یادگیری تقویتی روشی است که در آن عامل با در نظر گرفتن حالت محیط، از بین همه اعمال ممکن یکی را انتخاب می کند و محیط در ازای انجام آن عمل، یک سیگنال عددی به نام پاداش به عامل باز می گرداند. هدف عامل این است که از طریق سعی و خطا سیاستی را بیابد که با دنبال کردن آن به بیشترین پاداش ممکن برسد. در این پروژه سعی داریم به یک عامل یاد بدهیم چگونه مواد مورد نیاز برای درست کردن یک کیک را با استفاده از یادگیری تقویتی جمع آوری کند. محیط به صورت یک ماز است که یک هیولا در آن وجود دارد و در یک سری از خانه ها چاله وجود دارد که مانع عامل ما هستند. عامل باید سه ماده آرد، شکر و تخم مرغ را در کوتاهترین زمان جمع آوری کند بدون آنکه هیولا او را بگیرد.  # مقدمه یادگیری تقویتی دیدگاه نوینی در یادگیری ماشین است که در آن به جای افزودن اطلاعات هنگام پیاده سازی از محیط عامل خود با تجربه کردن محیط کشف میکند که چه عملی در چه حالتی بیشترین پاداش را دارا می باشد مهم ترین شاخصه های یادگیری تقویتی آن است که کاوش بر مبنای آزمون و خطا می باشد و بیشینه پاداش در انتهای فرآیند در اختیار عامل قرار دارد [2]  معمولا برای یادگیری تقویتی محیط را مارکوف تصور می کنیم این خاصیت برای محیط به ازای هر حالت s و پاداش r در زمان t+1 به صورت زیر تعریف می شود  بر اساس این تعریف هر پاداش به ازای هر حالت در محیط محدود به وضعیت عامل در تنها یک حالت قبل یعنی t می باشد و وضعیت سایر حالات از 0 تا t-1 اگر ما در t+1 باشیم در نظر گرفته نمی شود   در مسایلی که با یادگیری تقویتی سروکار داریم هدف این است که عامل به بیشینه پاداش دست یابد  برای حل مسئله درست کردن کیک باید عامل بتواند چاله و مواد اولیه کیک را تشخیص بدهد در ازای دریافت مواد اولیه پاداش مثبت دریافت کند و در ازای ورود به چاله پاداش منفی دریافت کند (هزینه بپردازد) در هر حرکت باید تشخیص بدهد که در چهار طرفش هیولا وجود نداشته باشد با حفظ کلیت مسئله فرض میکنیم هیولا در خانه ی تصادفی ثابت است و از زمان 0 تا t در همان خانه می ماند بر این اساس ما از دو الگوریتم سارسا و یادگیری کیو استفاده می کنیم   # کارهای مرتبط # آزمایشها محیط آزمایش شامل یک ماز با 16 خانه می باشد که عامل باید با پیمایش ماز 3 آیتم شامل مواد اولیه ساختن کیک را به ترتیب جمع آوری کرده وبه خانه شروع برگردد عامل نباید وارد خانه هایی با علامت X شود همچنین یک عامل منفی (دشمن) در ماز وجود دارد که با جمع آوری اهداف به ماز اضافه شده به صورت تصادفی در جهت های مختلف حرکت میکند عامل باید یک خانه قبل از رسیدن به دشمن جهت حرکت آنرا حدس بزند و جهت مناسب را پیا کرده تارسیدن به خانه شروع S این فرآیند را تکرار کند. محیط آزمایش به صورت زیر ساده سازی شده است: 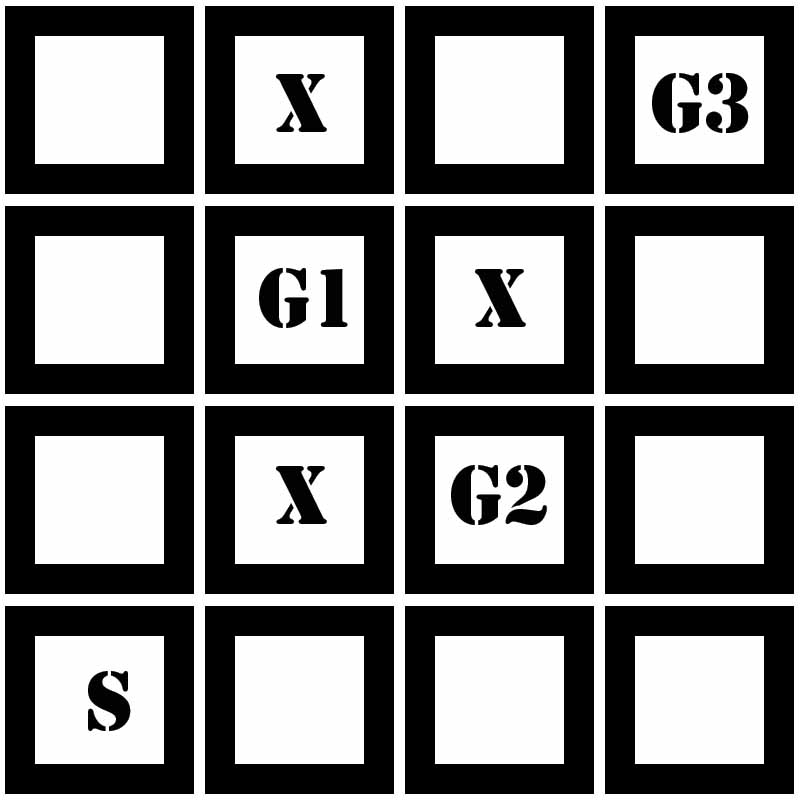 برای انجام آزمایش ها ما برمبنای اجرای الگوریتم های یادگیری کیو و سارسا در اپیزود های مختلف عمل کرده و امتیازی در یافتی را نسب به اجرای هر اپیزود مقایسه میکنیم و بر اساس آن نتایج را گزارش می نماییم در ضمن پیاده سازی صورت گرفته برای جمع آوری آیتم ها می باشد **الگوریتم سارسا** پیاده سازی این الگوریتم در لینک زیرآمده است: [Sarsa.java](https://github.com/mhaji93/reinforcement-learning/blob/master/Sarsa.java) روش سارسا به این صورت عمل می کند که یک تابع کاهشی در نظر گرفته میشود **(( Τ = 1000 * (1.05 ^ (-ep/60** که بر اساس آن** پارامتر τ** را تعریف می کنیم این پارامتر یک** هیوریستیک** به ما می دهد تا در اجرای هر اپیزود عامل به بیشترین پاداش دست یابد ep همان تعداد اپیزود ها استجدول زیر نتایج جدول زیر مقادیر مورد توجه پارامتر τ را که از تابع T بدست آمده را مشخص میکند  حاصل از اجرای Sarsa.java را روی ماز مورد آزمایش نشان می دهد 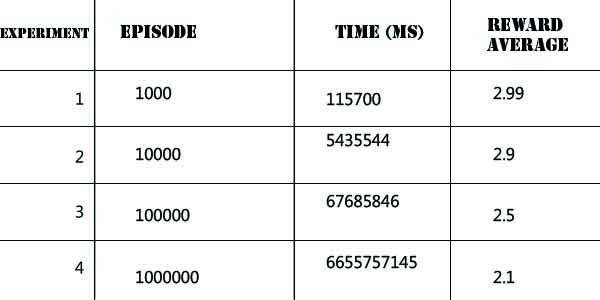 **الگوریتم یادگیری کیو** پیاده سازی این الگوریتم بر مبنای سیاست بولتزمن در لینک زیر آمده است [QLearning.java](https://github.com/mhaji93/reinforcement-learning/blob/master/QLearning.java) جدول زیر نتایج حاصل از اجرای QLearning.java را روی ماز مورد آزمایش نشان می دهد 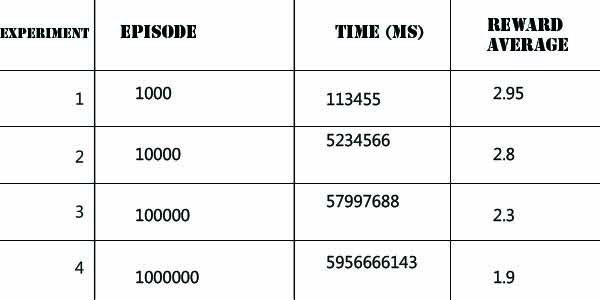 # کارهای آینده # مراجع [1] محمد غضنفری، "بهبود عملکرد عامل شبیهسازی فوتبال دوبعدی با استفاده از یادگیری تقویتی "، پایاننامه کارشناسی، دانشگاه علم و صنعت ایران، ۱۳۹2. [دریافت](https://www.dropbox.com/s/2elzbgh9qnym476/Performance%20Improvement%20of%20a%202D%20Soccer%20Simulation%20agent%20using%20Rainforcement%20Learning.pdf) [2] R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. Cambridge, United States of America: MIT Press, 1998. **پیوندهای مفید** + [یک نمونه استفاده از این مسئله برای پیادهسازی روش سارسا و یادگیری کیو](https://www.dropbox.com/s/zi1p2jkgohjhv5b/TD_Sarsa.pdf) + [یک نمونه استفاده از این مسئله برای پیادهسازی روش value iteration و policy iteration ](https://www.dropbox.com/s/6c5q3lbppa8qaag/Value_Iteration.pdf) + [Reinforcement learning](http://en.wikipedia.org/wiki/Reinforcement_learning)