**بسم الله الرحمن الرحیم**
# مقدمه
توئیتر به یک منبع اصلی اطلاعات هم در زندگی روزمره و هم در مطالعات علمی تبدیل شدهاست. به عنوان یک شبکه ی اجتماعی مردم در آن به بیان واقعیات ، ابراز احساس و گسترش دانش میپردازند. و آن ها را در قالب نوشته های کوچک [^microblog] که ما به آن توئیت می گوییم مطرح می کنند. توئیتر به عنوان یک رسانه ی جدید، داده ها را در یک چارچوب قانونی برای حمایت از تحقیقات دانشگاهی به اشتراک می گذارد.
آب و هوا یکی از شایع ترین عناوینی است که مردم در توئیتر به آن اشاره می کنند. با مطالعه ی این که کاربران توئیتر چگونه درباره ی آب و هوا صحبت می کنند
می توانیم دانشی درباره ی احساسات مردم نسبت به یک پدیده ی آب و هوایی خاص و علاوه بر آن حمایت های سیاسی دولت در این زمینه، به دست بیاوریم.
اولین قدم برای این کار طبقه بندی توئیت هایی است که درباره ی آب و هوا هستند. در این مطالعه ما روش هایی را برای دسته بندی آب و هوا از طریق مجموعه داده توئیتر پیدا می کنیم.
# کارهای مرتبط
یکی از کارهای مهمی که باید انجام دهیم طبقه بندی متن های کوتاه[^short text classificatio] است.
**2.1 روش های دسته بندی**
دستهبندی به عملیات یادگیری تابع f گفته می شود که هرمجموعه ویژگی x را به یکی از دستههای از پیش تعریف شدهی y نگاشت میکند. به این تابع مدل دسته بندی نیز می گویند که شامل مدل های توصیفی ومدلهای پیشگویانه میباشد. مدل توصیفی، مدلی است که به عنوان ابزارتوضیحی برای تشخیص اشیا از دسته های مختلف به کار می رود و مدل پیشگویانه به مدلی گفته می شود که می تواند برچسب دسته یک رکورد شناخته نشده را تخمین بزند. روشهای دسته بندی برای ساخت مدلهای دسته بندی از مجموعههای دادهای به کار میروند. این روشها دارای یک الگوریتم یادگیری برای توصیف مدل میباشند.مدل ساخته شده به وسیله ی این الگوریتم ها باید داده های ورودی را به خوبی تطبیق دهد و بتواند برچسب رکوردهایی را که تا کنون ندیدهاست، تخمین بزند. به این منظور ابتدا یک مجموعه آموزش که شامل دادههای با برچسب معین است فراهم می شود، سپس از این مجموعه یک مدل دسته بندی تهیه میگردد.این مدل به مجموعه ی آزمون که شامل داده های با برچسب نا مشخص است، اعمال می شود. کارایی این مدل دسته بندی با بررسی تعداد تخمینهای درست و غلطی که توسط مدل صورت گرفته ارزیابی می شود.
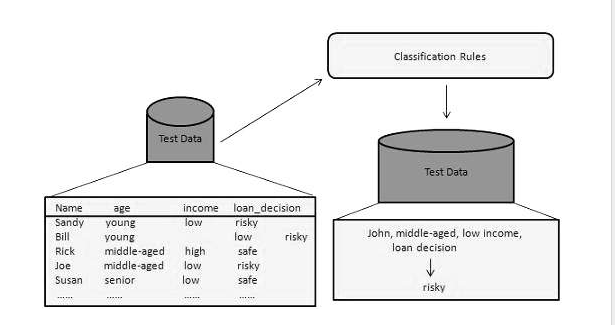
در ادامه به معرفی سه روش مهم دسته بندی اشاره شده است :
****2.1.1ماشین بردار پشتیبانی**** [^Support Vector Machine-SVM]
هدف این دسته الگوریتم ها[1] تشخیص و متمایز کردن الگوهای پیچیده در داده ها (از طریق کالسترینگ، دسته بندی، رنکینگ، پاکسازی و غیره)می باشد. مبنای کاری این نوع دسته بندی، دسته بندی خطی داده ها است و در تقسیم خطی داده ها سعی می شود خطی را انتخاب کنیم که حاشیه اطمینان بیشتری داشته باشد. این روش در سالهای اخیر کارایی خوبی نسبت به روشهای قدیمیتر برای طبقهبندی از جمله شبکههای عصبی پرسپترون نشان داده است.از الگوریتم ماشین بردار پشتیبان، در هر جایی که نیاز به تشخیص الگو یا دسته بندی اشیا در کلاس های خاص باشد می توان استفاده کرد.اگر داده های آموزشی جدایی پذیر خطی باشند، می توان دو ابر صفحه در حاشیه نقاط در نظر گرفت؛ به طوری که هیچ نقطه مشترکی نداشته باشند. سپس می بایست فاصله آنها را به حداکثر رساند. نزدیکترین داده های آموزشی به ابر صفحه های جدا کننده بردارپشتیبان نامیده می شوند.

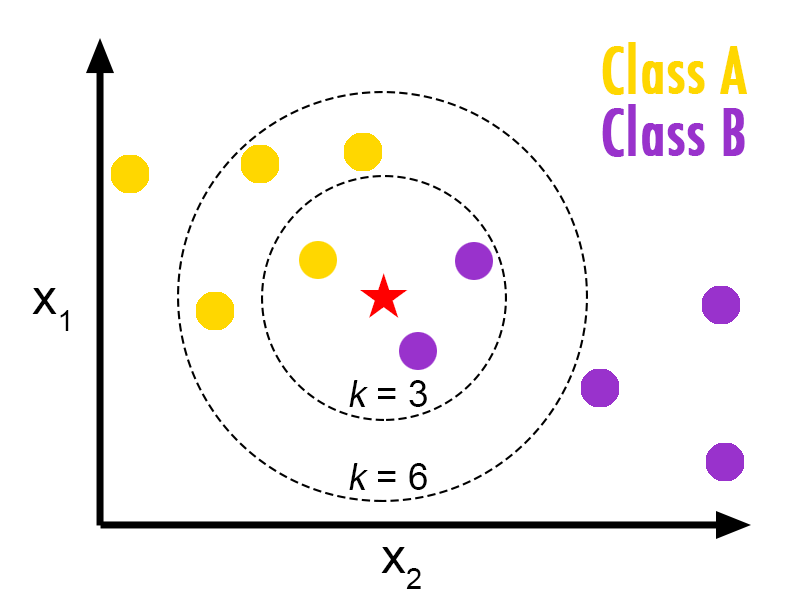
**2.1.2 k-نزدیک ترین همسایه**[^k-nearest neighbors]
در شناخت الگو، الگوریتم [k-Nearest Neighbors](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm) (یا K-NN به اختصار)[2] یک روش غیر پارامتری مورد استفاده برای طبقهبندی و رگرسیون است. [3] در هر دو مورد، ورودی شامل K تا نزدیک ترین نمونه های آموزشی در فضای ویژگی است. خروجی بستگی به این دارد که K-NN برای طبقه بندی یا رگرسیون استفاده می شود.
در K-NN طبقه بندی، خروجی کلاس عضویت است. یک شی با رأی اکثریت از همسایگان خود طبقه بندی میشود، که شئ با رایج ترین مقدار میان K نزدیک ترین همسایگان خود (K یک عدد صحیح مثبت است، به طور معمول کوچک) به کلاس اختصاص داده میشود. اگرk = 1 باشد، در ان صورت شی به سادگی به کلاسی با نزدیکترین همسایه واحد اختصاص داده میشود.
****2.1.3درخت تصمیم**** [^Desition Tree]
[درخت تصمیم](https://en.wikipedia.org/wiki/Decision_tree) یک ابزار برای پشتیبانی از تصمیم است که از درختان برای مدل کردن استفاده میکند. در آنالیز تصمیم، یک درخت تصمیم به عنوان ابزاری برای به تصویر کشیدن و آنالیز تصمیم، در جایی که مقادیر مورد انتظار از رقابتها متناوباً محاسبه میشود، استفاده میگردد.
مشکل استفاده از درختهای تصمیم آن است که به صورت نمایی با بزرگ شدن مسئله بزرگ میشوند. همچنین اکثر درختهای تصمیم تنها از یک ویژگی برای شاخه زدن در گرهها استفاده میکنند در صورتی که ممکن است ویژگی ها دارای توزیع توأم باشند. ساخت درخت تصمیم در برنامههای داده کاوی حافظه زیادی را مصرف میکند زیرا برای هر گره باید معیار کارایی برای ویژگیهای مختلف را ذخیره کند تا بتواند بهترین ویژگی را انتخاب کند [4]. با این حال می توان با استفاده از الگوریتم هایی درخت تصمیم بهینه ای در بازه ی زمانی قابل قبولی تشکیل داد.

**2.2 مطالعات انجام شده**
در این زمینه مطالعات متعددی انجام شدهاست که در ادامه به بررسی تعدادی از آن ها میپردازیم.
1. در یکی از روش ها [5] از یک مجموعه اسناد بدون برچسب برای دسته بندی و طبقه بندی سند های کوتاه استفاده کردند. آن ها از یک مدل فضای برداری به نمایندگی از سند کوتاه کمک گرفتند و از امتیازدهی TF-IDF برای وزن دهی به اصطلاحات استفاده کردند، سند برچسب گذاری نشده می تواند به ارائه ارزش کلمات ( از لحاظ ارزش TF-IDF خود در این مجموعه بزرگی ) و احتمال توام کلمات کمک کند. و در نهایت از روش یادگیری ماشین برای پایان کار طبقه بندی استفاده می کنند. این روش زمانی مفید خواهد بود که مقدار زیادی اطلاعات درباره ی مشکل خاصی در وب، داشته باشیم.
2. در روشی دیگر راه حلی را برای پرداختن به محدودیت مدل bag -of -words وقتی که در طبقه بندی متن های کوتاه استفاده می شود، مطرح میکند. در این روش به جای استفاده از یک مجموعه بزرگ از اسناد، از یک مجموعه ی کوچک از ویژگی هایی با دامنه خاص که از پروفایل نویسنده و متن استخراج شدهاست استفاده میکند. این رویکرد به صورت کارآمد متن را به یک مجموعه ی از پیش تعریف شده از کلاسهای کلی مثل اخبار، رویدادها و پیام خصوصی طبقه بندی میکند [6] .
با توجه به محدودیت مجموعه ی داده ی این پروژه که در ادامه به آن میپردازیم و تعریفی که از مسئله شد، نمی توانیم یک مجموعه اسناد را برای پشتیبانی از پیش بینی مان پیدا کنیم. علاوه بر این ما نمیتوانیم به داده های پروفایل کاربران با توجه با مسائل خصوصی دسترسی داشته باشیم. بنابراین روش هایی که در مقاله ی دوم توصیف شد فقط می تواند راه تجزیه را نشان دهد و مشکل را تسهیل نماید.
**2.3چالش های پیش رو**
طبقه بندی توئیت ها بر اساس دسته بندی آب و هوای آن ها در ابعاد مختلف به چالش کشیده شدهاست :
+ اول این که توییت ها اسناد بسیار کوتاه با بیان روزانه هستند و امکان اشتباه گرامری و دستوری دارند. بنابراین برخی از روش های سنتی طبقه بندی متن
که برای اسناد رسمی بزرگ به خوبی کار می کنند، ممکن است هنگام استفاده از آن برای حل این مشکل عملکرد ضعیفی داشته باشد.
+ دوم مشکل طبقه بندی چندکلاسی است. در واقع در مجموعه داده ای ما دسته بندی آب و هوا بر اساس 24 مورد است که این میتواند در میزان دقت و فراخوانی روی دسته ها و کلاسهای مختلف برای به دست آوردن نتیجه ی مطلوب کلی، اهمیت داشته باشد. بنابراین به یک روش که برای مقابله با این دو مشکل به خوبی طراحی شده، نیاز است.
#آزمایش ها :
در این بخش به پیاده سازی روشی که در ادامه توضیح داده میشود پرداخته شده است. که کد آن در [گیت هاب](https://github.com/z-momeni/Weather_Tweets) قابل مشاهده است.
**4.1 مجموعه داده**[^Data set]
مجموعه داده ای که برای این پروژه استفاده می شود از پایگاه داده توئیتر [7] گرفته شدهاست. تعداد کل توییت ها 77947 است. هر مورد توییت شامل 5 قسمت است : مشخصه توییت، محتوای توییت، حالت کاربر، شهر، برچسب آب و هوا. این توییت ها به عنوان متن های مرتبط با آب و هوا انتخاب شدهاند و توسط انسان ها با 12 مشخصه برچسب زده شدهاند. دسته بندی ها در جدول زیر آورده شدهاست :
+ **جدول 4.1.1 برچسب های توئیت در مجموعه داده**
| 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | ID |
|:----:|:----:|:------:|:--:|:----:|:----:|:---:|:----:|:---:|:--:|:---:|:---:|-------:|
|other|wind|tornado|sun |storm |snow | rain | humid| hot| dry | clod | cloud|category|
**4.2 روش انجام کار**
**4.2.1 انتخاب ویژگی ها**
ابتدا با تعریف برچسب گذاری اجزای کلامشده است. برای طبقه بندی از یک مدل فضای برداری به نمایندگی از اسناد کوتاه کمک گرفته و برای وزن دهی به اصطلاحات روش امتیازدهی [TF-IDF](https://en.wikipedia.org/wiki/Tf%E2%80%93idf) انتخاب شده است، سند برچسب گذاری نشده می تواند به ارائه ارزش کلمات ( از لحاظ ارزش TF-IDF خود در این مجموعه بزرگی ) و احتمال توام کلمات کمک کند. و در نهایت از روش یادگیری ماشین برای پایان کار طبقه بندی استفاده می کنند. این روش زمانی مفید خواهد بود که مقدار زیادی اطلاعات درباره ی مشکل خاصی در وب، داشته باشیم.
2. در روشی دیگر راه حلی را برای پرداختن به محدودیت مدل [bag -of -words](https://en.wikipedia.org/wiki/Bag-of-words_model) وقتی که در طبقه بندی متن های کوتاه استفاده می شود، مطرح میکند. در این روش به جای استفاده از یک مجموعه بزرگ از اسناد، از یک مجموعه ی کوچک از ویژگی هایی با دامنه خاص که از پروفایل نویسنده و متن استخراج شدهاست استفاده میکند. این رویکرد به صورت کارآمد متن را به یک مجموعه ی از پیش تعریف شده از کلاسهای کلی مثل اخبار، رویدادها و پیام خصوصی طبقه بندی میکند [6] .
با توجه به محدودیت مجموعه ی داده ی این پروژه و تعریفی که از مسئله شد، نمی توان یک مجموعه اسناد را برای پشتیبانی از پیش بینی پیدا کرد. علاوه بر این نمیتوان به داده های پروفایل کاربران با توجه با مسائل خصوصی دسترسی داشت. بنابراین روش هایی که در مقاله ی دوم توصیف شد فقط می تواند راه تجزیه را نشان دهد و مشکل را تسهیل نماید.
**2.3چالش های پیش رو**
طبقه بندی توئیت ها بر اساس دسته بندی آب و هوای آن ها در ابعاد مختلف به چالش کشیده شدهاست :
+ اول این که توییت ها اسناد بسیار کوتاه با بیان روزانه هستند و امکان اشتباه گرامری و دستوری دارند. بنابراین برخی از روش های سنتی طبقه بندی متن
که برای اسناد رسمی بزرگ به خوبی کار می کنند، ممکن است هنگام استفاده از آن برای حل این مشکل عملکرد ضعیفی داشته باشد.
+ دوم مشکل طبقه بندی چندکلاسی است. در واقع در این مجموعه داده دسته بندی آب و هوا بر اساس 24 مورد است که میتواند در میزان دقت و فراخوانی روی دسته ها و کلاسهای مختلف برای به دست آوردن نتیجه ی مطلوب کلی، اهمیت داشته باشد. بنابراین به یک روش که برای مقابله با این دو مشکل به خوبی طراحی شده، نیاز است.
**2.4 روش انجام کار**
**** انتخاب ویژگی ها****
ابتدا با تعریف [برچسب گذاری اجزای کلام](https://en.wikipedia.org/wiki/Part-of-speech_tagging) [^pos-tagging] آشنا می شویم این کار درواقع عمل انتساب برچسب به کلمات تشکیلدهندهٔ یک متن یا یک پیکره است. این برچسبگذاری براساس نقش آن کلمه در متن، مانند اسم، فعل، قید، صفت، و غیره صورت میگیرد. بعضی کلمات ممکن است یک یا چند برچسب داشتهباشند. برای انتخاب ویژگی ها دو روش زیر وجود دارد :
1. بدون برچسب گذاری bag-of-words :
ما باید مجموعه ای از ویژگی ها را بر اساس امتیازTF-IDFاستخراج کنیم. به منظور کاهش بیش برازش [^over-fitting . بیش برازش یعنی اگرچه مدل روی داده ی استفاده شده برای یادگیری بسیار خوب نتیجه میدهد، اما بر روی داده ی جدید دارای خطای زیاد است و وقتی اتفاق می افتد که مدل به جای بیان روابط اصلی، نویزها و خطاهای تصادفی را مدل کند. ] و بهبود پیچیدگی زمانی، ویژگی های انتخاب شده را پیاده سازی می کنیم و با استفاده از جستجوی رو به جلو[^Forward search]، تعداد مناسب این ویژگی ها را انتخاب می کنیم.
2. برچسب گذاری bag-of-words:
بعد از اعمال برچسب گذاری مجموعه ی ویژگی ها شامل تعدادی اسم، فعل، قید و صفت می شود. برای این کار مراحل زیر را دنبال می کنیم :
+ ابتدا تعداد مناسب برای اسم را انتخاب می کنیم که بیشترین بازده را در نتیجه ی طبقه بندی داشته باشد.
+ سپس تعداد مناسبی که برای اسم به دست اورده ایم نگه می داریم و تعداد مناسب فعل ها را پیدا می کنیم طوری که بیشترین بازده را در نتیجه
ی طبقه بندی داشته باشد.
+ تعداد مناسبی که برای اسم وفعل به دست اورده ایم نگه می داریم و به دنبال بهترین تعداد برای صفت می رویم.
+ و در نهایت تعداد مناسب قید را طوری به دست می اوریم که بیشترین بازده را در نتیجه طبقه بندی داشته باشد.
البته سعی شده هر دو روش پیاده سازی شود تا نتایج قابل مشاهده باشد.
در پردازش متن نمی توان کل متن را به الگوریتم های مختلف دسته بندی بدهیم بنابراین باید ویژگی هایی را از متن استخراج کنیم [^feature extraction]. برای این کار ما مدل برداری فضا [^Vector Space Model]را پیاده سازی می کنیم [مدل برداری فضا](https://en.wikipedia.org/wiki/Vector_space_model) [^Vector Space Model]را پیاده سازی می کنیم . مدل فضای برداری [8,9] یکی از مدل های بازیابی اطّلاعات است کـه در سـطح وسـیعی به کار می رود در این مدل، هرمقوله اطّلاعاتی ـ شامل متون ذخیـره شـده و هـر تقاضای اطّلاعاتی زبان طبیعی ـ به صـورت مجموعـه بردارهـایی از اصـطلاحات نگهـداری میشوند.
به طور نظری، این اصطلاحات میتوانند از واژگان کنترل شده انتخاب شـوند. بـه خاطر وجود مشکلاتی در تهیه این واژگان، اصطلاحات از متون استخراج میشوند. معمولاً برای کاهش اندازه واژگان از ریشه واژه ها استفاده می شود. همچنـین معمـولاً از [واژه هـای بازدارنـده](https://en.wikipedia.org/wiki/Stop_words) [^Stop words] نظیـر an ,of ,the ,.... صـرف نظـر مـی گـردد.
از تمـام واژه هـای موجـود در مدارک، یک مجموعه واژگان به وجود می آید. هر مـدرک بـه صـورت بـرداری از تمـام واژگان نمایانده می شود.
مدل فضای برداری، شیوه ای است برای نمایش مدارک از طریق واژه هـای موجـود در آنها. این مدل ، یک تکنیک استاندارد در بازیابی اطّلاعات است . بر اساس مـدل فـضای برداری، میتوان تصمیم گرفت که کدام مدارک شبیه به یکـدیگر و یـا بـه کلیـدواژه هـای جستجو شبیه هستند. سپس از فرکانس کلمه [10,11] یعنی تعداد تکرار کلمه درمتن [^Term frequency] به عنوان وزن کلمه و به عنوان اندازه گیرنده برای ایجادمجموعه ویژگی ها استفاده می کنیم. به عبارت دیگر ما فرکانس کلی کلمه را برای هر کلمه ای که درمجموعه ی آموزش به نظر می رسد با استفاده از روش TFمحاسبه می کنیم وk کلمه ای که بالاترین ارزش را در TF به دست آوردند به عنوان ویژگی های خود انتخاب می کنیم ${f_{1},f_{2},...,f_{k}}$ و در مجموعه ی bag-of-word قرار می دهیم . مقدار k را با انجام ازمایش های مختلف و بررسی نتایج باید انتخاب کنیم بنابراین از مقادیر کم شروع کرده و به تدریج آن را افزایش می دهیم تا به یک دقت نسبی برسیم این مقدار نباید به اندازه ای بزرگ باشد که بیش برازش رخ دهد. از آن جا که ما در پایگاه داده ی خود با تعدادی جمله رو به رو هستیم نه یک متن، بنابراین برای انجام این کار کل جملات را در کنار هم به عنوان یک متن در نظر می گیریم و سپس از روش TFبرای به دست اوردن ارزش کلمات جهت استخراج ویژگی ها در این متن استفاده می کنیم .
سپس یک بردار فضا را به نمایندگی از هر توییت به دست می اوریم به صورت زیر :
$t_{i}=(w_{1},w_{2},...,w_{k})$
که در آن هر یک از ابعاد ازw نشان دهنده ی ارزش TF ویژگی f در توییت مورد نظر است .
**4.2.2 دسته بندی**
در پیاده سازی پروژه از روش دسته بندی "ماشین بردار پشتیبان" که در بخش های قبلی به توضیح آن پرداختیم استفاده شده است. در انتها بردار هایی که به ازای هر توئیت به دست آوردیم را به همراه 12 برچسبی که در مجموعه ی آموزش برای هر توئیت درنظر گرفته شده است جهت اموزش ماشین به آن داده می شود و در نهایت بر روی داده های تست آزمایش می شود.
# کارهای آینده
$t_{i}=(w_{1},w_{2},...,w_{k})$$
که در آن هر یک از ابعاد ازw نشان دهنده ی ارزش TF ویژگی f در توییت مورد نظر است .
#آزمایش ها :
در این بخش به ارائه روش پیشنهادی خود و مراحل انجام آن می پردازیم و در این راستا کارکرد هر یک از روش های پیشنهادی با پیاده سازی آن روش ارزیابی می گردد. کد پیاده سازی و جزئیات اجرایی مربوط به آن از طریق [این لینک](https://github.com/z-momeni/tweets_about_weather)در گیتهاب قابل مشاهده است.
**3.1 مجموعه داده**[^Data set]
[مجموعه دادهای](https://www.kaggle.com/c/crowdflower-weather-twitter/data)که برای این پروژه استفاده میشود از پایگاه داده توئیتر [7] گرفته شدهاست البته با اعمال تغییراتی که این تغییرات در ادامه توضیح داده می شوند.. تعداد کل توییتها در مجموعه آموزش 77947 است. هرتوییت علاوه بر مشخصه، محتوا، حالت و شهر، شامل 24 برچسب میباشد که به 3 دسته تقسیم می شود. این توییتها به عنوان متن های مرتبط با آب و هوا انتخاب شدهاند وتوسط انسان ها با 24 مشخصه برچسب زده شدهاند. دسته بندی ها در تصویر زیر آورده شدهاست:

**3.2مراحل پیاده سازی**
در این قسمت به توضیح مراحل پیاده سازی پرداخته شدهاست.
****3.2.1دسته بندی ****
در پیاده سازی پروژه از روش دسته بندی "ماشین بردار پشتیبان" که در بخش های قبلی به توضیح آن پرداختیم استفاده شده است.
$$ clf.fit(X, lable)$$
همانطور که مشاهده میکنید به دو پارامتر نیاز است پارامتر اول با تعیین مجموعه بردار توئیتها تعیین میشود و پارامتر دوم با تعیین برچسب هر بردار
مشخص میشود.
بنابراین در ادامه مراحل به دست آوردن این دو پارامتر بیان می شود.
برای پیاده سازی این پروژه هر بخش به طور جدا پیاده سازی شده است. پروژه شامل 4 فایل اصلی **readFile.py** ، **reduce_data.py** و **feature_withPosTag.py**و **evaluation.py**می باشد.این کار باعث شد خطایابی و رفع اشکالات کد در حین پیاده سازی راحت تر انجام شود.
****3.2.2.1مرحله ی اول کاهش داده ها****
با توجه با اینکه حجم داده ها در مجموعه ی دادگان زیاد_حدود 70 هزار جمله_ است انجام پردازش بر روی آنها کار ساده ای نخواهد بود. بنابراین برای ارزیابی، داده های مربوط به قسمت یادگیری به دو قسمت تقسیم می شود و از نیمی از آن برای تست و از نیم دیگر آن برای یادگیری استفاده می کنیم کد مربوطه را در [اینجا ](https://github.com/z-momeni/tweets_about_weather/blob/master/reduce_data.py)ببینید. می توان از هر نوع استراتژی برای کاهش داده های استفاده نمود. چنین روش هایی در [این لینک](https://www.kaggle.com/c/acquire-valued-shoppers-challenge/forums/t/7666/getting-started-data-reduction/) مطرح شده اند.
در این قسمت کد مربوط به کاهش حجم داده ها قابل مشاهده است.
|my train| my test | train |
|:----:|:-------:|:-------:|
| 38947| 38947 | 77947 |
****3.2.2.2مرحله دوم استخراج ویژگی ها****
قدم بعدی استخراج ویژگی ها از داده ی مسئله است. باید کلماتی مهم و کلیدی از متن استخراج شود که با توجه به وجود یا عدم وجود آن ها در هر توییت برداری به ازای هر توییت ساخته شده و برای آموزش به ماشین یادگیری داده شود. برای تعیین کلمات کلیدی از ارزش tf-idf آن ها استفاده شده است.برای این کار ابتدا کلمات بازدارنده از بین کلمات موجود حذف می شود. سپس میتوان از بین کلمات باقی مانده با استفاده از برچسب گذاری اجزای کلام تنها کلماتی که نقش های خاصی در جمله دارند از جمله صفت ، قید و اسم را نگه داشته و بعد ارزش tf-idfآن ها را به دست اورد. برای پیاده سازی این قسمت از[این مطالب](vase%20ghesmate%20tozih%20posTag%20ina%20:%20http://www.bogotobogo.com/python/NLTK/tokenization_tagging_NLTK.php)استفاده شده است.
+ JJ = صفت
+ NN = اسم
+ RB = قید
+ VB = فعل
تعداد کل کلمات کلیدی در روش برچسب گذاری برابر با 18112 است که در [این فایل](https://github.com/z-momeni/tweets_about_weather/blob/master/feature.txt) قابل مشاهده است. این کلمات به ترتیب بیشترین ارزش به کمترین ارزش در فایل ذخیره می شوند.
****3.2.2.3مرحله ی سوم تشکیل بردار هر توییت****
بعد از به دست اوردن مجموعه ویژگی ها از بین تعدادی که موجود است هر بار با انتخاب k کلمه اول فایل که بیشترین ارزش را دارند مجموعه ی bag of word را تشکیل داده و با استفاده از آن بردار متناظر با هر توییت را با توجه به وجود یا عدم وجود کلمات این مجموعه در هر توییت تشکیل میدهیم.
تا این مرحله پارامتر اول تعیین شد.
****3.2.2.4مرحله ی چهارم ****
در این مرحله کافیست برچسب های هر توییت را به شکل قابل استفاده برای ماشین تبدیل کنیم .در فایل داده های مربوط به آموزش 24 ستون مقابل هر توییت قرار دارد که مقادیر اعشاری بین صفر تا یک دارند. که در پیاده سازی برای ساختن رشته ی برچسب هر توییت مقادیر بیشتر از 0.5 را برابر یک و مقادیر کمتر از 0.5 برابر صفر در نظر گرفته شده اند.
همان طور که در بخش "مجموعه داده" گفته شد سه دسته برای هر توییت در نظر گرفته شده است. یعنی هر توییت سه برچسب مختلف داردکه هر بار با یکی از این برچسب ها اموزش داده میشود کد مربوط به این قسمت در [این فایل](https://github.com/z-momeni/tweets_about_weather/blob/master/evaluation.py)قرار داده شده است.
****3.2.2.5مرحله پنجم ارزیابی****
در این مرحله 5 مقدار برای k در نظر گرفته شده و نتایج حاصل برای هر 3 دسته به طور جداگانه بررسی می شود.
****جدول 3.2.2.5.1درصد پیش بینی درست دسته S ****
|k=800 | k=600 | k=300 | k=150 | k = 50 |
|:-----:|:-----:|:-----:|:-----:|:-----:|
|73.4713|73.4713|73.6355|73.5616|73.6766|
بهترین مقدار k برای این دسته برابر است با 50.
****جدول 3.2.2.5.2درصد پیش بینی درست دسته W ****
|k=800 | k=600 | k=300 | k=150 | k = 50 |
|:-----:|:-----:|:-----:|:-----:|:-----:|
|90.9947|90.9947|90.9947|90.9947|90.9947|
با توجه با اینکه مقادیر ثابت ماند یعنی مقدار k تاثیری در پیش بینی مقادیر این دسته ندارد. و با احتمال خوبی نزدیک به ۹۰ درصد پیش بینی درست انجام میشود.
****جدول 3.2.2.5.3درصد پیش بینی درست دسته K ****
|k =800 | k =600 | k =300 | k =150 | k = 50 |
|:------:|:------:|:------:|:------:|:------:|
| 69.2751| 69.2751| 69.6579| 69.6795|69.8447 |
بهترین مقدار k برای این دسته برابر است با 50.
**نتیجه آزمایش**
مقدار k هر چه بیش تر می شود درصد پیش بینی های درست به مرور کم می شود. پس هر چه مقدار k متعادل تر انتخاب شود، هم امکان بیش برازش کمتر است و هم نتایج مطلوب تر خواهد بود.
# کارهای آینده
از آن جا که سرعت ماشین یادگیری به کار گرفته شده در این پروژه با افزایش حجم داده ها پایین می آید از ماشین هایی با سرعت بالاتر مثل [libsvm](https://www.csie.ntu.edu.tw/~cjlin/libsvm/) که با زبان c پیاده سازی شده و نسبتا سریع می باشد و یا روش هایی که به نوعی سرعت پردازش را بالا ببرد می توان استفاده کرد.
برای بالا بردن دقت از روش های دیگر برای ایجاد مجموعه ویژگی ها جهت هدفمند تر بودن آن ها استفاده کرد.
در مجموعه ی دادگان این مسئله برچسب ها مقادیر اعشاری دارند اما در این پیاده سازی مقادیر بیشتر از 0.5 معادل با یک و کوچکتر معادل با صفر در نظر گرفته شده است. یکی از کارها هم می تواند این باشد که از روشی استفاده شود تا دقیقا از همان مقادیر اعشاری استفاده شود.
# مراجع
[1] Christopher J. C. Burges. "*A Tutorial on Support Vector Machinesfor Pattern Recognition* ", Data Mining and Knowledge Discovery, 1998.
[2] Altman, N. S. "*An introduction to kernel and nearest-neighbor nonparametric regression* ". The American Statistician, 1992.
[3] Y. Yuan and M.J. Shaw. "*Induction of fuzzy decision trees* ", Fuzzy Sets and Systems, 1995.
[4] *What can a machine learn from tweets about the weather*. (2013, December 1). Retrieved November 5, 2015, from
[5] Zelikovitz, Sarah, and Haym Hirsh. "*Improving short text classification using unlabeled background knowledge to assess document similarity* ", Proceedings of the Seventeenth International Conference on Machine Learning, 2000.
[6] Sriram, Bharath. "*Short text classification in twitter to improve information filtering*", Proceedings of the 33rd
international ACM SIGIR conference on Research and development in information retrieval, 2010.
[7] www.kaggle.com/c/crowdflower-weather-twitter
[8].گراسمن، دیوید و افیر فریدر."بازیابی اطلاعات،الگوریتم ها و روش های اکتشافی"ترجمه ی جعفر مهراد و سارا کلینی .انتشارات کتابخانه ای.1384.
[9] Baeza Yates, R. Ribeiro. "*Modern information Retrieval* ", Addison Wesley, 1999.
[10] Salton, G., Yang, C.G., Yu, C.T. "*A Theory of Term Importance in Automatic Text Analysis* ", Journal of
the ASIS, 1975.
[11] Salton, G.Buckley. "*Term weighting Approaches in Automatic Text Retrieval* ", Information Processing and
Management, 1988.
# پیوندهای مفید
+ [www.kaggle.com/crowdflower-weather-twitter](https://www.kaggle.com/c/crowdflower-weather-twitter/)
+ [scikit-learn](http://scikit-learn.org/stable/tutorial/index.html)
+ [nltk](http://www.nltk.org/)
#پاورقی