در مدلسازی موضوعی، فرض میکنیم که مجموعه متون ورودی از روی چند موضوع نامعلوم ساخته شدهاند و باید این موضوعات را پیدا کنیم. هر موضوع یک توزیع احتمال نامعلوم روی واژهها است و هر متن توزیع احتمالی روی موضوعها.
در این پروژه شما باید بعد از فهمیدن فرایند مدلسازی موضوعی، تلاش کنید موضوعات بیانشده را برای آیات قرآن پیدا کنید. دادههای ورودی شما ظاهر آیات به همراه ترجمه و تفسیر آنها هستند.
۱. مقدمه
همان طور که اطلاعات در دنیای امروز در حال زیاد شدن است پیدا کردن موضوعی که ما به آن نیاز داریم نیز سخت تر میشود. پس ما برای ساماندهی ، جستجو و فهمیدن این اطلاعات وسیع نیاز به ابزاری مناسب داریم.
مدل سازی موضوعی یک سری روش است که به طور اتوماتیک ساماندهی ، فهمیدن ، جستجوکردن و خلاصه کردن مقالات الکترونیکی را انجام می دهند.
درواقع سه وظیفه ی اصلی آن ها عبارتند از:
پیدا کردن موضوعات نامعلوم که در مجموعه اسناد وجود دارند.(شایع هستند)
تفسیر کردن اسناد بر اساس موضوعات آن ها .
استفاده کردن از این تفاسیر برای سازمان دهی کردن ، خلاصه کردن و جستجو کردن متن ها.
ما در این پروژه قصد داریم بر اساس الگوریتم (LDA) مدل سازی موضوعی را انجام دهیم.حال کمی به توضیح مبانی این روش می پردازیم:
هر موضوع توزیعی روی کلمات است.
هر سند ترکیبی از موضوعات کل اسناد است.
هر کلمه از یک موضوع گرفته شده است.
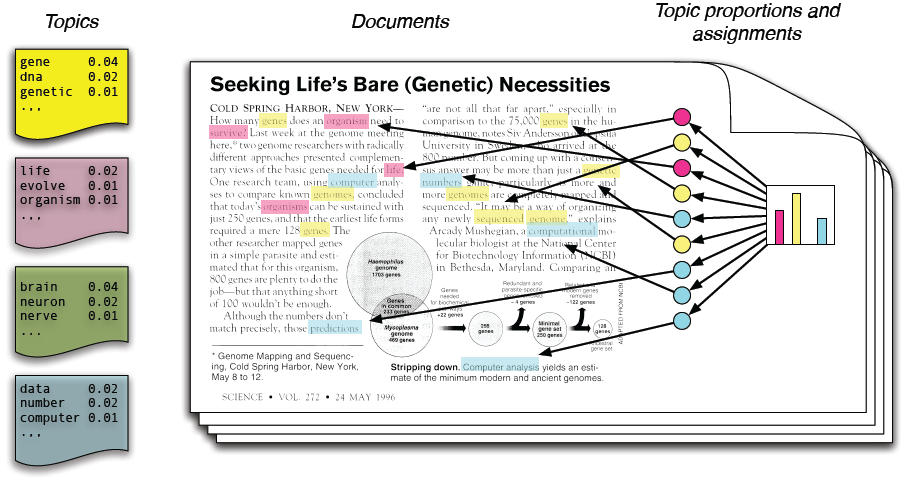
در واقع ما فقط اسناد را می بینیم و دیگر ساختار ها ساختار های نامعلوم هستند.
هدف ما حدس زدن این ساختار های نامعلوم است.
LDA به صورت یک مدل گرافیکی:
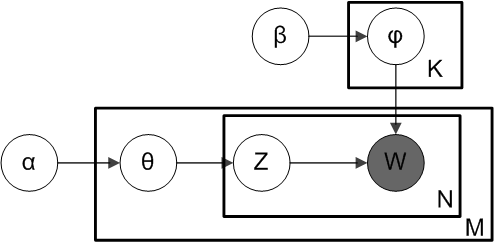
که در این مدل :
w=کلمات مشاهده شده
\theta= نسبت فراوانی موضوعات برای هر سند
\alpha= پارامتر نسبت ها
Z= موضوع اختصاص داده شده برای هر کلمه
\phi= موضوعات
\beta= پارامتر موضوع
و این هم یک فرمول ریاضی برای محاسبه ی LDA:
به علاوه در مورد مدل LDA دانستن موارد ذیل مفید است:
LDA یک مدل احتمالی از متن است. این مدل مساله پیدا کردن موضوعات در مجموعه ای بزرگ از اسناد را به مساله استنتاج قبلی (posterior inferecne problem) محدود می کند.
این مدل به ما اجازه میدهد تا در یک مجموعه اسناد بزرگ و حجیم ساختار موضوعی نامعلومی را تصور کنیم و همچنین اطلاعاتی جدید را که برای این ساختار مناسب هستند را تولید کنیم.
در ضمن این مدل محاسبات ریاضی و احتمالی دارد که از آوردن آنها در این جا صرف نظر می کنیم ولی در صورت نیاز میتوانید روی این مقاله کلیک کنید.
۲. کارهای مرتبط
خلاصه ای از روش پیاده سازی :
ما ابتدا باید با استفاده از ابزاری ، زبان های فارسی و عربی را در زبان برنامه نویسی مورد نظر که احتمالا پایتون است ، پردازش کنیم. سپس با استفاده از کتابخانه gensim که ابزازی برای مدل سازی موضوعی است متن قرآن را مدل سازی موضوعی کنیم.در حقیقت ما LDA را پیاده سازی نمیکنیم بلکه library آن در زبان پایتون به نام gensim وجود دارد و ما برای انجام پروژه از آن استفاده می کنیم.یکی از کارهای انجام شده در مورد مدل سازی موضوعی مرورگری برای ۱۰۰۰۰۰ مقاله سایت ویکی پدیا است که از TMVE استفاده میکند. بعد باید با استفاده از ابزارTMVE برای این مدل سازی یک مرورگر بنویسیم.در واقع کار ما از این مرورگر ایده میگیرد . که می خواهیم این مرورگر ویژگی های گفته شده در ذیل را داشته باشد:
بتواند موضوعات را به ترتیب تکرار بیشتر زیر هم مرتب کند
روی هر موضوعی کلیک می شود کلمات پر تکرار آن موضوع ، موضوعات مرتبط با آن موضوع و همچنین اسناد مربوطه را نشان دهد و به همین ترتیب اگر روی اسناد کلیک شد متن سند را نشان دهد. در این جا منظور از سند میتواند یک سوره یا یک صفحه از قرآن باشد.
در هر موضوع مشخص باشد که چه کلماتی با چه درصد هایی وجود دارند.
یک صفحه از مرورگر شامل تمام موضوعات با ۵ کلمه پر تکرار آن ها باشد.
صفحه ای دیگر شامل همه ی کلمات به ترتیب تکرار آنها در کل قرآن باشد که مشخص شود که به طور کلی هر کلمه ای در قرآن چند بار تکرار شده است.
در ضمن برای درک بیشتر به این لینک می توانید مراجعه کنید.
در حوزه ی مدل سازی موضوعی library های مفیدی نیز برای زبان های مختلف وجود دارد که در این سایت وجود دارد.
۳. آزمایشها
همانطور که در بخش کارهای مرتبط گفته شد یکی از مهمترین آزمایش ها روی مدل سازی موضوعی مرورگری است که ۱۰۰۰۰۰ مقاله ویکی پدیا را مدل سازی موضوعی کرده است.
یکی دیگر از این آزمایش ها روی مدل کردن تحول علم صورت گرفته است که برای رفتن به آن می توانید روی اینجا کلیک کنید.
۴. کارهای آینده
۵. مراجع
Blei, David M. "Probabilistic topic models." Communications of the ACM 55.4 (2012): 77-84.
Probabilistic Topic Models Mark Steyvers Tom Griffiths
On-Line LDA: Adaptive Topic Models for Mining Text Streams with
Applications to Topic Detection and Tracking Loulwah AlSumait, Daniel Barbar´a, Carlotta DomeniconiJoint Sentiment/Topic Model for Sentiment Analysis Chenghua Lin
Yulan HeExploring Content Models for Multi-Document Summarization
Aria Haghighi Lucy VanderwendeVisualizing Topic Models Allison J. B. Chaney and David M. Blei
# پیوندهای مفید