برای دریافت داده و اطلاعات بیشتر میتوانید به [صفحه مربوط به این مسابقه](https://www.kaggle.com/c/predict-wordpress-likes) مراجعه کنید.
#مقدمه:
سایت وردپرس یکی از محبوب ترین پلتفرمهای ارائه دهنده خدمات بلاگ در دنیاست که نزدیک به نیمی از ۷۴ میلیون سایت وردپرسی (۱۶ درصد از کل دامنههای وب) روی این سایت هاست شده است. در این پروژه میخواهیم یک سامانه توصیهگر آموزش دهیم که پیش بینی کند کدام کاربر، کدام پست از میان ۹۰ هزار بلاگ فعال را دوست خواهد داشت و اصطلاحا لایک میکند.
به این آمارها نگاهی بیاندازید:
+ ۶۱ درصد کاربران آمریکایی با توجه به توصیههای یک وبلاگ، دست به خرید زدهاند.
+ ۸۱ درصد کاربران آمریکایی به وبلاگها اعتماد داشته، توصیهها و اطلاعات مندرج در وبلاگ ها را میپذیرند.
+ بازاریابهایی که از وبلاگ استفاده میکنند، ۶۷ درصد بیش از دیگران میتوانند مشتریان کلیدی (Lead) به دست آورند.
+ در شرکتهایی که وبلاگ دارند، لینکهای ورودی به سایت (inbound links) تا ۹۷ درصد بیشتر است.
+ ۶۰ درصد کاربران وقتی محتواهای سفارشی یک شرکت را بر سایتش مطالعه میکنند، دید مثبتی نسبت به آن کمپانی پیدا میکنند.
امروزه اهمیت وبلاگها و تاثیرات آن بر زندگی افراد جامعه غیر قابل انکار میباشد و با توجه به انبوه وبلاگها، پستها و نیز ارزشمند بودن وقت کاربران و وجود چنین نقش پررنگی در زندگی مردم جامعه، در دسترس بودن پستهای دستچین شده بر حسب سلیقه شخصی کاربران، لازم و با ارزش بنظر میرسد.
پاسخ دادن به سوال "چه کسی این نوشته را دوست خواهد داشت؟ " علاوه بر راحتی کاربران و اراعه پستهای مورد پسندشان به ترتیب اولویت و نیز جلوگیری از اتلاف وقت آنها، سبب دستیابی به اطلاعات مهم دیگری نیز میشود، از جمله:
مشخص شدن علاقه مندیها و موضوعات محبوب و رایج درجامعه
مشخص شدن افراد و بلاگرهای تاثیرگذار برجامعه
تحلیل موضوعات مختلف با توجه به افرادی که آن را تایید و پسند میکنند
# کارهای مرتبط:
برای رسیدن به پاسخ این سوال باید :
۱-موضوع اصلی پست را پیدا کنیم.
۲-برای هر کاربر موضوعات محبوب را شناسایی کنیم.
۳- کاربرانی که موضوع پست جز موضوعات محبوب آنها بوده و نیز وبلاگ وبلاگ محبوبشان است ان را لایک میکنند.
برای هر کدام از موارد بالا باید بهترین الگوریتم را بیابیم. برای این منظور مطالب زیر مفید خواهند بود:
در مقاله برچسب زنی موضوعی متون فارسی مطالب زیر مفید خواهند بود:
۱-تشخیص موضوع متن:
برچسب زنی موضوعی متون امری مهم در حوزه بازیابی اطلاعات میباشد. این امر به نوعی دسته بندی یا طبقه بندی متون در زبان طبیعی است. سیستم معمولا روی یک دسته از متون از قبل برچسب زنی شده آموزش داده می شود و سپس با استفاده از مدل های حاصل از مرحلۀ آموزش، طبقه بندی متون جدید صورت میگیرد. امروزه دسته بندی متون در بسیاری از زمینه ها از جمله فیلترکردن متون مخصوصا نامه های الکترونیکی، تشخیص طبقه، ابهامزدایی از کلمات، سیستم های خودکار پاسخ به سوالات و یا حتی نمره دهی به مقالات در سیستمهای آموزشی و به طور کلی در هر کاربردی که سازماندهی مستندات و یا توزیع انتخابی و
تطبیقی خاصی از مستندات مد نظر باشد، کاربرد دارد. برچسب زنی موضوعی متون با مسائلی چون استخراج اطلاعات و دانش از متون و داده کاوی متون دارای ویژگی های فنی مشترک میباشد.
روش کار:
الف).نرمالسازی متن :
تمامی حوزه های مرتبط با پردازش زبان طبیعی به نحوی از انحنا با متون واقعی سروکار دارند. صورتهای غیر استاندارد نویسه ها وکلمات به وفور در این نوع متون دیده میشوند . قبل از اینکه بتوان از این متون به منظور استفاده در سیستم های تبدیل متن به گفتار، ترجمه ماشینی، بازشناسی حروف فارسی، خلاصه ساز فارسی، جستجو در متون فارسی استفاده کرد و یا در پایگاه داده ذخیره شان کرد، باید ابتدا پیشپردازشی روی آنها انجام گیرد، تا صورت های غیرستاندارد1 به شکل استاندارد تبدیل گردند. اگر حروف، نشانه های نگارشی و کلمات فارسی به شکل یکسانی نوشته نشوند، متون مورد استفاده قابل تحلیل توسط سامانه های رایانه ای نخواهند بود. طی فرایند نرمال سازی علایم نگارشی، حروف، فاصلههای بین کلمات، اختصارات وغیره بدون ایجاد تغییرات معنایی در متن به شکل استانداردشان تبدیل میگردند.
ب)الگوریتم بردار فاصله :
الگوریتم پیشنهادی برای برچسب زنی موضوعی بدین صورت عمل میکند که ابتدا تعدادی کلمه از بین کلمات دادگان آموزشی به عنوان کلمۀ کلیدی انتخاب میشود نحوة استخراج کلمات کلیدی در بخش بعد توضیح داده شده است. در مرحلۀ بعد بسامد وزندار کلمات کلیدی در متون آموزشی مربوط به هر موضوع استخراج میشود. به ازای هر موضوع، بردار بسامد وزن دار کلمات کلیدی به عنوان بردار نمایندة آن کلاس در نظر گرفته میشود. در مرحلۀ آزمون، برای برچسبزنی موضوعی به یک متن جدید، ابتدا بردار بسامد وزندار کلمات کلیدی متن جدید استخراج گشته و سپس فاصلۀ این بردار با تک تک بردارهای مربوط به کلاسها سنجیده میشود. کلاس یا موضوعی که بردار مربوط به آن کمترین فاصله را از بردار ورودی داشته باشد، به عنوان محتمل ترین موضوع برای متن جدید در نظر گرفته می شود. در این مقاله از معیار کسینوسی به عنوان :معیار فاصلۀ بین بردارها استفاده شده است. در این روش موضوع متن جدید از رابطۀ زیر به دست می آید:
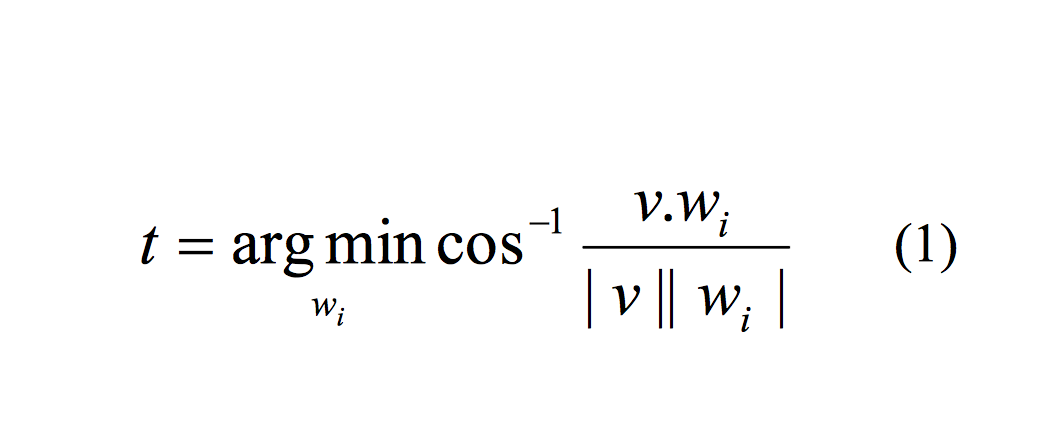
که v بردار مربوط به متن جدید و wi بردار مربوط به موضوع i میباشد.
ج)استخراج کلمات کلیدی:
مهم ترین و پایهایترین بخش سیستم طبقه بندی کننده متون،تهیه کلمات کلیدی است. تهیه این مجموعه لغات با در دست داشتن پیکره متنی زبان فارسی صورت پذیرفت. روشهای گوناگونی برای استخراج کلمات کلیدی وجود دارد که معروفترین آنها حاصلضرب tf-idf میباشدکه در آن tf متناسب با بسامد یک کلمه در مستند و idf یک فاکتور وزنی است که بیانگر معکوس میزان پراکندگی یک کلمه در سندهای مختلف است. برای استخراج کلمات کلیدی، tf-idf را برای هر کلمۀ i به روش زیر بهدست می آوریم:
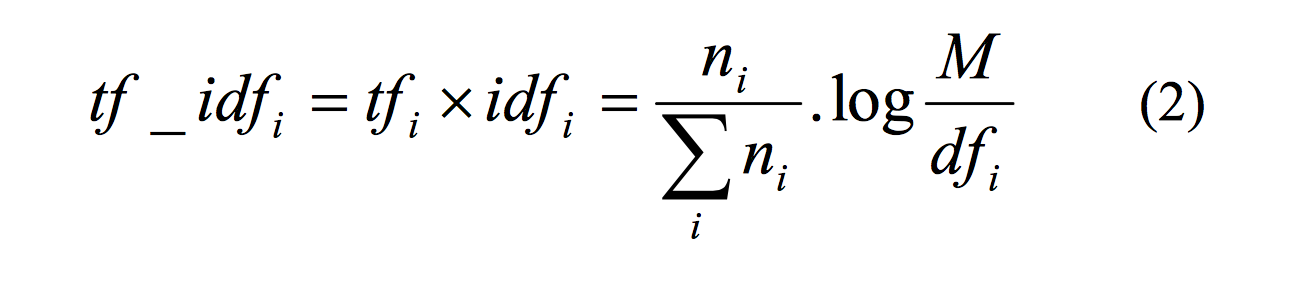
در فرمـول۲، ni تعـداد کلمـۀ i در زیرپیکـره، M فراوانـی کـل سندها در زیر پیکره و dfi تعداد مستنداتی است که شامل کلمۀ i میباشند. با در نظر گرفتن حد آستانه ای روی tf-idf مـی تـوان کلمات کلیدی را انتخاب کرد. کلمات کلیدی کلماتی هستند کـه دارای tf-idf بالایی باشند. با توجه به تعریف فاکتور tf-idf روشن است که به دلیل وجود فاکتور tf کلماتی که بسامد وقـوع بـالایی دارند امتیاز بیشتری برای انتخاب به عنوان کلمه کلیدی خواهند داشت. در عین حال این توضیح لازم است که تمام کلمـاتی کـه دارایtf بالایی هستند،ارزش استفاده در فرآیند طبقه بنـدی را ندارند. برای مثال میتوان به کلمۀ "است" اشاره داشت که تعداد
وقوع بسیار بالایی دارد اما کلمۀ کلیدی محسـوب نمـیشـود. در اینجافاکتور idfبه کارمی آید.این فاکتور در مورد کلماتی کـه در تعداد محدودی از مدارک دیده شده باشـند بالاسـت. و بـرای مثال در مورد کلمـه "اسـت" ایـن فـاکتور مسـاوی صـفر اسـت! بنابراین با توجه به اینکه معیار انتخاب کلمات کلیدی حاصلضرب
دو فاکتور احتمال وقوع یا بسامد در پیکـره و فـاکتور تمرکـز idf است، کلماتی به عنوان کلمه کلیدی انتخاب میشوند کـه ضـمن داشتن بسامد وقوع بالا در تعداد محدودی سند واقع شده باشـند و به عبارتی در اسناد مربوط به طبقه خاصی به تعداد زیاد دیـده شوند.
در مرحلۀ بعدی، کلماتی که در رساندن معنای متن تاثیری ندارند حذف میگردنـد. نـام متـداول اینگونـه کلمـات در مقابـل کلمات محتوایی که دارای معنی هستند دستوری میباشد. عمده دلیل حذف این کلمات به خـاطر عـدم کارآمـدی آنهـا در طبقـه بندی متـون و افـزایش سـرعت پـردازش ماشـین مـیباشـد. در بسیاری از کارهای قبلی، مشکل عمده نداشتن مجموعۀ منسـجم و منظم از این کلمات بـرای زبـان فارسـی بـود. در ایـن تحقیـق کلمات دستوری به کمک واژگان زایای زبان فارسی و بـر اسـاس دیدگاههای صرفی و معناشـناختی جمـع آوری شـده انـد کـه در جدول زیر به همراه مثال هایی قابل مشاهده میباشد.[۱](http://sharif.ir/~bahram/papers/BabolClassifier.pdf)
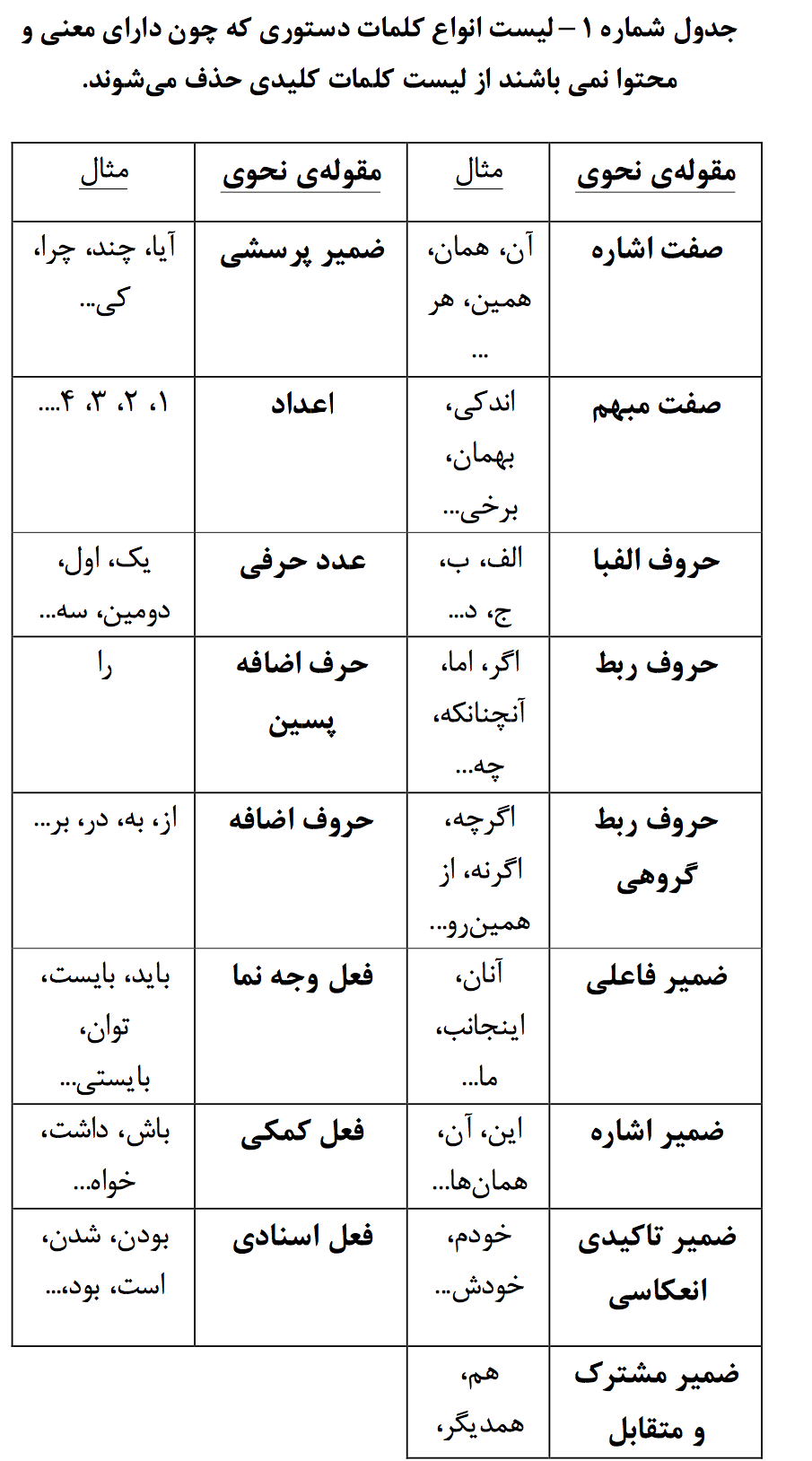
۲-تشخیص سلیقه کاربران:
با پیدا کردن موضوع هر متن به روش گفته شده برای هر تمامی پستهای هر کاربر الگوریتم بالا انجام میشود. بیشترین موضوعات موضوعات محبوب کاربر خواهند بود. برای چنین منظوری توییتر در تحلیلهای خود برای افراد موضوعات محبوبشان را شناسایی کرده و به ترتیب لیست میکند.[۲](https://sonetinfo.com/group/%D8%AA%D8%AC%D8%B2%DB%8C%D9%87-%D9%88-%D8%AA%D8%AD%D9%84%DB%8C%D9%84-%D8%B9%D9%85%D9%84%DA%A9%D8%B1%D8%AF-%D8%AF%D8%B1-%D8%B4%D8%A8%DA%A9%D9%87-%D9%87%D8%A7%DB%8C-%D8%A7%D8%AC%D8%AA%D9%85%D8%A7%D8%B9/)[ ۳ ](https://marketingland.com/meet-new-twitter-analytics-tools-twitter-113161)
متن کاوی:
بخش قابل توجهی از اطلاعات قابل دسترس در پایگاه دادههای متنی ذخیره شده اند که این پایگاه داده ها شامل مجموعه بزرگی از اسناد و منابع مختلف مانند مقالات خبری، علمی ، کتابها، ایمیلها و صفحات وب می باشند. این پایگاه دادهها و خصوصا اطلاعات موجود به فرم الکترونیکی سریعا در حال رشد بوده و امروزه بیشتر اطلاعات موجود در صنعت، کسب و کار و سایر سازمانها از این نوع می باشند .
متن کاوی یک حوزه تحقیقاتی بوده که از ترکیب چند حوزه تحقیقاتی دیگر بوجود آمده است. این حوزه های تحقیقاتی عبارتند از داده کاوی، پردازش زبان طبیعی و بازیابی اطلاعات. اما بین داده کاوی و متن کاوی تفاوت هایی وجود دارند که مهمترین آنها عبارتند از:
داده کاوی معمولا با داده های ساخت یافته سر و کار دارد اما برعکس متن کاوی با داده های ساخت نیافته یا شبه ساخت یافته درگیر بوده، خصوصا زمانی که این کاوش درون یک مقاله یا سند متنی عمومی انجام شود. از طرف دیگر حتی اگر کمی ساخت یافتگی هم در متن وجود داشته باشد باز هم دلیلی دیگر وجود دارد که متن کاوی را بسیار مشکل تر از داده کاوی می کند و آن هم انتزاعی بودن مفاهیم درون متن است که به سختی می توان آنها را با ساختارهای ارائه دانش مرسوم مدل کرد. از طرف دیگر در متن کاوی با مشکلات دیگری مانند کلمات هم خانواده (کلماتی که دارای معنی مشابه اما دیکته و تلفظ متفاوت) و کلمات متشابه (کلماتی که دیکته یا تلفظ مشابه داشته اما معنی کاملا متفاوت دارند) در گیر بوده که کار با متن کاوی را به مراتب مشکل تر نسبت به داده کاوی می کنند.
متن کاوی و خلاصه سازی متن:
آنچه مسلم است پروسه خلاصه سازی متن را نمی توان از موضوع متن کاوی جدا کرد. از آنجا که تحقیقات بسیاری در حوزه متن کاوی انجام شده است و خلاصه سازی هم نوعی کاوش در متن به جهت یافتن بخشهای مهم آن می باشد می توان از یافته های موجود در این مبحث برای خلاصه سازی متن کمک گرفت. [۴](http://mabdollahi.net/%D9%85%D8%B1%D9%88%D8%B1%DB%8C-%D8%A8%D8%B1-%D9%85%D8%AA%D9%86-%DA%A9%D8%A7%D9%88%DB%8C-%D9%88-%D8%AE%D9%84%D8%A7%D8%B5%D9%87-%D8%B3%D8%A7%D8%B2%DB%8C-%D9%85%D8%AA%D9%86/)
# مراجع:
1. Luhn, “The automatic creation of literature abstraction”, IBM Journal of research and development, 2-159-165, 1958
2. Edmundson, “New Methods in Automatic Extracting”, Journal of the Association for Computing Machinery, 16 (2), 264{285,1969.
3. Gupta, G. S. Lehal, “A Survey of Text Mining Techniques and Applications”, Journal of Emerging Technologies in Web Intelligence, vol. 1, no. 1, 2009.
4. Gulcin Ozsoy, I. Cicekli, F. Nur Alpaslan, “Text Summarization of Turkish Texts using Latent Semantic Analysis”, ۲۳rd International Conference on Computational Linguistics, pages 869–۸۷۶, , August 2010
5. هادی عبدی قویدل، بهرام وزیر نژاد ، محمدبحرانی ،برچسب زنی موضوعی متون فارسی ، دانشگاه صنعتی شریف