شاخص هر بورس، میتواند نمایندهی خوبی برای نمایش میزان رشد سهامهای موجود در بورس و خوب و یا بد بودن وضعیت سرمایهگذاری در آن باشد. این شاخص در طول زمان نوساناتی را تجربه میکند که بسیاری از متخصصین بر این باور هستند، که این نوسانات در شرایط عادی از الگوهای مشخصی پیروی میکنند. حتی برخی از این الگوها به صورت فرموله شده نیز تحت عنوان «تحلیل تکنیکال بورس» تبیین شده است. اگر این فرض را بپذیریم، پس باید بتوانیم با کنکاش در گذشته شاخص یک بورس، آینده نوسانات آن را پیشبینی کنیم. تکنیکهای هوش مصنوعی و یادگیری ماشین هم میتوانند یک ابزار بسیار قدرتمند در استخراج الگو و پیشبینی آینده بازار بورس باشند. چیزی که هدف از این پروژه خواهد بود، شکل ساده شدهای از مسئله پیشبینی شاخص بورس میباشد، آن هم این که با مشاهده وضعیت شاخص بورس در بازههای مشخص زمانی گذشته (مثلا هفتههای پیش)، پیشبینی کنید که آیا شاخص بورس در بازه زمانی پیش رو (هفته آتی) مثبت است یا منفی. در واقع مسئله در این پروژه یک ردهبندی دو کلاسه خواهد بود، که دادههای آن مربوط به شاخص بورس هستند. مجموعه دادههای متعددی در این زمینه وجود دارد که از یکی از آنها برای انجام پروژه میتوانید استفاده کنید. مثلا مجموعه داده شاخص بورس داوجونز.
۱. مقدمه
بازار بورس چیست؟
در علم اقتصاد بورس به بازاری اطلاق می شود که قیمت گذاری و خرید و فروش کالا و اوراق بهادار در آن انجام می پذیرد و در یک طبقه بندی کلی شامل بورس کالا و اوراق بهادار است.
تفاوت بازار بورس به عنوان یک بازار مالی با بازار فیزیکی در آن است که در این بازار سهام و اوراق قرضه بجای کالا مورد معامله قرار میگیرد. بازار بورس تابع مقرراتی است که توسط نهادهای قانون گذار تعیین میشود و به منظور جلوگیری از بی نظمی و رعایت حقوق طرفین عرضه و تقاضا، رعایت آنها الزامی است. امروزه بازارهای بورس و اوراق بهادار، شاهراه سرمایهگذاری و انجام معاملات در حوزه بورس کالا و اوراق بهادار در جهان محسوب میشود.
پیش بینی بازار بورس چیست ؟
پیش بینی بازار بورس به فرآیندی که در طی آن قیمت سهام شرکت مورد نظر مورد پیش بینی قرار می گیرد گفته میشود. طبق نظریه بازار کارآمد (efficinet market hypothesis) قیمت سهام ها تمامی اطلاعات موجود را در اختیار ما می گذارد و چنان چه قیمت یک سهام بر اساس اخبار منتشر شده تغییر پیدا نکند در نتیجه آن سهام به خودی خود قابل پیش بینی نخواهد بود. عده ای دیگر نیز وجود دارند که با ارایه ی چندین متد راه های پیش بینی قیمت سهام را عرضه کرده اند.
روش های پیش بینی بازار بورس چیست؟
روش های پیش بینی به ۳ دسته تقسیم میشوند که می توانند با یکدیگر هم پوشانی نیز داشته باشند
تحلیل بنیادی
تحلیل تکنیکال
تحلیل مبتنی بر داده کاوی و تکنولوژی
تحلیل بنیادی چیست؟
تحلیل بنیادین یک شرکت شامل تحلیل گزارشها مالی و سلامت مالی شرکت، مدیریت و امتیازات رقابتی، رقبا و بازارهای مربوطهاست. در تحلیل بنیادین اساس پیش بینی بر مبنای وقایع و رخدادهای واقعی پایهگذاری شدهاست. معامله گر با تحلیل اتفاقات و اخبار دنیای واقعی و بر اساس دانش و استراتژی خود، به پیش بینی بازار میپردازد. پایه نظر تحلیل گران بنیادی این است که تمام تغییرات در قیمتها حتماً یک علت اقتصادی بنیادی دارد. این نوع از تحلیل نسبت به تحلیل تکنیکال بسیار زمانگیرتر است و معمولاً همراه با جمعآوری اطلاعات از منابع مختلف ممکن میگردد.

تحلیل تکنیکال چیست؟
در این تحلیل از طریق بررسی تغییرات و نوسانهای قیمتها و حجم معاملات و عرضه و تقاضا میتوان وضعیت قیمتها در آینده را پیشبینی کرد. تحلیلگران تکنیکال ارزش ذاتی اوراق بهادار را اندازهگیری نمیکنند، در عوض از نمودارها و ابزارهای دیگر برای شناسایی الگوهایی که میتواند فعالیت آتی سهم را پیشبینی کند، بهره میجویند. این نوع تحلیل با استفاده از «مطالعه رفتار و حرکات قیمت و حجم سهام در گذشته و تعیین قیمت و روند آینده سهم» صورت میپذیرد.

تحلیل مبتنی بر داده کاوی و تکنولوژی
با پیشرفت تکنولوژی استفاده از متد ها و روش های کامپیوتری نیز در سهام مرسوم شده اند. الگوریتم های ژنتیک و شبکه های عصبی ساختگی ( artificial neural networks - ANN ) از برجسته ترین روش های مورد استفاده هستند. از شایع ترین فرم ANN می توان به Feed Forwarding Network اشاره کرد. همچنین فرم های دیگری مانند Recurrent Neural Network یا Time Delay Neural Network نیز وجود دارند که الگوریتم های المان و جردن نیز از این ۲ فرم استفاده می کنند. همچنین استفاده از Text Mining به همراه Machine Learning نیز در این کار افزایش یافته است.
۲. کارهای مرتبط
استفاده از شبکه های عصبی ساختگی ( ANN )
در مقاله ی [۱] با استفاده از شبکه های عصبی ساختگی و در نظر گرفتن ساعت باز شدن و بسته شدن بازار - بالاترین و پایین ترین قیمت سهم به عنوان ورودی و قیمت سهم در پایان روز به عنوان خروجی پیاده سازی شده است. همچنین ۶۰ درصد از داده به Train و ۴۰ درصد باقی به آزمایش کردن اختصاص یافته و تعداد لایه های مخفی از ۱ تا ۳ لایه متغیر است. نتیجه نیز در صورت موجود وکافی بودن داده مورد نیاز در بدترین حالت که ۱ لایه مخفی داریم خطایی در حدود ۳.۵٪ خواهیم داشت.
در مقاله ی دوم[۲] نیز با استفاده از پیاده سازی شبکه عصبی و تست کد خود بر روی ۶۰ شرکت از بازار Nairobi در بازه سال های ۲۰۰۸ تا ۲۰۱۲ کار خود را پیش می برد. در ابتدا نسبت داده های مورد آموزش (Train) نسب به داده های مورد آزمایش ۷۰ به ۳۰ و تعداد نورون های ورودی ۵ و ۲ لایه مخفی شامل ۱۱ نورون و لایه ی آخر خروجی شامل ۱ نورون مورد آزمایش قرار گرفت. که در پایان این تنظیمات به افزایش ۱۰ درصدی داده مورد آموزش و برقراری نسبت ۸۰ به ۲۰ در داده های مورد آموزش به آزمایش و افزایش تعداد نورون های لایه های پنهان به ۲۱ نیز افزایش پیدا کرد. (این ارزیابی در بازه های ۳ ماهه انجام گرفت) جهت ارزیابی های نهایی نیز آزمایش ها بر روی ۳ شرکت مایکروسافت - کوکاکولا و آلکاتل انجام گرفت. که در تست های نهایی بر روی شرکت کوکاکولا مقدار خطا به ۰.۷۱٪ رسید.
استفاده از خطی سازی
در این صفحه [۳] با استفاده از کشف ارتباط بین قیمت ها و استخراج معادله ی خطی برای استفاده از آن به پیش بینی قیمت سهم مورد نظر می پردازد.
نتایج الگوریتم مورد استفاده در طی ۶۰ روز بر روی یکی از بانک ها که ۴۰ روز ابتدایی به یادگیری (training) و ۲۰ روز انتهایی به آزمایش گذاشته شده است.


استفاده از یادگیری ماشین و الگوریتم های ژنتیک
در این صفحه [۴] با استفاده از الگوریتم های ژنتیک I Know First که با دنبال کردن قیمت حال حاضر سهم و اضافه کردن آن به دیتابیس که مبتنی بر سری داده های مبتنی بر زمان و سپس مقایسه آن و پیش بینی قیمت آتی سهم در ۶ افق زمانی مختلف می پردازد.
در این مقاله [۵] نیز با استفاده از الگوریتم های ژنتیک و فریم ورک GAFD و بررسی بازار سهام کره (KOSPI) در بازه ۲۹۲۸ روز معاملاتی در طی سال های ۱۹۸۹ تا ۱۹۹۸ می پردازد. همچنین به مقایسه نتایج این روش با روش تبدیل خطی همراه با شبکه های عصبی Back Propagation و همچنین مقایسه با روش تبدیل خطی همراه با شبکه عصبی تمرین داده شده توسط الگوریتم های ژنتیک می پردازد.
در این لینک [۶] پیاده سازی با استفاده از پایتون و یادگیری ماشین انجام گرفته و خروجی پیشبینی بر اساس index های s&p 500 است که ۲ مساله طبقه بندی باینری ( بنا بر اتفاقات روز قبل پیشبینی را مثبت یا منفی در نظر می گیرد) و مساله پسرفت ( پیش بینی دقیق ) را مورد بررسی قرار می هد.
۳. آزمایش ها
در این قسمت هدف پیاده سازی پروژه مبتنی بر قسمت قبل و موارد مطالعه شده جدیدتر است که ابتدا به معرفی کلیات پروژه شامل زبان پیاده سازی و ماژول ها و فریم ورک های مورد استفاده و توضیحات مربوط به هر کدام و سپس جزییات پیاده سازی و توضیح بخش های مختلف کد و در نهایت خروجی نهایی و بررسی نتایج می پردازیم.
زبان پیاده سازی
این پروژه با استفاده از زبان برنامه نویسی Python2.7 پیاده سازی شده است. این زبان به علت عدم پیچیدگی در syntax و همچنین وجود کتابخانه و فریم ورک های فراوان در این زمینه بسیار مناسب بوده و پیشنهاد میشود.
ماژول ها و فریم ورک های استفاده شده
ماژول numpy : از این کتابخانه که برای پایتون نوشته شده است در کارهای ریاضی پیچیده تر مانند ماتریس ها و غیره استفاده میشود.
ماژول pandas :از این ماژول برای داده کاوی می توانیم استفاده کنیم و فایل csv داده های بورسی خودمان را با استفاده از ماژول می خوانیم.
ماژول sklearn : یک کتابخانه ی مورد استفاده در مبحث یادگیری ماشین است که امکانات فراوانی را در اختیار ما می گذارد و ما از MinMaxScalar این کتابخانه جهت scale کردن داده های مورد نظر خودمان بر روی بازه دلخواه استفاده می کنیم.
ماژول matplotlib :از این ماژول برای رسم نمودار های نتایج خودمان استفاده می کنیم.
کتابخانه TensorFlow : این کتابخانه متن باز در حال حاضر یکی از بهترین و مورد استفاده ترین کتابخانه های موجود جهت استفاده در زمینه هوش مصنوعی و یادگیری ماشین ( به ویژه مبحث یادگیری عمیق یا Deep Learning ) و پیاده سازی بهتر و راحت تر شبکه های عصبی مورد استفاده قرار میگیرد. این کتابخانه با زبان C++ پیاده سازی شده و با پایتون نیز مورد استفاده قرار میگیرد. با استفاده از این کتابخانه می توانیم عملیات های ریاضی را به صورت گراف نمایش دهیم. از آنجایی که شبکه های عصبی نیز گراف هایی متشکل از داده ها و عملیات های ریاضی هستند این کتابخانه برای استفاده در مبحث شبکه های عصبی و یادگیری ماشین به ویژه یادگیری عمیق بسیار به کار می رود.
مثال ساده ی زیر را در نظر بگیرید :

یک مثال ساده برای توضیح تنسورفلو
در این مثال NUM1 و NUM2 و RESULT سه متغیر هستند که مقادیر موجود در NUM1 و NUM2 با استفاده از node میانی مربع شکل که وظیفه ی جمع کردن را به عهده دارد با یکدیگر جمع شده و به RESULT اضافه میشود. می توانیم NUM1 و NUM2 و RESULT را به عناون placeholder در نظر بگیریم و بدین صورت که هر مقداری درون NUM1 و NUM2 تزریق شود به RESULT اضافه می گردد. این دقیقا ظرز کار Tensorflow است و برنامه نویس یا کاربر به صورت کلی مدلی از گرف خود (شبکه ی عصبی مورد نظر خود ) را با استفاده از متغیر ها و placeholder ها طراحی می کند و پس از آن placeholder ها با استفاده از مقادیر داده ها پر شده و عملیات محاسبات آغاز میگردد. اگر بخواهیم کد مثال بالا را با استفاده از Tensorflow در زبان پایتون پیاده سازی کنیم به صورت زیر خواهد بود :
import tensorflow as tf
NUM1 = tf.placeholder(dtype = tf.int8)
NUM2 = tf.placeholder(dtype = tf.int8)
RESULT = tf.add(NUM1, NUM2)
#Initialize the graph
myGraph = tf.Session()
#Start and Running the "myGraph"
myGraph.run(RESULT, feed_dict = {NUM1 : 10, NUM2 : 15})
مجموعه داده مورد استفاده ( Dataset )
داده ی مورد استفاده در این پروژه مجموعه داده ایست جمع آوری شده از S&P500 که شامل ۴۱۲۶ دقیقه از افت و خیز و شاخص های این بازار در یک بازه ۳ ماهه در سال ۲۰۱۷ بوده وجمع آوری گردیده و به صورت فایل csv خروجی یافته است.
نمودار فایل csv به صورت زیر خواهد بود :

جزییات پیاده سازی
۱ - داده های مورد یادگیری (Train ) و آزمایش (Test)
از مجموعه داده های خودمان ۸۰٪ را به یادگیری (Train) و ۲۰٪ باقی را به آزمایش (Test) اختصاص می دهیم. البته می توان این نسبت را نیز تغییر داد و نتایج متفاوتی گرفت برای مثال می توان از مجموعه داده بزرگتری (مثلا دقایق بیشتری) استفاده کرد و نسبت یادگیری را کاهش داد و مشاهده کرد که آیا نتایج بهبود می یابد یا خیر.
train_start = 0
train_end = int(np.floor(0.8*n))
test_start = train_end + 1
test_end = n
data_train = data[np.arange(train_start, train_end), :]
data_test = data[np.arange(test_start, test_end), :]
۲- مقیاس بندی داده ها ( Data Scaling )
در شبکه های عصبی از مقیاس بندی داده های ورودی (و حتی خروجی) استفاده میشود تا بهره ی بیشتری داشته باشیم بخاطر این که بیشتر توابع فعال سازی ( Activation Function ) نورون های شبکه از داده هایی بر روی بازه ی [-1, 1] و یا [0, 1] استفاده می کنند پس باید مقادیر داده های ورودی خودمان را نیز در این بازه قرار دهیم تا بتوانیم بهره ی مناسب را داشته باشیم. برای این کار نیز همانطور که در قسمت ماژول های مورد استفاده توضیح داده شده از MinMaxScalar موجود در کتابخانه sklearn استفاده می کنیم.
#Scale Data
scaler = MinMaxScaler()
scaler.fit(data_train)
data_train = scaler.transform(data_train)
data_test = scaler.transform(data_test)
#X and Y initializing
X_train = data_train[:, 1:]
y_train = data_train[:, 0]
X_test = data_test[:, 1:]
y_test = data_test[:, 0]
۳ - حفره ها ( Placeholders )
در این پروژه ما به ۲ حفره (placeholder) نیاز داریم . یکی X به عنوان ورودی های شبکه (قیمت s&p500 در زمان T = t ) و دیگری Y به عنوان خروجی شبکه ( شاخص s&p500 در زمان T = t + 1 ). شکل حفره های ما به ۲ صورت خواهد بود. ورودی ها به [None, n_stocks ] و خروجی ها به [None] مرتبط بوده و بدین معنا است که ورودی های ما ماتریس ۲ بعدی و خروجی های ما ۱ بعدی خواهند بود. None بدین معنا خواهد بود که در این نقطه ما تعداد مشاهدات خودمان که در جریان شبکه است را به طور دقیق نمی دانیم و آن را None قرار می دهیم تا منعطف باشد.
X = tf.placeholder(dtype=tf.float32, shape=[None, n_stocks])
Y = tf.placeholder(dtype=tf.float32, shape=[None])
۴ - متغیر ها (Variables)
حفره ها برای ذخیره سازی ورودی ها و هدایت آن ها در داخل گراف به کار می روند و متغیر ها به عنوان نگه دارنده های منعطفی می توانند به کار بروند که در حین اجرا نیز می توانند تغییر کنند. ۲ متغیر برای هر لایه در نظر می گیریم. ۱ - وزن ۲- بایاس
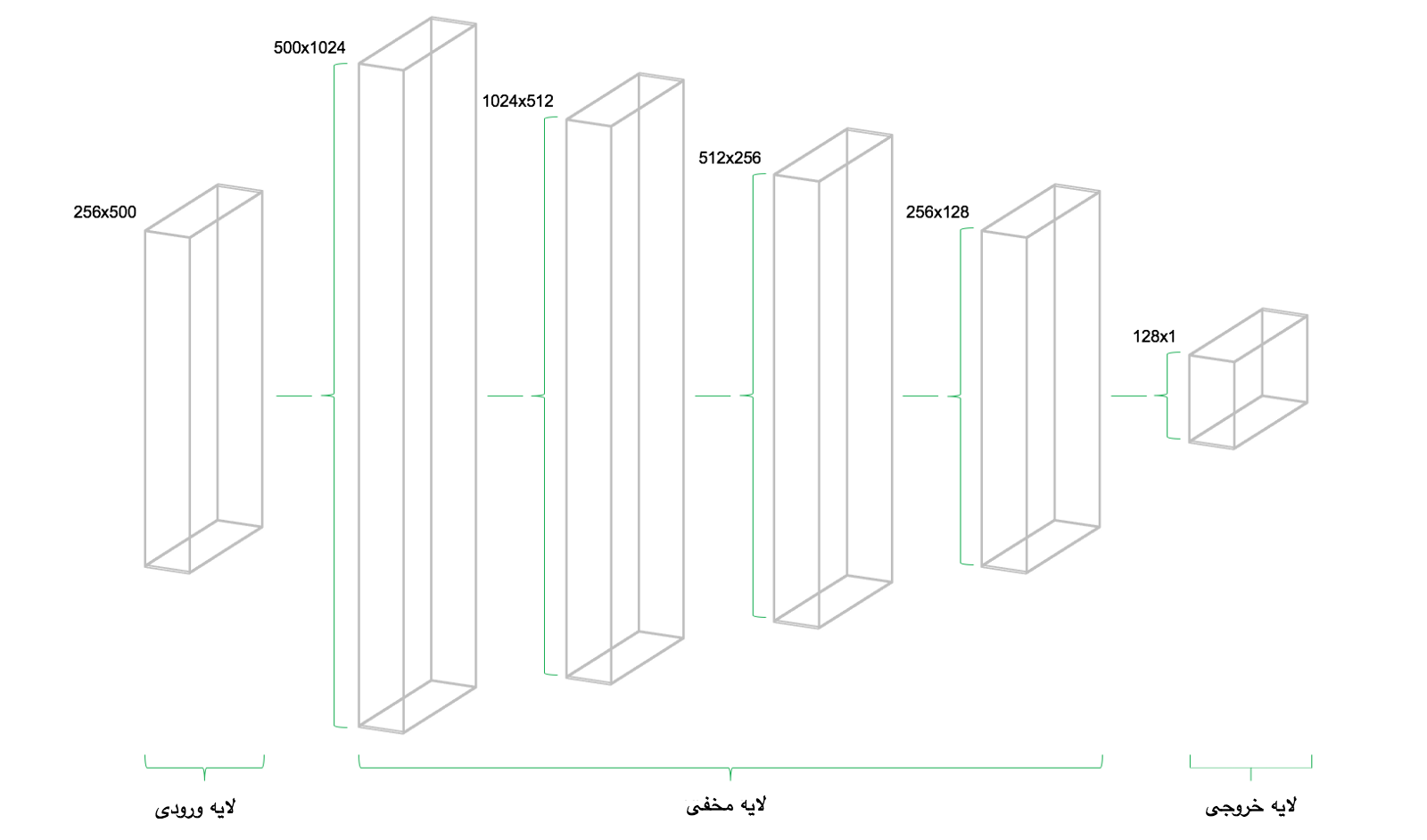
شبکه ی عصبی ما ۴ لایه مخفی دارد. لایه ی اول ۱۰۲۴ نورون که بیشتر از ۲ برابر لایه ی ورودی ما که شامل ۵۰۰ نورون است و بنا بر این که هر لایه باید نصف لایه ی قبلی خود نورون داشته باشد لایه ی دوم ۵۱۲ و لایه سوم ۲۵۶ و لایه ی چهارم نیز ۱۲۸ نورون خواهد داشت. کاهش تعداد نورون ها باعث فشرده شدن اطلاعات رسیده به هر لایه مخفی از لایه مخفی پیشین خود میشود. تعداد لایه ها و همچنین تعداد نورون های هر لایه با رعایت قاعده گفته شده میتواند متغیر باشد.
همچنین باید در نظر داشته باشیم که در شبکه های عصبی MLP رابطه ی بین لایه های مخفی و خروجی وجود دارد و بدین صورت است که بعد دوم لایه ی پیشین برابر با بعد اول لایه کنونی است .
کد زیر نحوه ی تعریف متغیر های وزن و بایاس با فرض این که فقط ۲ لایه داریم را نشان میدهد :
n_stocks = 500
n_neurons_1 = 1024
n_neurons_2 = 512
n_target = 1
#Layer1
W_hidden_1 = tf.Variable(weight_initializer([n_stocks, n_neurons_1]))
bias_hidden_1 = tf.Variable(bias_initializer([n_neurons_1]))
#Layer2
W_hidden_2 = tf.Variable(weight_initializer([n_neurons_1, n_neurons_2]))
bias_hidden_2 = tf.Variable(bias_initializer([n_neurons_2]))
#Output Layer
W_out = tf.Variable(weight_initializer([n_neurons_2, n_target]))
bias_out = tf.Variable(bias_initializer([n_target]))
۵ - طراحی شبکه ی عصبی
در نهایت حفره ها ( placeholder) و متغیر ها (وزن و بایاس) باید ترکیب شوند و شبکه ی عصبی ما را بسازند. توابع فعال سازی نیز به دلیل این که وظیفه ی انتفال بین لایه های مخفی ما را دارند اهمیت زیادی پیدا می کنند . یکی از مورد استفاده ترین توابع فعال سازی ReLU یا Rectified linear unit است.
کد زیر نحوه ی تعریف توابع فعال سازی برای لایه های مخفی ( با فرض این که ۲ لایه داریم ) و لایه ی خروجی را نشان می دهد :
#Hidden Layer Activation Function Definition
hidden_1 = tf.nn.relu(tf.add(tf.matmul(X, W_hidden_1), bias_hidden_1))
hidden_2 = tf.nn.relu(tf.add(tf.matmul(hidden_1, W_hidden_2), bias_hidden_2))
#Output Layer Activation Function Definition
out = tf.transpose(tf.add(tf.matmul(hidden_4, W_out), bias_out))
شبکه ای که ما ساخته ایم Feed Forwarding است و همانطور که قبلا توضیح داده شد این شبکه ها به این صورت عمل می کنند که اطلاعات را فقط به لایه ی بعدی خود می فرستند و شبکه های دیگری مانند Recurrent Neural Network نیز بدین صورت عمل می کنند که داده می تواند به لایه پیشین خود نیز جریان پیدا کند.
با توجه به قاعده های گفته شده بالا طراحی شبکه ی عصبی ما به صورت زیر خواهد بود :
۶ - تابع هزینه ( Cost Function )
در شبکه های عصبی تایع هزینه برای به دست آوردن اختلاف و انحرافی که داده های واقعی (داده هایی که هدف ما هستند) با داده هایی که ما به دست می آوریم به کار میروند. یکی از پر کاربرد ترین این توابع MSE یا Mean Squared Error است که میانگین مربع انحرافات را محاسبه می کند.
#Cost Function
mse = tf.reduce_mean(tf.squared_difference(out, Y))
۷ - بهینه سازی
بهینه ساز یا Optimizer طوری عمل می کند که با در نظر گرفتن متغیر های وزن و بایاس اعمال محاسبات بر روی آن ها مقدار انحراف از داده واقعی ( داده هدف) را به حداقل خودش برساند. یکی از بهینه ساز های پیش فرض Tensorflow که از آن استفاده می کنیم AdamOptimizer است . ( Adaptive Moment Estimation ).
#Optimizing
opt = tf.train.AdamOptimizer().minimize(mse)
۸ - فیت کردن شبکه ی عصبی (Fitting Neural Network)
بعد از تعریف حفره ها و متغیر ها و طراحی شبکه و تابع هزینه و بهینه ساز نوبت به تمرین (train) شبکه عصبی میرسد. برای این عمل از متد یادگیری دسته های کوچک (minibatch Training) استفاده شده است. مجموعه داده ی مورد تمرین train به بخش هایی با اندازه n/batch_size تقسیم می شوند که به صورت مرحله به مرحله وارد شبکه عصبی میشوند و زمانی که این داده ها وارد شبکه میشوند دو حفره (placeholder) که X و Y هستند وظیفه ی ذخیره سازی ورودی و هدف قرار دادن داده را دارند و این داده ها را به این عنوان به شبکه نشان می دهند.
دسته ای از داده های X وارد شبکه میشوند و لایه لایه جلو می روند تا این که به لایه آخر برسند. در همین حین Tensorflow مقادیر داده های پیش بینی شده را با مقادیر واقعی (هدف) Y در دسته ای که الآن هستیم مقایسه می کند. پس از آن Tensorflow بهینه سازی را انجام داده و پارامتر های شبکه را بروز رسانی می کند. پس از بروزرسانی وزن و بایاس ها دسته ی بعدی نیز به همین منوال مورد پردازش قرار میگیرد و عملیات های گفته شده دوباره اجرا میشود. این فرآیند تا وقتی ادامه پیدا می کند که تمامی دسته ها وارد شبکه شده و پردازش صورت بگیرد. یک بار اجرای کامل عملیات ها بر روی تمامی دسته ها را Epoch می گوییم. مقدار epoch را در شبکه خودمان تعریف می کنیم و برنامه تا وقتی تمام epoch ها را طی نکند اجرا میشود.
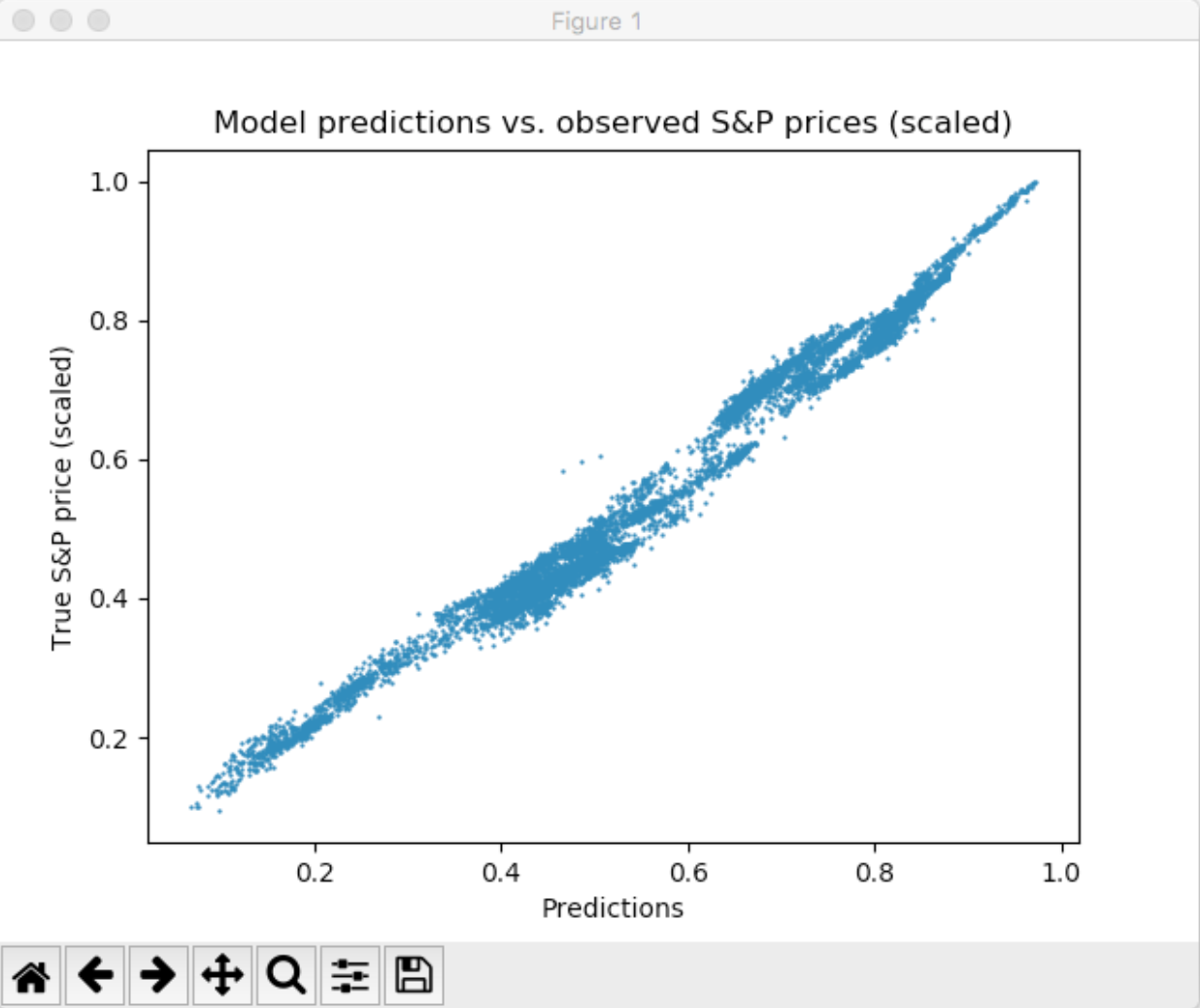
در حین این که عملیات یادگیری ( train) را انجام می دهیم عملیات آزمایش ( test ) را نیز بر روی مجموعه ی داده های تست خودمان اعمال می کنیم. بدین صورت که به ازای هر ۵ دسته (batch) که یادگیری (train) انجام می دهیم عملیات آزمایش (test) را انجام می دهیم و نمودار آن را رسم می کنیم.

در تصویر بالا مشاهده میشود که شبکه به علت این که در epoch اول است و اول کار است هنوز به پیش بینی مطلوب نرسیده است.
نتایج
مشاهده میشود که با پیمایش هر دسته (batch) شبکه ی عصبی مرحله به مرحله خودش را با داده های هدف ما تطبیق میدهد. بعد از طی شدن ۱۰ epoch اجرای برنامه ما به پایان میرسد و مقدار MSE نهایی ما بر روی داده های مورد آزمایش (Test) به ۰.۰۰۰۷۸ میرسد که مقدار درصد اروری(انحراف) که داریم تقریبا برابر با ۵.۱۳٪ خواهد بود.
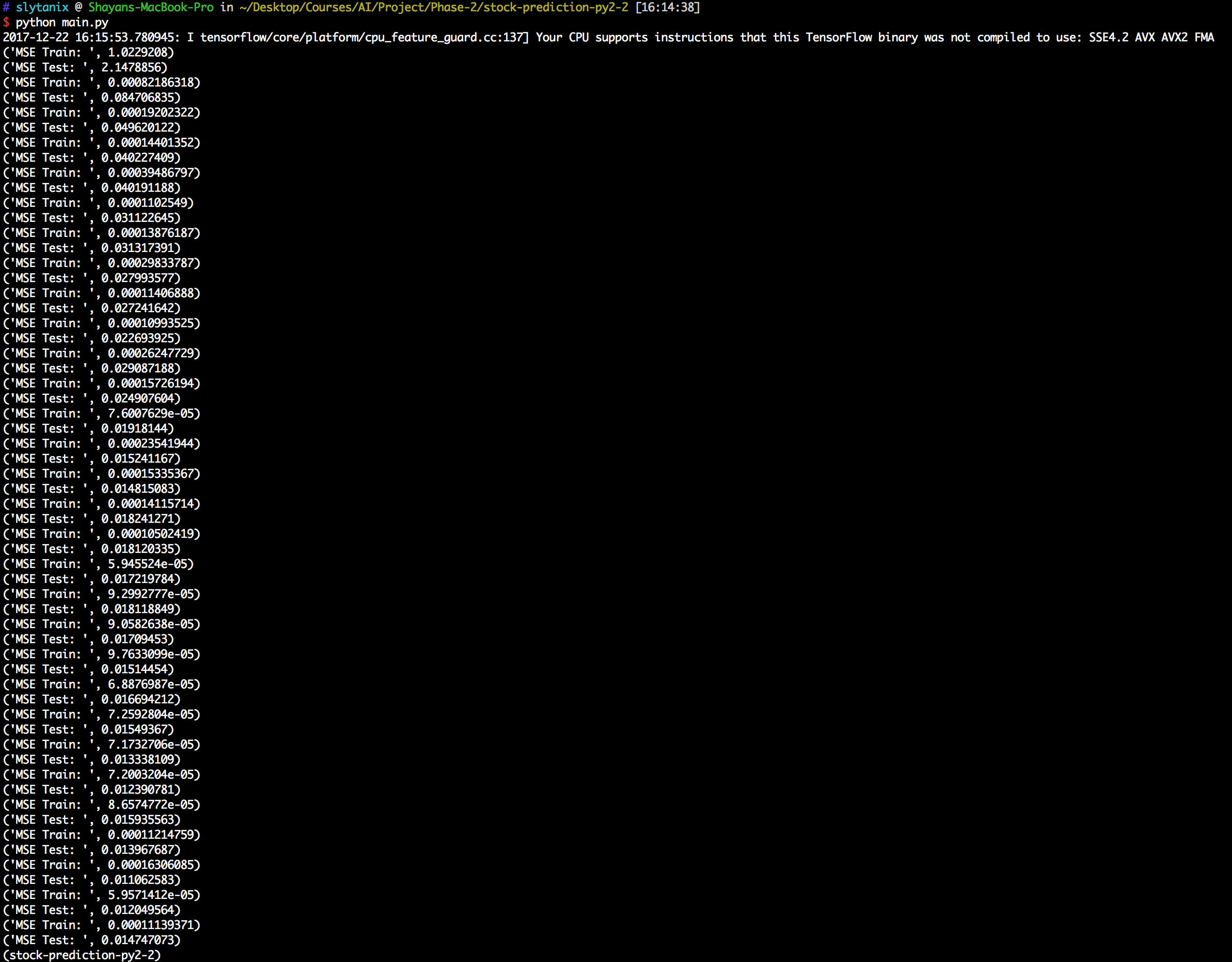
** در تصویر بالا همانطور که ذکر شده است به علت فشار بسیار زیاد بر روی cpu پس از ورودی ۵۰اُمین دسته ( batch) فرآیند تست را انجام می دهیم.
۴. نحوه ی اجرا ی کد
فایل مجموعه ی دیتا از طریق لینک قابل دانلود است.
دسترسی به گیت هاب پروژه از طریق لینک امکان پذیر است.
پس از دریافت پروژه فایل مجموعه داده را extract کرده و فایل csv را داخل فولدر root پروژه قرار دهید.
پروژه در بستر Virtual Enviorement نوشته شده است. پس هر ماژولی نصب کنید فقط داخل همان پروژه نصب شده و به فایل های اصلی سیستم تغییری اعمال نمیشود.
از طریق command line به مسیر root پروژه رفته و دستور زیر را وارد کنید.
source bin/activate
محیط مجازی فعال میشود و با دستور زیر می توان آن را غیر فعال کرد
deactivate
در حالی که محیط مجازی فعال است ابتدا فایل installer جهت نصب ماژول ها و کتابخانه های مورد نیاز و سپس فایل main را اجرا کنید.
python installer.py
python main.py
#If 2 previous commands return error try these commands
python2.7 installer.py
python2.7 main.py
۵. کارهای آینده
۶. مراجع
[1] Abhishek Kar, Stock Prediction using Artificial Neural Networks, Dept. of Computer Science and Engineering, IIT Kanpur
[2] Wanjawa, Barack Wamkaya, ANN Model to Predict Stock Prices at Stock Exchange Markets, School of Computing and Informatics University of Nairobi
[3] How to Predict Stock Prices using regression
[4] Machine Learning Trading, Stock Market, and Chaos
[5] Kyoung-jaeKim, Ingoo Han, Genetic algorithms approach to feature discretization in artificial neural networks for the prediction of stock price index, Korea Advanced Institute of Science and Technology
[6] Predicting Stock Market Returns
[7] Stock Market Prediction
[8] Technical Analysis
[9] Fundamental Analysis
[10] Efficient-market hypothesis
[11] Feed Forward Neural Network
[12] Back Propagation
[13] Tensorflow
[14] Numpy
[15] Pandas
[16] sklearn.processing MinMaxScalar
پیوندهای مفید