۱. مقدمه
سامانه پیشنهاد فیلم شاخه ای از سامانه های توصیه گر محسوب می شود.سامانه ی توصیه گر سامانه ای است که با بررسی رفتار کاربر خود، مناسب ترین داده را به وی پیشنهاد می نماید. علت اصلی به وجود آمد این سامانه ها افزایش چشمگیر حجم اطلاعات است و کاربر بدون داشتن راهنما به سختی می تواند به اطلاعات یا داده های مطلوب خود دست یابد. اگر به میزان فیلم های تولید شده در سال های اخیر توجه کنیم متوجه می شویم که با پیشرفت صنعت سینما و استقبال مخاطب میزان فیلم های تولیدی به حدی رسیده است که بدون معیاری برای انتخاب فیلم های بهترفرد نمی تواند فیلم های مورد پسند خود را تشخیص داده و انتخاب نماید. در نمودار زیر تعداد فیلم های با کیفیت و مورد پسند مردم در هر سال، از سال 2000 تا کنون که از سایت imdb به دست آمده آورده شده است:

و در مجموع تا کنون 3,523,374 فیلم در این سایت به ثبت رسیده است که این رقم به لزوم وجود سامانه توصیه گر برای پیشنهاد فیلم تاکید میکند.
توصیههایی که از سوی سیستمهای توصیهگر ارائه میشوند به طور کلی میتوانند دو نتیجه در برداشته باشند :
1) کاربر را در اخذ تصمیمی یاری میکنند که مثلاً از میان چندین گزینه پیش رو کدام بهتر است و آن را انتخاب کند و ...
2) موجب افزایش آگاهی کاربر، در زمینه مورد علاقه وی میشود (مثلاً در حین ارائه توصیه به کاربر موجب میشود تا وی با اقلام و اشیاء جدیدی را که قبلاً آنها را نمیشناخته، آشنا شود)
در صورتی که بخواهیم این سامانه را مدل سازی ریاضی کنیم آن را میتوان با این نگاشت همسان دانست و مدل کرد: u : C*S -> R
فرض کنید C مجموعه تمامی کاربران و S مجموعه اقلام در دسترس باشند. تابعی را که میزان مفید و متناسب بودن کالای S برای کاربر C را محاسبه میکند با u نشان میدهیم، که در آن Rمجموعهای است کاملاً مرتب(براساس میزان اهمیت) . هرکدام از عناصر S را میتوان با مجموعهای از خصوصیات، مشخص کرد. در مورد سامانه پیشنهاد فیلم محصولی مثل فیلم را میتوان با مشخصههایی چون عنوان فیلم، کارگردان، طول زمانی فیلم، تاریخ تولید و ... ثبت کرد. همچنین عناصر
مجموعه C را نیز میتوان بر اساس ویژگیهای مثل سن، جنسیت و ... ثبت کرد. (باید توجه داشت که u روی تمام فضای مجموعه آغازین S×C تعریف شده نیست؛ از این رو باید برونیابی شود.)
۲. انواع سامانه های توصیه گر
سامانه های توصیه گر معمولا بر اساس چگونگی تولید توصیه ها، به دسته های زیر طبقه بندی می
شوند:
پالایش مبتنی بر محتوا: به کاربر اقلامی توصیه خواهد شد، که او قبلا آنها را ترجیح داده بود.
پالایش مبتنی بر همکاری: به کاربر اقلامی توصیه خواهد شد که دیگران در گذشته با تمایلات و ترجیحات مشابه او این اقلام را پسندیدند.
پالایش مبتنی بر دانش: متدهای مبتنی بر دانش یا رویکرد پالایش مبتنی بر دانش با استدلال در مورد آن اقلامی که نیازمندی های کاربر را رفع میکنند، توصیه هایی ایجاد میکند.
پالایش مبتنی بر محتوا
در برخی از سیستم های توصیه گر، ممکن است از پالایش مبتنی بر محتوا استفاده شود، که پیشنهادها را بر اساس انتخاب های گذشته ی کاربر، ارائه میدهد (برای مثال اگر کاربر چند فیلم تخیلی را در گذشته پسندیده باشد، سیستم توصیه ممکن است فیلم های تخیلی اخیری را که او تابحال ندیده است، پیشنهاد دهد). همچنین، پالایش محتوا محور، پیشنهادها را با استفاده از محتوای اشیاء در نظر گرفته شده برای پیشنهاد، ارائه می دهد؛ بنابراین، محتوای خاصی ممکن است
تحلیل شود برای مثال برای توصیه فیلم ها به کاربر a ، سیستم توصیه گر محتوا محور سعی میکند تا اشتراکات میان فیلم هایی که کاربر a در گذشته برای آنها رتبه ی بالایی را درنظر گرفته، بفهمد (بازیگران خاص، کارگردانان، ژانر، موضوع و غیره). سپس، تنها فیلم هایی را که دارای میزان بالای شباهت به هر یک از ترجیحات کاربر هستند را توصیه میکند.
بصورت عمومی، مراحل پالایش مبتنی بر محتوا به شرح زیر است:
ایجاد پروفایل های اقلام: برای هر قلم باید پروفایلی ایجاد کنیم که ویژگی های قلم را مشخص میکند. برای تعیین ویژگی های یک سند، از فراوانی کلمه، فراوانی سند معکوس، استفاده میکنیم. فراوانی کلمه، فراوانی سند معکوس هر سند را بصورت یک بردار نشان میدهیم و سپس برای مشابهت، از مشابهت کسینوسی بین دو بردار استفاده میکنیم.
ایجاد پروفایل های کاربر: با داشتن ماتریس نشان دهنده ارتباط هر کاربر با اقلام، میتوان ترجیحات کاربران را استخراج کرد. مثلا اگر در 20% فیلم های مورد علاقه ی کاربری، بازیگر b بازی میکند، سپس پروفایل کاربر دارای 0.2 برای این بازیگر است.
توصیه اقلام به کاربران: محاسبه ی فاصله ی کسینوسی بین بردارهای کاربر و اقلام. با استفاده از تکنیک LSH میتوان پروفایل اقلام را در سطلی (bucket) قرار داد و با استفاده از این تکنیک میتوان تعیین کرد کدام سطل ها دارای اقلام با فاصله کم از کاربر هستند.
پالایش مبتنی بر همکاری
برخلاف متدهای توصیه ی محتوا محور، در سیستم های توصیه گر همکاری محوربهره وری اقلام برای یک کاربر خاص، بر اساس اقلامی که قبلا بوسیله ی کاربران مشابه، رتبه دهی شده، پیش بینی میشود. برای مثال برای توصیه ی فیلم ها به کاربر u ، سیستم توصیه گر همکاری محور سعی میکند تا "نظایر" کاربر u را پیدا کند، برای نمونه، کاربران دیگری که دارای سلایق مشابه در فیلم ها هستند (به همین فیلم ها بصورت مشابه رتبه می دهند). سپس، تنها فیلم هایی که بیشتر مورد پسند نظایر قرار گرفته اند، توصیه میشود.
رویکردهای گوناگونی برای محاسبه ی مشابهت بین دو کاربر در سیستم های توصیه گر همکاری محور استفاده شده است. در بسیاری از این رویکردها، مشابهت بین دو کاربر بر اساس رتبه هایی است که هر دو کاربر به اقلام دادهاند. نتیجه ی اندازه گیری مشابهت، بین +1 , -1 است؛ +1 مشابهت کامل را نشان میدهد و مقادیر مثبت بیانگر وجود شباهت بین دو کاربر است و نتیجه ی منفی، بیانگر عدم مشابهت در امتیازات دو کاربر به اقلام، میباشد. دو رویکرد معروف، ضریب همبستگی پیرسون و رویکرد کسینوسی میباشد s(x,y) را قرار میدهیم مجموعه ی تمام اقلامی که توسط دو کاربر x و y به آنها رتبه ای داده شده است.
ضریب همبستگی پیرسون، از معروفترین رویکردها جهت اندازه گیری مشابهت است:

در رویکرد کسینوسی،با دو کاربر x و y به عنوان دو بردار در فضای m بُعدی رفتار میشود که m تعداد اقلام رتبه دهی شده توسط دو کاربرمورد نظر در پایگاه داده است. این متد با مقایسه ی زاویه ی بین این دو بردار، مشابهت دو کاربر را محاسبه میکند:

متدهای مبتنی بر دانش
متدهای مبتنی بر دانش یا رویکرد پالایش مبتنی بر دانش با استدلال در مورد آن اقلامی که نیازمندی های کاربر را رفع میکنند، توصیه هایی ایجاد میکند دانش از طریق ثبت ترجیحات/انتخاب های کاربر یا از طریق درخواست از کاربر جهت ارائه ی نیازمندی ها، ایجاد میشود. تابع مشابهت، نشاندهنده حدی است که نیازهای کاربر با گزینه های اقلام موجود، مرتبط می باشند. مقدار تابع مشابهت معمولا برای نشان دادن مفید بودن هر توصیه بکار می رود. معمولا زمانی که امکان اعمال پالایش همکاری و محتوا محور وجود ندارد به دلیل، رتبه دار نبودن اقلام، یا مشکل شروع سرد(که در ادامه مقاله با توضیح آن خواهیم پرداخت) از پالایش
مبتنی بر دانش استفاده میشود. در سیستم توصیه فیلم این مشکل وجود ندارد و معمولا از این روش استفاده نمیشود پس به شرح بیشتر این روش بیشتر از این
نمیپردازیم
چالش های اصلی
از اصلی ترین مشکلاتی که سیستم توصیه گر میتواند با آنها مواجه شود به موارد زیر می توان اشاره کرد:
مشکل شروع سرد که از مهمترین مسائل پیش روی سیستم های توصیه گر می باشد، زمانی رخ میدهد که ایجاد توصیه های قابل اعتماد به علت عدم وجود رتبه های اولیه، ممکن نیست. این مشکل در وضعیت هایی نظیر قلم جدید و کاربر جدید به وجود می آید.
مشکل قلم جدید به دلیل اینکه اقلام جدید وارد شده در سیستم توصیه گر معمولا فاقد رتبه های اولیه نیستند، بنابراین سیستم توصیه گر مایل به توصیه ی این اقلام نمیباشد. قلمی که توصیه نشود، توسط جامعه بزرگی از کاربران بی توجه باقی میماند، و بدلیل اینکه آنها از این قلم آگاه نیستند، در نتیجه به این قلم رتبه ای اختصاص نمیدهند. این مشکل تاثیر اندکی بر روی فرآیند توصیه دارد، زیرا میتوان اقلام را به نحو دیگری به کاربران معرفی کرد مثلا تبلیغات فیلم های تازه تولید شده از عواملی است که به جلوگیری از وقوع این مشکل کمک میکند
مشکل کاربر جدید یکی از مشکلات بزرگی است که سیستم های توصیه گر با آن روبرو می باشند. به دلیل اینکه کاربران جدید در سیستم هنوز هیچ امتیاز یا رتبه ای را ارائه نداده اند، این کاربران نمیتوانند پیشنهاد شخصی سازی شده ای را بر اساس متدهای همکاری محور مبتنی بر حافظه دریافت کنند؛ زمانیکه کاربران اولین امتیازات خودشان را وارد میکنند، آنها از سیستم توصیه گر انتظار دارند تا توصیه های مرتبط با علایق خودشان را ارائه دهد، اما معمولا این تعداد امتیاز ارائه شده در سیستم توصیه گر هنوز هم برای ارائه ی توصیه های همکاری محور قابل اعتماد، کافی نمیباشند، و بنابراین کاربران جدید احساس میکنند که سیستم سرویس هایی را که انتظار دارند به آنها ارائه نمیدهد و ممکن است از استفاده از سیستم صرف نظر کنند.
خلوت بودن داده ها : در هر سیستم توصیه گر تعدادی از رتبه هایی که بدست آمده اند در مقایسه با تعداد رتبه هایی که برای پیشبینی نیاز است، بسیار کم
است. پیش بینی موثر رتبه دهیها از موارد با تعداد کم، حائز اهمیت می باشد برای مثال فیلم های بسیاری توسط تنها تعداد کمی از افراد رتبه دهی شده اند و حتی اگر این کاربران اندک، رتبه های بالایی را به این فیلم ها اختصاص داده باشند هنوز هم این فیلم ها به ندرت پیشنهاد خواهند شد. همچنین برای کاربرانی که سلایق آنها در مقایسه با کل جمعیت، غیر معمول باشد، کاربران دیگری وجود ندارند تا شبیه این کاربر باشند که باز هم به پیشنهادهای
ضعیف منجر خواهد شد.
قابلیت مقیاس پذیری : در حالیکه داده ها اکثرا پراکنده هستند، سایت های اصلی شامل چند میلیون کاربر و قلم است. بنابراین توجه به مسائل هزینه ی محاسباتی و جستجوی الگوریتم هایی که نیازمندی های کمی دارند و به آسانی قابل موازی سازی هستند، امری است حیاتی. در واقع راه حل ارائه شده در سیستم های اخیر، پیاده سازی سرویس دهنده و پایگاه های داده بصورت توزیع شده و در بستر ابر میباشد.
۳. کارهای مرتبط
ابتدا به بررسی اجمالی چند سایت برتر که سامانه پیشنهاد فیلم دارند می پردازیم:
Rotten Tomatoes :
به جای این که به این سایت بگویید چه فیلم هایی را دوست دارید می توانید به آن بگویید چه نوع فیلم هایی را دوست دارید یا چه بازیگر هایی را می خواهید در فیلم
ببینید و ملاک هایی از این قبیل برای انتخاب فیلم.
MovieLen :
این سایت طراحی ضعیفی دارد اما الگوریتم پیشرفته ای برای پیشنهاد فیلم دارد که برا اساس فیلم هایی که قبلا کاربر دیده است کار میکند و بعد از این که کاربر به 15 فیلم امتیاز دهی کرد می تواند به کاربر فیلمی مطابق سلیقه اش پیشنهاد دهد.
Fixster :
اینسایت با ظاهری بهتر از movielen و با الگوریتمی مشابه به پیشنهاد فیلم می پردازد. این سایت علاوه بر امکانات سایت movielen امکاناتی از قبیل امکان مشاهده امتیاز دهی سایر کاربران را در اختیار آنها قرار میدهد.
IMDB :
این سایت به جای این که ار کاربر بخواهد به فیلم ها امتیاز بدهند به طور خودکار فیلم هایی با توجه search هایی که انجام داده اید پیشنهاد فیلم میدهد. قسمت recommendations به کاربر می گوید که اگر یک فیلم را دوست داشته است چه فیلم هایی شبیه آن وجود دارد و کاربر احتمالا آنها را هم خواهد پسندید. در واقع بجای بررسی شباهت بین کاربر ها این سایت به بررسی شباهت بین فیلم ها با توجه به اطلاعاتی که از آنها دارد میپردازد. و از این طریق بدون اینکه نیازی باشد کاربر وقت صرف امتیازدهی به فیلم ها کند می تواند فیلم مورد پسند خود را در این سایت پیدا کند
Criticker :
این سایت هم با پیدا کردن همسایه های کاربر و با توجه به امتیاز دهی این همسایه ها به فیلم ها برای هر فیلم امتیازی که کاربر احتمالا به آن فیلم خواهد داد را تخمین میزند. این سایت امکاناتی از قبیل شناسایی 1000 همسایه نزدیک خود و امکان مشاهده پروفایل این افراد را به کاربر میدهد.
Clerkdogs :
به صورت ساده تر و با پیروی از روش IMDB کار میکند به این صورت که نام یک فیلم را کاربر در آن وارد کرده و سایت فیلم های شبیه به آن فیلم ها را پیشنهاد می دهد. سایت های NanoCrowd و Tastekid هر با سیستمی مشابه همین سایت کار میکنند.

همانطور که اشاره شد، criticker.com یکی از سایت های معتبر پیشنهاد فیلم میباشد. به طور کلی می توان گفت این سایت همکاری محور بوده
و بر اساس پیشنهاد سایر کاربران به کاربر هدف فیلم پیشنهاد می دهد. الگوریتم های این سایت مبدا آزمایش های این پروژه خواهد بود به همین دلیل در این بخش به توضیح دقیقتر این الگوریتم ها می پردازیم.
امتیازی که کاربر در این سایت به فیلم میدهد عددی بین صفر و صد است با توجه به این که ممکن است مثلا امتیاز 50 برای یک کاربر امتیازی بالا و برای کاربر دیگری امتیاز پایین محسوب شود، برای حل این مشکل سایت تعداد فیلم هایی که کاربر به آنها امتیاز داده است را به 10 تقسیم کرده و ده بسته فیلم ایجاد می کند و به هر یک از این بسته ها یک عدد از یک تا ده متناظر میکند عدد حاصل از این تناظر با T1 تا T10 نشان داده می شود.
این سایت برای پیشنهاد دهی به کاربر ابتدا میزان اختلاف سلیقه او با همه ی کاربر های موجود در سایت، یعنی 1TCI را محاسبه می نماید، و لیست 1000 کاربر که کمترین TCI را داشته اند
را، به عنوان بهترین TCI ها نگه می دارد (و امکان مشاهده این لیست را به کاربر می دهد) فرض می کنیم این لیست BTCI نام داشته باشد به طوری که [BTCI[ i ][0 برابر با نام iامین همسایه نزدیک به کاربر هدف بوده (TCI کمتر) و [BTCI[ i ][1 مقدار این TCI باشد.
اکنون همانطور که در مقدمه به آن اشاره شد، پس از پیدا کردن همسایه ها نوبت به محاسبه ی یک عدد برای پیشنهاد برای امتیاز دهی به فیلم یعنی PSI2 میرسد. برای این کار سایت criticker اگر فرض کنیم می خواهد امتیازی که کاربر a به فیلم x خواهد داد را حدس بزند، 10 TCI اول (کمتر) a را که به این فیلم امتیاز داده اند را در نظر میگیرد، میانگین T این کاربر ها برای فیلم x را محاسبه می کند ( هر چند به نظر می رسد این روش مشکلاتی دادر چون با میانگین گرفتن
در واقع به اختلاف اهمیت نظر همسایه اول و آخر این 10 کاربر توجه نشده است)
عددی که در اینجا محاسبه شده چون میانگین T هاست، عددی بین یک تا ده است و چون قرار است کاربر از صفر تا صد به فیلم امتیاز دهی کند عدد متناظر با T را با در نظر گرفتن همان ده بسته ی 3T1 تا T10 کاربر محاسبه میکند و به عنوان PSI ارائه می دهد.
علاوه بر این سیستم که بر حسب فیلمی که کاربر می خواهد PSI را محاسبه می کند، در صفحه اصلی سایت با تقسیم بندی بر اساس ژانر تعدادی فیلم به طور random از این ژانر ها را از database خود انتخاب کرده، PSI آنها را محاسبه کرده، و فیلمی که در این میان بیشترین PSI را داشته باشد را در این صفحه به عنوان نماینده ای از این ژانر، پیشنهاد می دهد. این انتخاب random فیلم ها و پیشنهاد از میان آنها سرعت فرایند پیشنهاد فیلم را بالا می برد اما در عوض دقت آن را به شدت کاهش می دهد. این فیلم پیشنهادی که با هر بار refresh کردن صفحه تغییر می کند، دارای PSI ماکزیمم محلی بوده و ممکن است اختلاف زیادی با ماکزیمم کل داشته باشد.
برای تکمیل توضیحات پیرامون روش کار این سایت می توان نکات زیر را مورد توجه قرار داد:
· برای محاسبه ی TCI ابتدا سایت بررسی می کند که حداقل این کاربر به 15% از فیلم هایی که کاربر هدف امتیاز دهی کرده است، امتیاز داده است یا خیر. اگر این گونه نبود، سایت این کاربر را برای محاسبه TCI در نظر نمی گیرد. با این کار دقت پیشنهاد دهی بهبود می یابد و جلوی قضاوت در باره شباهت سلیقه ی دو نفر تنها بر اساس تعداد محدودی امتیاز دهی مشترک گرفته می شود. عدد این درصد (15%) می تواند توسط کاربر در بخش تنظیمات کاربری به 10% الی 30% تغییر پیدا کند.
· هنگام محاسبه PSI ابتدا بررسی می کند که آیا حداقل 10 نفر از 100 TCI کمتر کاربر فیلم مورد نظر را امتیاز دهی کرده اند یا خیر. اگر این امتیاز دهی انجام نشده باشد PSI رامحاسبه نمی کند و به کاربر اعلام میکند اطلاعات کافی برای این محاسبه را ندارد. چون در غیر این صورت نظر کاربرانی مورد توجه قرار میگیرد که اختلاف سلیقه ی نسبتا زیادی با کاربر هدف داشته اند و این باعث کاهش دقت محاسبات می گردد.
در برابر سایت های نسبتا ساده ای مثل citicker سایت های پیشرفته ای مانند netflix وجود دارد که پیشنهاد فیلم تنها یکی از امکانات آن می باشد.
در این سایت الگوریتم های پیچیده ای به صورت همزمان مورد استفاده هستند. اگر تنها بر روی بخش پیشنهاد فیلم آن متمرکز شویم میتوان گفت در این بخش دو الگوریتم اصلی استفاده شده ( RBM Restricted Boltzman Machines) و فرم فاکتورگیری ماتریس استفاده شده است.
به دلیل پیچیدگی الگوریتم ها و عموما در درسترس نبودن آنها از توضیح بیشتر درباره این الگوریتم ها صرف نظر می شود. گستردگی اطلاعات در این سایت دلیل دیگری بر پیچیدگی الگوریتم های آن است. این سایت با وجود حدود 480 کاربر، 18 هزار فیلم و 100 میلیون امتیاز ثبت شده در چند ثانیه توصیه فیلم را انجام می دهد. این سایت در سال 2006 مسابقه ای برگزار کرد و برای کسی که بتواند الگوریتم های این سایت را تنها 10% بهبود بخشد 1 میلیون دلار جایزه در نظر گرفت، این مسابقه تا سال 2008 ادامه داشت. از نکاتی این سایت را از بقیه ی سایت ها متمایز می کند و ما در این مقاله تنها به ذکر این مورد اشاره میکنیم، استفاده از امکان دیگر این سایت یعنی پخش فیلم بای پیشنهاد دهی فیلم است.
در واقع این سایت علاوه بر روش های متداول سیستم های پیشنهاد فیلم از روش های دیگری استفاده میکند که پیچیدگی الگوریتم و دقت نتایج را بالا میبرد. یکی از این تفاوت های که یکی از توسعه دهندگان این سایت در مصاحبه ای درباره ی آن سخن گفت این است که "پیشنهاداتی که این سایت در روز های کاری اول هفته ارائه می دهد کاملا متفاوت با فیلم هایی است که عصر روز های تعطیل ارائه میدهد!"
همانطور که پیشتر اشاره شد این سایت با استفاده از اطلاعاتی که از طریق پخش آنلاین فیلم به دست می آورد نتایج خود را بهبود میدهد. از این اطلاعات می توان به موارد زیر اشاره کرد:
· چه روزی کاربر فیلم را دیده است(به عنوان مثال این سایت متوجه شده است که عموم مردم در طول هفته ترجیح میدهند برانامه های تلویزیونی و در آخر هفته فیلم های سینمایی ببینند)
· کاربر چه زمانی فیلم را با سرعت زیاد دیده است یا از دیدن آن به کلی صرف نظر کرده
· در چه ساعت و تاریخی فیلم ها بیشتر دیده می شوند
· موقعیت جغرافیای کاربر
· با چه دستگاهی فیلم دیده شده است (مثلا اینکه افراد معمولا برنامه های تلویزیون را با گوشی نگاه کرده یا مثلا برنامه های مربوط به کودکان عموما باipad مشاهده می شوند)
و ...
۴. آزمایشها
کد پیاده سازی این بخش در اینجا و dataset استفاده شده در آن در اینجا قرار داده شده است
مجموعه ی داده های استفاده شده در این پروژه از سایت MovieLens گرفته شده است که از اینجا قابل مشاهده می باشد. در بخش اول آزمایش تنها از کوچکترین مجموعه داده استفداه شده است که در آن امتیاز حدود 1000 کاربر به حدود 2000 فیلم ثبت شده است. هدف آزمایش پیشبینی درست امتیازی است که کاربر به فیلم مورد نظر میدهد. نوع پالایش الگوریتم در نظر گرفته شده مبتنی بر همکاری است یعنی امتیاز یا بر اساس امتیاز هایی که سایر کاربران به فیلم داده اند پیشبینی میکند.
برای این پیشبینی امتیاز باید ابتدا همسایگانی که سلیقه ی نزدیک به کاربر مورد نظر دارند را بیابیم. در این الگوریتم نیز مانند سایت criticker عدد متناظر با این تفاوت سلیقه TCI نامیده می شود.
در توضیح نحوه ی محاسبه ی TCI می توان این چنین گفت که اگر فرض کنیم لیست فیلم های مشترکی که دوکاربر(کاربر هدف و کاربری که TCI قرار است برای آن محاسبه شود) تا کنون امتیاز دهی کرده اند CMOV نام داشته باشد به طوری که [CMOV[i][0 امتیاز کاربر هدف به فیلم iام و [CMOV[i][1 امتیاز کاربر دیگر به فیلم باشد، داریم:

برای پیداکردن فیلم های مشترکی که دو کاربر دیده اند استفاده از تابع هش برای کاهش زمان اجرا بسیار موثر واقع شده به طوری که مجموع زمان محاسبه TCI برای همه ی کاربران از 883 ثانیه به 53 ثانیه تغییر پیدا کرد.

سپس در یک لیست جداگانه 100 TCI کمتر هم ذخیره میشوند تا برای محاسبه ی PSI مورد استفاده قرار گیرند. علاوه بر این به یک عدد به عنوان مینیمم تعداد کاربری که باید به فیلم مورد نظر امتیاز داده باشند(از بین صد TCI برتر) نایز است تا بتوان PSI را محاسبه کرد،این عدد را m مینامیم.در غیر این صورت پیغامی مبنی بر ناکافی بودن اطلاعات برگردانده می شود. بدیهی است اگر تعداد امتیاز ها کم باشد احتمال خطا بیشتر است چون بر اساس نظر یک یا دو نفر نمیتوان امتیاز را پیشینی کرد. پس اگر بتوان این عدد را افزایش داد (مثلا تا ده) احتمال خطا کمتر می شود.در آزمایش اولیه به دلیل این که تعداد امتیازدهی ها کافی نیست این مینیمم 3 در نظر گرفته شده است، تا تعداد خطا ی اطلاعات ناکافی افزایش نیابد.
برای محاسبه ی PSI ، ابتدا m امتیاز اولی که توسط نزدیکترین همسایگان ثبت شده اند را در نظر میگیریم و به آنها یک وزن نسبت میدهیم. و PSI حاصل تقسیم مجموع امتیاز ها ضربدر وزن متناظرشان، بر مجموع وزن ها خواهد بود.
به دلیل این که محاسبه ی TCI برای همه ی کاربر ها در ابتدای برنامه، ممکن است بیهوده باشد و برنامه را بی جهت سنگین می نماید، برنامه به نحوی نوشته شده است که برای هر کاربر اولین باری که تابع محاسبه گر PSI را فراخوانی میکند، TCI همه ی کاربر ها برایش محاسبه میگردد. در آزمایش های بعدی امکان به روز رسانی این عدد هم فراهم خواهد شد. تا هر بار پس از وارد کردن تعداد مشخصی امتیاز جدید، این اعداد به روزرسانی شوند.
برای تست برنامه تمام امتیاز های ثبت شده با امیتزی که برنامه تخمین میزند مقایسه می شوند.در روش اول تست درصد جواب های کاملا درست محاسبه میشود. در روش دیگر تست به طور میانگین درصد اختلاف امتیاز کاربر و PSI محاسبه میشود با تغییر m و وزن ها میتوان تغییرات محسوسی در این در صد ها مشاهده کرد به عنوان مثال در شکل زیر سه نمونه از انتخاب های ممکن برای m و وزن ها در نظر گرفته شده است و درصد جواب های پیشبینی شده کاملا درست برای هر کاربر محاسبه شده است.

پس از چندین آزمایش و تغییر ور وزن ها و مقدار m برنامه ای مورد استفاده قرار گرفت که در روش اول تست درصد جواب های کاملا درست آن 58.9 و درصد خطای آن 6.7% میباشد. اما به دلیل 3 در نظر گرفته شدن مقدار m همانطور که پیشتر توضیح داده شد برای مجموعه داده های گسترده تر مناسب نمیباشد.درصد خطا ها برای هرکاربر در این برنامه در نمودار زیر قابل مشاهده می باشد.

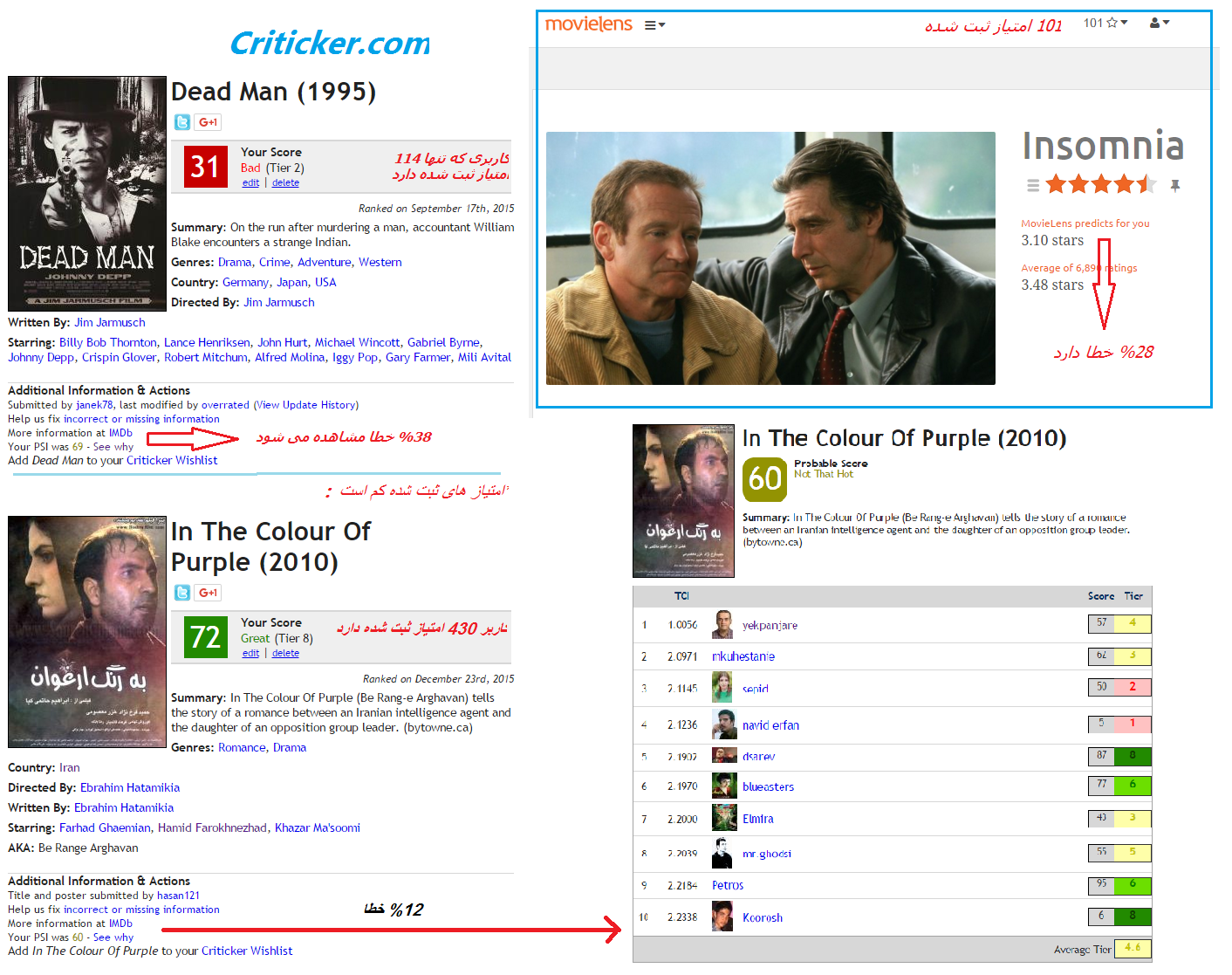
برای کاهش این درصد خطا باید برنامه قادر به پردازش مجموعه داده های گسترده تر باشد زیرا هر چه اامتیاز های ثبت شده ی یک کاربر بیشتر باشد بیشتر میتوان سلیقه ی کاربر را شناخت و همسایه های مناسب تری برای آن پیدا کرد تا بتوان مقدار PSI را دقیقتر حساب کرد.با این وجود حتی برای مجموعه داده های وسیع تر هم باز برای کاربرانی که تعداد فیلم کمی را امتیاز دهی کرده اند خطا وجود دارد. همچنین برای فیلم هایی که تعداد امتیاز های ثبت شده برای آن کم باشد،امکان مواجه با خطای کافی نبودن اطلاعات، یا درصد بالایی از خطا (به دلیل فاصله ی همسایگانی که امتیاز دهی کرده اند)زیاد میباشد. نمونه ای از این مشکلات در سایت های criticker و movieLens در شکل زیر قابل مشاهده می باشد.
۵. کارهای آینده
۶. مراجع
[1] M. Satyanarayanan, "Pervasive Computing: Vision and Challenges," Personal Communications, IEEE, 2001.
[2] M. Weiser, "The Computer for the 21st Century," Scientific American, pp. 94-104 , 1991.
[3] B. Schilit, N. Adams and R. Want, "Context-Aware Computing Applications," in Mobile Computing Systems and Applications, Workshop on, Santa Cruz, CA, 1994.
[4] Burke, R. The Wasabi Personal Shopper: A Case-Based Recommender System. In Proceedings of the 11th National Conference on Innovative Applications of Artificial Intelligence, pages 844-849. AAAI, 1999.
[5] Marko Balabanovic , Yoav Shoham .Content-based, collaborative recommendation (1997)
[6] P. Resnick and H. R. Varian, "Recommender systems," Communications of the ACM, vol. 40, no. 3, 1997 .
[7] G. Adomavicius and A. Tuzhilin, "Context-Aware Recommender Systems," in Recommender Systems Handbook, Springer, 2011, pp. 217-253.
Taste Compatibility Index
Probable Score Indicator
Tier