یکی از معمولترین شکل کپچا به صورت تصویر است. در این نوع کپچا معمولا حروف و اعدادی انگلیسی به شکلی کنار هم قرار میگیرند و از کاربر پرسیده میشود که بگوید که این حروف و اعداد چیست. معمولا مسئولین این سایتها فکر میکنند که رباتها یا برنامههای کامپیوتری نمیتوانند پاسخ این سؤالات را بدهند.
مواقع زیادی هم رخ میدهد که این کپچاها به غیر از اعصاب خوردی چیزی برای ما ندارد.
در این پروژه ما میخواهیم که یک افزونه برای مروگر بنویسیم که یک کپچا را بکشند و به صورت خودکار آن را حل نماید.
برای مثال سادهتر میتوانید از کپچای سامانه آموزش دانشگاه شریف استفاده کنید.
۱. مقدمه
کپچا در تعریفی ساده سامانهٔ امنیتی و روند ارزیابی است که بااستفاده از ازمون تورینگ برای جلوگیری از برخی حملههای خرابکارانهٔ رباتهای اینترنتی بهکار میرود. این روند میتواند مشخص کند که مراجعه کنندگان به یک وبگاه و یا سایر خدمات آنلاین انسان هستند یا کامپیوتر.
بدین منظور برنامهٔ کپچا آزمونهایی را تولید میکند که:
انسان بتواند به راحتی و در طول چند ثانیه به آن پاسخ دهد و دراین زمینه به مشکل برنخورد.
کامپیوترهای فعلی ، نباید قادر باشند به چنین سوالاتی پاسخ دهند.
هر کاربری که آنرا درست حل کند، انسان فرض میشود
کپچا گاهی «معکوس تست تورینگ» نامیده میشود. چون تست تورینگ توسط انسان برگزار میشود و هدفش تشخیص ماشین است اما کپچا توسط ماشین برگزار میشود و هدفش تشخیص انسان است.
۲. روش پیشنهادی
حذف درهم و برهمی پس زمینه ، به عنوان مثال با فیلتر کردن رنگها و تشخیص دادن خطوط نازک
در ابتدا باید نموداری از رنگها در تصویر را مشخص کنیم ،این کار با گرفتن تمام پیکسل ها وگروه بندی انها انجام میشود
مثلا پس زمینه سفید ،خطوط نویز خاکستری ،متن قرمز خواهد شدتقسیم بندی ، یعنی تقسیم تصویر به قطعات حاوی یک حرف
با پردازش افقی در طول تصویر زوج مرتبی از موقعیتی که هر حرف شروع و تمام شده میتوان به دست اوردتشخیص دادن حرف هر بخش
در حال حاضر مجموعه ای از حروف اماده برای تشخیص داریم ،با به کارگیری از الگوریتم های شبکه عصبی میتوان حروف را مشخص کرد
در این مرحله نیاز به اطلاعات جامع و کاملی دارد که در هنگام اموزش باید تکمیل شده باشد
مرحله اول به طور معمول بسیار اسان بوده و به طور خودکار انجام میشود
در مرحله سوم با استفاده از الگوریتم شبکه های عصبی به درصد خطای کمتری نسبت به انسان میرسیم
ولی در مرحله دوم هنوزم انسان بهتر است زیرا اگر درهمریختگی های پس زمینه متشکل ازاشکال متشابه باحروف باشد
این اشکال وحروف توسط این درهم و برهمی متصل شده یا گاهی به اشتباه در هر تصویر 2 حرف تقسیم بندی می شود
تقسیم بندی این نوع کپچا با نرم افزار های فعلی غیر ممکن است .
از این رو برای بهبود عملکرد باید بر این بخش تمرکز کرد
اما با اثبات این موضوع که تشخیص کاراکتر ها اسیب پذیر هستند ،برخی محققان جایگزین هایی مانند تشخیص تصویر را پیشنهاد داده اند
این محققان تشخیص تصویر را چالش برانگیزتر میدانند زیرا محدود به کاراکتر و رقم در الفبای انگلیسی نیست
۳. کد پروژه
کد
# کارهای مرتبط
به مدت چند سال ازمون تورینگ نیمه یا همان captcha در اکثرسایت ها با قابلیت اطمینان بالا موجود بود ولی در چندین سال اخیر این ازمون تورینگ شکست پذیر شد
در نتیجه در پی این معضل برنامه نویسان به استفاده از audio روی اوردند
که در این روش نه به اسانی captcha ولی بازهم قابلیت شکستن دارد
شروع این برنامه با خواندن فایل های صوتی شروع میشود .اولین قدم برای شکستن این نوع کپتچا استفاده از چندین تکنولوژی machine learning برای اجرای ASR میباشد
در این زمینه تکنیک های زیادی وجود دارد.3روش که در این قسمت استفاده میشود :
(mel-frequency cepstral coefficients (MFCC
(perceptual linear prediction (PLP
(relative spectral transform-PLP (RAS TA-PLP
MFCC :
یکی از مشهورترین ها در این زمینه میباشد برای تبدیل فایل های صوتی به باند فرکانس میباشد
موفقیت در این زمینه به دو بخش تقسیم میشود :
Segmentation , recognition
در ابتدا باید audio را به بخش هایی تقسیم کنیم و پس از ان باید انها را بر اساس سروصدا و یا کلمه طبقه بندی کنیم.(کلمات در این قسمت شامل حرف یا عدد است)
با استفاده از manual که برای audio captcha اطلاعاتی درباره مکان هر کلمه که به دست می اوریم و ما قادر به برچسب زدن بخش ها با استفاده از این اطلاعات میشویم .
تقریبا 100 فایل صوتی از سایت های مختلف برای train استفاده میشود به بخش های از سر و صدا ،حروف A -Z، و یا ارقام از 0-9 تقسیم میشوند.
A test audio CAPTCHA with the fixed-size segments containing the highest energy peaks highlighted

برای recognize کردن حروف و اعداد از الگوریتم های زیر استفاده میشود :
adaBoost
support vector machine
K-nearest neighbor
4. Cage :
Cage نوعی از کپتچا بر اساس کتابخانه جاوا میباشد که سریع ، کوچک و اسان است
و با هدف ایجاد عکس هایی که برای انسان اسان و برای کامپیوتر غیرقابل حل یا حداقل مشکل باشد


با استفاده از maven میتوان سریعا ازاین کپتچا استفاده کرد
در غیراین صورت باید فایل jar دانلود کرده و کد کپتچا ساخته میشود که به علت سادگی به اسانی نیز میشکند
5. NUCaptcha
نسل بعدی کد امنیتی به طور خاصی طراحی شده است که کپتچا به طورمتحرک است و احتمال خطای کامپیوترها بیشترشده است و از طرفی امنیت تصویر بیشترشده است
Nucaptcha با استفاده از شاخص های اندازه گیری برای شناسایی فعالیت های مشکوک ساخته شده است
این نوع کپتچا یا خیلی اسان هستند که با استفاده از ocr قابل حل میباشند
یا به شدت سخت بوده و حتی انسان ها هم قادر به حل ان نمیباشند
این نوع کپتچا برای استفاده و امنیت بالا طراحی شده است
6. Are you A Human
سرویس جالبی است که کاربر برای تکمیل فرم باید یک بازی تعاملی را انجام دهد
این بازی با کلیک کردن و کشیدن اشیا انجام میشود و مطمئنا از تشخیص حروق کپتچا جالب تر خواهد بود

. پروژه Mori G. که به چاپ مقاله ای در IEEE CVPR'03 منجر شد.در این مقاله یک روش برای شکستن یکی از مشهورترین کپچا ها پرداخته اند و تاحدود 92% موفق به شکست کپچا شده اند:
. پروژه PWNtcha نیز پیشرفت زیادی در این زمینه دارد :
it stands for “Pretend We’re Not a Turning Computer but a Human Antagonist”
.An Anti-SMS-Spam Using CAPTCHA
۷. آزمایشها
خوشبختانه بسیاری از کپچا ضعیف هستند و با تمیز کردن ، حذف خطوط درهم و برهم و به کمک OCR های ساده حل شده اند
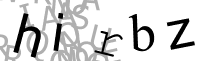
با گذشتن از مرحله اول
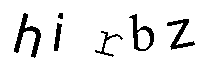
اکنون نتایج حاصل را برای استخراج متن به OCR داده میشود
در اینجا از 3 ابزار OCR برای مقایسه استفاده شده :
Tesseract :hirbz
Gocr:_i_bz
Ocrad:hi_bL
چند نمونه دیگر:
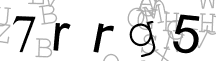
Tesseract :7rrq5
Gocr :7rr95
Ocrad :7rrgs
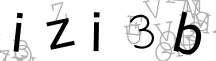
Tesseract :izi3b
Gocr :izi3b
Ocrad :iLi3b
در این ازمایش گرفتن نتیجه 100% ملاک نیست زیرا مردم واقعی هم گاهی اشتباه میکنند
در این ازمایش ، Tesseract فقط g با q اشتباه کرد و Gocr به جای g ,عدد 9 را چاپ کرده بود که قابل درک بود
ولی Ocrad هیچ جواب درستی نداده است
۸. اینده کپچا
۹. مراجع
J Yan and A S El Ahmad. “Breaking Visual CAPTCHAs with Naïve Pattern Recognition Algorithms”, in IEEE
Conference Proc. of the 23rd Annual Computer Security Applications Conference (ACSAC’07)
K Chellapilla, and P Simard, "Using Machine Learning to Break Visual Human Interaction Proofs (HIPs)," Advances in Neural Information Processing Systems 17, Neural Information Processing Systems (NIPS), MIT Press, 2004.
Akshay Mittal , Ankit Kumar ,Recognising Text from Captcha
Kumar Chellapilla Patrice Y. Simard “Using Machine Learning to Break Visual
Mori G,Malik J (2003),"Recognizing Objects in Adversarial Clutter:Breaking a Visual CAPTCHA," proc. of the computer Vision
and pattern Recognition (CVPR )Conference,IEEE Computer Society, vol.l,June 18-20,2003
Chandavale, A.A., Sapkal, A.M., Jalnekar, R.M.: Algorithm To Break Visual CAPTCHA. In: Second International Conference on Emerging Trends in Engineering and Technology, ICETET 2009 (2009)
Shirali-Shahreza, M. ; Sharif Univ. of Technol., Tehran ; Shirali-Shahreza, S., Question-Based CAPTCHA, Conference on Computational Intelligence and Multimedia Applications
Paul Baecher, Niklas Büscher, Marc Fischlin, Benjamin Milde , Breaking reCAPTCHA: A Holistic Approach via Shape Recognition
Haribabu, K. ; Comput. Sci. Group, Birla Inst. of Technol. & Sci., Pilani, India ; Arora, D. ; Kothari, B. ; Hota, C.Detecting Sybils in Peer-to-Peer Overlays Using Neural Networks and CAPTCHAs