما نتیجهی بهتری از بردار w ارائه شده توسط روش SVM ارائه میکند. در روش ما(شکل سمت راست)، منظور از margin، فاصلهی امتیازی دو نزدیکترین عکس است که وقتی نقاط(عکسها) را روی w بدست آمده از این روش عمود میکنیم ترتیب بدست آمده یه ترتیب جزئی از عکسها با توجه هر صفت به ما میده ولی وقتی از SVM استفاده میکنیم هیچ ترتیب جزئیای به ما نمیده(شکل سمت چپ).

حال برویم سراغ دو زمینهای که گفتیم از «رتبهبندی صفات» برای بهبود آنها استفاده شده است:
**ارائه مدل جدیدی از ردهبند zero-shot**:
فرض کنید که در کل N کلاس داریم که برای S تا از آنها نمونههایی(عکسهایی) در training set موجود است و برای U تا از آنها هیچ نمونهای به ماشین داده نشده است.
این S تا کلاس براساس صفات نسبت به یکدیگر توصیف شدهاند.
این U تا کلاس براساس رابطهی بین اون S کلاس توصیف شدهاند.
در ابتدا مجموعهای از صفات نسبی را روی S تا کلاسی که توسط سرپرست فراهم شده است، تمرین میدهیم. کاری که میکنیم این است که یک مدل مولد[^Gaussian](گوسین) را برای هر کدام از S کلاس با استفاده از پاسخهایی که از صفات نسبی برای نمونههای S تا کلاس دریافت کردهایم، می سازیم. به زبان سادهتر، به صورت رندوم از هر کدام از کلاسهای S، تعدادی نمونه را انتخاب میکنیم و مقدار هر صفت برای هر کلاس را میانگین مقادیر این نمونهها در نظر میگیریم. سپس پارامترهای مدل مولد را برای U کلاس با استفاده از توصیفات نسبی که از این U تا کلاس بر اساس S تا کلاس داریم بدست میآوریم. شکل زیر مراحلی که توضیح دادیم را به صورت گرافیکی توضیح داده است.

عکسی که به عنوان تست به ماشین داده میشود که کلاسش هم مشخص نیست، بر اساس روند بالا به کلاسی که بیشترین شباهت را به آن داشته باشد نسبت داده میشود.
**ساخت ماشینی که تصاویر را تشریح میکند**:
برای عکس I تمام توابع امتیاز دهی را اعمال و مقدار خروجی را دریافت میکند. سپس دو عکس را در دو طرف آن به عنوان مرجع انتخاب میکند به صورتی که امتیازشان نه خیلی دور و نه خیلی نزدیک به عکس I باشد. سپس عکس I را با توجه به دو عکس مرجع توصیف میکند. تصویر زیر مراحل بالا را به صورت گرافیکی نمایش میدهد.

همانطور که مشخص است توصیف نسبی عکس بسیار دقیقتر از توصیف باینری آن است.
# کارهای مرتبط
در ابتدا لازم است این نکته را خاطر نشان کنم که ابتدا حضور یا عدم حضور یک صفت در یک تصویر مطرح بود. سپس پیشنهاد شد که به جای تشخیص حضور یا عدم حضور یک صفت، به تشخیص میزان حضور صفت بپردازیم. همانطور که مشخص است رتبهبندی صفات به عنوان شاخهای از شناسایی صفات مطرح است. سعی میکنیم در بخشکارهای مرتبط، کارهایی که در هر دو زمینهی تشخیص و رتبهبندی صفات مطرح شده است را بررسی نماییم. دلیل این کار نیز همپوشانیای است که این دو موضوع دارند.
+ **کلاس ردهبندی صفات و تشابهات برای تطبیق دادن چهره**
برای تطابق چهرهای که به ورودی داده میشود، از سه روش استفاده میکند.
۱) از یک کلاسردهبند دودویی برای تشخیص حضور یا عدم حضور جنبههایی از تصویر که قابل توصیف هستند، میپردازاستفاده میکند. برای مثال در مورد جنسیت، نژاد، سن و ... نظر میدهد.
۲) نیازی به برچسبزنی صفات روی تصاویر ندارد. این روش فقط تشابه چهره یا نقطهی خاصی از چهره را برای نمونههایی که به آن داده میشود یاد می گیرد.
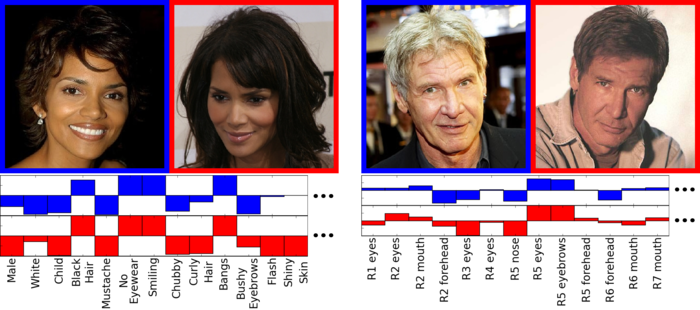
۳) در روش سوم از ترکیبی از دو روش قبلی استفاده میکند که بر اساس آزمایشهای انجام گرفته نتیجهی آن بهتر از دو روش قبلی است.
همانطور که مشخص است ایدههای مطرح شده در اینجا، بیشتر روی حضور یا عدم حضور یک صفت نظر میدهند ولی روش رتبهبندیصفات دقیقتر عمل میکند و خروجی آن نیز اطلاعات بیشتری را در اختیار ما میگذارد.[15,2]
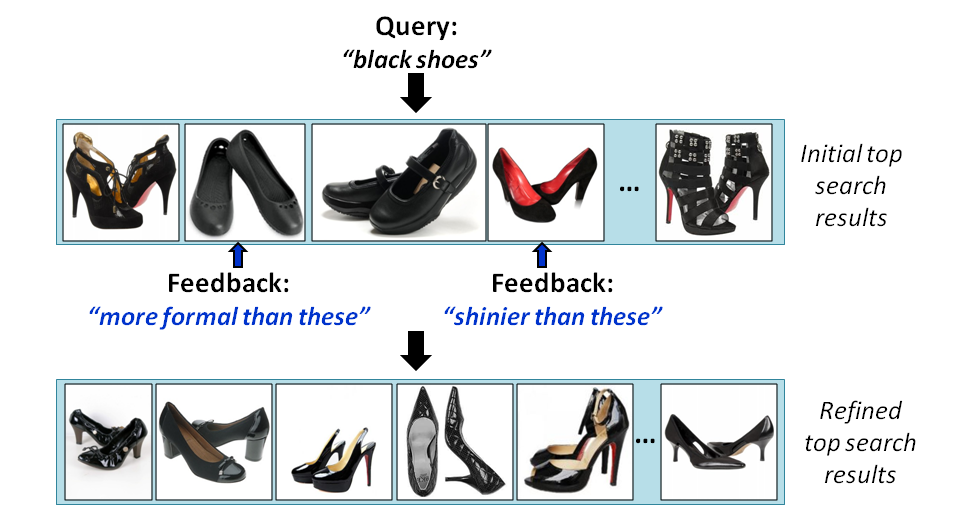
+ **جستجوی ساطوری[^Whittle] : جستجوی تصاویر بر اساس صفات نسبی با کمک بازخورد[^Feedback] **
این روش را با یک مثال توضیح میدهم. فرض کنید که میخواهید در مجموعهای از هزاران عکس به دنبال کفش خاصی که سیاه رنگ است بگردید. این کفش سیاهرنگ شامل ویژگیهایی هست که در ذهن شما است و شما فقط ویژگی سیاه بودن را به جستجوگر میدهید. سیستمماشین بعد از جستجو مجموعهای از کفشهای سیاه را به خروجی میدهد. حال فرض کنید که کفشی که در ذهن شماست براق است. در سیستمماشینهای قدیمی حال شما باید یکی یکی عکسهای موجود در خروجی را بررسی کنید و در مورد براق بودن یا نبودن آنها نظر بدهید که همان سیستم دودویی تشخیص حضور یا عدم حضور صفت است. ولی روش ساطور پیشنهاد میدهد به جای این کار، سیستم مثلا یکی از عکسها را در نظر بگیرید و تمام عکسهایی که میزان براق بودن آنها از عکس مورد نظر کمتر است را از نتیجهی جستجو حذف کند. به همین ترتیب برای ویژگیهای دیگری که در ذهنمان است نیز این کار را ادامه میدهیم تا در نهایت به کفشی که مدنظرمان است برسیم. البته توجه به این نکته در این روش الزامی است که باید ترتیب جزئی صفت «براق بودن» ساخته شود و سپس در مرحلهی جستجو از این ترتیب جزئی استفاده شود. مزیت مهم این روش که در اسم آن نیز نهفته است این است که به مرور ویژگیهای نامربوط را از فضای مسئله حذف میکند.[4]
+ **مقایسه مجموعهای از تصاویر[^setwise] به جای مقایسهی دو تصویر[^pairwise] به عنوان راهکاری برای یادگیری فعال صفات نسبی**
اگر عنوان این روش برایتان گنگ است، نگران نباشید. با توضیحات مختصری پی به نحوهی عملکرد این روش خواهید برد. این روش پیشنهاد میکند به جای اینکه در مورد درجهی حضور یک صفت در یک تصویر در مقایسه با تصویر دیگری نظر بدهیم، مجموعهای از تصاویر را انتخاب کنیم و یک ترتیب جزیی از میزان حضور صفت در این مجموعه بسازیم.
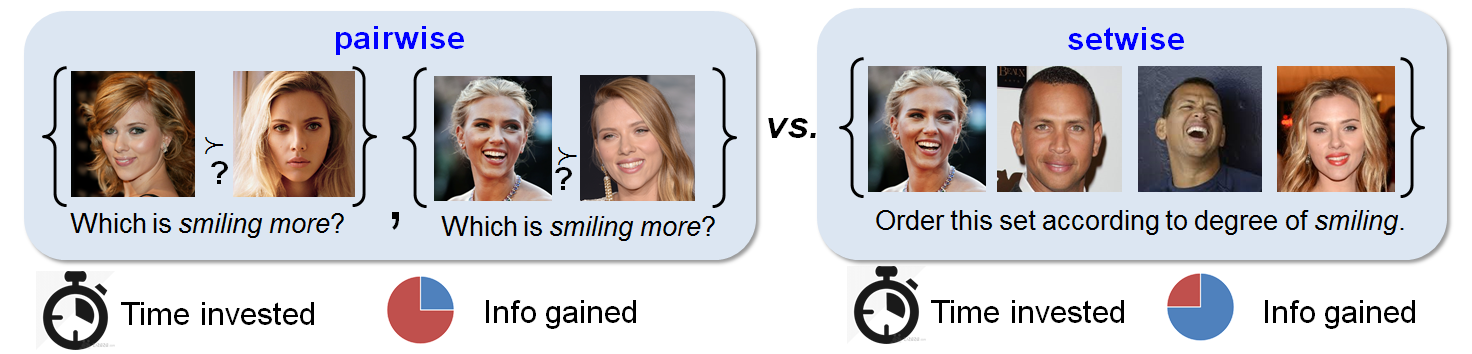
یکی از مزیتهای اصلی این روش کاهش بسیار زیاد هزینه است. برای مثال اگر بخواهیم ۵ عکس را با هم مقایسه کنیم، باید ۲۴ مقایسه صورت گیرد ولی در این روش شاید بتوان با تنها ۴ یا ۵ مقایسه ترتیب جزیی را ایجاد کرد. به این صورت عمل میشود که در «تابع رتبهبند صفات رابطهای» به جای مقایسهی نسبیت یک صفت در دو تصویر، یک ترتیب جزئی[^Partial ordering] از چند تصویر با استفاده از یک صفت مشخص کنیم. این روش عملاً اطلاعات بیشتری را در اختیار ما قرار میدهد.[8]

+ **یادگیری بیناظر صفات تصویری نسبی یا رابطهای**
روش بعدی «یادگیری بیناظر صفات تصویری نسبی یا رابطهای» است. در یک DataSet بزرگ امکان برچسبزنی روی همهی صفات وجود ندارد، بنابراین مجموعهای از تصاویر را به سیستم می دهیم و خود سیستم باید صفات را تشخیص داده و در مورد نسبت هر صفت در یک تصویر با تصویر دیگر اظهار نظر کند.[11]
+ **تعیین میزان حضور یک صفت در تصویر بدون مقایسه با تصاویر دیگر**
یکی از کارهای مرتبط صورت گرفته روشی است که در آن درجهی حضور یک صفت را در تصویر نشان می دهد. این روش یک روش باناظر است که برای هر صفت یک تابع رتبهبند[^Ranking Function] را پیشنهاد میدهد و یک یادگیرندهی zero-shot بهبود یافته را پیشنهاد میدهد.[12]
در نمودارهای زیر چند روش با هم مقایسه شدهاند.

# آزمایشها
# کارهای آینده
# آزمایشها
انجام آزمایشات و مقایسه نتایج روی دو data set صورت گرفته است.
۱- Outdoor Scene Recognition که شامل ۲۶۸۸ عکس از ۸ گونهی مختلف است. ساحل C، جنگل F، بزرگراه H، داخل شهر I، کوه M، دشت O، خیابان S، ساختمان بلند T. برای نمایش دادن عکسها از Gist Features استفاده شده است.
۲- زیرمجموعهای از Public Figures Face Database که شامل ۷۷۲ عکس از ۸ انسان مختلف است.
Alex Rodriguez A, Clive Owen C, Hugh Laurie H, Jared Leto J, Miley Cyrus M, Scarlett Johansson S, Viggo Mortensen V and Zac Efron Z
برای نمایش عکسها از الحاق Gist Features و Color Features استفاده شده است.
شکل زیر این دو data set را بر اساس ویژگیهای دودویی و نسبی نمایش میدهد.

**یادگیری zero-shot:**
روشمان را با دو روش پایه پایه مقایسه میکنیم. روش اول Score-based Relative Attribute یا SRA است. این روش شباهت زیادی به روش ما دارد و تنها تفاوت آن این است که از امتیازات به دست آمده از ردهبند دودویی به جای تابع امتیاز دهی استفاده میکند. دومین روش Direct Attribute Prediction یا DAP است. ما روشمان را با این دو روش و در حالتهای زیر مقایسه خواهیم کرد.
+ متغییر بودن تعداد گونهها یا همان کلاسها
+ متغییر بودن تعداد دادههایی که برای آموزش صفات مورد استفاده قرار میگیرد.
+ متغییر بودن تعداد صفاتی که برای توصیف گونهها یا همان کلاسهای دیده نشده[^Unseen] مورد استفاده قرار میگیرد.
+ متغییر بودن میزان دقت مورد انتظار برای توصیف گونههای دیده نشده
نتایج مقایسه این سه روش و برتری روش ما نسبت به دو روش دیگر به وضوح دی تصاویر زیر مشهود است.

**توصیف تصاویر به صورت خودکار:**
در این جا حاصل آزمایشات روش ما یعنی «توصیفگر نسبی تصاویر» با روش «توصیفگر دودویی تصاویر» مقایسه شده است. ابتدا ۳ تصویر به ماشین میدادیم و توصیفاتی از یکی از این تصاویر را ارائه میکردیم و ماشین باید این ۳ تصویر را بر اساس میزان شباهتشان به توصیفات ارائه شده رتبهبندی کند.
حاصل مقایسه را در زیر مشاهده مینماییدکه به وضوح روش ما دقت بیشتری در پاسخگویی دارد.

کد برنامه که متعلق به دانشجوی دکترای دانشگاه کلمبیا است رو Fork کردم تا در صورت بهبود کد، خود این فرد رو هم مطلع کنم.
[https://github.com/mehrdadscomputer/reproducingcodes/tree/master/CODE/osr_dir](https://github.com/mehrdadscomputer/reproducingcodes/tree/master/CODE/osr_dir)
# کارهای آینده
نکتهای که در مقالهی اصلی نیز به آن اشاره شده است این است که انتخاب دو تصویر مرجع در دو طرف عکس مورد بررسی موضوعی است که جای کار دارد.
در مقالهای که متأسفانه دقیقاً یادم نیست کدوم مقاله بود ذکرشده است که همواره وقتی قرار است مرجعی انتخاب شود، بهتر است این مرجع آنقدر به شی مورد بررسی نزدیک باشد تا طیف کمتری از اشیا امکان ارضاء کردن محدودیتهای ایجاد شده توسط شی مرجع را داشته باشند.
در کدی که لینک آن قرار داده شده است چندین بار پارامترهای مسئله را تغییر دادم تا عکسهایی که به عنوان مرجع انتخاب میشوند تا حد ممکن به عکس مورد بررسی نزدیک باشند تا تعداد کمتری عکس امکان بودن در مجموعهی پاسخها را داشته باشند که البته در همهی حالات با تغییر این پارامترها مقدار دقت برای کلاسهای دیده نشده به سمت صفر میل میکند. احتمالاً این مشکل به خاطر وجود مشکلی در script بیزین است که لازم است برطرف شود.(در تمدید موعد تحویل پروژه).
خروجی پروژه:
These are the category pairs for RankSVM training
4 8
1 8
2 1
6 3
The relative ordering of the attributes for each image
-(Transpose to display in the same oreintation as the means below)
ans =
1 1 7 5 6 4
2 2 5 3 4 4
2 2 6 3 4 4
3 4 4 4 5 4
4 4 2 4 3 1
4 4 1 2 2 3
4 3 3 2 2 2
4 1 3 1 1 4
These are the Actual Means that exist for this test. They should be similar to the ordering above
means(:,:,1) =
-1.0457 -1.7475 0.9519 -0.1995 0.2708 1.2996
means(:,:,2) =
-0.6232 -1.2102 0.4801 -0.8401 -0.2666 1.0982
means(:,:,3) =
-0.5259 -1.2377 0.6644 -1.0962 -0.3298 1.3643
means(:,:,4) =
0.0258 -0.0797 -0.0654 -0.5587 -0.2023 0.5046
means(:,:,5) =
0.3653 0.1073 -0.5150 -0.5435 -0.5415 -0.1318
means(:,:,6) =
0.5547 -0.3563 -0.6381 -1.3314 -0.9781 0.2059
means(:,:,7) =
0.5198 -0.6776 -0.3228 -1.5110 -1.0564 0.1339
means(:,:,8) =
0.5953 -1.8935 -0.1669 -2.2642 -1.6498 1.0797
The unseen classes are
unseen =
5 6
Difference between the actual means and the predicted means for our unseen classes
(:,:,1) =
0 0 0 0 0 0
(:,:,2) =
0 0 0 0 0 0
(:,:,3) =
0 0 0 0 0 0
(:,:,4) =
0 0 0 0 0 0
(:,:,5) =
-0.0113 -0.4222 -0.0627 0.0238 -0.1200 0.0196
(:,:,6) =
-0.2007 0.0415 0.0604 -0.2207 0.0199 0.5108
(:,:,7) =
0 0 0 0 0 0
(:,:,8) =
0 0 0 0 0 0
Accuracy on Unseen Classes
0.3676
Accuracy on all Classes
0.6647
همانطور که مشخص است دقتها در حد قابل قبولی نیستند.
# مراجع
[1] Parikh, Devi, and Kristen Grauman. "Relative attributes." Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011. [لینک](https://filebox.ece.vt.edu/~parikh/Publications/ParikhGrauman_ICCV2011_relative.pdf)
[2] A. Farhadi, I. Endres, D. Hoiem, and D.A. Forsyth, “Describing Objects by their Attributes”, CVPR 2009 [لینک](http://web.engr.illinois.edu/~iendres2/publications/cvpr2009_att.pdf)
[3] Jeff Donahue,Kristen Grauman, “Annotator Rationales for Visual Recognition”, In Proceedings of the International Conference on Computer Vision (ICCV), 2011.
[4] Adriana Kovashka, Devi Parikh, Kristen Grauman, “WhittleSearch: Image Search with Relative Attribute Feedback”, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
[5] Aron Yu, Kristen Grauman, “Fine-Grained Visual Comparisons with Local Learning”, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[6] Lucy Liang, Kristen Grauman, “Active Learning for Image Ranking
Over Relative Visual Attributes”.
[7] Adriana Kovashka, Sudheendra Vijayanarasimhan, Kristen Grauman, “Actively Selecting Annotations Among Objects and Attributes”. In Proceedings of the International Conference on Computer Vision (ICCV), 2011.
[8] Lucy Liang, Kristen Grauman, “Beyond Comparing Image Pairs: Setwise Active Learning for Relative Attributes”. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[9] Sung Ju Hwang, Kristen Grauman, “Accounting for the Relative Importance of
Objects in Image Retrieval”. In bmvc2010.
[10] Devi Parikh, Kristen Grauman, “Interactively Building a Discriminative Vocabulary of Nameable Attributes”. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
[11] Shugao Ma, Stan Sclaroff, Nazli Ikizler-Cinbis, “Unsupervised Learning of Discriminative
Relative Visual Attributes”.
[12] Dinesh Jayaraman, Kristen Grauman, “Zero-Shot Recognition with Unreliable Attributes”. In Proceedings of Advances in Neural Processing Systems (NIPS), 2014.
[13] Devi Parikh, Kristen Grauman, “Interactive Discovery of Task-Specific Nameable Attributes”. In FGVC_CVPR201.
[14] Devi Parikh,Kristen Grauman, “Implied Feedback: Learning Nuances of User Behavior in Image Search”, In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2013.
[15] N. Kumar, A. C. Berg, P. N. Belhumeur and S. K. Nayar. Attribute and Simile
Classifiers for Face Verification. ICCV, 2009