
چکیده
دراین پروژه الگوریتم جدیدی در طبقه بندی عکس هایی که کاربران رستوران گرفته اندارائه میشود،با استفاده از شبکه عصبی کانولوشن، مدلی برای مجموعه
عناصرارائه میشود و ماشینی طراحی میشود که ویژگی ها رابصورت باینری طبقه بندی میکند که بعدا برای پیش بینی برچسب ها استفاده میشود. اگرچه هدف اصلی پیدا کردن قوانین مرتبط بین برچسب های مختلف برای افزایش دقت هدف مطلوبمان است.این روش بااستفاده از پایگاه داده yelp ارزیابی میشودوکارایی اندازه گیری میشود ودرنهایت نتایج تجربی بدست امده کارایی الگوریتم استفاده شده را اثبات میکنند.
مقدمه
یلپ وبسایتی در مورد غذا و رستورانها میباشد که در آن کاربران تجربه نظرات خود را در مورد رستورانها و غذاهای آنها به اشتراک میگذارند.
در این پروژه میخواهیم در مسابقهای که Yelp برای برچسبزنی خودکار رستورانها تدارک دیده است استفاده کنیم. در واقع این مسابقه میخواهد سامانهای آموزش داده شود که با استفاده از مجموعه دادهای از عکسهایی که کاربران از غذاهای یک رستوران گرفتهاند، برچسب هایی را برای این رستوران انتخاب کنند.
یلپ یک امریکایی وجزو شرکت های چندملیتی است که مقر ان درسان فرانسیسکو کالیفرنیا است.
این سرویس بر پایهٔ وبسایت Yelp.com و اپلیکیشن موبایل Yelp، دیدگاههای (Reviews) دیگران در مورد کسب و کارهای محلی مانند رستورانها، کافهها و… را پردازش و در اختیار کاربران دیگر قرار میدهد. همچنین، این شرکت به مدیران کسب و کارها روش برخورد و با دیدگاههای آنلاین و روشهای پاسخ به آنها را آموزش میدهد.Yelp در سال ۲۰۰۴ توسط دو کارمند سابق کمپانی پی پال به نامهای راسل سیمونز و جرمی تأسیس شد. سرعت رشد این کمپانی به حدی زیاد بود که در سال ۲۰۱۰ به ۳۰ میلیون دلار درآمد رسید و طبق آمار منتشر شده در وبسایت خود ادعا کرد بیش از ۴٫۵ میلیون نفر از این سرویس استفاده میکنند. Yelp از سال ۲۰۰۹ تا ۲۰۱۲ مشغول توسعهٔ کسب و کار خود در اروپا و آسیا بودهاست.
در حال حاضر Yelp دارای ۱۳۵ میلیون بازدید کنندهٔ ماهانه و ۹۵ میلیون دیدگاه (Review) است. درآمد شرکت Yelp نیز از راه تبلیغات و واگذاری کنترل پنل به کسب و کارها است.
معرفی
هدف این پروژه ساختن مدلی است که بتواند باچندین برچسب که ازمجموعه داده هایی که کاربرارائه کرده است بصورت اتوماتیک رستوران ها را برچسب بزند
درصورتی که درحال حاضر کاربران yelp بصورت دستی ودلخواه رستوران ها را برچسب میزنند.
برچسب ها عبارت از:
0:good_for_lunch
1:good_for_dinner
2:takes_reservations
3:outdoor_seating
4:restaurant_is_expensive
5:has_alcohol
6:has_table_service
7:ambience_is_classy
8:good_for_kids
مجموعه داده اموزش دیده برای2000 رستوران برچسب اماده میکندیعنی234840عکس رابه رستوران نگاشت میکنند.درتست مجموعه داده 237152عکس رابه
10000رستوران نگاشت میکند.مدل اموزش دیده باید هر 10000رستوران را بایک یابیشتربرچسب از 9برچسب که درخواست میشود تگ بزند.
جالب است بدانیم سایز ورودی ثابت نیست یعنی زمانی که برچسب باید پیش بینی شود تعدادعکس ها برای رستوران هامتفاوت است.بعلاوه مسئله طبقه بندی عکس درImageNet یک خروجی دارد، هرعکس باید یک برچسب بخورد ولی این مسئله درواقع multi class است باچندین خروجی مواجه هستیم یعنی رستوران هاباید با9برچسب مختلف تگ بشوند.(هربرچسب میتواند درخواست شود ویا درخواست نشود.)
ورودی :عکس های مروری که کاربر از غذاهای رستوران گرفته است،تعداد عکس ها واندازه عکس ها متفاوت است.
خروجی:لیستی از برچسب های پیش بینی شده برای رستوران.
برای مثال اگر(1,2,3,8) خروجی باشد که پیش بینی میکند برچسب های 1و2و3و8 به رستوران درخواست دادند ولی برچسب های 0و4و5و6به رستوران درخواستی ندادند، پس اولین قدم برای طراحی مدل پیش بینی برچسب است(درخواست شده یادرخواست نشده)پیشگو برچسب هااز شبکه عصبی کانولوشن باسایز ورودی ثابت استفاده میکند.زمانی که همه عکس ها برچسب گذاری شدندمدل طراحی شده نتایج رابرای پیش بینی برچسب رستوران ترکیب میکند.دراخررستوران، بابرچسبی که بالاترین متقاضی راداشته باشد برچسب زده میشود.
باتوجه به رشد روزافزون عکس ها درفضای مجازی مثل اینستگرام و پیشرفت نرم افزارها وبوجود امدن موقعیت های کاری، کاربران باکلیک کردن بروی عکس ها تشویق می شوند درگروه ها مختلف فعال شده واطلاعاتشان را به اشتراک می گذارند.درنتیجه ی شکوفاشدن این گرایش تعدادزیادی عکس های سلفی باغذا به اشتراک گذاشته میشود.
بطورخلاصه ،پیش بینی ویژگی رستوران ها باتوجه به سرنخ های بینایی عکس هایی که کاربران گرفتند نوعی مسئله MIL (یادگیری که از روی چندین سورس انجام میشودمثلا شما میخواهید روی عکس یادگیری انجام بدیدچندین مجموعه کاملا متفاوت رو میگیرید برای یادگیری شبکه عصبی یا حتی یک مجموعه رو از چندین منظر مختلف یادگیری کنید)است.دراین مسئله کلاس بندی کننده براساس مجموعه ای(bag،منظور مجموعههایی است که در طول عملکرد الگوریتم عناصر رو داخلش جمع میکنن با مجموعه فرق دارد چون مجموعه تعریف علمی دارد و دراین تحقیق صدق نمیکند)از عناصر طراحی شده به طوری که هر مجموعه چندین مسیرحالت دارد.هرمجموعه بابرچسب ها درارتباط هست اما برچسب های هرنمونه ازمجموعه مشخص نیستند حتی ممکن است هرنمونه داخل مجموعه اطلاعات مرتبط به کلاس رانشان ندهد[1].الگوریتم های زیادی برای مسئله طبقه بندی multi instance وجود دارد.اخیرااستفاده ازمجموعه ای ازحالات برای طبقه بندی موثربوده است[2].اگرچه براساس شبکه عصبی کانولوشن حالات استخراج می شود[3]ولی مسئله کلاس بندی هنوزبخاطرMILها چالش برانگیزباقی مانده است.
هدف ارائه الگوریتمی برای پیش بینی ویژگی رستوران براساس عکس هایی که کاربران گرفته اندو طراحی شبکه عصبی کانولوشن برای استخراج حالات از عکس های مختلف که درنهایت مجموعه حالات بدست می اید.درواقع مدلی مجموعه ای برای هررستوران تعریف میکنیم.سپس ماشین جداگانه ای را برای هرویژگی اموزش میدهیم همچنین استقلال داده بین ویژگی های مختلفی که درطول طبقه بندی شدن ویژگی را پیش بینی میکردن را مورد توجه قرارمیدهیم و ازدیتاست رستوران یلپ استفاده میکنیم ودلیل انتخاب این دیتاست این است که نمایش دقیقی از عکس های رستوران در دنیای واقعی میدهد. دیتاست شامل برچسب هایی هست که بصورت دستی برای دیتابیس رستوران انتخاب شدند وهمچنین شامل نویز درقالب عکسای داپلیکیت و برچسب های نادرست است به همین دلیل کلاس بندی کردن دراین مسئله سخت شده است.
محدودیت های این پروژه زمان و محاسبات میباشد. اجرا شامل تنظیمات فریمورک و اماده سازی دیتا وطراحی مدل و پیش بینی خروجی است.
کارهای مرتبط
مقاله[Dietterich [4 : برای مسئله پیش بینی دارو که در موردطبقه بندی مولکول های شیمیایی است سیستم باید توضیح بدهد که مولکول های شیمیایی مورد نظر دارو خوب هستند یاخیر.
مقاله[Andrews [5: دوروش برای تغییرSVM ارائه کرد: mi_SVM و MI-SVM کلاس بندی نمونه ای و کلاس بندی مجموعه از عناصر وبرای
حل MIL از شبکه عصبی کانولوشن استفاده شد[3,6]
مقاله[Maron and Lozano-Perez[7: الگوریتمی در MIL ارائه کرد، هدف پیداکردن فضای حالاتی که به نمونههایی از مجموعهها مثبت نزدیک باشد(مجموعه عناصری که خصلت مورد بررسی رو در بر دارند) وهمچنین به نمونه ازمجموعه منفی عناصر دور باشد.بنابراین فاز یادگیری شامل پیداکردن
بهترین نمونه است. الگوریتم ارائه شده درحوزه تشخیص شی درتصویرمورد استفاده قرارمیگیرد[8].
معماری یادگیری عمیق، لایه های مختلف خصوصیات مقایسه میشود، خصوصیات ساده با لایه های پایینی کشف میشوند که بعدا به لایه های بالاتر تبدیل
میشوند و خصوصیات پیچیده را محاسبه میکنند[9,10,11,12]. شبکه های عصبی کانولوشن (CNN) یکی از مهمترین روش های یادگیری عمیق هستند که در آنها چندین لایه با روشی قدرتمند آموزش میبینند این روش بسیار کارآمد بوده و یکی از رایج ترین روشها در کاربردهای مختلف بینایی کامپیوتر است، مثلا تشخیص اشیا وکلاس بندی ویدیو.
مقاله[Xu [13: روش یادگیری عمیق برای محاسبه خصوصیات MIL درتصویربرداری پزشکی ارائه کرد.
مقاله[Song [14: شبکه عصبی کانولوشن را برای تشخیص مکان شی ارائه می دهد.
مقاله[Wang [15: الگوریتم k-nearest neighbour) KNN) برای MIL بکاربرد،الگوریتم KNN یکی از بهترین و پرکاربردترین الگوریتم های دسته بندی است که از آن استفاده گسترده ای در کاربردهای مختلف می شود. یکی از مشکلات این الگوریتم، تأثیر یکسان همه خصیصه ها در محاسبه اصله رکورد جدید با همسایه های آن رکورد می باشد، در صورتیکه برخی از این خصیصه ها برای عمل دسته بندی کم اهمیت ترند. این امر باعث گمراهی روند دسته بندی و کاهش دقت الگوریتم دسته بندی می شود.
برای مثال،پیدا کردن داده از روی تصویر کار ساده ای نیست. برای مثال، یک کار پیش پا افتاده که یک کودک شش ساله براحتی انجام میده مثل تشخیص سگ یا گربه از روی عکس، برای کامپیوتربیشتر شبیح یه کابوسه. به همین خاطر برای استخراج اطلاعات ازروی عکس، مجبوریم خیلی کارها بکنیم. تصویر پایین رو در نظر بگیرید، این گراف قیمت مس رو نشون میده. عدد 2.9401 میتونه یک مثال خوب برای استخراج باشه.
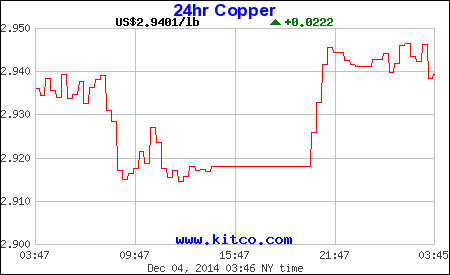
فرض نویسنده بر اینه که شما دانش اولیه راجع به پردازش تصویر دارید. اولین کاری که نیاز داریم انجام بدیم، بریدن اون تیکه عکس هست که عدد مورد نظر ما توی اون قرار داره. چون تصویردو بعد داره، نقطه شروع تصویر (0,0) و نقطه پایان عکس (m,n) خواهد بود که m نشون دهنده طول عکس و n عرض عکس رو نشون میده. باتوجه به گرافی که در دست داریم، نقطه شروع (15, 136) و نقطه پایان (28, 179) خواهد بود.
بسته به اینکه چه زبان برنامه نویسی رو برای پیاده سازی این الگوریتم استفاده میکنید، روش بریدن تصویر و کار با اون هم متفاوت خواهد بود.
مقاله[Chvaleyre et al[16: درخت تصمیم برای دسته بندی اطلاعات و نیز فرآیند انتخاب های ماشینی می توان از الگوریتم های تصمیم گیری
استفاده کرد، به طور مثال ما می توانیم مقداری از اطلاعات را به یک کامپیوتر بدهیم و سپس از آن بخواهیم با گرفتن اطلاعات بعدی (بر اساس اطلاعات قبلی) برای ماتصمیم گیری کند. یکی از الگوریتم های موجود الگوریتم ID3 نام دارد که درسال 1975 توسط J. Ross Quinlan و در کتابMachine Learning معرفی شد.به طور ساده یک الگوریتم id3 از تعدادی داده ثابت برای ما یک درخت تصمیم گیری می سازد که این درخت برای طبقه بندی کردن اطلاعات و در نتیجه تصمیم گیری به کار می روند .
مثال هایی که ما به کامپیوتر می دهیم شامل تعدادی مشخصات و تعدادی کلاس هستند. به طور مثال وقتی می گوییم یک مرد باید از 170 سانتیمتر بلند تر باشد ، دو مولفه ی کلاس و مشخصه را تعریف کرده ایم که در اینجا مشخصه "اندازه ی قد" و کلاس "مردبودن" است و یا ممکن است بگوییم یک زن حتما موهایی بلندتر از 30 سانتی متر دارد که در اینجا "اندازه ی مو" مشخصه و نیز "زن بودن" کلاس است.
انتخاب مشخصه ی کلاس بندی الگوریتم id3 از کجا می فهمد که باید بر اساس کدام مشخصه اطلاعات را طبقه بندی کند؟جواب در یک متغییر
آماری به نام ig و یا همان ضریب اطلاعات خلاصه شده است که این ضریب مشخص میکند که یک مشخصه "چقدر خوب؟"می تواند اطلاعات را دسته بندی کند و به اینصورت بهترین مشخصه انتخاب می شود تا بر اساس آن طبقه بندی اطلاعات صورت گیرد یعنی همان مشخصه ای که ig بیشتری داشته باشد برای آنکه بتوانیم ig را تعریف کنیم باید از تئوری اطلاعات و نیز مفهوم آنتروپی استفاده نماییم. آنتروپی میزان اطلاعاتی است که درون یک مشخصه گنجانده شده است و با فرمول زیر اندازه گیری می شود:(Entropy(S)= S -p(I) log2 p(I
مثال معروف بازی کردن بیس بال:
فرض کنید که به وسیله ی الگوریتم می خواهیم تشخیص دهیم که آیا هوا برای بازی کردن بیس بال خوب است یا نه؟
در دوره ی دو هفته ای از بازی کردن بیس بال اطلاعات زیر جمع آوری شده است این اطلاعات به id3 کمک می کند تا یک درخت تصمیم گیری ساخته شود. هدف ساختن در ختی است که تعیین کند که آیا باید در یک روز با اطلاعات خاص بیس بال بازی کنیم یا نه؟
اطلاعات شامل :
نوع هوا{آفتابی ، ابری ، بارانی}
دما {گرم ، معتدل ، سرد}
رطوبت {زیاد، کم}
شدت باد {قوی ، ضعیف}
مجموعه اطلاعات داده شده که به نام S شناخته می شوند شامل اطلاعات زیر هستند:
| ستون 1 | ستون 2 | ستون 3 | ستون 4 | ستون 5 | ستون 6 |
|---|---|---|---|---|---|
| Day | Outlook | Temperature | Humidity | Wind | Play ball |
| D1 | Sunny | Hot | High | Weak | No |
| D2 | Sunny | Hot | High | Strong | No |
| D3 | Overcast | Hot | High | Weak | Yes |
| D4 | Rain | Mild | High | Weak | Yes |
| D5 | Rain | Cool | Normal | Weak | Yes |
| D6 | Rain | Cool | Normal | Strong | No |
| D7 | Overcast | Cool | Normal | Strong | Yes |
| D8 | Sunny | Mild | High | Weak | No |
| D9 | Sunny | Cool | Normal | Weak | Yes |
| D10 | Rain | Mild | Normal | Weak | Yes |
| D11 | Sunny | Mild | Normal | Strong | Yes |
| D12 | Overcast | Mild | High | Strong | Yes |
| D13 | Overcast | Hot | Normal | Weak | Yes |
| D14 | Rain | Mild | High | Strong | No |
ابتدا باید بفهمیم که کدام یک از مشخصات ریشه ی درخت تصمیم گیری هستند؟
برای این منظور باید آنتروپی تمامی مشخصات را حساب کنیم.
Gain(S, Outlook) =0.246
Gain(S, Temperature) =0.029
Gain(S, Humidity) =0.151
Gain(S, Wind) = 0.048
(calculated in example 2)
بیشترین ضریب مربوط به نوع هوا است (Oultlook) ، بنا بر این به عنوان ریشه درخت ما مورد استفاده قرار می گیرد.به خاطر اینکه نوع هوا شامل 3 مقدار است پس درخت تصمیم گیری شامل 3شاخه می شود .
سوال بعدی این است که در شاخه ی نوع هوای آفتابی چه نوع تصمیم گیری باید انجام شود ؟برای پاسخ به این سوال باید از ضریب اطلاعات استفاده شود و باید
مشخص کنیم که در مجموعه هوای آفتابی کدام یک از متغییر های دیگر دارای پراکندگی اطلاعات کم تری هستند و در حقیقت igبالاتری دارند.
Ssunny ={D1, D2, D8, D9, D11} = 5 examples from table 1 with outlook = sunny
Gain(Ssunny, Humidity) = 0.970
Gain(Ssunny, Temperature) = 0.570
Gain(Ssunny, Wind) = 0.019
که در اینجا رطوبت دارای بیشترین ضریب است و به عنوان مشخصه تصمیم انتخاب می شود و این فرآیند ادامه پیدا می کند تا زمانی که مشخصات ما به اتمام
برسد.
مقاله[1 ]Emores: تحلیلی ازچندین MIL ارائه کرد(دسته بندی براساس رویکرد)
برای حل مسائل از نوع multi instance سه روش روتحلیل کرده :
۱.Instance space
bag space
embedded space
تفاوت اینا توی مرزبندی عناصرموجود و شیوه ارتباط دهی بین عناصر هست، embeded space بر اساس ارتباط بین عبارتهای مورد استفاده ،
درbag spaceشباهت بین اینستنسهای بگها، instance space هم کلاسه بندی اینستنس ها.
REFERENCES
[1] Jaume Amores. Multiple instance classification: Review, taxonomy and comparative study. Artificial Intelligence,201:81105, 2013.
[2] P. Auer, R. Ortner, A boosting approach to multiple instance learning, in: Proc. of European Conference on Computer Vision, 2004, pp. 63–74.
[3] Z.-H. Zhou and M.-L. Zhang. Neural networks for multi instance learning. In ICIIT, 2002
[4] T. G. Dietterich, R. H.Lathrop, and T. Lozano-Pérez. "Solving the multiple-instance problem with axis-parallel rectangles," Artificial Intelligence, vol.89, no.1-2,pp.31-71, 1997.
[5] S. Andrews, I. Tsochantaridis, and T. Hofmann. Support vector machines for multiple-instancelearning. In NIPS, 2002.
[6] J. Ramon and L. De Raedt. Multi instance neural networks. In ICML workshop on attribute-value and relational learning, 2000.
[7] O. Maron and T. Lozano-Pérez. "A framework for multipleinstance learning," in: Advances in 7Neural Information Processing Systems 10, M. I. Jordan, M. J. Kearns, and S. A. Solla, Eds. Cambridge, MA: MIT Press, pp.570-576, 1998.
[8] Yang, C. and Lozano-Pérez, T.: Image database retrieval with multiple-instance learning techniques, In: Proceedings of the 16th International Conference on Data Engineering, pp. 233-243, San Diego, CA, 2000
[9] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal ProcessingMagazine, IEEE, 29(6):82–97, 2012.
[10] K. Kavukcuoglu, P. Sermanet, Y.-L. Boureau, K. Gregor, M. Mathieu, and Y. LeCun. Learning convolutional feature hierarchies for visual recognition. In NIPS, 2010
[11] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In ICML, 2009.
[12] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with
convolutional neural networks. In CVPR, 2014
[13] Y. Xu, T. Mo, Q. Feng, P. Zhong, M. Lai, E. I. Chang, et al. Deep learning of feature representation with multiple instance learning for medical image analysis. In ICASSP, 2014
[14] H. O. Song, Y. J. Lee, S. Jegelka, and T. Darrell. Weakly supervised discovery of visual pattern configurations. In NIPS,
2014
[15] J. Wang and J.-D. Zucker. Solving the multiple-instance problem: a lazy learning approach, Proceedings 17th International Conference on Machine Learning, pp. 1119-1125, 2000
[16] Y. Chevaleyre, J. D. Zucker, Solving multiple-instance and multiple-part learning problems with decision trees and
rule sets. Application to the mutagenesis problem. In: Stroulia, E., Matwin, S. (eds.): Lecture Notes in Artificial Intelligence, Vol. 2056. Springer, Berlin(2001) 204-214.