سامانه توصیهگر به کمک هوشمصنوعی و دادههای بزرگ به تشکیل پرسونای تک تک کاربران میپردازد. سلیقه کاربران را بدون سوال و جواب کشف کرده و آنها را به سمت آنچه میجویند راهنمایی میکند.
۱. مقدمه
با توجه به گسترش فضای اینترنت، مطالب، محصولات فروشگاه ها که درنتیجه باعث افزایش قابل توجه حقانتخاب کاربر میشود، نیاز به طبقهبندی و کوچککردن فضای جستجو برای رسیدن به نتیجه بسیار حس میشود. چهبسا بسیاری از کاربران به دلیل این گستردگی قادر به یافتن نتیجهی خود نبوده و از ادامهی جستجو صرفنظر میکنند. سامانهی توصیهگر با کوچککردن فضای جستجویکاربران اینمشکل را حل میکند. این سامانه با روشهای متفاوت محتوای شخصیسازی شدهی هر کاربر را باتوجه به مشخصات، پیشینه جستجو و علایق به او پیشنهاد میدهد[1].در اینمقاله به بررسی روشهای موجود، نقاط ضعف و قوت و پیادهسازی آن(ها) میپردازیم.
۲. کارهای مرتبط

سامانههای توصیهگر برای کمک به تصمیمگیری و ارائهی رهنمود برای انتخاب محتوای مناسب هرشخص تعریف شدهاند و در راستای اینهدف از روشهای متفاوتی استفاده میکنند. در ابتدا به توضیح اجمالی هریک از این روشها اکتفا میکنیم(تصویر ۱) و در آینده به صورت تخصصیتر و جزئیتر به آنها میپردازیم. سعی داریم در این مقاله از روش مارپیچ برای توضیح روشهای پیادهسازی سامانهی توصیهگر استفاده کنیم.[3]
یکی از روشهای پیادهسازی توصیهگر تکنیک Collaborative filtering [4] نام دارد. به طور خلاصه این روش با شناسایی کاربران دیگر با ذائقه یکسان شما، محتوای مناسب را پیشنهاد میدهد[5] (تصویر ۲).

پیادهسازی این تکنیک به شیوههای متفاوتی انجام میشود که در آینده به طور کامل به آن اشاره میکنیم. از نمونههای استفادهکننده از این تکنیک میتوان به RINGO[7] اشاره کرد که البته سامانهای قدیمی در اینحوزه است. پس از آن میتوان به Amazon [8] اشاره کرد. آمازون از روش item-to-item که یکی از زیرمجموعههای تکنیک Collaborative filtering است استفاده میکند [9] . علاوه بر آن میتوان به سامانهی توصیهگر last.fm[10] اشاره کرد.این سایت موزیک هارا با توجه سلیقهی کاربر دستهبندی و به او پیشنهاد میدهد. لازم به ذکر است این سایت، توصیهگر خود را Audioscrobbler نامگذاری کرده است [11].
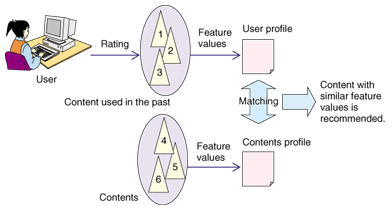
روش دیگر پیادهسازی توصیهگر تکنیک Content-base filtering نام دارد [13] . در اینروش ذائقهی کاربر باتوجه به مشخصات خود شخص و تشابه محتوای انتخابشدهی قبلی با نمونههای مشابه انتخابنشده تشخیص دادهمیشود و محتوای مشابه پیشنهاد میگردد(تصویر ۳). در اینروش تعامل و تشابه ذائقه بین کاربران مختلف نادیده گرفته میشود و تشابهات براساس تشابهات بین محتوا و محصولات بررسی میشود که تفاوت اصلی این تکنیک با تکنیک Collaborative filtering است [14]. از نمونههای استفادهکننده از این تکنیک میتوان به سامانهتوصیهگر Pandora [15] اشاره کرد. اینسامانه با بررسی مشخصات موزیک و هنرمند، موزیکهای مشابه را پیدا و به کاربر پیشنهاد میدهد [16].
برای مقایسهی ایندو روش اصلی میتوان به مقایسه last.fm و Pandora پرداخت. last.fm و دیگرسامانههای استفادهکننده از Collaborative filtering از مشکل شروع سرد(cold start [17]) رنج میبرند. برای شناخت موزیکهای مشابه ، یک موزیک برای قابل پیشنهاد شدن باید به سطح حداقلی از محبوبیت برسد تا از آستانهی( [18] threshold) صافی موزیکها عبور کند. البته Pandora نیز از معایبی مشابه رنج میبرد. برای اضافه شدن یک موزیک جدید لازم است تا کارمندان Pandora آنرا از تنگنای کلاسهبندی([19] classification) توصیهگرشان عبور دهند تا مشخصات موزیک و هنرمند بهدرستی بررسی و ثبتگردد. مقاله nature vs nurture به صورت جزئی به اختلافات و نقاط ضعف و قوت هریک از این سامانهها میپردازد [20].
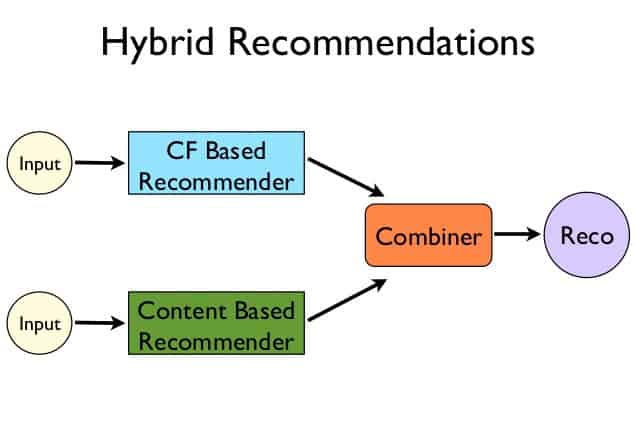
باتوجه به ضعفها و نقاط قوت ذکرشده در هرروش، روشی تلفیقی به نام تکنیک Hybrid filtering بهوجود آمد. باتوجه به قدرت Collaborative filtering و سرعت ابتدایی Content-base filtering با ترکیب نقاط قوت ایندوتکنیک، تکنیکی قویتر و کارآمدتر بهوجود میآید . این ترکیب میتواند شامل عبوردادن خروجی نتیجه CF به Content-base filtering باشد یا برعکس یا از تلفیق نتیجه مستقل هریک بهوجودآید(تصویر ۴).[21,22] از مثالهای استفادهکننده از این تکنیک میتوان به Netflix [23] اشاره کرد. Netflix با ترکیب قدرت بالای CF و کاهش هزینهی محاسباتی باتوجه به نیازمندیهای کم Content-base filtering سامانهی توصیهگر خود را پیادهسازی کردهاست[25, 24]
در آینده به بررسی جزئی تر هریک از این تکنیک ها در فاز پیادهسازی میپردازیم.
۳. آزمایشها
برای پیادهسازی سامانهی توصیهگر دو روش اساسی وجود دارد و روش سومی که از تلفیق این دو روش بهوجود میآید. پیادهسازی مدل Content-base filtering به زمان زیاد برای اضافهکردن محصولات نیاز دارد. باید مشخصات کاربر ثبت شود و برای هریک از محصولات ، مشخصات آنمحصول استخراج و تهیه شود و سپس محصولات مشابه یافت شود. پس اینروش کنار میرود.
روش دیگر پیادهسازی یعنی Collaborative filtering را برای پیادهسازی اینفاز انتخاب کردیم. اینروش انواعی دارد که هریک را توضیحمیدهیم و سپس مناسبترین را با ذکر دلیل پیاده میکنیم.

دو تقسیمبندی اساسی در این روش وجود دارد. Memory-based filtering و Model-based filtering.
روش Memory-based filtering
در اینروش با توجه به نمرهدهی های کاربران در گذشته، محصولات مشابه شناسایی شده و پیشنهاد میشوند[27].
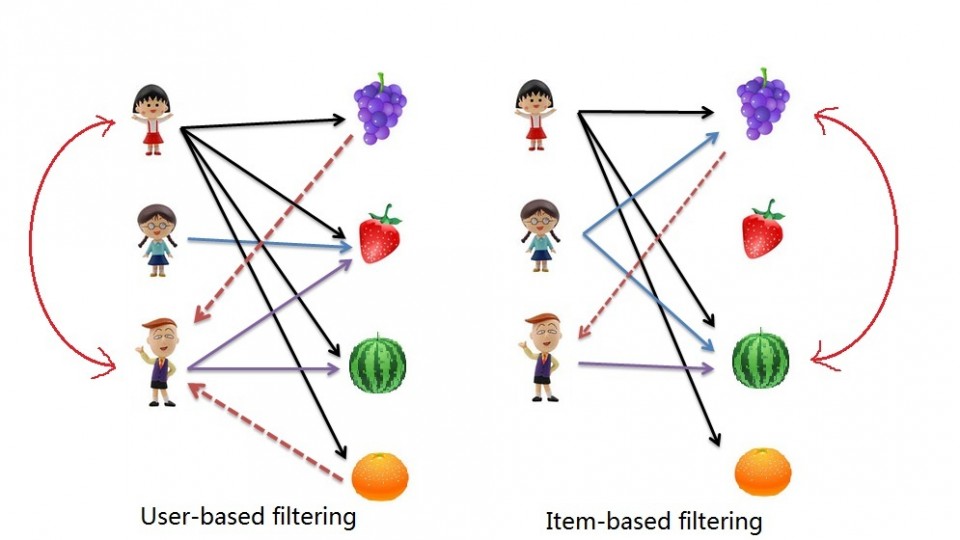
یکی از تقسیمبندیهای ریز این بخش سامانهی user-based است. در ایننوع پیادهسازی افراد مشابه باتوجه به امتیازاتی که به محصولات دادهاند استخراج میشوند و با توجه به سلایق یکسانشان، محصولات پیشنهادی انتخاب میشود. به عبارت دیگر: "اگر فرد ب تشابه زیادی در انتخاب محصول یا امتیازدهی با شما داشته باشد، کالاهایی که مورد پسند او است احتمالا برای شما جذاب باشد."
قسمت دوم تقسیمبندی این بخش، تکنیک item-based است. در اینتکنیک محصولات مشابه برحسب امتیازاتی که کاربران فعال به آن دادهاند استخراج میشوند و سپس بهجای هم پیشنهاد میشوند. به عبارت دیگر: "اگر محصول الف تشابه زیادی با محصول ب داشتهباشد، اگر از الف خوشتان بیاید احتمالا از ب نیز خوشتان بیاید و باالعکس." اینروش در خصوص دیتاست های امتیازدار بهخوبی نتیجه میدهد. در بخش پیادهسازی اولیه، ما این تکنیک را انتخاب کردهایم. پس از توضیح دیگر تکنیکها به بررسی ریزتر اینتکنیک میپردازیم [30, 29].
تکنیکهای Model-based

در ایننوع تکنیک، با بهکارگیری نتایج روش قبلی، الگویی استخراج میشود که بااستفاده از آن محصول جدید به کاربر پیشنهاد میشود. برای شناسایی الگو از روشهای بسیاری استفاده میشود که اکثر آنها زیرمجموعه روش های خوشهبندی [32] و کلاسهبندی [33] هستند.
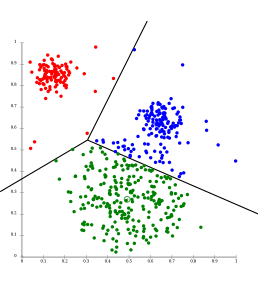
در تکنیکهای خوشهبندی، محصولات باتوجه به امتیازات و درصدتشابهاتی که دارند بدون هیچگونه برچسبی به دستههای مختلف تقسیممیشوند. دستههای مختلف با توجه به مشخصات مشابهی (که از روشهای متفاوتی این معیار اندازهگیری میشود) که دارند، با انتخاب میزان دقت به چند دسته متفاوت تقسیم میشوند که محصولات هردسته، مشابع یکدیگرند و بهجای هم پیشنهاد میشوند(تصویر ۸).
در تکنیکهای کلاسهبندی، ما دستههای مختلف را از ابتدا میدانیم و قسمتی از دادهی خود را در این دستهها قرار دادهایم. با توجه به الگوی استخراجشده از این نوع برچسبگذاری، دادهی جدید بدون برچسب را برچسبگذاری میکنیم و پیشبینی میکنیم هریک در کدام یک از ایندستهها قرار میگیرند.
حال که انواع تکنیکهای Collaborative filtering آشنا شدیم، جهت انتخاب تکنیک مناسب ابتدا باید به آنالیز مجموعهدادهمان بپردازیم.
مجموعهداده
مجموعهداده ما، قسمتی از مجموعهداده فروشگاه آمازون است. اینمجموعهی داده، خام و بدون هیچگونه نمونهبرداری آموزشی یا برچسبگذاری تهیهشده است و بررسیهای مشابهی روی ایندیتاست یافت نشد. بنابراین تمامی مراحل لازم پیشپردازش و پردازش باید از ابتدا طی شود.
ابتدا به بررسی ستونهای موجود در این دیتاست میپردازیم:
کاربر (user):در اینستون id کاربر فروشگاه قرار دارد. مقداری یکتا که هرکاربر را از دیگری متمایز میکند.
محضول (item): در اینستون id محصول وجود دارد. مقداری یکتا که هرمحصول را از محصول دیگر متمایز میکند.
امتیاز (rating): در اینستون امتیاز داده شدهی کاربر به آنمحصول وجود دارد که مقداری از ۱ تا ۵ را میگیرد.
زمان (timestamp): در اینستون زمان امتیاز داده شده موجود میباشد. از عدد موجود برای مقایسهزمان ها میتوان استفاده نمود.
حجم دادههای موجود، باتوجه به انتخاب دستهی مورد نظر متفاوت میباشد. دستههای مختلف (کتاب، فیلم، و ...) حجم های متفاوتی دارند که از ۵۰۰۰۰۰ سطر تا ۲۲۰۰۰۰۰۰ سطر قرار دارند.
اولینچالش حجم بالای اطلاعات است. در سامانههای توصیهگر دو نوع پردازش به طور عمومی وجود دارد: پردازش آفلاین و آنلاین. پردازش آفلاین در هرزمانی امکان دارد و نتایج اینپردازش در زمانی که کاربر یک محصول را مشاهده میکند، ارائه میشود. پردازش آنلاین درلحظه صورت میگیرد و هنگامی که کاربر در حال مشاهدهی یک محصول است، سامانهی توصیهگر به محاسبهی محصولات و تشابه بین آنها میپردازد تا نتیجهی مناسب را به کاربر نشان دهد. هدف ما انتخاب روشی است که حداکثر پردازش آفلاین و حداقل پردازش آنلاین را دارد و در عین حال نتیجه با دقت خوبی به کاربر ارائه شود.
روشهای سنتی Collaborative filtering معمولا پردازش آفلاینی ندارند و یا میزان آن بسیار ناچیز است. در اینروش ها که شباهت کاربر با کاربران دیگر درخصوص یکمحصول به صورت آنلاین محسابه میشود، با توجه به نیاز به جواب در لحظه، سیستمهای پردازشی قویای را میطلبد و همچنین روی دیتاستهای بزرگی چون دیتاست آمازون بهخوبی نتیجه نمیدهد. بنابراین این روش را از فاز پیادهسازی حذف میکنیم
روش های خوشهبندی مشکل طبقهبندی آنلاین را تا حد خوبی رفع میکنند. در این روشها اکثر محاسبات به صورت آفلاین انجام میشود، اما دقت زیادی ندارد. برای افزایش دقت نیاز به افزایش تعداد دستهها است که افزایش قابل توجه هزینه را درپی دارد . همچنین برای افزودن دستههای جدید و استفاده از روشهای کلاسهبندی user-based پردازش آنلاین را میطلبد که مشکلات روش قبل را درپی خواهد داشت [35].
روش باقیمانده، تکنیک item-based است که زیرمجموعهی تکنیک memory based میباشد. یعنی محصولات مشابه را پیدا میکنیم و سپس بهجای یکدیگر پیشنهاد میدهیم. کدهای پیاده سازی آمادهی بسیاری در اینزمینه وجود دارند که نیاز به پیادهسازی مجدد را برطرف میکنند [36]. اما متاسفانه همهی آنها از روشهای معمول item-based استفاده میکنند که سوالهای زیر را ایجاد میکند:
با توجه به زیاد بودن محصولات فروشگاه آمازون، استفاده از روشهای معمول item-based به صرفه است؟ اکثر آنان به بررسی تشابه میان تکتک محصولات میپردازند که پیچیدگی فضای آن از مرتبه O(n^2) میباشد که n تعداد محصولات است. همچنین پیچیدگی زمانی آن ترکیبی پیچیدهتر از پیچیدگی فضایحافظه آن است چون باتوجه به معیار مقایسه تشابه، تعداد کاربران را نیز درگیر میکند. حال با این حجم عظیم داده چگونه با اینپیچیدگی محاسبات را انجام دهیم؟ فرض کنید به نمونهبرداری محصولات معروف بپردازیم. محصولات دیگر هیچوقت پیشنهاد نمیشوند. با محصولات جدید چه کنیم؟ فرض کنید برای کم کردن پیچیدگی زمانی به نمونه برداری کاربران فعال بپردازیم. با پیچیدگی حافظه چه کنیم؟
با توجه به روبروشدن با اینسوال ها روش های معمول item-based را کنار گذاشتیم و به سراغ روش منحصربهفرد فروشگاه آمازون یعنی item to item Collaborative filtering رفتیم. الگوریتم کلی این روش را با استفاده از شبهکد توضیح میدهیم:

تصویر ۹ [37]
در ابتدا برای کمکردن میزان پیچیدگی، سامانهی توصیهگر توصیه های خود را از دستهبندی مشابه انتخاب میکند. به عنوان مثال در صورت انتخاب یک نوع کتاب خاص کتابهای مشابه به شما پیشنهاد میشود و در صورت انتخاب یک فیلم خاص، فیلم های مشابه. بدین صورت به جای محاسبه تشابه میان کل محصولات، کافیست محصولات هر دسته را جداگانه بررسی کنیم و همین روند در بهبود سرعت کار بسیار تاثیرگزار خواهد بود. درون یک دسته نیز ما تمام محصولات را تشابهشان را با هم محاسبه نمیکنیم. بسیاری از محصولات هستند که یک کاربر به هردوی آنها امتیاز نداده است. در نتیجه بسیاری از هزینه زمانی و حافظه صرف محاسبه و نگهداری تشابهاتی میشود که از ابتدا میزان ۰ بودن آنها مشخص است. بنابراین فقط به بررسی تشابهات غیر ۰ میپردازیم. روشهای محاسبه تشابه (similarity) بسیار زیاد و متنوعند. استفادهی نادرست از این روشها با وجود دانستن کم بودن دقت( precision and recall 38 ) یک اشتباه است. برای استفاده از روش اندازهگیری تشابه مناسب باید به نوع متغیر توجه کرد. متغیرها انواعی دارند :غیر عددی مانند سبز و قرمز و ...
عددی باینری متقارن که جابهجایی ۰ و ۱ ها تاثیری در تحلیل ندارد.
عددی باینری نامتقارن که جابهجایی ۰ و ۱ ها در تحلیل تاثیرگزار است.
عددی غیر باینری
ترتیبی مانند بد، خوب و عالی
متغیرهای ما به نوعی ترتیبی هستند که هرکدام از صفتهارا به یکعدد نسبت دادیم. یکی از بهترینانواع محاسبه similarity برای این نوع متغیر شباهت مثلثاتی (Cosine similarity [39] )(تصویر ۱۰) است.

تصویر ۱۰
بهعلت انتخاب بسیار ریز ما در روش پیادهسازی، بسیاری از مراحل میبایست شخصیسازی میشدند تا پیچیدگی زمانی و حافظه رعایت شود. نمونه اولیه این محاسبه شباهت در گیتهاب موجود است. در پیادهسازی اینروش از ماژولهای زیر استفاده شدهاست:ماژول pandas: برای دسته بندی و فیلترینگ دادهها به صورت جدولی
ماژول scipy:برای محاسبات آماری
در فاز بعدی، به بررسی دقت روشمان میپردازیم. برای اینکار باید دادهی تست را از داده خام تولید کنیم. همچنین به بهبود سرعت و پیچیدگی زمانی الگوریتم پیاده شده میپردازیم تا به پیچیدگی استاندارد فروشگاه آمازون برسد. باوجود انتخاب درست و دقیق روش محاسبه شباهت، به بررسی دقیقتر روش های مشابه شباهت مثلثاتی نیز میپردازیم.
۴. مراجع
[1] http://www.sciencedirect.com/science/article/pii/S1110866515000341
[2] http://www.sciencedirect.com/science/article/pii/S1110866515000341
[3] https://en.wikipedia.org/wiki/Spiral_model
[4] http://recommender-systems.org/collaborative-filtering/
[5] http://www.sciencedirect.com/science/article/pii/S1110866515000341
[6] https://en.wikipedia.org/wiki/Collaborative_filtering#/media/File:Collaborative_filtering.gif
[7] http://jolomo.net/ringo.html
[8] https://www.amazon.com/
[9] https://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf
[10] https://www.last.fm/
[11] https://en.wikipedia.org/wiki/Last.fm
[12] http://findoutyourfavorite.blogspot.com/2012/04/content-based-filtering.html
[13] http://recommender-systems.org/content-based-filtering/
[14] http://www.sciencedirect.com/science/article/pii/S1110866515000341
[15] https://www.pandora.com/
[16] https://en.wikipedia.org/wiki/Recommender_system
[17] https://en.wikipedia.org/wiki/Cold_start
[18] https://en.wikipedia.org/wiki/Threshold_model
[19] https://en.wikipedia.org/wiki/Statistical_classification
[20] http://blog.stevekrause.org/2006/01/pandora-and-lastfm-nature-vs-nurture-in.html
[21] http://www.sciencedirect.com/science/article/pii/S1110866515000341
[22] https://en.wikipedia.org/wiki/Recommender_system
[23] https://www.netflix.com/
[24] https://rpubs.com/kismetk/Netflix-recommendation
[25] https://dl.acm.org/citation.cfm?id=2843948
[26] http://www.sciencedirect.com/science/article/pii/S1110866515000341
[27] Zhao ZD, Shang MS. User-based collaborative filtering recommendation algorithms on Hadoop. In:
Proceedings of 3rd international conference on knowledge discovering and
data mining, (WKDD 2010), IEEE Computer Society, Washington DC, USA;
{kind=link}
p. 478–81. doi: 10.1109/WKDD.2010.54.
[28] http://www.salemmarafi.com/code/collaborative-filtering-with-python/
[29] Melville P, Mooney-Raymond J, Nagarajan R. Content-boosted collaborative filtering for improved recommendation. In: Proceedings of the eighteenth
national conference on artificial intelligence (AAAI), Edmonton, Canada; 2002. p. 187–92.
[30] D. Jannach, M. Zanker, A. Felfernig, G. FriedrichRecommender systems – an introduction
Cambridge University Press (2010)
[31] https://abgoswam.wordpress.com/2016/06/13/recommendation-systems-approaches/
[32] https://en.wikipedia.org/wiki/Cluster_analysis
[33] https://en.wikipedia.org/wiki/Statistical_classification
[34] https://en.wikipedia.org/wiki/Cluster_analysis
[35] https://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf
[36] http://www.salemmarafi.com/code/collaborative-filtering-with-python/
[37] https://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf
[38] https://en.wikipedia.org/wiki/Precision_and_recall
[39] https://en.wikipedia.org/wiki/Cosine_similarity