نتیجه این پروژه تشخیص کلمه حذف شده از یک جمله به زبان فارسی با توجه به ویژگی های ساختی زبان و تکمیل جملات ناقص بر اساس نکات دستوری و معنایی آن جمله میباشد.
۱. مقدمه
حتما برای شما هم پیش آمده است که کلمهای بر نوک زبانتان باشد، اما هر چه فکر میکنید نمیتوانید آن را به خاطر بیاورید. احتمالا با دستنوشتههای بدخط و ناخوانایی مواجه شدهاید و تشخیص برخی از واژهها در آن برایتان دشوار بوده است. شاید شما هم جزء آن دسته از افرادید که دوست دارید یک دستیار توانا و هوشمند در نگارش جملات زیبا کمکتان کند. شخصی را در نظر بیاورید که به دلایل مختلف ،از ناتوانی رنج میبرد و فشردن یک کلید کمتر هم، میتواند به تسریع نگارش او کمک بزرگی نماید.
با اندکی جستوجو در مییابید که چنین سیستمها و ابزارهایی برای زبانهای رایج دنیا ، از جمله انگلیسی، به فراوانی یافت میشود. اما متاسفانه کمبود چنین دستیارهای هوشمند و پرکاربردی، در زبان فارسی بیشتر به چشم می خورد. شاید یکی از دلایل عمده آن، پیچیدگیها و چالشهای پیش روی پردازش زبان مادریمان باشد.
به هر حال در این مقاله قصد داریم به شرح و پیادهسازی سیستمی برای پیشبینی واژهها1 دریک جملهی زبان فارسی بپردازیم.
۱.۱. چالشهای پردازش زبان فارسی [2]
زبان فارسی از جمله زبانهای پیچیده در مراحل پردازشی و پیشپردازشی زبانهای طبیعی به شمار میآید. برخی از این موارد عبارتند از:
۱.۱.۱. فاصله و نیمفاصله 2
یکی از مهمترین مشکلات زبان فارسی، فاصلههای میان واژهها است. در مواردی لازم است بجای فاصله، یک نیمفاصله قرار گیرد و یا برعکس؛ معمولا کاربرها در هنگام تایپ این موضوع را رعایت نمیکنند. مثلا در واژهی " ناامید " ممکن است میان " نا " و " امید " فاصله یا نیمفاصله قرار دهند.
۱.۱.۲. ابهام در یونیکد3
چون زبان عربی و فارسی کاراکترهای یکسان با یونیکدهای متفاوت دارند، برای هر کاراکتر چندین یونیکد مختلف وجود دارد. مثلا کاراکتر " ی " 56 کد مختلف با شکل مشابه دارد.
۱.۱.۳. کاراکترهای نامتداول4
برخی از کاراکترها مانند " ء " ، " ؤ " ، " أ " و" إ " ممکن است در دستنوشتهها هم به کار برده نشوند اما وجود آنها ابهام را در پردازش زبان طبیعی زیاد مینماید. البته در بیشتر موارد با جایگزینی این کاراکترها با پرکاربردترین آن، معنی واژه تغییر نمیکند و میتواند راه حل مناسبی باشد.
۱.۱.۴. آواها5
در فارسی شش مصوت وجود دارد که معمولا درنگارش استفاده نمیشوند مگر آن که نبود آن ابهام ایجاد نماید. اما بههر حال در مواردی وجود این آواها در نوشتار میتواند مشکلساز شود.
۱.۱.۵. کلمات چنداملایی
در زبان فارسی برخی از کلمات دارای چندین صورت املایی مختلف میباشند.
۱.۲. پیشپردازش زبان طبیعی6
قبل از شروع پردازشهای مورد نظر روی زبانهای طبیعی، لازم است تا پیشپردازشهایی روی آن صورت گیرد تا اطلاعات مورد نیاز از متن زبان مقصد بهدست آید. برای این کار روشهای متعددی وجود دارد که هرکدام بهدنبال استخراج اطلاعاتی خاص از زبان میباشند. از جمله این روشها میتوان به نرمالسازی7، قطعهبندی8، ریشهیابی9، لمیابی10، برچسبگذاری اجزای کلام11 و... اشاره نمود که در ادامه برخی از این روشها به اختصار آوردهشدهاند.
۱.۲.۱. نرمالسازی یا یکسانسازی
وظیفه یکسانساز، یکسانسازی برخی نویسهها و حذف حرکتهای موجود در متن میباشد. این کار به سبب وجود نویسههای متفاوت برای یک حرف در رسمالخط فارسی جزء ضروریات اولیه میباشد. نویسههایی مانند "ی"، "ک"، "الف" و ... در این قسمت یکسانسازی شده و حرکتهایی مانند انواع تنوین، همزه، تشدید و ... در این قسمت حذف میشوند. [2]

۱.۲.۲. قطعهبندی
همانطور که از نام آن پیداست هدف از پیشپردازش قطعهبندی، جداسازی کاراکترهای تشکیلدهندهی متن به دنبالهای از کلمات میباشد. ازجمله کارهایی که در این قسمت انجام میشود اصلاح فاصلههای نادرست میان کلمات مرکب و پیشوندها و پسوندها است تا واژهها، نوشتار و معنای درست خود را حفظ نمایند.

قطعهبندی و تشخیص صحیح مرز کلمات و عبارات در بسیاری از سیستمهای پردازش زبان طبیعی مانند تشخیص گروه های نحوی و پردازش آنها در سیستمهای ترجمه ماشینی، استخراج اطلاعات، سیستم پرسش و پاسخ، تشخیص نقش های موضوعی، موتورهای جستجو و غیره نقش کلیدی ایفا میکند. با توجه به این کاربردها، قطعهبندی صحیح کلمات می تواند موجب بهبود در بازدهی فعالیتهای ذکرشده شود. در زبان فارسی به علت وجود فاصله و نیمفاصله، عدم توجه کاربران به فاصلهگذاریها و نبود قواعد دقیق در نوشتن کلمات چندقسمتی، تشخیص و قطعهبندی کلمات چندقسمتی و مرکب با مشکلات و پیچیدگیهای خاص خود روبهرو است. [6]
۱.۲.۳. ریشهیابی
در زبان فارسی واژهها با توجه به نقش معنایی و نحوی خود در جمله به شکلهای ظاهری متفاوتی حضور مییابند؛ این شکل ظاهری متفاوت از جهتی نشاندهندهی معنای متفاوت این واژههاست، اما با توجه به این که تمامی آنها از یک ریشه مشتق شدهاند، از نظر معنا قرابت نسبتا زیادی خواهند داشت. ازهمین رو در بسیاری از کاربردهای پردازش زبان طبیعی و بازیابی اطلاعات، نیاز داریم تا همه مشتقات یک واژه را به ریشهی آن، که همان شکل سادهی واژه میباشد، تبدیل نماییم. ریشهیاب فارسی همانند ریشهیابی در الگوریتم پورتر12 است که اساس کار در هردو ریختشناسی13 زبان مقصد است و به سبب همین امر، تفاوتهایی نیز میانشان است. برای مثال در الگوریتم پورتر نیاز است تا آواها در ریشهیابی کلمات در نظر گرفته شود، در صورتی که در زبان فارسی این آواها نوشته نمیشوند. در تصویر زیر نمونهای از یک ماشین حالت14، برای ریشهیابی در زبان فارسی آوردهشدهاست.[3]

۱.۳. پردازش زبان فارسی15
در این مرحله باید با توجه به اطلاعات بهدست آمده از پیشپردازشها، به پردازش زبان فارسی برای دستیابی به هدف مورد نظر، یعنی پیشبینی واژه در ساخت جملات، پرداخت. شرح این موضوع و روشهای آن در بخش بعدی بررسی خواهد شد.
۲. کارهای مرتبط
در این قسمت، ابتدا به روشهای پردازش زبان فارسی به منظور ایجاد سیستمی برای پیشبینی واژه میپردازیم. سپس یکی از الگوریتم بهکار بردهشده در چنین سیستمی را شرح خواهم داد و در پایان یک ابزار مرتبط با این پروژه و پردازش زبان فارسی را معرفی مینمایم.
۲.۱. متودولوژی16های پیشبینی کلمه[1]
در این قسمت به شرح سه راهبرد اصلی که تا کنون در چنین سیستمهایی بهکار بردهشدهاست میپردازیم.
۲.۱.۱. مدلسازی آماری17
در مدلسازی آماری، انتخاب کلمات براساس احتمال ظاهر شدن یک رشته در یک متن میباشد. از این رو به چنین مدلسازی، مدلسازی احتمالی نیز میگویند. اطلاعات آماری و جداول توزیع آن میتواند برای پیشبینی حروف، کلمات، عبارات و حتی جملات مورد استفاده قرار گیرد.
پیشبینی حروف18
احتمالا با این تکنولوژی در تلفنهای همراه برای نوشتن یک پیامک و یا یک متن آشنا هستید. این تکنولوژی میتواند کمک قابل توجهی در تسریع عمل نگارش در این دستگاهها نماید. از سه متودی که در این تکنولوژی رایج است میتوان به روش پیشبینیکنندهی مبتنی بر واژهی متن ورودی، واژهی معقول و حرف معقول اشاره نمود.
پیشبینی کلمات
این سیستمها سعی دارند کلمات مقصود کاربر را حدس بزنند و آنها را در لیستی از واژهها در اختیار او قرار دهند. در این سیستمها مدلسازی آماری زبان بیشترین کاربرد را دارد. اساس چنین سیستمهایی فرض مارکو19 است که میگوید تنها n-1 کلمهی قبلی در انتخاب کلمهی بعدی تاثیر میگذارند. از این رو به آن مدل n-gram مارکو نیز میگویند. فرکانس واژه و فرکانس دنبالهی واژه از متودهای رایج در این سیستمها هستند.

۲.۱.۲. مدلسازی دانشمحور20
سیستمهایی که کمتر از مدلهای آماری بهره میبرند، معمولا خطاهای نحوی، معنایی و گرامری در پیشنهادهایشان وجود دارد. بدین ترتیب سرعت تایپ کاربر را پایین میآورند. حذف واژههای نامناسب موجب افزایش سرعت و البته اعتمادبهنفس کاربر در نگارش متون میشود. بنابراین میتوان از دانشهای زبانی برای بهبود لیست کلمات پیشنهادی بهره برد. این دانشها در سه زمینهی نحوی، معنایی و گرامری مورد استفاده قرار میگیرد.
برای مثال در پیشبینی نحوی، سیستم با استفاده از برچسبهای POS21 که برای تمامی کلمات موجود است و با استفاده از قواعد نحوی زبان، کلمات نامناسب را از لیست پیشنهادی حذف مینماید. البته این سادهترین روش آن است. در روشهای پیچیدهتر سیستم با استفاده از کلمات قبلی و بعدی و برچسبهای POS آنها سعی در محاسبهی احتمال کلمات کاندید مینماید.
۲.۱.۳. مدلسازی اکتشافی (انطباقی)22
برای ایجاد پیشبینیهای دقیقتر و مناسبتر برای یک کاربر خاص، از روشهای تطبیق استفاده میشود. در این متولوژی سیستم سعی دارد با هر کاربری به طور جداگانه انطباق پیدا کند و در واقع به نوعی سعی دارد با توجه سبک نگارش و کلمات استفاده شده توسط کاربر پیشنهادات خود را به نظر او نزدیکتر نماید. دو روش معمول در چنین سیستمهایی یادگیری کوتاهمدت و یادگیری بلندمدت است.
در یادگیری کوتاهمدت سیستم تنها با توجه به نوشتهی جاری سعی در تطبیق خود با کاربر دارد و در این راه از متودهای مختلفی از جمله ارتقاء تاخر، هدایت موضوع و کش n-gram بهره میبرد.
در یادگیری بلند مدت در کنار نوشتهی جاری از نوشتههای قبلی کاربر نیز جهت تطبیق و همگامسازی سیستم استفاده میشود. بنابراین با استفادهی بیشتر از سیستم درصد انطباق آن با کاربر بیشتر و بیشتر میشود. از جمله متودهایی که در تطبیق اکتشافی کاربرد دارد میتوان به اضافه نمودن واژهی جدید، کپیتال نمودن خودکار و ایجاد ترکیبهای جدید نام برد.
۲.۲. بررسی یک الگوریتم[4]
در این بخش به بررسی یک الگوریتم پیشنهادی و فلوچارت آن می پردازیم و همچنین در بخش بعدی روش خود را ارایه خواهیم نمود.

این سیستم از چهار بخش اصلی تشکیل شدهاست:
الف) اطلاعات آماری از قسمت training corpus برای الگوریتم پیشبینی استخراج میشود.
ب) برنامهی پیشبینیکنندهای که سعی بر پیشنهاد کلمه به کاربر دارد. این بخش خود شامل دو قسمت تکمیل واژه و پیشبینی واژه میباشد. الگوریتم پیشبینی ابتدا کلمهی ناقص را تکمیل نموده و سپس لیستی از کلمات مناسب و محتمل را پیشنهاد میدهد.
ج) کاربر شبیهسازیشدهای که نوشته را وارد مینماید. این کاربر واژههای مناسب و زیبا را انتخاب نموده و آن را از دست نمیدهد.
د) بخشی که بروزرسانی اطلاعات آماری مربوط به تاخر کلمات مورد استفاده و اضافه نمودن واژههای جدید بهمراه فراوانی استفاده به عهده دارد.
برای همگامسازی سیستم با کاربر دو فرآیند انجام خواهد شد. یکی استخراج تککلمهای ، دوکلمهای و سهکلمهای از متن جاری و دیگری ذخیره و بروزرسانی اطلاعات آماری در یک فایل پویا. این درحالی است که اطلاعات اخیر مربوط به فایل استاتیکی بوده که اطلاعات آماری یادگرفته شده را در خود ذخیره مینمود. در هنگام پیشبینی واژه، ابتدا به سراغ فایل پویا23 میرود و وزن بیشتری به کلماتی که اخیرا مورد استفاده قرار گرفته داده میشود. سپس به سراغ فایل استاتیک24 رفته و از آن استفاده مینماید.
به این ترتیب هرچه این سیستم بیشتر مورد استفاده قرار گیرد، بیشتر با سبک نگارش کاربر منطبق میشود و در نتیجه کلمات مناسبتری را پیشنهاد میدهد.
۳. پیادهسازی
در این فاز تصمیم بر آن شد که پیادهسازی اولیه روی زبان انگلیسی صورت گیرد تا از چالش های پیش روی زبان فارسی و یونیکدها صرف نظر شود و تنها به جنبهی روشهای پیادهسازی و حل مسئله بپردازیم. البته با وجود ماژول قدرتمند هضم که برای پردازش زبان فارسی و همینطور پشتیبانی بسیاری از ماژولهای مورد استفاده از یونیکدها، در فاز پایانی علاوه بر بهبود نتایج در زبان انگلیسی به پیادهسازی در زبان فارسی نیز پرداختهایم. لینک گیت هاب پروژه در این قسمت قابل دسترسی است.
۳.۱. روشها
پیادهسازی این پروژه با چالشهای بسیاری همراه بود. فرض کنید یک جمله ناقص را میخواهید کامل نمایید. ابتدا باید از نظر ساختار و گرامر جمله، نقش کلماتی که میتوانند در جای خالی قرار گیرند را تشخیص داده و با توجه به معنای جمله کلمهای مناسب از دایرهی لغات در دسترس پیشنهاد دهید!
اما واقعا اجرای این اعمال برای یک ماشین چگونه امکانپذیر است؟
تاکنون تحقیقات زیادی در این زمینه صورت گرفته است و به روش های مختلفی سعی در ایجاد درکی از واژهها، در یک ماشین شده است. یکی از روش های کارآمد، یادگیری عمیق با استفاده از الگوریتم word2vec گوگل می باشد. سرعت این یادگیری هم بسیار بالاست و در عرض چند ساعت و یا چند دقیقه میتوان حجم عظیمی از داده ها را به این الگوریتم داد و بردارهای لغات را ایجاد نمود. این روش که الگوریتم آن به صورت متن باز نیز منتشر شده است و کتابخانههای مختلفی برای زبانهای مختلف برای کار با آن تولید شده است، زمانی که توسط گوگل بر روی حجم بالای متون و اطلاعات به کار رفته است ، نتایج بسیار شگرفی را به همراه داده است . مثلا اگر بردار لغت پادشاه را منهای بردار لغت مرد کنیم ، نتیجه به بردار کلمه ملکه بسیار نزدیک است.
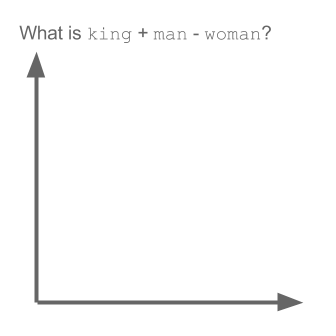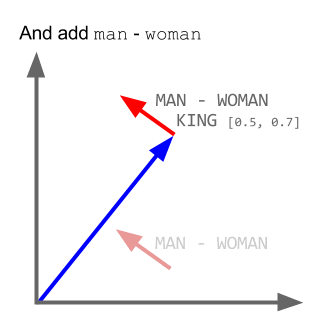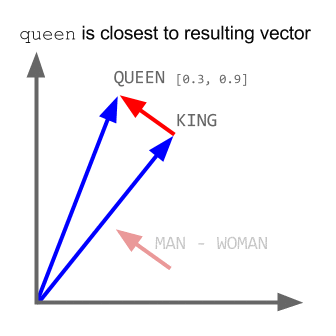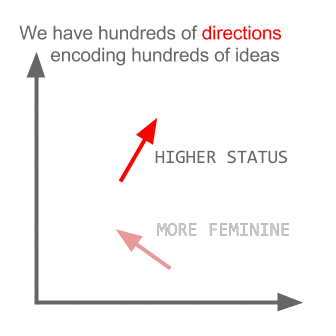
ما از این الگوریتم برای یافتن کلمات مشابه و نزدیک استفاده مینماییم. کتابخانه ی gensim پایتون پیادهسازی کاملی از این الگوریتم ارائه داده است.
اما قبل از استفاده از آن باید یک کلمه مناسب برای جای خالی پیدا کنیم و قبل از آن هم نقش جای خالی. با استفاده از کتابخانهی بسیار قدرتمند nltk و همچنین وزن دهی مناسب به برخی از قواعد گرامری زبان انگلیسی به نتایج خوبی دست یافتیم. همچنین با استفاده از یادگیری 3-گرم25 عبارات پرکاربردی که در محدوده ی جای خالی مورد نظر قرار می گرفت را پیدا و کلمه ی مناسبی با توجه نقش به دست آمده، انتخاب مینماییم.( البته گاهی این کلمه معنای مناسبی به جمله نمیداد)
در پیادهسازی پروژه برای زبان فارسی تنها تحلیلگر دستوری متفاوتی نیاز بود و تحلیلگر معنایی مورد استفاده در زبان انگلیسی در این قسمت نیز نتایج مورد انتظار را میدهد. برای پیاده سازی تحلیلگر نحوی زبان فارسی از ماژول قدرتمند هضم و ساختار جملات فارسی استفاده مینماییم.
۳.۲. دادههای زبان انگلیسی
دیتاست مورد استفاده در این بخش، یک مجموعه 200 مگابایتی است که در هر خط آن یک جملهی انگلیسی قرار دارد. این دیتابیس در یادگیری word2vec به کار گرفته شده است. البته این الگوریتم قادر است حجم خیلی بیشتری از داده را در زمانی نسبتا کوتاه تمرین نماید. در واقع دقت این الگوریتم در حجم هایی از داده در حدود چندین گیگابایت بسیار خیرهکننده است ولی در همین حدود برای آزمایش کفایت میکند.
همچنین از کرپوس برون26 کتابخانهی nltk برای یادگیری مدل 3-گرم استفاده شده است که با استفاده از توابع داخلی این ماژول مجموعهای از کلمات در قالب جملات به 3-گرم داده می شود و این مدل بر اساس تکرارهای پیش آمده به هر تکرار سهتایی یک امتیاز می دهد.
۳.۳. دادههای زبان فارسی
از آنجا که دیتاست مورد نظر برای این یادگیری در زبان فارسی موجود نبود، تصمیم بر آن شد تا آن را با استفاده از دیتاستهای موجود در زبان فارسی مانند پیکرهی بیجنخان و پیکرهی همشهری استخراج نماییم. برای بهبود نتایج باید جملات با استفاده از ماژول هضم به فرم نرمال درمیآمد و سپس در هر خط یک جمله قرار میگرفت. همچنین با توجه به گوناگونی اشکال کللمات در فارسی، باید حجم بیشتری از جملات مورد استفاده قرار میگرفت و به این ترتیب از یک دیتاست 400 مگابایتی استفاده شد.
همچنین در این پیادهسازی بجای nltk از هضم استفاده نموده و این ماژول از روی پیکرههایی مانند درخت وابستگی نحوی و ... یادگیری را انجام داده و بنابراین به طور غیر مستقیم از این پیکرهها نیز استفاده نمودهایم.
۴. آزمایشها
۴.۱. محاسبهی دقت
در این قسمت برای ارزیابی کارایی الگوریتم، به محاسبه درصد دقت آن میپردازیم. از آنجا که روش دقیق و سازمان یافته ای برای محاسبه ی دقت خروجی وجود نداشته، با بررسی خروجی، جملات معقول را به عنوان نتیجهی مطلوب در نظر میگیریم. لازم به ذکر است منظور از جملات معقول جملاتی است که در زبان حداقل یک مکالمه برای آن وجود داشته باشد. به عبارت دیگر این جمله از نظر لغوی، نحوی و معنایی درست باشد.
۴.۱.۱. دقت پیادهسازی زبان انگلیسی
دقت تحلیلگر دستوری
در این قسمت بیست آزمایش انجام شد و خوشبختانه 13 مورد از نتایج قابل قبول بود. این سطح دقت یعنی 65% بنظر امیدوار کننده می باشد. البته جا دارد که این قسمت را با تغییر وزن داده شده و یا حتی آموزش آن بهبود بخشید.
دقت تحلیلگر معنایی
در این بخش نیز ده آزمایش صورت گرفت و در هر آزمایش نسبت تعداد جملات قابل قبول بر تعداد کل جملات خروجی را برابر درصد دقت در نظر گرفتیم. نتایج به شرح زیر است:
| شماره آزمایش | تعداد خروجی | تعداد صحیح | درصد دقت |
|---|---|---|---|
| 1 | 9 | 4 | 44% |
| 2 | 11 | 5 | 45% |
| 3 | 7 | 4 | 57% |
| 4 | 10 | 3 | 30% |
| 5 | 10 | 6 | 60% |
| 6 | 8 | 2 | 25% |
| 7 | 3 | 1 | 33% |
| 8 | 7 | 3 | 43% |
| 9 | 7 | 4 | 57% |
| 10 | 12 | 5 | 41% |
همانطور که مشاهده می شود در این قسمت پروژه هنوز دارای ضعفهایی است که باید بهبود یابد ولی با این حال میانگین دقت 43.5 درصد بنظر قابل قبول است.
در زیر نمونه ای از خروجی نهایی برنامه را مشاهده مینمایید.

بهبود نتایج
در این قسمت با آزمایشهای مختلف و وزندهی مناسب در توابع پیادهسازی شده برای تعیین احتمال نقش کلمهی جا افتاده، سعی در بهبود تحلیلگر دستوری داشتیم و تنوانستیم در آزمایش قبل به 15 پاسخ مطلوب از 20 مورد آزمون دست یابیم و بنابراین 10 درصد عملکرد این بخش بهبود یافت. البته چون نقش کلمهی جا افتاده در موردهای آزمون بخش تحلیلگر معنایی به طور مناسب تشخیص داده شده بود، در این بخش به همان دقت میانگین 43.5 درصد دست یافتیم. البته قطعا بهبود تحلیلگر دستوری، سبب افزایش دقت تحلیلگر معنایی خواهد بود و این موضوع زمانی قابل مشاهده است که تحلیلگر دستوری بهبود یافته نقش مناسبی را تعیین نماید که در تحلیلگر دستوری قبلی نامناسب و اشتباه بود. همچنین از یک بررسیکنندهی گرامر برای رفع اشکالات جزئی گرامری استفاده شده است.
۴.۱.۲. دقت پیادهسازی زبان فارسی
دقت تحلیلگر دستوری
در این قسمت نیز بیست آزمایش انجام شد و 11 مورد از نتایج قابل قبول بود. این سطح دقت یعنی 55% برای زبان فارسی و با توجه به ساختار پیچیدهتر آن نسبت به زبان انگلیسی قابل قبول می باشد.
دقت تحلیلگر معنایی
در این بخش نیز همانند آزمون زبان انگلیسی ده آزمایش صورت گرفت و در هر آزمایش نسبت تعداد جملات قابل قبول بر تعداد کل جملات خروجی را برابر درصد دقت در نظر گرفتیم. نتایج به شرح زیر است:
| شماره آزمایش | تعداد خروجی | تعداد صحیح | درصد دقت |
|---|---|---|---|
| 1 | 6 | 1 | 17% |
| 2 | 6 | 2 | 34% |
| 3 | 8 | 3 | 37% |
| 4 | 5 | 1 | 20% |
| 5 | 13 | 2 | 15% |
| 6 | 9 | 4 | 44% |
| 7 | 11 | 5 | 45% |
| 8 | 8 | 3 | 37% |
| 9 | 8 | 1 | 12% |
| 10 | 5 | 2 | 40% |
در این پیادهسازی میانگین درصد دقت از آزمونهای انجام شده برابر 30.1 درصد میباشد و با توجه به مشکلات پیش روی زبان فارسی که قبلا هم ذکر شد، بنظر چنین درصد دقتی قابل قبول است.
۵. کارهای آینده
میتوان گفت این پروژه یکی از چالشهای مهم آیندهی پردازش زبان طبیعی خواهد بود. در یک نسخهی کامل و کارا میتواند کمک شایان توجهی به آموزش زبانهای جدید نماید و یا حتی با اندکی تغییر در زمینهی بهبود وتصحیح متون مفید باشد. ترکیب این پروژه با یک برنامه متنخوان میتواند در خواندن و تحلیل متون چاپی و همچنین برای بازیابی متون نوشتهها و کتب قدیمی (که احتمال دارد کلماتی از متن پاک شده باشند یا قابل خواندن نباشند) مورد استفاده قرار گیرد.
۶. مراجع
[1] MasooGhayoomi, Saeedeh Momtazi; "An Overview on the Existing Language Models for Prediction Systems as Writing Assistant Tools" ; Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics; Saarland University
[2] Zahra Sarabi, Hooman Mahyar, Mojgan Farhoodi; "ParsiPardaz: Persian Language Processing Toolkit" ; Cyber Space Research Institute, Tehran,2013
[3] Kazem Taghva, Russel Beckley, Mohammad Sadeh; "A Stemming Algorithm for the Farsi Language"; Iformation Science Research Institute; Unversity of Nevada, 2003
[4] Masood Ghayoomi, Seyyed Mostafa Assi; "Word Prediction in a Running Text: A Statistical Language Modeling for the Persian Language" ; institute for Humanities and Cultural Studies, Tehran
[5] Ciprian Chelba,Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, Tony Robinson; "One billion Word Benchmark for Measuring Progress in Statistical Language Modeling"; "GOOGLE" ; University of Edinburgh
[6]محمدمهدی میردامادی، علی محمد زارع بیدکی و مهدی رضائیان؛"قطعه بندی عبارات متون فارسی با استفاده از شبکه های عصبی"؛ نشریه مهندسی برق و مهندسی کامپیوتر ایران، ب- مهندسی کامپیوتر، سال 11 ، شماره 2، زمستان 1392
word prediction
Space and half space
Unicode ambiguity
Uncommon characters
Diacritical mark
Natural Language Preprocessing
Normalizer or Unification
Segmentation
Stemming
Lemmatization
POS Tagger
Porter
Morphology
state machine
Natural Language Processing
methodology
Statistical Modeling
letter prediction
Markov assumption
Knowledge-based Modeling
Part-of-speech
heuristic Modeling(Adaptation)
dynamic
static
Trigram
brown corpus