شاید بتوان تشخیص بیماریها با استفاده از الگوریتمهای هوش مصنوعی را مفیدترین و صلحآمیزترین کاربرد هوش مصنوعی تاکنون دانست. یکی از شایعترین بیماریها و علل مرگ و میر در دنیای امروز بیماریهای قلبی است.
در تشخیص این نوع بیماریها معمولا عواملی چون سن، جنسیت، فشار خون، میزان کلسترول و ... مدنظر قرار میگیرند و در نهایت میزان ریسک بیمار در مقابل بیماریهای قلبی تعیین میشود.
در این پژوهش انتظار میرود با استفاده از هریک از روشهای یادگیری ماشین (مثلا دستهبندی) به تشخیص این بیماری پرداخته شود.
برای این منظور میتوان از دادههای دانشگاه ایرواین که لینک آن در قسمت لینکهای مفید قرار دارد استفاده کنید.
# تعریف پروژه
امروزه با پیشرفت تکنولوژی استفاده از سیستم های هوشمند در پردازش و تحلیل سیگنال های حیاتی و تشخیص بیماری های مختلف از اهمیت ویژه ای برخوردار است اما تشخیص نهایی بیماری به عهده پزشک می باشد و با مشاهده علایم و انجام آزمایشاتی این تشخیص صورت می گیرد. از جمله بیماری هایی که پزشکان را در تشخیص با مشکلاتی مواجه می کند ، بیماری قلبی است. بیماریهای قلبی یکی از عوامل اصلی مرگ و میر در دنیا، به خصوص ایران، است و بهترین درمان آن تشخیص به موقع و پیشگیری آن است. بیماری قلبی، که معمولا از آن به عنوان بیماری شریانهای اکلیلی(Coronary Artery Disease) نام برده میشود؛ واژهای با دامنه وسیع است که به هر نوع شرایطی که قلب را تحت تأثیر قرار میدهد، اطلاق میشود. بیماری شریانهای اکلیلی، بیماری مزمنی است که طی آن شریان اکلیلی بهتدریج سفت و باریک میشود .
# مقدمه
حجم داده های پزشکی روز به روز درحال افزایش است و پزشکان معمولا اطلاعات ارزشمندی را در خصوص بیماری ها و ارتباط آن ها با یکدیگر و عوامل ایجاد کننده بیماری ها بدست می آورند [8] . اما این مجموعه داده های خام به خودی خود ارزشی ندارند، برای معنی بخشیدن به این داده ها باید آن ها را تحلیل و تبدیل به اطلاعات یا بهتر از آن ها دانش کرد [9]. با توجه به شیوع بیماری های قلبی – عروقی در سراسر جهان، استفاده از روش های جدید در تحقیقات زیست پزشکی بسیار مورد توجه قرار گرفته است. داده کاوی می تواند ارتباطات و وابستگی های بدیعی را کشف کند که برای پزشکان بسیار مفید است.
تکنیک های داده کاوی به طور کلی به دو دسته توصیف کننده و پیش گویی کننده تقسیم می شوند. وظایف توصیفی خواص عمومی داده ها را مشخص می کند و هدف آن پیدا کردن الگوهای قابل تفسیر توسط افراد برای داده هاست. وظایف پیش گویانه، پیش بینی رفتار آینده آن هاست و منظور از آن بکارگیری چند متغیر در پایگاه داده برای پیش گویی مقادیر آینده متغیرهاست[4] داده کاوی گونه ای از تکنیک ها برای شناسایی اطلاعات و یا دانش تصمیم گیری از میان داده ها می باشد، به نحوی که با استخراج آن ها در حوزه های تصمیم گیری، پیش بینی، پیش گویی و تخمین بتوان از آن ها استفاده کرد. داده کاوی پزشکی دارای پتانسیل زیادی برای کشف الگوهای پنهان موجود در داده ها داراست که این الگوها می تواند برای تشخیص های بالینی مورد استفاده قرار گیرد [5]. امروزه استفاده از روش های متنوع داده کاوی و استخراج دانش برای شناسایی الگوها و ارتباطات میان متغیرهای مختلف در تولید مدل های پیش بینی کننده در علوم پزشکی بسیار مورد توجه قرار گرفته است [6]. کاربرد روش های داده کاوی در حوزه های مختلف پزشکی مانند تشخیص، پیش گویی و حتی درمان به اثبات رسیده است[7].
به طور کلی روشها و الگوریتمهای متعددی برای پیشبینی بیماری قلبی مورد ارزیابی قرار گرفتهاند که این الگوریتمها بر روی مجموعه دادههای متفاوت و تحت شرایط متنوعی آزمایش شدهاند. هدف اصلی ما در این بحث استفاده از الگوریتمهای دادهکاوی(Data Mining) برای پیشبینی حملات قلبی است که در ادامه به توضیح آن می پردازیم .
# کارهای مرتبط
یکی از عملکردهای پیش گویانه در داده کاوی،دسته بندی است. دسته بندی فرایند یافتن مدلی است که با تشخیص دسته ها و یا مفاهیم داده می تواند دسته
ناشناخته اشیا دیگر را پیش گویی کند . یکی از روش های رایج دسته بندی درخت تصمیم است. درخت تصمیم گیری روشی است که به شما در یک انتخاب خوب
کمک می کند. به خصوص تصمیم گیری هایی که دربردارنده هزینه بالا و خطرات زیادی است. درختان تصمیم یک روش گرافیکی برای مقایسه رقابت جایگزین و
اختصاص ارزش به آن ها از طریق ترکیب عدم قطعیت ها، هزینه ها و بازپرداخت ها به وسیله ارزش های خاص عدد است .
درخت تصمیم معمولا از چندین گره 3 تشکیل می شود که با نام گره های ورودی و خروجی شناخته می شوند. قوانین ایجاد شده در درخت تصمیم به صورت "اگر" و
"آنگاه بیان می شوند. از میان الگوریتم های مورد استفاده در ساخت درخت تصمیم، مهم ترین آن ها الگوریتم [10]C5 است که توسعه یافته [ID3[11 [C5](http://rulequest.com/see5-comparison.html.) است که توسعه یافته [11] [ID3](http://www.cise.ufl.edu/~ddd/cap6635/Fall-97/Short-papers/2.htm)می باشد.شبکه های عصبی مصنوعی با پردازش داده های تجربی،دانش یا قانون نهفته در ورای داده ها را به ساختار شبکه منتقل می کنند، به همین دلیل به این سیستم ها هوشمند می گویند. زیرا بر اساس محاسبات داده های عددی یا مثال ها، قوانین کلی را فرا می گیرند.
یکی دیگر از الگوریتم های درخت تصمیم ، الگوریتم ( CHAID ( Chi-squared Automatic Interaction Detector است . این الگوریتم توسط کاس در سال 1980 برای استفاده در مورد متغیرهای کیفی معرفی شد که می تواند برای متغیرهای کمی گروه بندی شده نیز استفاده شود. در هر گره، می توان بیش از دو تقسیم نیز داشت. در این روش از مقدار P-Value آماره کای- دو مربوط به آزمون استقلال جداول توافقی ، استفاده می شود. از بین متغیر های موجود، متغیری که دارای P-Value کوچک تری باشد در مرحله اول برای تقسیمات روی یک گره در نظر گرفته می شود. ضعف این الگوریتم عدم توانایی آن در ایجاد بهینه ترین تقسیمات ممکن بر اساس متغیر های موجود است.
ازجمله الگوریتم های درخت تصمیم دیگر ،( QUEST ( Quick Unbiased Efficient Statistical Trees ی باشد . این الگوریتم در سال 1997 توسط لو و شی برای متغیرهای پاسخ اسمی طراحی شد. درخت رده بندی حاصل از این الگوریتم دارای تقسیمات دوتایی بوده و ملاک تصمیم برای انتخاب متغیرها با استفاده از مقدار P-Value آماره کای- دو مربوط به جداول توافقی برای متغیر های کیفی صورت می پذیرد. این الگوریتم با توجه به این که از مقدار P-Value برای تصمیم گیری استفاده می نماید، موجب تشکیل درختی نااریب از متغیرها می گردد.
در واقع شبکه های عصبی تکنیک هایی هستند که می توانند برای مدل های با ارتباطات پیچیده مورد استفاده قرار گیرند.مدل های شبکه عصبی مصنوعی در طبقه بندی مسائلی نظیر، پیش بینی مشکلات قلبی در بیماران، تشخیص فشار خون و... استفاده شده است . پیش گویی خطر ابتلا به بیماری های قلبی به کمک سیستم های حمایت از تصمیم نقش مهمی در پیشگیری از بیماری ایفا می کند.
شبکه های عصبی از سیستم یادگیری پیچیده ی مغز که متشکل از مجموعه نرون ها می باشد الهام گرفته شده است. هدف از شبکه های عصبی مصنوعی ارائه روش هائی جهت استفاده از سخت افزارها ( مدارات ) و نرم افزارها( الگوریتم ها) برای ایجاد قابلیت های هوشمند به دستگاه ها، روبوت ها، برنامه ها و غیره میباشد که قادر به یادگیری حین فرآیند هستند. نرون مصنوعی کوچکترین واحد پردازشگر اطلاعات است.ورودیهای نرون توسط یک نوع ارتباط به نام وزنبه نرون وارد می شوند .
داده های مورد نیاز :
مجموعه داده مورد استفاده در این پروژه متعلق به قسمت پیوندهای مفید میباشد. پارامترها و محدوده آن ها در زیر آورده شده است:
| ستون اول | ستون دوم |
|:---------------------------------|:------------------------------------------------------:|
|Age | سن بیمار |
|Sex | جنسیت بیمار |
|chest pain type | بیان کننده درد قفسه سینه که شامل 4 مقدار مشخصهی درد قلبی، بدون درد و بدون علامت است|
|Resting blood pressure | فشار خون در زمان استراحت |
|Serum cholesterol | چربی بد خون |
|Fasting blood sugar|قند خون ناشتا|
|Resting electrocardiographic results|نتایج نوار قلب در حال استراحت که شامل 3 مقدار نرمال، موج غیر قلبی و نشاندهندهی افزایش مقطعی یا احتمالی ضخامت بطن چپ است|
|Maximum heart rat achieved|ماکزیمم ضربان قلب به دست آمده|
|Exercise induced angina|آنژین ناشی از ورزش که شامل مقادیر بله و خیر است|
|St depression induced by exercise relative|ایجاد شده موقع تست ورزش وابسته به استراحت st|
|The slop of peak exercise at segment|در زمان حداکثر ورزش که شامل 3 مقدار بالا رفتن، صاف و پایین آمدن قطعه st بیان کننده شیب قطعه است|
|Number of major vessels colored by fluoroscopy|این صفت بیانگر تعداد رگهایی که در فلوروسکوپی دیده میشود|
|Thal|اسکن تالیوم است که شامل 3 مقدار ضایعه ثابت، نرمال و ضایعه قابل برگشت است|
|um|تشخیص بیمارهای قلبی ( وضعیت آنژیوگرافیک بیماری )|
# آزمایشها و متدولوژی
روش های متعددی برای اجرای پروژه های داده کاوی وجود دارد که یکی از روش های قدرتمند در این زمینه ، متدولوژی کریسپ می باشد[ 12 ].این پروژه نیز براساس این متدولوژی تنظیم شده است(شکل 1). در ادامه به بررسی هر یک از این مراحل در جهت رسیدن به مدلی برای پیشگویی احتمال ابتلا به بیماری قلبی می پردازیم.
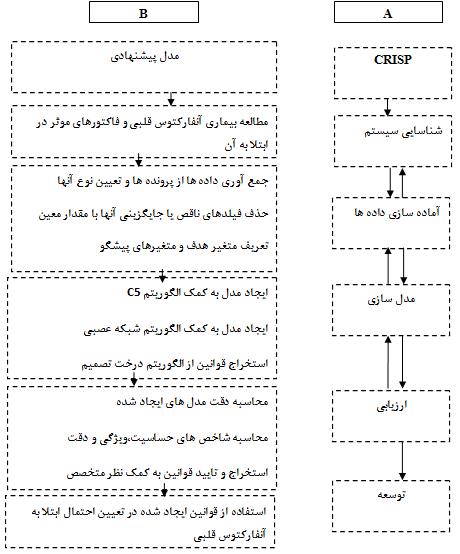
+ **4.1شناخت سیستم**
به کارگیری موفق داده کاوی مستلزم شناخت حوزه ای است که قرار است داده کاوی در آن به کار برده شود و علاوه بر آن شناخت کافی از روش ها و ابزارهای داده کاوی نیز لازم است. به طور کلی تیم داده کاوی بایستی دانش کافی در حوزه ای که قرار است بررسی شود داشته باشند. در گام اول پژوهشگر با مشورت پزشک متخصص قلب و عروق و نیز با مطالعه بر روی بیماری قلبی و تعیین فاکتورهای موثر در ابتلا و همچنین روش های تشخیصی و درمانی و روش های پیشگیری از ابتلا به بیماری، سعی در شناخت کافی حوزه مورد بررسی داشت.
+ **4.2 مرحله آماده سازی داده ها**
در این گام به جمع آوری داده ها از پرونده های بیماران پرداخته شد. داده های استفاده شده در این مطالعه مربوط به پرونده بیماران مراجعه کننده به بیمارستان شهید رجایی تهران در سال 1390 بود. تعداد بیماران مراجعه کننده به این بیمارستان در سال مذکور 1750 نفر بود. حجم نمونه با جدول مورگان 500 بدست آمد که نهایتا تعداد 150 رکورد از آنها به علت عدم تکمیل متغیرهای مورد بررسی ،از پایگاه داده حذف گردید. در این گام بایستی داده هایی که در حال حاضر در دسترس هستند و داده هایی که برای ساخت مدل نیاز بود، تعیین شوند.
متغیرهای تعیین شده، برای ایجاد مدل به دو دسته متغیر هدف و متغیرهای پیشگو دسته بندی شدند.متغیر هدف ابتلا یا عدم ابتلا به بیماری و سایر متغیرها به عنوان متغیر پیشگو مورد استفاده قرار گرفتند. در این پژوهش نیز برای مدیریت داده های از دست رفته ، متغیرها چون به تعداد بسیار کمی در پرونده های مورد مطالعه ثبت شده بودند برای اینکه در فرایند ساخت مدل خللی ایجاد نکنند از مجموعه متغیرها حذف شدند. برای سایر متغیرهایی که مقادیر گمشده شان نسبت به مقادیر موجود ناچیز بود با استفاده از امکانات نرم افزار [SPSS [13 مقدار پیش فرض مربوط به آن جایگزین شدند،که این مقدار با توجه به نوع متغیر انتخاب گردید. فاکتورهایی مانند قد و وزن که به تنهایی ارزشی ندارند بلکه شاخص توده بدنی (Body Mass Index) آن ها تاثیرگذار است، این شاخص به کمک آن ها و با توجه به رابطه زیر بدست آمد:
[14] شاخص توده بدنی = وزن(کیلوگرم)/قد(سانتی متر)
+ **4.3مدل سازی**
روش های داده کاوی متنوعی برای مدل سازی وجود دارد. در این مرحله با استفاده از تکنیک های داده کاوی به ارائه مدل پیشگویانه پرداخته شد. در این مرحله الگوریتم های درخت تصمیم، شامل الگوریتم-های ( C5, QUEST, CHAID ) و شبکه عصبی با بکارگیری متغیرهای ورودی و تعیین متغیر هدف ایجاد شدند. برای ساخت مدل های درخت تصمیم و شبکه عصبی متغیرهای جنسیت، سن، سابقه مصرف سیگار، سابقه اعتیاد، سابقه فشارخون، سابقه چربی خون،فاکتورهای قندی و چربی، شاخص توده بدنی و گروه خونی به عنوان متغیرهای پیشگو تعیین شد و متغیر ابتلا یا عدم ابتلا به بیماری نیز به عنوان متغیر هدف تعیین گردید و در مرحله بعد داده ها به دو بخش آموزش (80 درصد)و آزمون (20 درصد)تقسیم شدند. مدل شبکه عصبی دارای یک لایه ورودی، تعدادی لایه پنهان و یک لایه خروجی است. هر گره ورودی را دریافت کرده، آن را پردازش نموده و خروجی را تولید می کند. تعیین اینکه آیا هر ورودی به گره خروجی خواهد رسید یا خیر به وزن آن ورودی بستگی دارد[15]. یک درخت تصمیم ترکیب تعدادی استلزام منطقی (قانون اگر- آنگاه)است. درخت های تصمیم تنها نمایشی از فرایند تصمیم گیری نیستند بلکه می توان از آن ها در حل مسائل طبقه بندی نیز استفاده کرد . معمولا مجموعه قوانین استخراج شده از درخت تصمیم، مهمترین اطلاعاتی است که از آن ها بدست می آید.
+ **4.4ارزیابی**
در این مرحله پس از ایجاد مدل بایستی به ارزیابی مدل ایجاد شده پرداخت. برای بررسی صحت مدل داده ها به دو دسته آموزش( 80 درصد) و آزمون (20درصد)تقسیم شدند. داده های بخش آموزش مدل را می سازند و داده های بخش آزمون مدل ایجاد شده را مورد ارزیابی قرار می دهند. جهت ارزیابی مدل ها می توان از شاخص های حساسیت، ویژگی، دقت، ارزش اخباری مثبت و ارزش اخباری منفی استفاده کرد. در جدول شاخص های مقایسه دقت الگوریتم شبکه عصبی و الگوریتم های درخت تصمیم ارائه شده است.
حساسیت : یعنی تعداد نمونههایی که به درستی عدم وجود ناراحتی قلبی را نشان داده نسبت به تعداد کل نمونههایی که واقعاً ناراحتی قلبی ندارند.
ویژگی :یعنی تعداد نمونههایی که به درستی وجود بیماری قلبی را نشان داده نسبت به تعداد کل نمونههایی که واقعاً بیماری قلبی دارند.
ارزش اخباری مثبت : یعنی تعداد نمونههایی که به درستی عدم وجود بیماری را نشان داده نسبت به تعداد کل نمونههایی که پیشبینی شده بیماری ندارند.
ارزش اخباری منفی :یعنی تعداد نمونههایی که به درستی وجود بیماری را نشان داده نسبت به کل نمونههایی که پیشبینی شده بیماری دارند.
دقت :یعنی تعداد نمونههایی که به درستی در کلاس مورد نظر تشخیص داده میشوند نسبت به کل نمونهها.
** مقایسه دقت الگوریتم های درخت تصمیم و شبکه عصبی**
|ستون 1 | ستون 2 | ستون 3 | ستون 4 | ستون 5 |
|:--------------------------|:----------:|----------:|:----------:|:----------:|
|معیارها / الگوریتم ها |شبکه عصبی | C5 | CHAID | QUEST |
|حساسیت | 92% | 96% |83% |56% |
|ویژگی |89.5%|91.5%|87%|84.5%|
|ارزش اخباری مثبت |86.2%|89.4%|62.5%|73%|
|ارزش اخباری منفی |93.2%|96.8%|58.33%|71.9%|
|دقت |90.57%|93.4%|85.7%|72.28%|
+ **4.5توسعه**
ساخت مدل معمولا پایان پروژه نیست حتی اگر هدف مدل افزایش دانش است، دانش بدست آمده نیاز به سازماندهی دارد و نمایش به طریقی که کاربر بتواند از آن استفاده کند. دانش کشف شده باید سازماندهی شده و به شکل قابل ارائه برای دیگران درآید. ما در این مرحله سعی کردیم توضیح دهیم که بر اساس مدل های ایجاد شده تاثیرگذارترین فاکتورها در ابتلا فرد به بیماری قلبی کدامند. توجه به اینکه بیماری های قلبی عروقی از جمله شایع ترین بیماری ها و علل مرگ محسوب می شوند، چنانچه بتوانیم یک مجموعه پرخطر را شناسایی و برنامه های غربالگری را برای آن اجرا کنیم ، کارایی برنامه بیشتر خواهد شد.
الگوریتم های مورد استفاده دراین مطالعه، الگوریتم C5 دارای بالاترین میزان دقت ( 93/4 ) بود . در ارزیابی نظرات متخصصان حوزه نیز در مورد قوانین ایجاد شده اعمال می گردد. به این ترتیب که قوانین بدست آمده به متخصص مورد نظر ارائه شده و قوانینی که از نظر بالینی معتبر باشند به عنوان قوانین نهایی ارائه گردیدند. بنابراین طبق نظر متخصص قلب و عروق می توان گفت که ریسک فاکتورهای سن بالا، مصرف سیگار، فشارخون بالا، سطوح بالای کلسترول بیشترین تاثیر را در ابتلا به بیماری قلبی دارا هستند و این در حالی است که براساس مقایسه های انجام شده بر اساس اولویت بندی متغیرها توسط الگوریتم های مورد بررسی نیز ، این متغیرها جزو فاکتورهای اول قرار گرفته اند، که نشان از اهمیت این متغیرها در ابتلا به بیماری قلبی دارد.
# کارهای آینده
بحث و نتیجه گیری
در این تحقیق با استفاده از الگوریتم شبکه عصبی و درخت تصمیم به ارائه مدل و استخراج قوانین آن در راستای پیشگویی احتمال ابتلا به بیماری قلبی پرداختیم. بهترین نتایج از الگوریتم درخت تصمیم C5 بدست آمد که دقت آن 4 /93 درصد بود. بیشترین فاکتورهای تاثیرگذار در ابتلا افراد سن بالا، سابقه فشار خون بالا و چربی خون بالا و مصرف سیگار بودند. با استفاده از قوانین بدست آمده برای یک فرد جدید با داشتن متغیرهای مشخص،می توان تعیین کرد که احتمال ابتلا وی به بیماری قلبی چقدر خواهد بود. در جدول به مقایسه نتایج پژوهش های مشابه با پژوهش حاضر می پردازیم.
مطابق مطالعات گذشته، عملکرد مدلهای طبقه بندی کننده ممکن است بر روی پایگاه های داده مختلف نتایج متفاوتی داشته باشد. برای مثال Karaolis و همکارانش در مطالعه ای تحت عنوان "پیش گویی ابتلا به بیماری عروق کرونر با استفاده از درخت تصمیم گیری" از الگوریتم درخت تصمیم برای ارزیابی ریسک فاکتورهای بیماری عروق کرونر استفاده کردند. آنها ریسک فاکتورهای ابتلا را به دو دسته کلی، ریسک فاکتورهای قبل از رویداد و ریسک فاکتورهای بعد از رویداد تقسیم بندی کرده است[16]. یافته های آن مشابه با قوانین استخراج شده از الگوریتم درخت تصمیم در مطالعه حاضر می باشد.
در بررسی انجام شده توسط Jyoti جهت پیش بینی ابتلا به بیماری قلبی مدل ارائه شده توسط درخت تصمیم دارای بالاترین میزان دقت ( 89 درصد) بوده است [17] . این در حالی است که درخت تصمیم ارائه شده در این مطالعه از دقت بالاتری برخوردار بوده است. تفاوت مشاهده شده را می توان از تعداد بیشتر متغیرهای مورد بررسی در مطالعه اشاره شده دانست.
در مطالعه محمد پور به کاربرد شبکه عصبی در ارزیابی بیماری عروق کرونر قلب پرداخته و حساسیت مدل به دست آمده 96 درصد به دست آمد، که نشان از توان بالای این مدل در تشخیص سریعتر بیمارانی است که نیازمند اقدامات تشخیصی و درمانی هستند. حساسیت بالای مدل ارائه شده در این مطالعه را می توان به کارگیری متغیرهای مفیدی چون نتیجه تست ورزش و نتیجه اکو و همچنین تعیین تعداد نرونهای کمتر در لایه میانی شبکه عصبی بیان کرد [18].
در پژوهش Christine به مقایسه عملکرد [رگرسیون لجستیک](http://amar-pnu-nir.blogfa.com/post-65.aspx) و چند الگوریتم از درخت تصمیم در تعیین ابتلا به بیماری قلبی پرداخته شده است و مدل درخت تصمیم با حساسیت 81 % به عنوان مدل مناسبی جهت پیش گویی معرفی شده است [19].
جدول : مقایسه نتایج مطالعات انجام شده در حوزه داده کاوی در بیماری قلبی
|نویسندگان و سال ارائه تحقیق |الگوریتم های مورد استفاده |نوع بیماری |دقت(نوع) مدل نهائی |یافته ها | متغیرهای پیشگویی کننده |
|:---------------|:-----------:|:------------:|:------------:|:------------:|:----------------:|
|(Christine(1998|رگرسیون لجستیک،درخت طبقه بندی|بیماری قلبی| %81 (درخت طبقه بندی)|عملکرد بهتر درخت تصمیم در پیشگویی ابتلا به بیماری قلبی|سن،سابقه خانوادگی بیماری قلبی، مصرف سیگار، درد در ناحیه قفسه سینه، فشار خون بالا، دیابت، تعریق شبانه، استفراغ، جنسیت و ... |
|(Biglarian(2004 |شبکه عصبی مصنوعی،رگرسیون لجستیک|پیوند عروق کرونری قلب|99/33%(شبکه عصبی مصنوعی)|عملکرد بهتر شبکه عصبی مصنوعی در پیش بینی کننده های مهم مرگ و میر درون بیمارستانی پس از جراحی قلب باز|سن، شاخص توده بدنی، کلسترول، تری گلیسرید، فشارخون، مصرف سیگار، دیابت، چربی خون، سابقه بیماری قلبی و...|
|Kajabadi|درخت تصمیم|بیماری عروق کرونر|محاسبه نشده|عوامل تاثیر گذار عمده بر بروز بیماری قلبی مشخص شده اند.|چربی، فاکتورهای خونی، فاکتورهای چاقی، متغیرهای قندی، متغیرهای عمومی(سن، جنس، استعمال دخانیات و..)، آپولیپویروتئین ها، فاکتور التهابی |
|(Karaolis(2010|درخت تصمیم [C4.5](https://en.wikipedia.org/wiki/C4.5_algorithm)|بیماری قلبی،پیوند عروق کرونر قلبی|66%(درخت تصمیم c4.5 )|عوامل تاثیر گذار عمده بر بروز آنفارکتوس قلبی مشخص شده اند.|جنسیت، سن، فشارخون بالا، چربی خون بالا، مصرف سیگار، سطح کلسترول، دیابت و...|
|(Jyoti (2011 |شبکه بیز درخت تصمیم ،شبکه عصبی مصنوعی |بیماری قلبی|89%(درخت تصمیم)|ایجاد قوانینی جهت یافتن ارتباط بین متغیرها|جنسیت، سن، درد قفسه سینه، فشارخون بالا، قند خون ناشتا، سطح کلسترول، مصرف سیگار، شاخص توده بدنی و...|
|(2011)Mohammadpour |شبکه عصبی مصنوعی |بیماری عروق کرونری قلب|96%(شبکه عصبی مصنوعی )|طبقه بندی صحیح بیماران نیازمند آنژیوگرافی و دارو درمانی |سن، شاخص توده بدنی،کراتینین، کلسترول تام، تری گلیسرید، سابقه مصرف سیگار ،سابقه فشارخون، سابقه دیابت، سابقه بیماری قلبی،نتیجه تست ورزش و ...|
تکنیک های داده کاوی می تواند در طراحی مدل های مناسب جهت پیش گویی امکان ابتلای افراد به بیماری های خاص استفاده شوند و در این مطالعه مدل C5 دارای بالاترین میزان دقت بوده و می تواند در برنامه های غربالگری جهت شناسایی افراد در معرض خطر استفاده شود. پیشنهاد می شود که این مدل با مجموعه داده های بیشتر و در بازه زمانی طولانی تر اجرا شده و پس از رسیدن به سطح دقت مطلوب در برنامه های غربالگری مورد استفاده قرار گیرد. پیشنهاد می شود در مطالعاتی بعدی دقت این مدل در داده های سایر مراکز درمانی و یا سایر مقاطع زمانی مورد ارزیابی قرار گیرد و پس از ایجاد تغییرات ضروری و رسیدن به سطح مطلوب دقت، در انتخاب مدلی جامع و مناسب جهت پیشگویی احتمال ابتلا افراد به بیماری قلبی اقدام شود.
# مراجع
[1] Detrano, R., Janosi, A., Steinbrunn, W., Pfisterer, M., Schmid, J., Sandhu, S., Guppy, K., Lee, S., & Froelicher, V. (1989). International application of a new probability algorithm for the diagnosis of coronary artery disease. American Journal of Cardiology, 64,304--310.
[2] David W. Aha & Dennis Kibler. "Instance-based prediction of heart-disease presence with the Cleveland database."
[3] Gennari, J.H., Langley, P, & Fisher, D. (1989). Models of incremental concept formation. Artificial Intelligence, 40, 11--61.
[4]Huanga M, Chenb M, Leea S. [Integrating data mining with case-based reasoning for chronic diseases prognosis and diagnosis]. Expert Systems with Applications 2007; 32(3): 856–867.
[5] Subbalakshmi G, Road Y. [Decision Support in Heart Disease Prediction System using Naive Bayes]. Indian Journal of Computer Science and Engineering 2011; 2(2): 183-195.
[6] Fayyad M, Piatetsky G, Uthurusamy R, Smyth P. [Advances in Knowledge Discovery and Data Mining]. American Association of artificial intelligence 1996; 17(3): 37-54.
[7] Lavrac N. [Selected techniques for data mining in medicine]. Artificial Intelligence in Medicine 1999; 16(1): 3-23.
[8] Soni J, Ansari U, Sharma D, Soni S.[Predictive Data Mining for Medical Diagnoses: An Overview of Heart Disease Prediction].International Journal of Computer Applications 2011; 17(8): 85-93.
[9] Subbalakshmi G, Road Y. [Decision Support in Heart Disease Prediction System using Naive Bayes]. Indian Journal of Computer Science and Engineering 2011; 2(2): 183-195.
[10]https://en.wikipedia.org/wiki/C4.5_algorithm , http://rulequest.com/see5-comparison.html.
[11]http://www.cise.ufl.edu/~ddd/cap6635/Fall-97/Short-papers/2.htm
[12]Jianxin C, Yanwei X, Guangcheng X, Jianqiang Y, Dongbin Z. [A Comparison of Four Data Mining Models: Bayes, Neural Network, SVM and decision Trees in Identifying Syndromes in Coronary Heart Disease]. Springer- Verlag Berlin Heidelberg 2007:1274–1279.
[13]https://fa.wikipedia.org/wiki/%D8%A7%D8%B3%E2%80%8C%D9%BE%DB%8C%E2%80%8C%D8%A7%D8%B3%E2%80%8C%D8%A7%D8%B3
[14]Sezavar SH, Valizade M, Moradi M, Rahbar M.H. [review of early myocardial infarction and its risk factor in patients hospitalized in Rasool Akram hospital in Tehran]. Hormozgan Medical Journal 2010; 4(2): 156-163. [Persian]
[15]IBM SPSS Modeler CRISP-DM Guide. Available from:www.spss.ch/upload/1107356429_CrispDM1