یکی از کاربردهای مهم پردازش گفتار، یافتن کلمات کلیدی در گفتار است. به عنوان مثال یک پایگاه داده از صداهای ضبط شده را در نظر بگیرید. فرض کنید بخواهیم در این گفتارها به دنبال مجموعه ای از واژه های کلیدی بگردیم. در این صورت باید از الگوریتم های واژهیابی گفتار استفاده کنید. یکی از مقال هایی که این الگوریتم می تواند در آن جا مورد استفاده قرار گیرد، گفتارهای ضبط شده در یک کلاس درس است. مثلا فرض کنید که گفتارهای درس مدارهای الکتریکی_ضبط شده باشد و ما می خواهیم بدانیم در کدامیک از قسمت های این مجموعه در مورد کلمه کلیدی _دیود صحبت شده است.
۱. مقدمه
امروزه پردازش گفتار تقریبا در همه ی جنبه های زندگی ما نفوذ کرده. از گوشی و ساعت های هوشمند گرفته تا مباحث نظامی و امنیتی، همه جا نشانه ای از حضور تکنولوژی پردازش گفتار دیده می شود. [1]
اما این مباحث دهه هاست که در حوزه ی دانشگاهی مورد بررسی هستند، پس چرا در سال های اخیر اسم آن اینقدر بر سر زبان ها افتاده است؟ دلیل آن این است که اخیرا شاخه ی جدید از هوش مصنوعی به نام یادگیری عمیق توانسته است پردازش گفتار را به اندازه ای دقیق کند که خارج از محیط های کنترل شده هم بتوان از آن استفاده کرد.
استاد دانشگاه استنفورد و بنیان گذار سایت کورسرا، Andrew Ng پیش بینی کرده است که تا زمانی که دقت پردازش گفتار از 95 درصد به 99 درصد می رسد، اصلی ترین راه برای ارتباط برقرار کردن با کامپیوتر می شود. این فاصله ی 4 درصدی ، در واقع تفاوت میان "به طور آزاردهنده ای غیرقابل اعتماد" و "بسیار مفید" است که به لطف هوش مصنوعی و خصوصا یادگیری عمیق، آنقدری طول نمی کشد که بشر به این دقت می رسد.
درین بخش ما انحصارا به استخراج و جستجوی کلمات کلیدی در گفتار می پردازیم. گفته می شود آژانش امنیت ملی آمریکا مکالمات افراد بسیار زیادی را شنود کرده و به کار رفتن عبارات خاصی در متن مکالمه را بررسی می کند! [2] از کاربرد های امنیتی این موضوع که بگذریم این حوزه در جنبه های دیگر نیز کاربرد های فراوانی دارد.
۲. شرح مسئله و کارهای مرتبط
هدف مسئله: هدف ما همانطور که در بخش چکیده گفته شده است، پیدا کردن روشی برای استخراج و جستجوی کلمات به کار رفته در یک فایل صوتی می باشد. برای این منظور ما از هوش مصنوعی و شاخه های متنوع آن کمک خواهیم گرفت.
شرح مسئله و راهکار ها: خوب، اگر بخواهیم خیلی ساده مسئله را بیان کنیم، ما یک عامل هوشمند داریم که صوت را ورودی گرفته و لیست کلمات به کار رفته را خروجی می دهد.
اولین راهی که به ذهن می رسد این است که یک بار صوت مختص به یک کلمه و کلمه معادل را به عامل هوشمند داد و از آن خواست که در صورت مشاهده چنین صوتی، کلمه ی معادل را خروجی دهد. اما به این سادگی نیست... مشکلات بسیار زیادی وجود دارد که باعث می شود این روش عملی نباشد، برای مثال اولین مشکل این است: فرض کنید در صوتی که ما آن را برای یادگیری به عامل هوشمند داده ایم در عرض 1 ثانیه کلمه ی "سلام" گفته شود. مشکلی که وجود دارد این است که اگر کسی کلمه ی سلام را زودتر یا دیرتر ادا کند برای مثال در عرض نیم ثانیه بگوید "سلام" یا 5 ثانیه آن را طول بدهد و عبارت را بکشد و بگوید "سسسسللللااااامممم!" عامل هوشمند ما دیگر قادر به شناسایی عبارات گفته شده نیست.
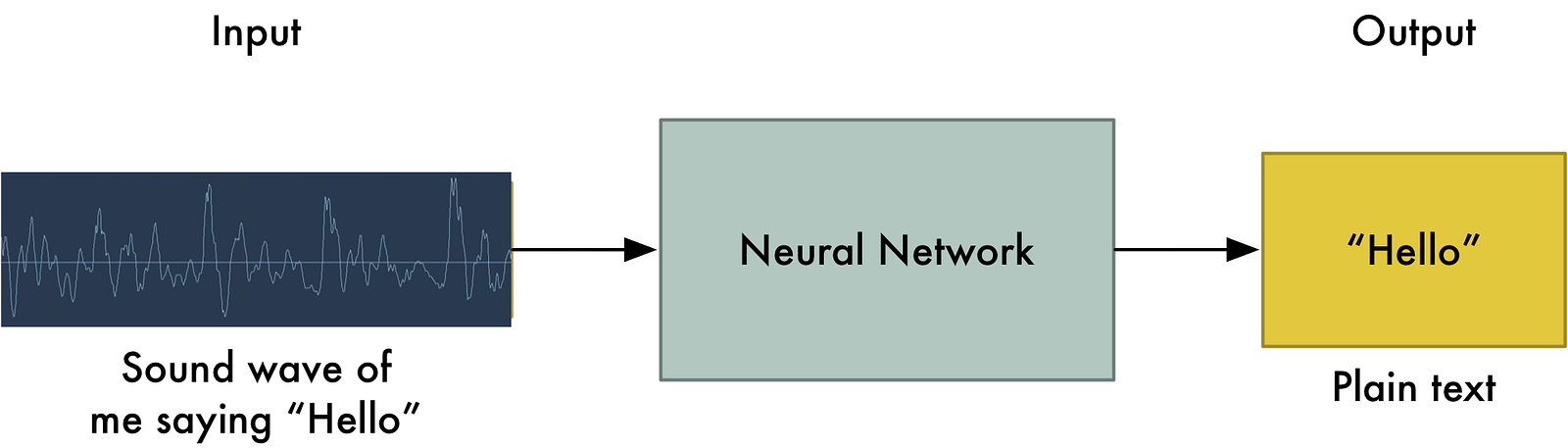
تبدیل صوت به داده ی دیجیتال:[1] اولین کاری که باید انجام داد تبدیل امواج صوتی به عدد و داده های دیجیتال قابل فهم برای کامپیوتر است. چونکه در نهایت تنها چیزی که کامپیوتر متوجه می شود 0 و 1 است نه امواج آنالوگ! برای مثال به موج صوتی زیر توجه کنید، درین شکل عبارت "Hello" گفته شده است:
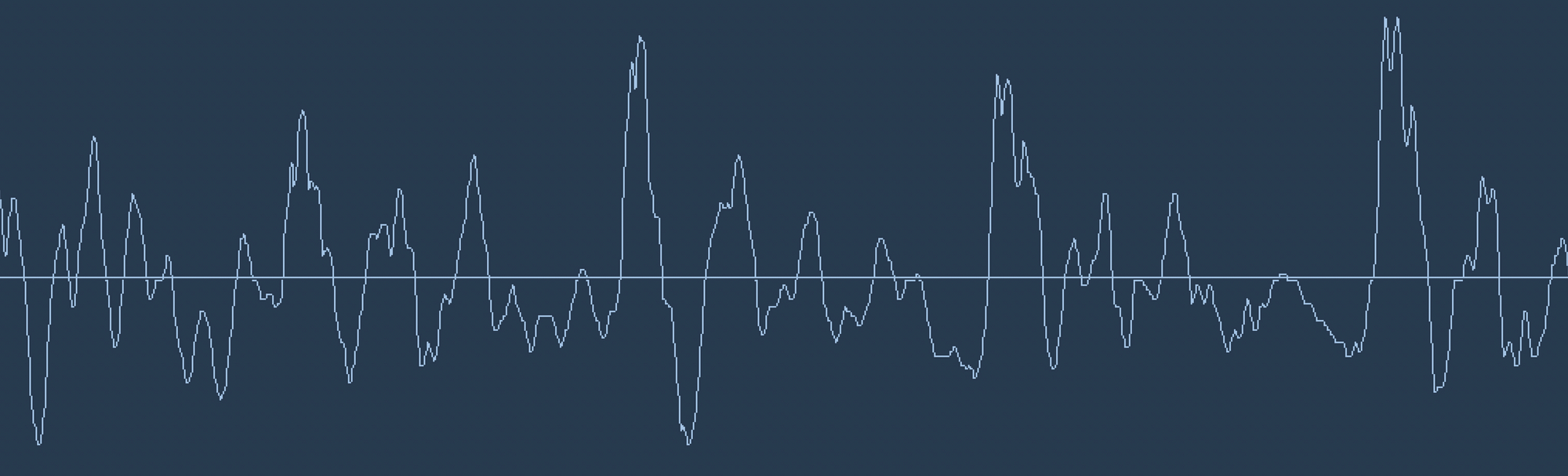
برای تبدیل این سیگنال به داده ی دیجیتال، می توان هر چند میکرو ثانیه، مقدار سیگنال را با تقریب به نزدیک ترین عدد تعریف شده گرد کرد و آن را ذخیره نمود. اینکه هر چند میکروثانیه این کار را انجام دهیم یا مقدار سیگنال در واحد زمان را با چه دقتی تعریف کرده باشیم، دقت معادل دیجیتال این سیگنال را تعیین می کند که مشخص است هرچقد بخواهیم دقت را زیادتر کنیم داده ی بدست آمده حجیم تر می شود. البته نکته ی جالب این است که زیاد بودن نرخ نمونه برداری ما بیشتر از یک حدی باعث افزایش کیفیت نمی شود. بر اساس قضیه ی Nyquist ، اگر نرخ نمونه برداری ما دو برابر بزرگترین فرکانس به کار رفته در موج باشد، می توانیم از روی داده ها به طور کامل به سیگنال اولیه برسیم. برای همین نرخ نموداری 16KHz برای پردازش گفتار انسان کافی است!
اگر ما بخواهیم از روی این داده ها به صورت خام عامل هوشمند را آموزش دهیم، مسئله بسیار پیچیده و سخت می شود. برای همین مسئله را ساده تر میکنیم. داده های بدست آمده را به بخش های 20 میلی ثانیه ای تقسیم میکنیم و پردازش را روی آن ها انجام می دهیم.
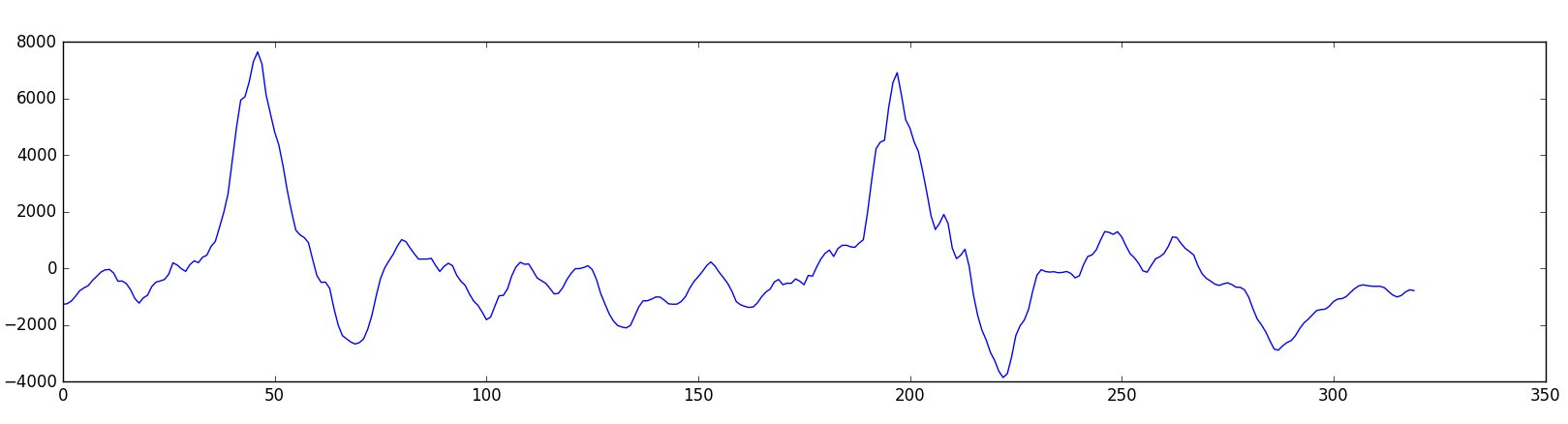
اما مشکل اینجاست که حتی 20 میلی ثانیه از موج ماهم ترکیبی پیچیده از صوت هایی با فرکانس های مختلف است.شکل[3]
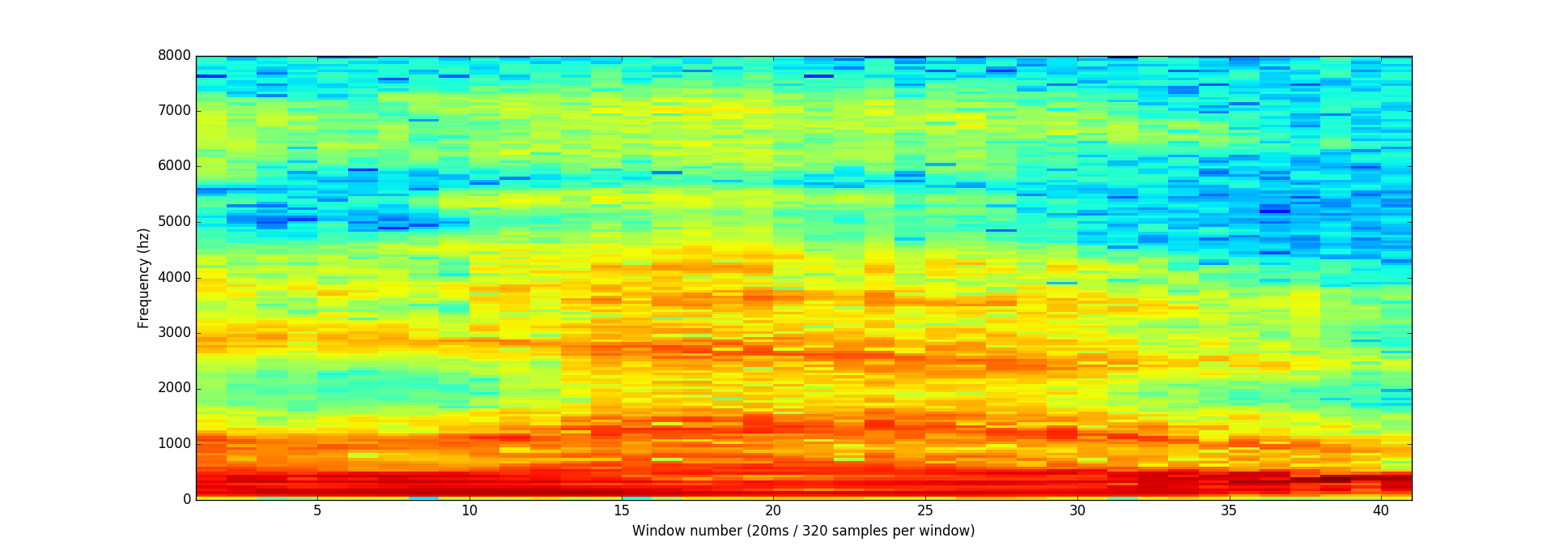
برای حل این مشکل ما با استفاده از تبدیل فوریه، سیگنال را به اجزای تشکیل دهنده اش تقسیم کرده و مشخص میکنیم هر جزء چقد انرژی دارد.

حال که سیگنال صوتی را ساده سازی کردیم می توانیم از داده های بدست آمده برای کار با عامل هوشمند استفاده کنیم.
عامل هوشمند پردازش گفتار می تواند بر اساس چندین مدل و متد مختلف ساخته شود. برای مثال مدل مخفی ماکاروف ، Dinamic Time Wrapping ، شبکه های عصبی ، یادگیری عمیق و ... [3]
۳. آزمایشها
۴. کارهای آینده
۵. مراجع
[1] : https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a
[2] : https://www.theguardian.com/technology/2015/feb/20/mobile-phones-hacked-can-nsa-gchq-listen-to-our-phone-calls
[3] : Anusuya, M. A., and Shriniwas K. Katti. "Speech recognition by machine, a review." arXiv preprint arXiv:1001.2267 (2010