در مدلسازی موضوعی، فرض میکنیم که مجموعه متون ورودی از روی چند موضوع نامعلوم ساخته شدهاند و باید این موضوعات را پیدا کنیم. هر موضوع یک توزیع احتمال نامعلوم روی واژهها است و هر متن توزیع احتمالی روی موضوعها.
در این پروژه شما باید بعد از فهمیدن فرایند مدلسازی موضوعی، تلاش کنید موضوعات بیانشده را برای آیات قرآن پیدا کنید. دادههای ورودی شما ظاهر آیات به همراه ترجمه و تفسیر آنها هستند.
۱. مقدمه
همان طور که اطلاعات در دنیای امروز در حال زیاد شدن است پیدا کردن موضوعی که ما به آن نیاز داریم نیز سخت تر میشود. پس ما برای ساماندهی ، جستجو و فهمیدن این اطلاعات وسیع نیاز به ابزاری مناسب داریم.
مدل سازی موضوعی یک سری روش است که به طور اتوماتیک ساماندهی ، فهمیدن ، جستجوکردن و خلاصه کردن مقالات الکترونیکی را انجام می دهند.
درواقع سه وظیفه ی اصلی آن ها عبارتند از:
پیدا کردن موضوعات نامعلوم که در مجموعه اسناد وجود دارند.(شایع هستند)
تفسیر کردن اسناد بر اساس موضوعات آن ها .
استفاده کردن از این تفاسیر برای سازمان دهی کردن ، خلاصه کردن و جستجو کردن متن ها.
ما در این پروژه قصد داریم بر اساس الگوریتم (LDA) مدل سازی موضوعی را انجام دهیم.حال کمی به توضیح مبانی این روش می پردازیم:
هر موضوع توزیعی روی کلمات است.
هر سند ترکیبی از موضوعات کل اسناد است.
هر کلمه از یک موضوع گرفته شده است.
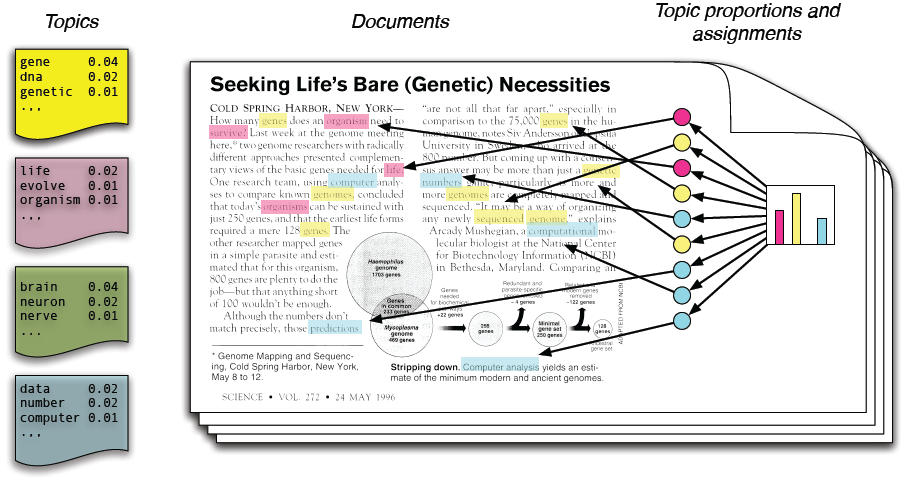
در واقع ما فقط اسناد را می بینیم و دیگر ساختار ها ساختار های نامعلوم هستند.
هدف ما حدس زدن این ساختار های نامعلوم است.
LDA به صورت یک مدل گرافیکی:
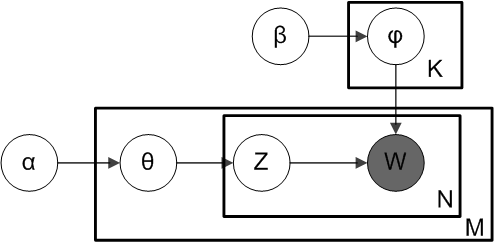
که در این مدل :
w=کلمات مشاهده شده
\theta= نسبت فراوانی موضوعات برای هر سند
\alpha= پارامتر نسبت ها
Z= موضوع اختصاص داده شده برای هر کلمه
\phi= موضوعات
\beta= پارامتر موضوع
و این هم یک فرمول ریاضی برای محاسبه ی LDA:
به علاوه در مورد مدل LDA دانستن موارد ذیل مفید است:
LDA یک مدل احتمالی از متن است. این مدل مساله پیدا کردن موضوعات در مجموعه ای بزرگ از اسناد را به مساله استنتاج قبلی (posterior inferecne problem) محدود می کند.
این مدل به ما اجازه میدهد تا در یک مجموعه اسناد بزرگ و حجیم ساختار موضوعی نامعلومی را تصور کنیم و همچنین اطلاعاتی جدید را که برای این ساختار مناسب هستند را تولید کنیم.
در ضمن این مدل محاسبات ریاضی و احتمالی دارد که از آوردن آنها در این جا صرف نظر می کنیم ولی در صورت نیاز میتوانید روی این مقاله کلیک کنید.
۲. کارهای مرتبط
برای پیاده سازی مدل سازی موضوعی دو روش اصلی وجود دارد:
LDA که در مقدمه توضیح داده شد.
۲.LSA که ما در زیر به توضیح آن می پردازیم.( در ضمن برای پیاده سازی اولیه از این روش استفاده کردیم.)
روشLSA:
مقدمه:LSA یک تکنیک برای آنالیز کردن روابط بین داکیومنت ها و کلمات درون آن ها در پردازش زبان طبیعی و به طور خاص تر در بردارهای مفهومی است که به وسیله تولید کردن یک سری مفهوم که به داکیومنت و کلمات مربوط می شود این کار را انجام می دهد. LSA فرض میکند که کلماتی که از نظر مفهومی به هم شبیه هستند در یک قطعه از متن قرار می گیرند.یک ماتریس شامل تعداد کلمات در هر پاراگراف ( سطر ها کلمات منحصر به فرد هستند و ستون ها هر پاراگراف را نشان می دهند.) که از یک قطعه متن بزرگ و یک مدل ریاضی به نام singular value decomposition ساخته شده است و هدف این است که با ثابت نگه داشتن سطر ها ستون های ماتریس را کاهش داد. کلمات با گرفتن کسینوس از زاویه بین دو vector ی که به وسیله ی هر دو سطر تشکیل شده است، مقایسه می شوند.مقادیر نزدیک به یک یعنی کلمات بسیار مشابه و مقادیر نزدیک به صفر یعنی کلمات غیر مشابه.
مدل LSA میتواند از ماتریس term-document که تعداد ترم ها در داکیومنت را بیان میکند استفاده کند. سطر های این ماتریس همان ترم ها و ستون هایش همان داکیومنت ها هستند. یک مثال عمومی این است که وزن element های ماتریس tf-idf باشد. element های ماتریس متناسب با تعداد کلمه در هر داکیومنت است.این ماتریس همچنین با مدل های استاندارد معنایی متداول است. و همچنین همیشه لازم نیست که به صورت ماتریس بیان شود.
شرحی بر مدل احتمالی PLSA:
طبق مدل Naive Bayes هر داکیومنت از k موضوع تشکیل شده است. هر موضوع یک چند جمله ای روی کلمات است و هر داکیومنت از یک موضوع منحصر به فرد تولید شده است.
پارامترهای (p(z=k) , p(w|z=k می توانند از داده های بر چسب خورده(MLE , MAP) یا با الگوریتم EM اگر برچسب کلاس وجود ندارد بدست بیایند. این مدل خیلی انعطاف پذیر نیست چون فرض می کند که هر داکیومنت یک موضوع دارد.
pLSA فرض میکند که هر داکیومنت d با word vector w از همه ی موضوعات با وزن مشخص هر موضوع داخل یک داکیومنت تشکیل میشود. یک فرآیند تولیدی از pLSA در ادامه گفته می شود.یک مجموعه داکیومنت ثابت با n داکیومنت داده شده است. ما آن را با یک ماتریس documnet-term داکیومنت-کلمه ای n*V به صورت c(d,w) نشان میدهیم ؛ منظور از (c(d,w تعداد کلمات از نوع w در داکیومنت d است . از فرمول زیر احتمال برداشته شدن c(d,w) به دست می آید.
پارامتر های این مدل \theta ={ p(z), p(d|z) , p(w|z)} هستند. ما میخواهیم احتمال ماتریس های document-term مشاهده شده را به حداکثر برسانیم.
که با فرمول های زیر قابل دستیابی است. و دیگر از توضیح بیشتر خودداری میکنیم چون فهمیدن کامل این مدل واقعا دشوار است. برای
در آخر باید بگویم چون کتابخانه ی این روش در پایتون وجود دارد از توضیح بیش از حد مدل ریاضی خودداری کرده ام چون نیازی نیست خود را به طور افراطی درگیر مدلی کنیم که پیاده سازی شده است.
خلاصه ای از روش پیاده سازی :
ما ابتدا باید با استفاده از ابزاری ، زبان های فارسی و عربی را در زبان پایتون، بتوانیم پردازش کنیم. سپس با استفاده از کتابخانه gensim که ابزازی برای مدل سازی موضوعی است متن قرآن را مدل سازی موضوعی کنیم. در این کتابخانه دو روش LSA, LDA برای مدل سازی موضوعی وجود دارد. یعنی این دو روش کامل در کتابخانه های خاصی پیاده سازی شده اند و ما فقط باید بتوانیم از آنها به نحو احسنت استفاده کنیم.(دیگر کاری به مدل ریاضی آن نداریم) در پیاده سازی اولیه ما از روش LSA استفاده میکنیم.
در ضمن ارزیابی روش آن را به فاز بعد موکول میکنیم.
۳. کد برنامه نویسی
شرحی بر کد برنامه نویسی:
در ابتدا باید گفت ما با استفاده از کتابخانه json متن اصلی آیات را داخل دیکشنری می توانیم ذخیره کنیم. همچنین بااستفاده از ISRIStemmer ریشه ی کلمات را پیدا میکنیم. و در واقع روی آنها مدل سازی انجام میدهیم.
روال کلی کار به این صورت است که ما هر صفحه ی قرآن را یک داکیومنت فرض کرده ایم. ابتدا تمامی کلمات عربی موجود را در این صفحه را بعد stem شدن در یک لیست می ریزیم و سپس آن را به لیستی دیگر اضافه می کنیم. در آخر مثلا اگر ۱۰ صفحه موجود باشد ما لیستی داریم که شامل ۱۰ element است. که در هر کدام از این element ها کلمات موجود در آن صفحه قرار دارد. حال با این لیست یک دیکشنری و کورپوس مخصوص که برای تبدیل داکیمونت به vector و همچنین مدل LSA لازم است را می سازیم. سپس با استفاده از کتابخانه ای که مدل tf_idf را در پایتون پیاده سازی کرده است متن کورپوس را به vector تبدیل می کنیم. چون یکی از ورودی های LSA متن تبدیل شده به vector tf_idf است. حال با استفاده از مدل LSA میتوانیم بگوییم که چند موضوع از این داکیمونت استخراج کن.( تعداد این موضوعات دلخواه است و باید با استفاده از کارهای علمی که روی قرآن انجام شده است تعیین گردد)
خروجی برنامه نیز بدین صورت است که هر موضوع متشکل از چند کلمه ضرب یک عدد خاص است که مشخص می کند این کلمه در این موضوع چقدر اهمیت دارد و کلمات در یک موضوع مسلما به هم مرتبط هستند.
۴. کار های مشابه:
یکی از کارهای انجام شده در مورد مدل سازی موضوعی ۱۰۰۰۰۰ مقاله سایت ویکی پدیا است. در واقع کتابخانه از gensim برای این کار استفاده شده است. این کار از TMVE برای نمایش آن به صورت گرافیکی استفاده میکند. این کار یک مرورگر است که ویژگی های زیر را دارد:
می تواند موضوعات را به ترتیب تکرار بیشتر زیر هم مرتب کند.
روی هر موضوعی کلیک می شود کلمات پر تکرار آن موضوع ، موضوعات مرتبط با آن موضوع و همچنین اسناد مربوطه را نشان می دهد و به همین ترتیب اگر روی اسناد کلیک شد متن سند را نشان می دهد.
در هر موضوع مشخص است که چه کلماتی با چه درصد هایی وجود دارند.
یک صفحه از مرورگر شامل تمام موضوعات با ۵ کلمه پر تکرار آن ها باشد.
صفحه ای دیگر شامل همه ی کلمات به ترتیب تکرار آنها است که مشخص شود که به طور کلی هر کلمه ای چند بار تکرار شده است.
در ضمن برای درک بیشتر به این لینک می توانید مراجعه کنید.
یکی از کار های دیگری که بر روی topic modeling انجام شده است مدل کردن تحول علم است. این کار به صورت یک مرورگر است که نشان می دهد در طی سال ها کلمات پر تکرار یک موضوع چگونه تغییر می کند. روی هر موضوع کلیک می شود داکیومنت های مرتبط با آن را نشان میدهد و همچنین چند کلمه پر تکرار آن . روی هر داکیومنت نیز کلیک شود موضوعات و داکیومنت های مرتبط با آن نشان داده می شود.
در ضمن برای درک بیشتر به این اینجا می توانید مراجعه کنید.
در حوزه ی مدل سازی موضوعی library های مفیدی نیز برای زبان های مختلف وجود دارد که در این سایت وجود دارد.
۵. آزمایشها
همانطور که در بخش کارهای مرتبط گفته شد یکی از مهمترین آزمایش ها روی مدل سازی موضوعی مرورگری است که ۱۰۰۰۰۰ مقاله ویکی پدیا را مدل سازی موضوعی کرده است.
یکی دیگر از این آزمایش ها روی مدل کردن تحول علم صورت گرفته است که برای رفتن به آن می توانید روی اینجا کلیک کنید.
۶. کارهای آینده
۷. مراجع
Blei, David M. "Probabilistic topic models." Communications of the ACM 55.4 (2012): 77-84.
Probabilistic Topic Models Mark Steyvers Tom Griffiths
On-Line LDA: Adaptive Topic Models for Mining Text Streams with
Applications to Topic Detection and Tracking Loulwah AlSumait, Daniel Barbar´a, Carlotta DomeniconiJoint Sentiment/Topic Model for Sentiment Analysis Chenghua Lin
Yulan HeExploring Content Models for Multi-Document Summarization
Aria Haghighi Lucy VanderwendeVisualizing Topic Models Allison J. B. Chaney and David M. Blei
# پیوندهای مفید