##**تولید گفتگو به کمک یادگیری تقویتی عمیق**
----------
**به نام خدا**
#مقدمه
یکی از موضوعات مهمی که در سالهای اخیر در حوزه پردازش زبانهای طبیعی[^**N**atural **L**anguage **P**rocessing (NLP)] مورد توجه قرار گرفته، سیستمهای تولید گفتگو[^Dialogue System] است. سیستمهای تولید گفتگو یا عاملهای مکالمه کننده[^**C**onversational **A**gents (CA)] مانند دستیارهای شخصی [^Personal Assistants] و رباتهای سخنگو [^Chatbots] در جامعه امروز بسیار فراگیر شده است[1]. که می توان در این حوزه به دستیار های شخصی بر روی تلفن های همراه [^همچون Siri در Apple و Cortana در Microsoft]یا ربات های آنلاین در شبکههای اجتماعی همچون تلگرام اشاره کرد. با این حال پاسخ های تولید شده توسط این عامل ها، جملات کوتاه و قابل پیش بینی هستند.
دراین مقاله با استفاده از یادگیری تقویتی عمیق به تولید مدلی برای رباتهای سخنگو می پردازیم،که بتواند مشکلات ذکرشده، را رفع کرده و به تولید پاسخهای هماهنگ، منسجم و سرگرم کننده بیانجامد. این مدل، گفتگو بین دو عامل مجازی را با استفاده از سیستم پاداش و تنبیه جهت دستیابی به اهداف بلند مدت در گفتگو[^ منظور از اهداف بلند مدت سرگرم کردن کاربر، ادامه پیدا کردن مکالمه با دیالوگ های جدید، برخورد کمتر با جملات گنگ،جلوگیری از حلقه بی نهایت و غیره می باشد.]، پیاده سازی میکند[2]. این کار را می توان جز یکی از اولین قدم ها در حوزه تولید مکالمه در جهت دستیابی به اهداف بلند مدت دانست.
#کارهای مرتبط
تلاش های انجام شده برای ساخت سیستمهای گفتگو، را می توان به دو گروه اصلی تقسیم کرد:
گروه اول در تلاش بودند،قوانینی برای نگاشت پیامهای ورودی به پاسخها، به وسیلهی مجموعه بزرگی از دادههای آموزش[^training data]، بیایند و از این طریق پاسخ مناسب هر ورودی را به دست بیاورند.(این گروه مسائل تولید گفتار را جز مسائل source-to-target transduction به حساب میآورند.) ریتر[^Ritter] و همکارانش مشکل تولید پاسخ را به عنوان یک مسئله ترجمه ماشینی [^Machine Translation]دسته بندی کردند[3]. در ادامه سوردونی [^Sordoni] سیستم ریتر را بهبود بخشید. او به جای استفاده از سیستم مکالمه بر پایه ترجمه ماشینی کلمه به کلمه[^a phrasal SMT-based(**S**tatistical **M**achine **T**ranslation) conversation system]، از شبکههای عصبی بهره برد. پیشرفت شبکههای عصبی و همچنین مدل [^LSTM sequence-to-sequence(SEQ2SEQ) model]SEQ2SEQ، منجر به تلاشهای زیادی در جهت ساخت سیستمهای مکالمه [^conversation system] شد[4].
گروه دوم بر روی ساخت سیستمهای گفتگو وظیفهگرا، برای حل مسائل در دامنههای خاص تمرکز کردند. که بیشتر این تلاشها شامل فرآیند تصمیمگیری مارکف [^**M**arkov **D**ecision **P**rocesses (MDPs)]میشود.
#تعریف مسئله
همانطوری که در بخش قبل ذکر شد مدل seq2seq یکی از مدل های مورد استفاده در سیستمهای تولید پاسخ است که می تواند احتمال تولید پاسخ مناسب را بیشینه کند. اما با وجود موفقیت مدل seq2seq، استفاده از آن، سبب رخداد دو مشکل میگردد.
- مشکل اول :
این مدل با تابع [^the **M**aximum-**L**ikelihood **E**stimation (MLE) objective function: در علم آمار برآورد درستنمایی بیشینه روشی است برای برآورد کردن پارامترهای یک مدل آماری. وقتی بر مجموعهای از دادهها عملیات انجام میشود یک مدل آماری به دست میآید آنگاه درستنمایی بیشینه میتواند تخمینی از پارامترهای مدل ارائه دهد.(در بخشهای بعدی به توضیح بیشتر آن میپردازیم)]MLE آموزش دیده است. دراین مدل احتمال پاسخ به کاربر با جملاتی مانند "I don’t know" زیاد است. اما هدف رباتهای سخنگو، سرگرم کردن کاربر است و تولید این دست از پاسخها موجب از دست دادن مخاطب میگردد. پس به پاسخهایی نیاز داریم که علاوه بر دارا بودن اطلاعات، توجه مخاطب را نیز جلب کند.
- مشکل دوم :
به ستون سمت راست جدول زیر توجه کنید :

یکی دیگر از مشکلات معمول در استفاده از این مدل ایجاد حلقه بینهایت برای سیستم است که سیستم توانایی شکستن این حلقه را ندارد. در قسمت بالا سمت راست جدول، سیستم در سومین دیالوگ وارد حلقه بینهایت میشود.
با توجه به مشکلات بالا به مدلی نیاز داریم که به هدف [^ارتباط مفید با کاربر] رباتهای سخنگو به وسیله پاداش تعریف شده [^توسط توسعه دهنده] دست یابد و همچنین بتواند با در نظر گرفتن اثر بلند مدت[^long-term influence] یک پاسخ بر روی مکالمه جاری، از وقوع حالتهایی مانند ایجاد حلقه بینهایت بپرهیزد.
# مروری بر ادبیات و مقدمات لازم
##شبکه های [^**L**ong **S**hort-**T**erm **M**emory(حافظه طولانی کوتاه-مدت)]LSTM
شبکههای LSTM، نوع خاصی از شبکههای عصبی بازگشتی هستند که توانائی یادگیری وابستگیهای بلندمدت را دارند. این شبکهها برای اولین بار توسط سپ هوخرایتر[^Sepp Hochreiter] و یورگن اشمیدهوبر [^Jürgen Schmidhuber] در سال ۱۹۹۷ معرفی شدند[5]. و در سال 2000 میلادی توسط ژرس و اشمیدهوبر بهبود یافتند[6].
در حقیقت هدف از طراحی شبکههای LSTM، حل کردن مشکل وابستگی بلندمدت[^long-term dependency] بوده است. به یاد سپاری اطلاعات برای بازههای زمانی بلند مدت، رفتار پیشفرض شبکههای LSTM بوده و ساختار آنها به صورتی است که اطلاعات خیلی دور را به خوبی بخاطر میسپارند که این ویژگی در ساختار آنها نهفته است.
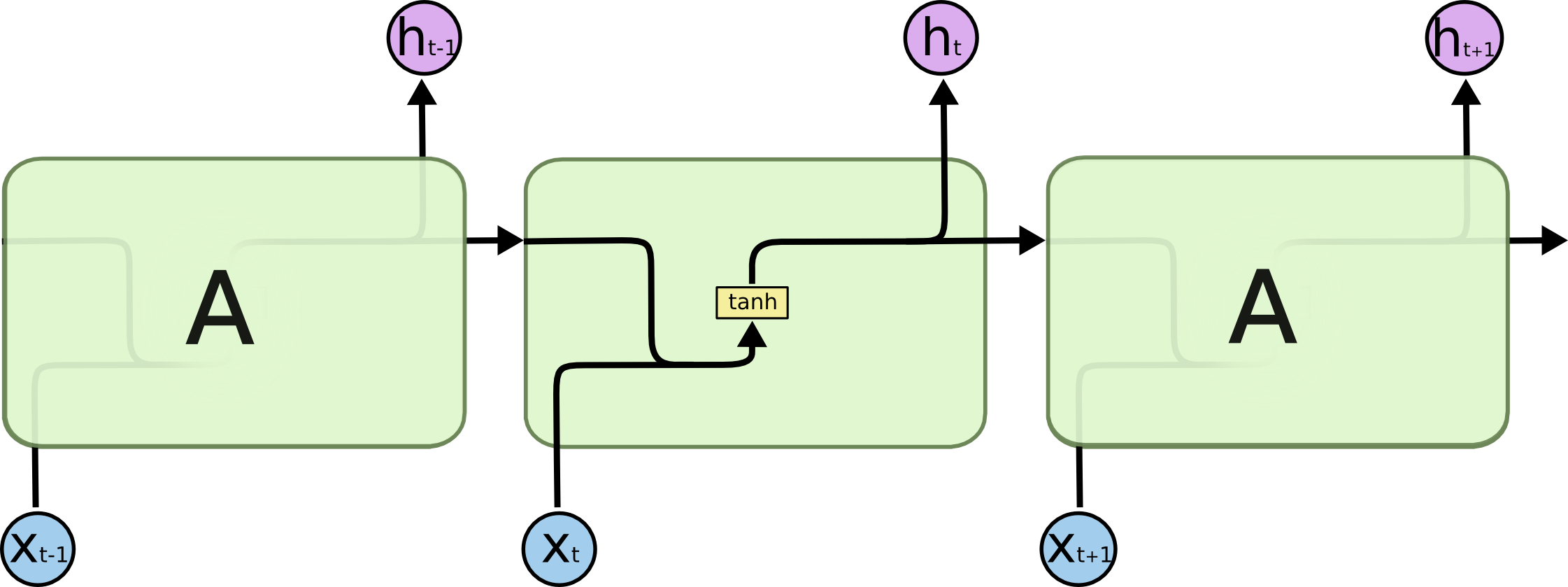
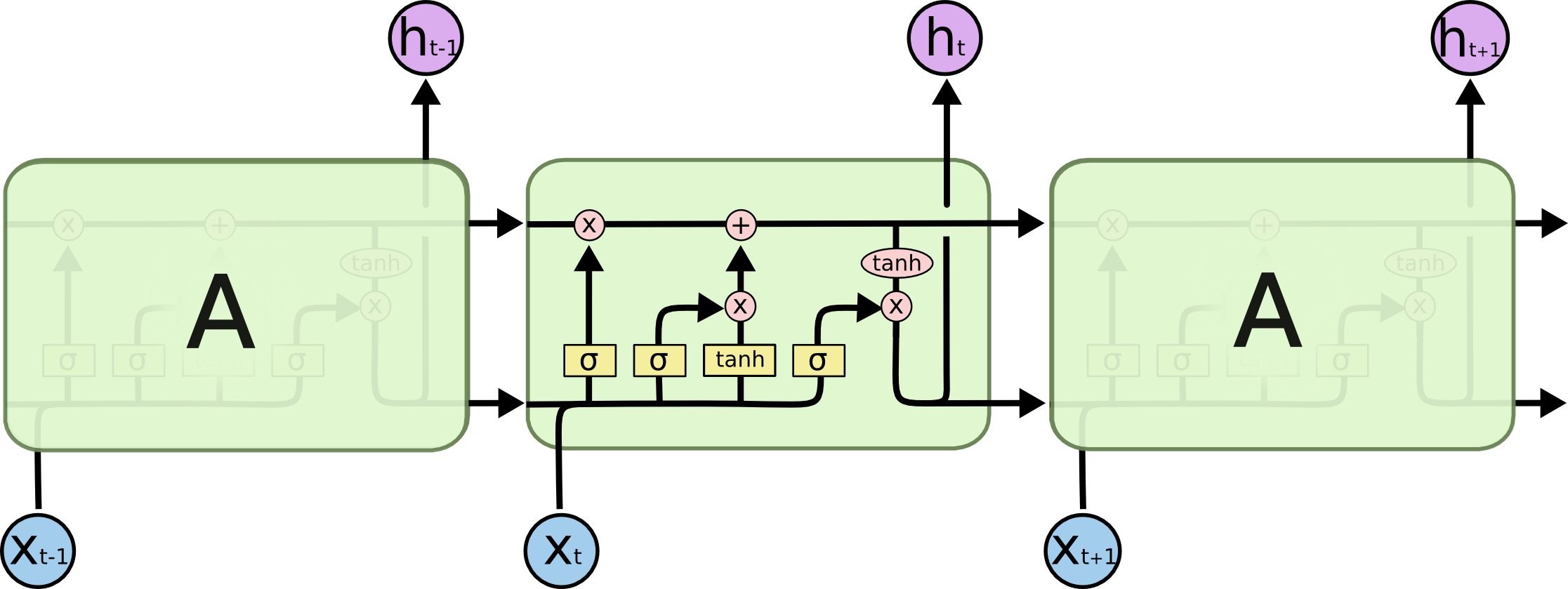
همه شبکههای عصبی بازگشتی به شکل دنبالهای (زنجیرهای) تکرار شونده، از ماژولهای (واحدهای) شبکههای عصبی هستند. در شبکههای عصبی بازگشتی استاندارد، این ماژولهای تکرار شونده ساختار سادهای دارند، در حالی که در شبکههای LSTM ماژول تکرار شونده به جای داشتن تنها یک لایه شبکه عصبی، ۴لایه دارند که طبق ساختار ویژهای با یکدیگر در تعامل و ارتباط هستند[8،7].
##مدل رمزنگار-رمزگشا (توالی به توالی ) شبکه [^ Encoder-Decoder( sequence-to-sequence) LSTM]LSTM
مدل رمزنگار-رمزگشا LSTM یک شبکه عصبی بازگشتی برای مسائلی است که یک دنباله را به دنباله دیگر نگاشت میکند. (یک دنباله به عنوان ورودی دریافت می کند و خروجی، دنباله دیگری است.) به همین دلیل به آن مدل seq2seq نیز گفته میشود. در مسائل seq2seq دنباله ورودی و خروجی میتوانند دارای طول های متفاوتی باشند به همین دلیل این مسائل از اهمیت زیادی برخوردار بوده و چالش برانگیزاند[9].
مدل seq2seq، در مسائلی چون ترجمه ماشینی، خلاصهکردن متن [^ Text summarization]و تشخیص گفتار[^ speech recognition] کاربرد دارد. به طور مثال در ترجمه ماشینی سنتی، جمله ها به چند قسمت تقسیم میشوند و هر قسمت به صورت جداگانه ترجمه میشود که منجر به اختلال در خروجی ترجمه میگردد. این در حالی است که انسان ها برای ترجمه یک جمله ابتدا معنای آن را متوجه میشوند سپس جمله را ترجمه میکنند. مدل seq2seq در ترجمه ماشینی از روش انسان گونهی ترجمه پیروی میکند.[10]
این معماری از ترکیب دو مدل تشکیل شده است. ابتدا دنباله ورودی رمزگذاری شده و به برداری از اعداد با طول ثابت تبدیل میشود که به آن، بردار فکر[^ thought vector] گفته میشود. سپس برای رمزگشایی، بردار به دنبالهی خروجی تبدیل میشود.[10،9]

# مدل یادگیری تقویتی
در این بخش به توضیح بخش های مختلف مدل مورد استفاده می پردازیم.
سیستم یادگیری شامل دو عامل است. (عامل اول را p و عامل دوم q مینامیم.) عامل ها به نوبت می توانند با دیگری صحبت کنند. یک گفتگو به صورت دنبالهای از جملهها است که به وسیله هر دو عامل تولید شده و به صورت زیر نمایش داده میشود.

## عمل
عمل [^action] **a** یک صحبت یا دیالوگ است که قرار است توسط یکی از عاملها تولید شود. فضای حالت اعمال، بی نهایت است زیرا دنبالههای تولید شده طول دلخواهی دارند.
## حالت
حالت [^state] به صورت دوتایی شامل** [p,q]** است که دیالوگ قبلی تولید شده توسط هر کدام از عاملها را نشان میدهد. تاریخچه گفتگو بین 2 عامل در یک بردار ذخیره میشود.
##پاداش
هر پاداش از 3 بخش تشکیل میشود که در زیر به توضیح آنها میپردازیم.
###سهولت در پاسخگویی[^Ease of answering]
پاسخ به دیالوگی که توسط ماشین تولید میشود باید آسان باشد.[^این جنبه از تولید کلام به تابع forward-looking مربوط می شود که در بخش بعد به توضیح آن می پردازیم.]حال میخواهیم این مقدار را اندازه بگیریم: جهت محاسبه میزان سهولت پاسخگویی، به جای محاسبه تمام حالتهایی که میتوانند جواب مناسبی داشته باشند، منفی احتمال جملاتی که باعث ایجاد گمراهی برای ماشین میشوند[^dull responses]مانند
- I don’t know what you are talking about.
- I have no idea.
را محاسبه میکنیم. مجموعه ای از این جملات (S)را در نظر گرفته و به کمک این مجموعه و احتمالات مدل seq2seq به محاسبه پاداش (r1) میپردازیم.

### جریان اطلاعات[^Information Flow]
میخواهیم از تولید پاسخهای تکراری توسط هر عامل جلوگیری کنیم. به همین منظور میزان شباهت معنایی بین نوبتهای متوالی یک عامل را محاسبه کرده و پاداش r2، برابر منفی لگاریتم cos شباهت بین این دو عامل است.

### هماهنگی معنایی[^Semantic Coherence]
همچینین میخواهیم از حالت هایی که پاسخ ها دارای امتیاز (پاداش) بالا هستند اما از نظر معنایی هماهنگی با مکالمه بین 2 عامل ندارند پرهیز کنیم. به همین دلیل میزان اشتراک اطلاعات بین عمل انتخاب شده و دیالوگهای قبلی بیان شده در متن را بررسی میکنیم .

پاداش نهایی عملی مانند a مجموع وزندار پاداشهای معرفی شده در بخشهای قبل است.
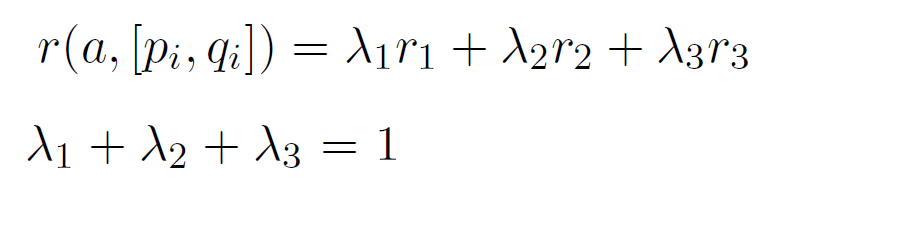
که در آن مجموع ضرایب پاداش ها 1 است. و در این مدل این ضرایب را با مقادیر زیر مقدار دهی می کنیم.
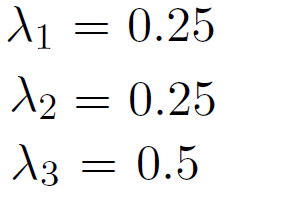
#معرفی مجموعه داده
جهت پیاده سازی این کار از مجموعه داده[^Dataset] ترجمه ماشینی WMT10 کنفرانس ACL [^**A**ssociation for** C**omputational **L**inguistics]2010 دانشگاه اوپسالا سوئد [^Uppsala University, Sweden] استفاده میشود. در این مجموعه حدود 22 میلیون [^به طور دقیق 225220376] جمله به زبان انگلیسی در حوزهها و مفاهیم مختلف در ارتباط با تکنولوژی،جامعه و غیره وجود دارد. همچنین مجموعه دادههایی به زبانهای دیگر نیز در آن موجود و قابل استفاده است. مجموعه داده مورد استفاده را از [لینک](http://www.statmt.org/wmt10/training-giga-fren.tar) زیر دریافت کنید. [11]
در مقاله اصلی از بخشی ازمجموعه داده سایت [Opensubtitle](http://www.opensubtitles.org/) استفاده شده است که شامل 10 میلیون پیام میباشد. که جهت اطمینان از ساده بودن مجموعه داده ورودی در پاسخگویی، 0.8 میلیون دنباله از آن استخراج شده که کمترین احتمال تولید جملاتی مانند:
- i don’t know what you are taking about.
به عنوان پاسخ در آن وجود داشته باشد.[12]
#مراجع <h1 align = "center">
<b>
تولید گفتگو به کمک یادگیری تقویتی عمیق
</b>
</h1>
----------
+ [لینک مرجع اصلی](https://db.tt/AaR6XjoPgX)
+ [لینک پیادهسازی](https://github.com/liuyuemaicha/Deep-Reinforcement-Learning-for-Dialogue-Generation-in-tensorflow)
----------
<p align = "center">
<b>
به نام خدا
</b>
</p>
#مقدمه
یکی از موضوعات مهمی که در سالهای اخیر در حوزه پردازش زبانهای طبیعی[^**N**atural **L**anguage **P**rocessing (NLP)] مورد توجه قرار گرفته، سیستمهای تولید گفتگو[^Dialogue System] است. سیستمهای تولید گفتگو یا عاملهای مکالمه کننده[^**C**onversational **A**gents (CA)] مانند دستیارهای شخصی [^Personal Assistants] و رباتهای سخنگو [^Chatbots] در جامعه امروز بسیار فراگیر شده است.[1] که می توان در این حوزه به دستیار های شخصی بر روی تلفن های همراه [^همچون Siri در Apple و Cortana در Microsoft]یا ربات های آنلاین در شبکههای اجتماعی همچون تلگرام اشاره کرد. با این حال پاسخ های تولید شده توسط این عامل ها، جملات کوتاه و قابل پیش بینی هستند.
دراین مقاله با استفاده از یادگیری تقویتی عمیق به تولید مدلی برای رباتهای سخنگو می پردازیم،که بتواند مشکلات ذکرشده، را رفع کرده و به تولید پاسخهای هماهنگ، منسجم و سرگرم کننده بیانجامد. این مدل، گفتگو بین دو عامل مجازی را با استفاده از سیستم پاداش و تنبیه جهت دستیابی به اهداف بلند مدت در گفتگو[^ منظور از اهداف بلند مدت سرگرم کردن کاربر، ادامه پیدا کردن مکالمه با دیالوگ های جدید، برخورد کمتر با جملات گنگ،جلوگیری از حلقه بی نهایت و غیره می باشد.]، پیاده سازی میکند.[2] این کار را می توان جز یکی از اولین قدم ها در حوزه تولید مکالمه در جهت دستیابی به اهداف بلند مدت دانست.
#کارهای مرتبط
تلاش های انجام شده برای ساخت سیستمهای گفتگو، را می توان به دو گروه اصلی تقسیم کرد:
گروه اول در تلاش بودند،قوانینی برای نگاشت پیامهای ورودی به پاسخها، به وسیلهی مجموعه بزرگی از دادههای آموزش[^Training data]، بیایند و از این طریق پاسخ مناسب هر ورودی را به دست بیاورند.(این گروه مسائل تولید گفتار را جز مسائل source-to-target transduction به حساب میآورند.) ریتر[^Ritter] و همکارانش مشکل تولید پاسخ را به عنوان یک مسئله ترجمه ماشینی[^Machine Translation]دسته بندی کردند.[3] در ادامه سوردونی[^Sordoni] سیستم ریتر را بهبود بخشید. او به جای استفاده از سیستم مکالمه بر پایه ترجمه ماشینی کلمه به کلمه[^a phrasal SMT-based(**S**tatistical **M**achine **T**ranslation) conversation system]، از شبکههای عصبی بهره برد. پیشرفت شبکههای عصبی و همچنین مدل [^LSTM sequence-to-sequence(SEQ2SEQ) model]SEQ2SEQ، منجر به تلاشهای زیادی در جهت ساخت سیستمهای مکالمه[^Conversation System] شد.[4]
گروه دوم بر روی ساخت سیستمهای گفتگو وظیفهگرا، برای حل مسائل در دامنههای خاص تمرکز کردند. که بیشتر این تلاشها شامل فرآیند تصمیمگیری مارکف[^**M**arkov **D**ecision **P**rocesses (MDPs)]میشود.
#تعریف مسئله
همانطوری که در بخش قبل ذکر شد مدل seq2seq یکی از مدل های مورد استفاده در سیستمهای تولید پاسخ است که می تواند احتمال تولید پاسخ مناسب را بیشینه کند. اما با وجود موفقیت مدل seq2seq، استفاده از آن، سبب رخداد دو مشکل میگردد.
- مشکل اول :
این مدل با تابع [^the **M**aximum-**L**ikelihood **E**stimation (MLE) objective function: در علم آمار برآورد درستنمایی بیشینه روشی است برای برآورد کردن پارامترهای یک مدل آماری. وقتی بر مجموعهای از دادهها عملیات انجام میشود یک مدل آماری به دست میآید آنگاه درستنمایی بیشینه میتواند تخمینی از پارامترهای مدل ارائه دهد.]MLE آموزش دیده است. دراین مدل احتمال پاسخ به کاربر با جملاتی مانند "I don’t know" زیاد است. اما هدف رباتهای سخنگو، سرگرم کردن کاربر است و تولید این دست از پاسخها موجب از دست دادن مخاطب میگردد. پس به پاسخهایی نیاز داریم که علاوه بر دارا بودن اطلاعات، توجه مخاطب را نیز جلب کند.
- مشکل دوم :
به ستون سمت چپ جدول زیر توجه کنید :

یکی دیگر از مشکلات معمول در استفاده از این مدل ایجاد حلقه بینهایت برای سیستم است که سیستم توانایی شکستن این حلقه را ندارد. در قسمت بالا سمت چپ جدول، سیستم در سومین دیالوگ وارد حلقه بینهایت میشود. (جدول 1)
با توجه به مشکلات بالا به مدلی نیاز داریم که به هدف[^ارتباط مفید با کاربر] رباتهای سخنگو به وسیله پاداش تعریف شده[^توسط توسعه دهنده] دست یابد و همچنین بتواند با در نظر گرفتن اثر بلند مدت[^Long-term influence] یک پاسخ بر روی مکالمه جاری، از وقوع حالتهایی مانند ایجاد حلقه بینهایت بپرهیزد.
# مروری بر ادبیات و مقدمات لازم
##شبکه های[^**L**ong **S**hort-**T**erm **M**emory(حافظه طولانی کوتاه-مدت)]LSTM
شبکههای LSTM، نوع خاصی از شبکههای عصبی بازگشتی هستند که توانائی یادگیری وابستگیهای بلندمدت را دارند. این شبکهها برای اولین بار توسط سپ هوخرایتر[^Sepp Hochreiter] و یورگن اشمیدهوبر [^Jürgen Schmidhuber] در سال ۱۹۹۷ معرفی شدند.[5] و در سال 2000 میلادی توسط ژرس و اشمیدهوبر بهبود یافتند.[6]
در حقیقت هدف از طراحی شبکههای LSTM، حل کردن مشکل وابستگی بلندمدت[^Long-term dependency] بوده است. به یاد سپاری اطلاعات برای بازههای زمانی بلند مدت، رفتار پیشفرض شبکههای LSTM بوده و ساختار آنها به صورتی است که اطلاعات خیلی دور را به خوبی بخاطر میسپارند که این ویژگی در ساختار آنها نهفته است.
همه شبکههای عصبی بازگشتی به شکل دنبالهای (زنجیرهای) تکرار شونده، از ماژولهای (واحدهای) شبکههای عصبی هستند. در شبکههای عصبی بازگشتی استاندارد، این ماژولهای تکرار شونده ساختار سادهای دارند، در حالی که در شبکههای LSTM ماژول تکرار شونده به جای داشتن تنها یک لایه شبکه عصبی، ۴لایه دارند که طبق ساختار ویژهای با یکدیگر در تعامل و ارتباط هستند.[8،7] (شکلهای 1 و 2)


##مدل رمزنگار-رمزگشا (توالی به توالی ) شبکه [^ Encoder-Decoder( sequence-to-sequence) LSTM]LSTM
مدل رمزنگار-رمزگشا LSTM یک شبکه عصبی بازگشتی برای مسائلی است که یک دنباله را به دنباله دیگر نگاشت میکند. (یک دنباله به عنوان ورودی دریافت می کند و خروجی، دنباله دیگری است.) به همین دلیل به آن مدل seq2seq نیز گفته میشود. در مسائل seq2seq دنباله ورودی و خروجی میتوانند دارای طول های متفاوتی باشند به همین دلیل این مسائل از اهمیت زیادی برخوردار بوده و چالش برانگیزند.[9]
مدل seq2seq، در مسائلی چون ترجمه ماشینی، خلاصهکردن متن [^ Text summarization]و تشخیص گفتار[^ Speech Recognition] کاربرد دارد. به طور مثال در ترجمه ماشینی سنتی، جملهها به چند قسمت تقسیم میشوند و هر قسمت به صورت جداگانه ترجمه میشود که منجر به اختلال در خروجی ترجمه میگردد. این در حالی است که انسان ها برای ترجمه یک جمله ابتدا معنای آن را متوجه میشوند سپس جمله را ترجمه میکنند. مدل seq2seq در ترجمه ماشینی از روش انسان گونهی ترجمه پیروی میکند.[10]
این معماری از ترکیب دو مدل تشکیل شده است. ابتدا دنباله ورودی رمزگذاری شده و به برداری از اعداد با طول ثابت تبدیل میشود که به آن، بردار فکر[^ Thought vector] گفته میشود. سپس برای رمزگشایی، بردار به دنبالهی خروجی تبدیل میشود.[10،9] (شکل 3)

# مدل یادگیری تقویتی
در این بخش به توضیح بخش های مختلف مدل مورد استفاده می پردازیم.
سیستم یادگیری شامل دو عامل است. (عامل اول را p و عامل دوم q مینامیم.) عامل ها به نوبت می توانند با دیگری صحبت کنند. یک گفتگو به صورت دنبالهای از جملهها است که به وسیله هر دو عامل تولید شده و به صورت زیر نمایش داده میشود. (فرمول 1)
----------
$${p}_{1}, {q}_{1}, {p}_{2}, {q}_{2}, ... , {p}_{i}, {q}_{i} $$
<p align = "center">فرمول شماره 1 - دنبالهای از جملهها</p>
----------
## عمل
عمل[^Action] **a** یک صحبت یا دیالوگ است که قرار است توسط یکی از عاملها تولید شود. فضای حالت اعمال، بی نهایت است زیرا دنبالههای تولید شده طول دلخواهی دارند.
## حالت
حالت [^State] به صورت دوتایی شامل** [p,q]** است که دیالوگ قبلی تولید شده توسط هر کدام از عاملها را نشان میدهد. تاریخچه گفتگو بین 2 عامل در یک بردار ذخیره میشود.
##سیاست
سیاست[^Policy]، احتمال انتخاب یک عمل را وقتی در یک حالت خاص سیستم هستیم، به ما میدهد[^به طور مثال احتمال انتخاب عمل a به شرط بودن در حالت s هستیم.]. ما از نمایش تصادفی سیاست استفاده میکنیم که همان توزیع احتمال بر روی عملها نسبت به حالتهای داده شده است. سیاست در اینجا به شکل یک مدل رمزنگار-رمزگشا در شبکه LSTM تعریف شده و به صورت زیر است. (فرمول شماره 2)
----------
$${P}_{RL} ({p}_{i+1}| {p}_{i},{q}_{i})$$
<p align = "center">فرمول شماره 2</p>
----------
##پاداش
هر پاداش از 3 بخش تشکیل میشود که در زیر به توضیح آنها میپردازیم.
###سهولت در پاسخگویی[^Ease of answering]
پاسخ به دیالوگی که توسط ماشین تولید میشود باید آسان باشد.[^این جنبه از تولید کلام به تابع forward-looking مربوط میشود.]حال میخواهیم این مقدار را اندازه بگیریم: جهت محاسبه میزان سهولت پاسخگویی، به جای محاسبه تمام حالتهایی که میتوانند جواب مناسبی داشته باشند، منفی احتمال جملاتی که باعث ایجاد گمراهی برای ماشین میشوند[^Dull responses]مانند دو جمله زیر :
- I don’t know what you are talking about.
- I have no idea.
را محاسبه میکنیم. مجموعه ای از این جملات (S)را در نظر گرفته و به کمک این مجموعه و احتمالات مدل seq2seq به محاسبه پاداش (r1) میپردازیم. (فرمول 3)
----------
$$r_1 = - \frac{1}{N_\mathbb{S}}\sum\limits_{s\in\mathbb{S}}\frac{1}{N_s}log p_{seq2seq}(s|a)$$
<p align = "center">فرمول شماره 3 - محاسبه پاداش r1</p>
----------
در این فرمول مقدار ${N_\mathbb{S}$ NS برابر تعداد عناصر مجموعه S ${mathbb{S\$ ، Ns تعداد واحدهای سازنده در یک جمله گمراهکننده s و Pseq2seq احتمال خروجی به وسیله مدل seq2seq است.
### جریان اطلاعات[^Information Flow]
میخواهیم از تولید پاسخهای تکراری توسط هر عامل جلوگیری کنیم. به همین منظور میزان شباهت معنایی بین نوبتهای متوالی یک عامل را محاسبه کرده و پاداش r2، برابر منفی لگاریتم cos شباهت بین این دو عامل است.
----------
$$r_2 = -log cos (\theta) = - log \frac {h_{p_i}. h_{{p}_{i+1}}} {|| h_{p_i} || || h_{p_{i+1}}||}$$
<p align = "center">فرمول شماره 4 - محاسبه پاداش r2</p>
----------
مقادیر hpi و hpi+1 در فرمول شماره 4 نمایش بردار رمزنگار در 2 نوبت متوالی pi و pi+1 را نشان میدهند.
### هماهنگی معنایی[^Semantic Coherence]
همچینین میخواهیم از حالت هایی که پاسخ ها دارای امتیاز (پاداش) بالا هستند اما از نظر معنایی هماهنگی با مکالمه بین 2 عامل ندارند پرهیز کنیم. به همین دلیل میزان اشتراک اطلاعات بین عمل انتخاب شده و دیالوگهای قبلی بیان شده در متن را بررسی میکنیم .
----------
$$r_3 = f\frac {1}{N_a} log p _{seq2seq}(a| q_i , p_i) + \frac {1}{N_{q_i}}log p_{seq2seq}^{backward}$$
<p align = "center">فرمول شماره 5 - محاسبه پاداش r3</p>
----------
مقادیر Pseq2seq احتمال رخداد a در دیالوگ قبلی [pi,qi] و Pbackward seq2seq احتمال رخداد دیالوگ قبلی بر حسب a را نشان میدهد.
پاداش نهایی عملی مانند a مجموع وزندار پاداشهای معرفی شده در بخشهای قبل است.
----------
$$r (a , [p_i,q_i] )= {\lambda}_{1}r_1 + {\lambda}_{2}r_2 + {\lambda}_{3}r_3 $$
<p align = "center">فرمول شماره 6 - جمع وزندار پاداشهایی r2,r1وr3</p>
$$ {\lambda}_{1} + {\lambda}_{2}+ {\lambda}_{3} = 1 $$
<p align = "center">فرمول شماره 7</p>
----------
که در آن مجموع ضرایب پاداش ها 1 است. (فرمول 7) و در این مدل این ضرایب را با مقادیر زیر مقدار دهی می کنیم. (فرمول 8)
----------
$${\lambda}_{1} = 0.25$$
$${\lambda}_{2} = 0.25$$
$${\lambda}_{3} = 0.5$$
<p align = "center">فرمول شماره 8 - مقادیر ضرایب پاداش ها در این مدل </p>
----------
# شبیه سازی[^Simulation]
مسئله اصلی مد نظر در این کار، پیاده سازی فرآیند صحبت کردن دو عامل مجازی، با درنظر گرفتن نوبت است. برای حل این مسئله ابتدا فضای حالت-عمل را جستجو کرده تا مدل، سیاستی را یاد بگیرد که منجر به پاداش بهینه شود.$${P}_{RL} ({p}_{i+1}| {p}_{i},{q}_{i})$$
برای پیاده سازی راه حل ذکر شده، از راهبرد[^Strategy] ابداع شده توسط گوگل در پروژه [^آلفاگو (AlphaGo) یک برنامه رایانهای است که توسط Google DeepMind در لندن، برای بازی تختهای Go توسعه یافتهاست. آنها برای آموزش برنامه خود از ترکیب جدیدی از یادگیری بانظارت از بازی انسان های خبره و یادگیری تقویتی از بازی های که خود برنامه انجام میدهد، استفاده میکنند. برای اطلاعات بیشتر در مورد این برنامه میتوانید به مرجع 12 و 13 مراجعه کنید.]AlphaGo استفاده میشود.[13،12،11] بر این اساس مدل یادگیری تقویتی به کمک سیاستی که به صورت بانظارت آموزش دیده است، مقدار دهی اولیه میشود.
##یادگیری با نظارت[^Supervised Learning]
درمرحله اول آموزش، براساس کارهای قبلی انجام شده در این حوزه عمل کرده و به کمک مدل SEQ2SEQ بانظارت و با توجه به تاریخچه گفتگو داده شده، یک دنباله پیشبینی میکنیم. نتایج به دستآمده از مدل بانظارت، در آینده برای مقداردهی اولیه استفاده میشود. مدل SEQ2SEQ را با توجه به مجموعه داده OpenSubtitles (در بخش 7.1 بیشتر توضیح داده میشود.) که 80 میلیون جفت منبع-هدف [^source-target pair] را شامل میشود، آموزش داده و در مجموعه داده هر نوبت را یک هدف و پیوند دو جمله قبلی را به عنوان ورودی یا منبع هر مرحله درنظر میگیریم.
## اطلاعات مشترک[^Mutual Information]
اغلب نمونههایی که از مدل SEQ2SEQبه دست میآیند (جملاتی مانند "i don’t know") گنگ و عمومی هستند. بنابراین ما نمیخواهیم از مدل SEQ2SEQ برای پیشآموزش[^pre-train] سیاست مدنظر برای این مسئله استفاده کنیم. زیرا موجب عدم تنوع در مدل RL میشود. لی و همکارانش نشان دادند که مدل کردن اطلاعات مشترک بین منبعها و هدفها به مقدار قابل توجهی احتمال تولید پاسخهای گنگ را کاهش میدهد و کیفیت پاسخهای تولید شده را بالا میبرد. حال میخواهیم مدل رمزنگار-رمزگشا را بهدست آوریم که پاسخ هایی تولید کند که دارای حداکثر اطلاعات مشترک باشند.[14]
ما با مسئله تولید پاسخهای دارای حداکثر اطلاعات مشترک به عنوان یک مسئله یادگیری تقویتی برخورد میکنیم که پاداش اطلاعات مشترک زمانی مشاهده میشود که مدل به پایان یک دنباله برسد. برای بهینهسازی از روش policy gradient استفاده میکنیم.
در این مرحله سیاست مدل Prl با استفاده از یک مدل از پیش آموزش دیده(Pseq2seq(a | pi,qi مقداردهی میشود. سپس با توجه به منبع ورودی داده شده [pi,qi]، یک لیست نامزدی تولید میکنیم.(فرمول 9) به ازای هر نامزد به کمک مدل از پیشآموزشدیده (Pseq2seq(a | pi,qi و (PbackwardSeq2Seq(qi | a امتیاز اطلاعات مشترک را محاسبه میکنیم. این امتیاز به عنوان پاداش برای مدل رمزگشا - رمزنگار استفاده میشود تا موجب بهبود شبکه برای تولید دنبالههایی با پاداش بالاتر شود[^برای اطلاعات بیشتر میتوانید به منبع15 مراجعه کنید.].[15] پاداش مد نظر برای یک دنباله به شکل زیر است : (فرمول 10)
----------
$$ A= \big\{ \hat{a} | \hat{a} \sim {P}_{RL}\big\}$$
<p align = "center">فرمول شماره 9 -لیست نامزدها</p>
$$ J ( \theta ) = E \big[ m ( \hat{a} , \big[ p_i , q_i \big] ) \big] $$
<p align = "center">فرمول شماره 10</p>
----------
و گرادیان به روش زیر تخمین زده میشود.(فرمول 11)
----------
$$ \nabla J ( \theta ) = m ( \hat{a} , \big[ p_i , q_i \big] ) \nabla log {P}_{RL} (\hat{a} | \big[ p_i , q_i \big] ) $$
<p align = "center">فرمول شماره 11</p>
----------
##شبیهسازی گفتگو بین دو عامل
مکالمه بین دو عامل مجازی که به نوبت با یکدیگر صحبت میکنند را شبیهسازی کردیم. مراحل شبیهسازی به شرح زیر است :
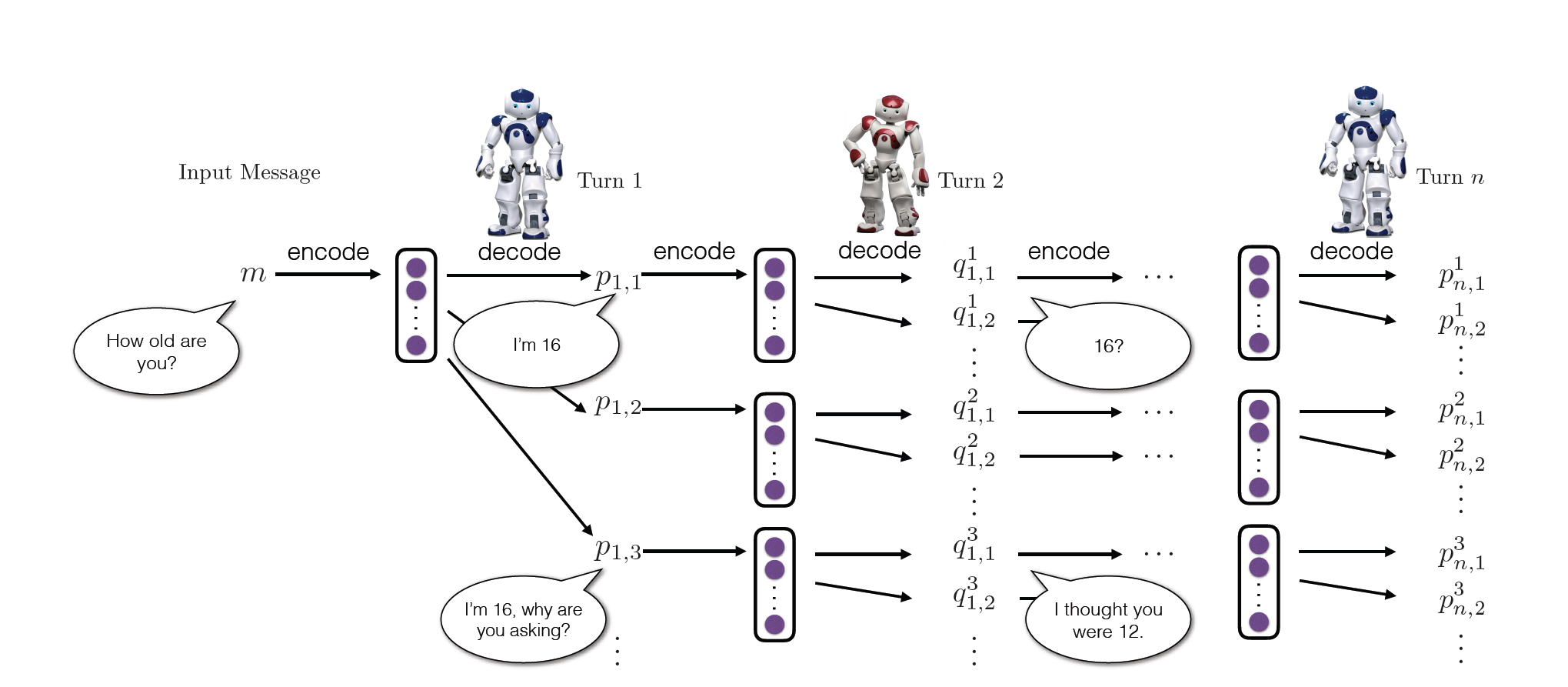
در گام اول یک مسیج از مجموعه آموزش به اولین عامل فرستاده میشود. عامل پیام ورودی به یک بردار رمزگذاری میکند و سپس برای تولید پاسخ خروجی به کمک شبکه، بردار را رمز گشایی میکند. با ترکیب کردن خروجی عامل اول با تاریخچه گفتگو، عامل دوم حالت خود را بروزرسانی میکند. عامل دوم تاریخچه گفتگو را به صورت نمایش برداری رمزنگاری کرده و با استفاده از رمزگشا RNN پاسخهای خود را تولید میکند که متعاقبا به عامل اول باز می گردد. و این روند دوباره تکرار میشود. (شکل 4)
### بهینهسازی
در این بخش برای بهینه کردن مدل میتوان مدل سیاست Prl را با مقادیر مدل اطلاعات مشترک مقداردهی کرد. که در بخش قبل به توضیح آن پرداختهشد. سپس از روش policy gradient برای یافتن پارامترهایی که به سمت پاداش بیشتر رهنمون میشوند، استفاده کرد. مقدار پاداش بیشینه به صورت زیر بهدست میآید. (فرمول 12) و سپس گرادیان را نیز میتوان به صورت تقریبی از طریق فرمول 13 یافت.
----------
$$J_{RL} ( \theta ) = E_{ PRL (a_{1:T})} \big[ \sum_{i=1}^{i=T} R( {a}_{i} , \big[ p_i , q_i \big] ) \big]$$
<p align = "center">فرمول شماره 12</p>
$$ \nabla J_{RL} ( \theta ) \approx \sum_{i} \nabla log p ({a}_{i} | p_i , q_i ) \sum_{i=1}^{i=T} R( {a}_{i} , \big[ p_i , q_i \big] ) $$
<p align = "center">فرمول شماره 13</p>
----------
#نتایج تجربی [^Experimental Results]
در این بخش نتایج تجربی همراه با دو نوع ارزیابی ارائه میشود. ما سیستمهای تولید گفتار را با استفاده از قضاوت های انسانی و دو معیار خودکار ارزیابی میکنیم. معیارهای خودکار به شرح زیر است:
1. طول مکالمه (تعداد نوبت ها در کل دوره).
2. تنوع.
##معرفی مجموعه داده
در شبیهسازی گفتگو ورودیهای اولیه که به عامل داده میشوند باید از کیفیت بالایی برخوردار باشند. برای مثال ورودی اولیه به صورت "?why" نامطلوب است از آنجایی که مشخص نیست چطور می تواند گفتگو را ادامه پیدا کند.
جهت پیاده سازی این کار از مجموعه داده[^Dataset] ترجمه ماشینی WMT10 کنفرانس ACL [^**A**ssociation for** C**omputational **L**inguistics]2010 دانشگاه اوپسالا سوئد [^Uppsala University, Sweden] استفاده میشود. در این مجموعه حدود 22 میلیون [^به طور دقیق 225220376] جمله به زبان انگلیسی در حوزهها و مفاهیم مختلف در ارتباط با تکنولوژی،جامعه و غیره وجود دارد. همچنین مجموعه دادههایی به زبانهای دیگر نیز در آن موجود و قابل استفاده است. مجموعه داده مورد استفاده را از این [لینک](http://www.statmt.org/wmt10/training-giga-fren.tar) دریافت کنید. [16]
در مقاله اصلی از بخشی ازمجموعه داده سایت [Opensubtitle](http://www.opensubtitles.org/) استفاده شده است که شامل 10 میلیون پیام میباشد. که جهت اطمینان از ساده بودن مجموعه داده ورودی در پاسخگویی، 0.8 میلیون دنباله از آن استخراج شده که کمترین احتمال تولید جملاتی مانند:
- i don’t know what you are taking about.
به عنوان پاسخ در آن وجود داشته باشد.[17]
## پیادهسازی
برای پیادهسازی این پروژه از ابزار یادگیری عمیق [tensorflow](https://www.tensorflow.org/) استفاده خواهیم کرد. کد پیادهسازی آن نیز در این [لینک](https://github.com/liuyuemaicha/Deep-Reinforcement-Learning-for-Dialogue-Generation-in-tensorflow) موجود است. که در فازهای آینده به توضیح بیشتر آن خواهیم پرداخت.
## ارزیابی خودکار[^Automatic Evaluation]
ارزیابی سیستمهای گفتگو دشوار است. معیارهایی مانند [^معیار**B**ilingual **E**valuation **U**nderstudy ) BLEU) روشی برای ارزیابی کیفی متن ترجمه شده توسط ماشین یا همان ترجمه ماشینی است.کیفیت ترجمه با عددی بین ۰ و ۱ اندازهگیری و اغلب به صورت درصد گزارش میشود. این عدد نمایانگر میزان نزدیکی ترجمه به مجموعهای از ترجمههای انسانی با کیفیت خوب (مجموعه مرجع) است.]BLEU و سرگشتگی[^Perplexity] به طور گسترده برای ارزیابی کیفیت گفتگو استفاده میشوند.[18] از آنجایی که هدف از سیستم پیشنهادی، پیشبینی پاسخ با بیشترین احتمال نیست، بلکه موفقیت طولانی مدت گفتگو مدنظر است ما معیارهای خودکار BLEU و یا سرگشتگی را برای ارزیابی به کار نمیگیریم.
### طول گفتگو[^Length of the dialogue]
اولین معیار پیشنهادی ما طول دوره گفتمان شبیهسازی شده است. از نظر ما یک گفتگو زمانی به اتمام میرسد که یکی از عاملها، شروع به تولید پاسخهای گمراه کننده[^Dull responses (کسل کننده یا راکد)] مانند "i don’t know" کند یا دو حرف متوالی از یک کاربر همپوشانی بسیاری داشته باشد.
مجموعه آزمایش شامل 1000 پیام ورودی است. برای کاهش احتمال[^Risk] ایجاد حلقه در گفتگوها[^Circular dialogues]، تعداد نوبتهای شبیه سازی شده را به کمتر از 8 نوبت محدود میکنیم. نتایج این بخش در جدول 2 نشان داده شده است. (جدول 2)
| |نوع مدل|متوسط تعداد نوبت های شبیهسازی شده|
|:------|:-----:|:--------------------:|
| |SEQ2SEQ|2.68|
| |Mutual Information|3.40|
| |RL|4.48|
>جدول 2 - متوسط تعداد نوبتهای شبیهسازی شده برای مدلهای seq2seq استاندارد، مدل اطلاعات مشترک و مدل پیشنهادی RL.
همانطوری که دیده میشود استفاده از اطلاعات مشترک منجر به گفتگوهای پایدارتری بین دو عامل میشود. مدل RL پیشنهادی ابتدا بر مبنای مدل اطلاعات مشترک آموزش داده میشود. و در نتیجه از آن، علاوه بر مدل RL سود میبرد. ما مشاهده میکنیم که مدل RL در این نوع ارزیابی برای شبیهسازی گفتار بهترین امتیاز را کسب میکند.
### تنوع[^Diversity]
درجه تنوع را با محاسبه تعداد یکتایی[^Unigram]ها و دوتایی[^Bigram]های مجزا در پاسخهای تولید شده، گزارش میگردد. این مقدار به وسیله تعداد کل واحد[^Token]های تولید شده، درجهبندی میشود تا از پیشنهاد جملات طولانی (برای بالابردن پاداش با ایجاد تنوع) اجتناب کند[^برای مطالعه بیشتر میتوانید به مرجع شماره 14 مراجعه کنید.].[14] بنابراین معیار تنوع نسبت نوع و واحدهای سازنده متن[^type-token ratio] برای یکتاییها ودوتاییها است. امتیاز مدلهای مختلف براساس تنوع پاسخهای تولید شده را در جدول 3 میبینید.
| |نوع مدل|یکتاییها|دوتاییها|
|:------|:-----:|:--------------------:|:-------:|
| |SEQ2SEQ|0.0062|0.015|
| |Mutual Information|0.011|0.031|
| |RL|0.017|0.041|
>جدول 3 - امتیازهای تنوع پاسخها (نسبت نوع-واحدهای سازنده متن) برای مدلهای SEQ2SEQ استاندارد، اطلاعات مشترک و مدل RL پیشنهادی.
با توجه به نتایج جدول درمییابیم که خروجیهای تولید شده توسط مدل RL پیشنهادی نسبت به دیگر مدلها (در مقایسه با مدلهای اطلاعات مشترک و seq2seq استاندارد) از تنوع بیشتری برخوردارند. (جدول 3)
##ارزیابی انسانی[^Human Evaluation]
برای ارزیابی انسانی سه نوع تنظیم متفاوت را درنظرمیگیریم. در تنظیم اول از داوران عمومی[^ داوران از بین مردم : crowdsourced judges] برای ارزیابی یک نمونه تصادفی از بین 500 نمونه، استفاده میکنیم. سپس پیام ورودی و پیام خروجی انتخاب شده را به سه داور تحویل میدهیم و از آنها میخواهیم تا تصمیم بگیرند کدام یک از دو خروجی داده شده بهتر است. این تنظیم که کیفیت یک خروجی را به تنهایی در یک نوبت میسنجد، با نام **single-turn general quality** مشخص میکنیم.
در دومین تنظیم،دوباره پیامهای ورودی و خروجیهای سیستم به داورها ارائه میشود. اما این بار از آن ها در خواست می شود که از بین دو خروجی، خروجی را انتخاب کنند که پاسخ به آن راحتتر باشد. این تنظیم که میزان سادگی برای پاسخگویی در یک نوبت را نشان میدهد،**single-turn ease to answer** مینامیم. مجددا در این سنجش نیز یک نمونه تصادفی از 500 مورد را ارزیابی میکنیم که هر کدام به 3 داور تحویل داده میشود.
برای سومین تنظیم، مکالمات شبیه سازی شده بین دو عامل به داورها ارائه میشود. هر مکالمه شامل 5 نوبت است. ما 200 مکالمه شبیهسازی شده را ارزیابی میکنیم، و هر کدام را به سه داور تحویل میدهیم و از آنها میخواهیم که در مورد این که کدام یک از مکالمات شبیه سازی شده از کیفیت بالاتری برخوردار است، تصمیم بگیرند. این تنظیم **multi-turn general quality** نام دارد.
ما بهبود حاصل از مدل RL نسبت به مدل اطلاعات مشترک را با میانگین اختلاف امتیازات بین مدلها اندازهگیری میکنیم.
| |نوع تنظیم|RL-win|RL-lose||
|:-------|:------:|:------:|:--------:|:---------:|
||single-turn general quality|0.40|0.36|
||single-turn ease to answer|0.52|0.23|
||multi-turn general quality|0.72|0.12|
>جدول 4 - بهره سیستم RL بر سیستم اطلاعاتی مشترک براساس زوج های داوری انسانی.
نتایج ارزشیابی انسانی در جدول 4 نشان داده شده است. همانطور که انتظار میرفت، سیستم RL پیشنهادی افزایش قابل توجهی در کیفیت یک تک نوبت (حالت1) ایجاد نمیکند. (بردن در 40 درصد زمانها شکست در36 درصد زمانها) زیرا مدل RL برای پیشبینی حرف بعدی بهینهسازی نشده است، بلکه برای افزایش پاداش بلندمدت است. با توجه به پاداش در نظر گرفته برای مدل RL در مراحل قبلی،سیستم RL جوابهایی را تولید میکند که پاسخ به آنها به طور قابل توجهی سادهتر از سیستم اطلاعات مشترک است. همچنین مقادیر جدول در تنظیم سادگی پاسخ در یک نوبت بر گفتههای قبلی دلالت دارد در این تنظیم میزان بردن 52 % زمانها و میزان باختن 23% زمانهاست. و همچنین در گفتگوهای چند نوبته نیز مدل RL پیشنهادی، به طور قابل ملاحظهای کیفیت بالاتری دارند. (نتایج در حالت سوم جدول 4 نشان داده شده است.)
# نتایج و کارهای آینده
##تجزیه و تحلیل کیفی مدل
یک نمونه تصادفی از پاسخهای تولید شده با توجه به پیام ورودی، در جدول شماره 5 نشان داده شده است وهمچنین نمونهای از مکالمات شبیهسازی شده را نیز در جدول 1 ابتدای مقاله ملاحظه میکنید.
| |RL|مدل اطلاعات مشترک|پیام ورودی|
|:----|:------:|:------:|:------:|
||?I’m 16, why are you asking|.I’m 16|?How old are you|
||?What’s yours|.I have no idea|?What’s your full name|
||?Why|?Really|.I don’t want to go home tonight|
||.I don’t want to hurt your feelings|.I don’t know what you are talking about|?Do you have any feelings for me|
||.Ten seconds|.Not long enough. Sorry, sir|?How much time do you have here|
|| .Yes. We’ve got a lot of work to do here| !Of course|?Shall we get started|
||!Yes. I love football|.No, i don’t|?Do you play football|
|| ?About what|I mean, he’s a good guy|.We’d have to talk to him|
||.I don’t think it’s a good idea to say it|.Because I don’t want to hurt you|?How come you never say it|
>جدول 5 - نمونه پاسخهای تولید شده با مدلهای اطلاعات مشترک و RL پیشنهادی.
از جدول 5 میتوان نتیجهگرفت که عامل بر مبنای مدل RL، پاسخهای تعاملیتری را نسبت به بقیه مدلها تولید میکند و همچنین مدل RL، به پایان دادن جمله با سوالی دیگر و انتقال مکالمه به عامل دیگر، گرایش دارد. و همانطوری که در جدول 1 نیز مشاهده میکنید مدل RL موفق به تولید مکالمات تعاملی و پایدارتری نسبت به مدل اطلاعات مشترک میگردد. (جدول 1و5)
### تحلیل خطا
با اینکه در این مدل پاسخهای تکراری جریمه میشوند (به آنها پاداش منفی اختصاص داده شده است)، گاهی گفتگوها در یک حلقه تکراری با طولی بیشتر از یک میافتند مانند آنچه در جدول 6 مشاهده میشود. این شرایط در مقدار محدودی از تاریخچههای گفتگو رخ میدهد. (جدول 6)
A: What’s your name ?
B: Daniel.
A: How old are you ?
B: Twelve. What’s your name ?
A: Daniel.
B: How old are you ?
A: Twelve. What’s your name ?
B: Daniel.
A: How old are you ?
B: ...
> جدول 6 - یک نمونه مکالمه شبیهسازی شده با یک حلقه با طول بیشتر از یک.
از مشکلاتی دیگر مدل فعلی می توان به موارد زیر اشاره کرد:
+ گاهی اوقات مدل موضوعی را در طول مکالمه آغاز میکند که ارتباط کمی با موضوع اصلی مکالمه دارد. در نتیجه همانطوری که در فرمول شماره 6 ذکر شده است باید توازنی بین ارتباط بین جملات در یک مکالمه و تکرار کمتر آنها وجود داشته باشد.
+ در این مدل ما تنها میتوانیم تعداد بسیار کمی از نامزدها و نوبتهای شبیه سازی شده را بررسی کنیم، زیرا تعداد موارد مورد نظر به صورت نمایی[^exponential] رشد میکند.
##نتیجهگیری
در این مقاله یک چارچوب یادگیری تقویتی برای تولید پاسخهای عصبی را با شبیهسازی گفتگو بین دو عامل، کاملکردن نقاط قوت سیستمهای SEQ2SEQ عصبی و یادگیری تقویتی برای گفتگو، معرفی شد. همانند مدلهای قبلی SEQ2SEQ عصبی، چارچوب ذکر شده مدلهای ترکیبی از معنای یک گفت وگو را نشان میدهد و پاسخهای معنایی مناسب را تولید میکند. و نیز مانند سیستمهای یادگیری تقویتی تولید گفتگو، قادر به تولید سخنانی است که پاداش آتی را بهینه کند، که با موفقیت به خواص کلی یک مکالمه خوب دست یابد. با وجود این که مدل بیان شده از ابتکارات بسیار ساده و عملیاتی برای به دست آوردن این خواص استفاده میکند، اما چارچوب پاسخهای متنوع و تعاملی را تولید کرده که مکالمات پایدارتری را به وجود میآورد.
##کارهای آینده
این بخش در فاز آینده تکمیل خواهد شد[^خود مقاله دارای بخش کارهای آینده نمیباشد و همچنین افزودن نظریات خود در این بخش مربوط به فاز آینده است به همین دلیل این بخش در فاز آینده تکمیل خواهد شد.].
#مراجع
[1] Iulian V. Serban, Chinnadhurai Sankar, Mathieu Germain, Saizheng Zhang, Zhouhan Lin, Sandeep Subramanian, Taesup Kim, Michael Pieper, Sarath Chandar, Nan Rosemary Ke, Sai Rajeshwar, Alexandre de Brebisson, Jose M. R. Sotelo, Dendi Suhubdy, Vincent Michalski, Alexandre Nguyen, Joelle Pineau1 and Yoshua Bengio , "A Deep Reinforcement Learning Chatbot",pages 1. arXiv preprint arXiv:1709.02349.
[2] Jiwei Li1, Will Monroe1, Alan Ritter, Michel Galley, Jianfeng Gao2 and Dan Jurafsky , "Deep Reinforcement Learning for Dialogue Generation" .arXiv preprint arXiv:1606.01541.
[3] Alan Ritter, Colin Cherry, and William B Dolan. 2011. Data-driven response generation in social media. In Proceedings of the conference on empirical methods in natural language processing, pages 583–593. Association for Computational Linguistics.
[4] Iulian V Serban, Alessandro Sordoni, Yoshua Bengio, Aaron Courville, and Joelle Pineau. 2015a. Building end-to-end dialogue systems using generative hierarchical neural network models. arXiv preprint arXiv:1507.04808.
[5] Sepp Hochreiter, Jürgen Schmidhuber. "Long Short-Term Memory",1997.
[6] Felix A. Gers , Jürgen Schmidhuber. "Recurrent Nets that Time and Count", IDSIA, 2000.
[7] Understanding LSTM Networks, [Online], Available: http://colah.github.io/posts/2015-08-Understanding-LSTMs/#fn1 [Accessed Nov 2017].
[8] LSTM یادگیری شبکه های , [Online], Available: http://mehrdadsalimi.blog.ir/1396/02/25/Understanding-LSTM-Networks [Accessed Nov 2017].
[9] Encoder-Decoder Long Short-Term Memory Networks, [Online], Available: https://machinelearningmastery.com/encoder-decoder-long-short-term-memory-networks/ [Accessed Nov 2017].
[10] tensorflow neural machine translation tutorial, [Online], Available: https://github.com/tensorflow/nmt [Accessed Nov 2017].
[11] ACL 2010 Joint Fifth Workshop on Statistical Machine Translation and Metrics MATR Uppsala, Sweden, [Online], Available : http://www.statmt.org/wmt10/ [Accessed Nov 2017].
[12] OpenSubtitle corpus, [Online] , Available : http://opus.nlpl.eu/OpenSubtitles.php [Accessed Nov 2017][11] Artificial intelligence: Google's AlphaGo beats Go master Lee Se-dol, [Online], Available: http://www.bbc.com/news/technology-35785875 [Accessed Dec 2017].
[12] David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. 2016. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489.
[13] The story of AlphaGo so far, [Online], Available: https://deepmind.com/research/alphago/ [Accessed Dec 2017].
[14] Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2015. A diversity-promoting objective function for neural conversation models. arXiv preprint arXiv:1510.03055.
[15] Wojciech Zaremba and Ilya Sutskever. 2015. Reinforcement learning neural Turing machines. arXiv preprint arXiv:1505.00521.
[16] ACL 2010 Joint Fifth Workshop on Statistical Machine Translation and Metrics MATR Uppsala, Sweden, [Online], Available : http://www.statmt.org/wmt10/ [Accessed Nov 2017].
[16] OpenSubtitle corpus, [Online] , Available : http://opus.nlpl.eu/OpenSubtitles.php [Accessed Nov 2017].
[17] Kishore Papineni, Salim Roukos, Todd Ward, and Wei Jing Zhu. 2002. BLEU: a method for automatic evaluation
of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics, pages 311–318.